




一、问题现象
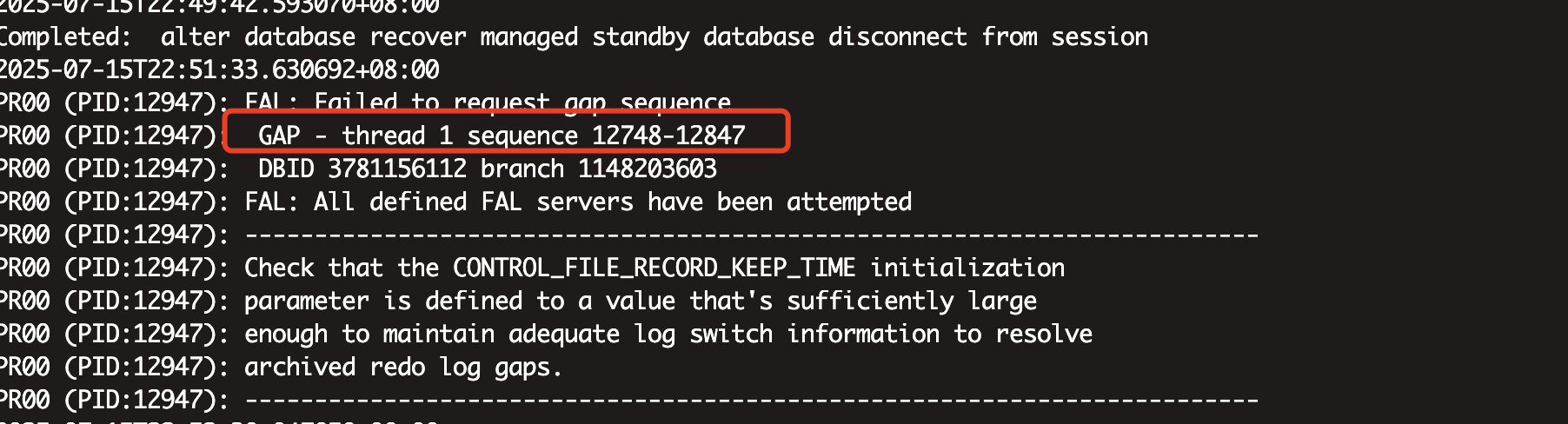
有一套19.3环境的备库意外断电,数据库重启到mount状态无法进行open,提示有gap,需要12748~12847的归档日志
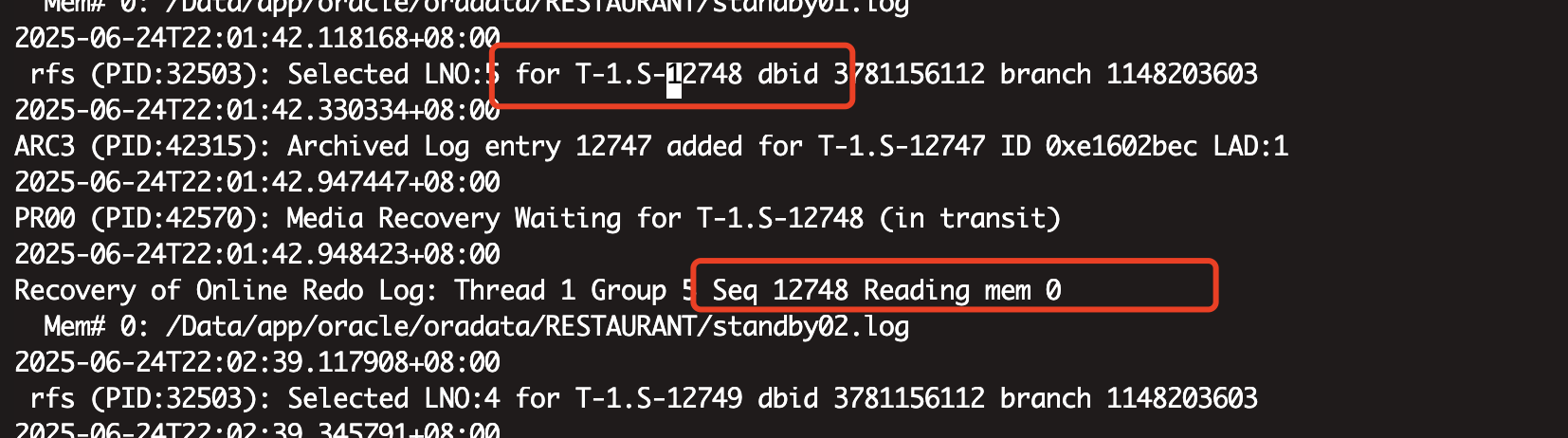
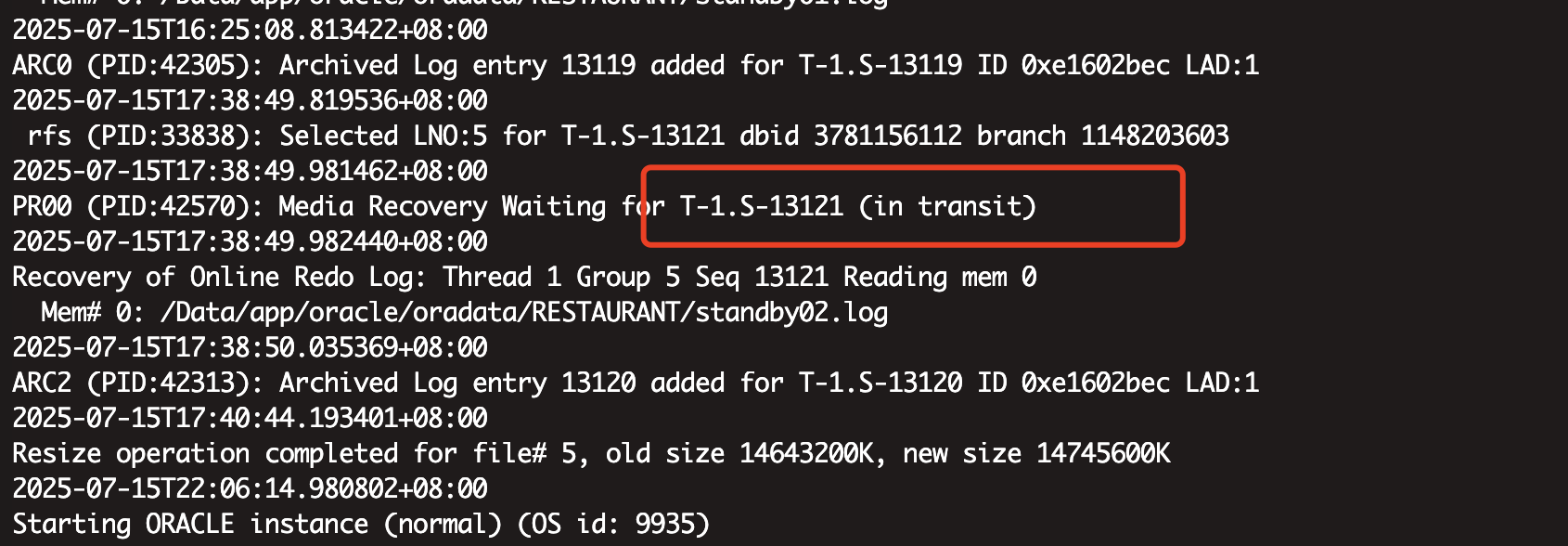
但是检查alert发现12748很早之前就已经应用了,具体日期在2025年6月24日,而且用到了今天下午(2025年7月15日)5点多点13121号日志。按理说19c不应该出现这种问题。
查看mos,找到相关的bug,Bug 29056767 - STANDBY: Datafiles Checkpoint not Updated at Standby Database when Media Recover is running (Doc ID 29056767.8)
Code Improvement
Recovery
Physical Standby Database / Dataguard
"_time_based_rcv_ckpt_target"
Description
On a Physical Standby database, media recovery not regularly updating the checkpoint scn and time stored in each datafile header.
This problem only happens in oracle version 18.1 onwards.
Standby media recovery is running, and it's applying successive log seq#'s,
but the checkpoint scn and time stored each datafile header doesn't change.
NOTE: the checkpoint in the datafile headers can be monitored by:
select to_char(sysdate,'HH24:MI:SS'), file#, checkpoint_change#,
to_char(checkpoint_time,'HH24:MI:SS') from v$datafile_header;
A level 1 incremental backup on the standby may skip all the datafiles.
Another impact of this bug is that if media recovery suddenly aborts for some other reason (eg due to a "shutdown abort" of the instance)
then the next media recovery session may try to start scanning redo from much further back in time than necessary, and if that redo is
unavailable, V$MANAGED_STANDBY would show MRP0 status is WAIT_FOR_GAP, alert log file will show 'FAL: Failed to request gap sequence'「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
