最近的大模型圈热闹非凡。
上周四,马斯克X.AI旗下的Grok 4正式官宣;仅仅一天之后,月之暗面也正式开源了 Kimi K2 大模型。宣传口径上,两家企业如出一辙,都强调了工具使用能力,也都宣称拿下了AIME2025 在内多个benchmark的SOTA表现。而在这一周,最新的 Gemini 和 OpenAI 开源模型也蓄势待发。
我们不再对模型细节做过多赘述,这里聊两个有意思的数据和现象:
关于Kimi K2,官方数据表示,模型完成了15.5T token的平稳训练,总参数1T(半年前的Moonlight-16B-A3B训练数据量还只有5.7T);
关于Grok 4,马斯克表示其训练量是Grok 2的100倍,强化学习(RL)阶段投入的算力,是市面上其他任何模型的10倍以上。
这是个很有意思的话题,大模型的预训练数据量万亿tokens成为常态,且仍在几何级增加,快速把那些研发能力、资本能力不过关的对手迅速甩下牌桌;
但另一边,Scaling law依然有用,只是模型的智能程度却不再随着训练量等比增加。
原因很简单,训练数据的冗余与重复太多了。
如何处理?
在与多个头部大模型企业合作之后,Milvus\Zilliz Cloud正式推出了成熟的Minhash LSH查重功能,可用于大模型预训练数据管理在内的百亿文档高效查重。加速大模型训练质量的同时,帮助企业实现了更低成本的数据检索与利用。
那么,大模型为什么需要数据查重,如何做数据查重,Milvus与Zilliz cloud的优势又是什么?本文将对此一一解读。
01 为什么大模型训练需要数据查重
在解读为什么需要大模型训练数据查重之前,我们先看这么一组数据:
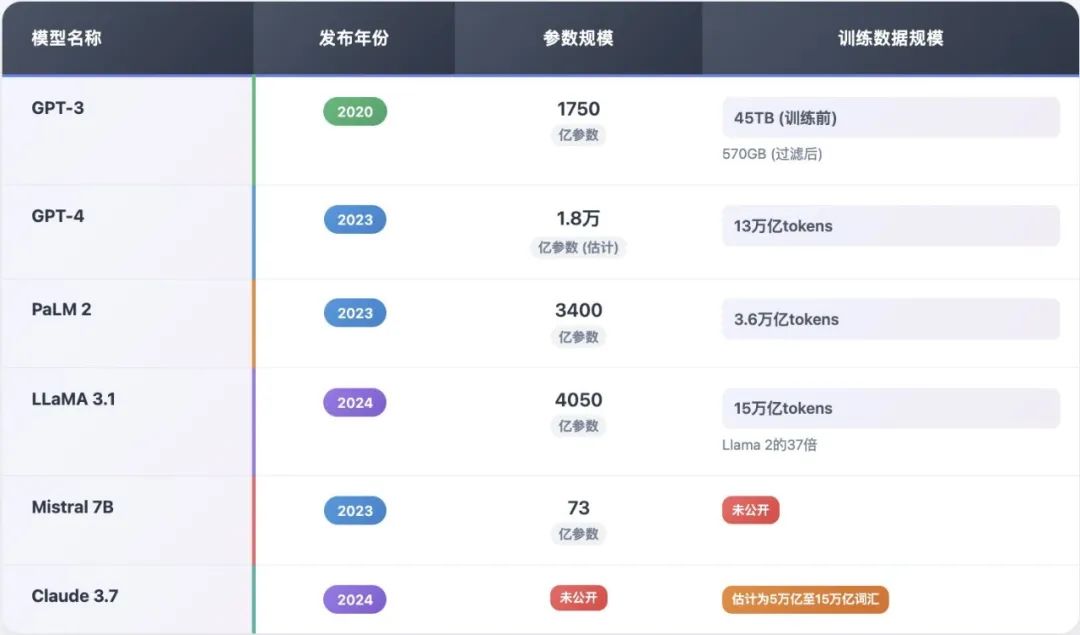
时至今日,大模型训练中,十万亿级别的tokens和百亿级的文档是大模型预训练的常态。
但一个问题是,来自公域互联网的这些预训练数据中往往会存在大量重复冗余内容,如果将其一股脑不加选择的用于预训练,不仅浪费计算资源,更会导致大模型反复“咀嚼”相同的知识,在重复内容上过拟合,降低了对新信息的泛化能力。
对预训练数据进行查重,已经成了各大主流大模型企业做预训练数据管理时的重要一环。从解决思路来说,目前主流的去重方法可以分为三类:精确匹配、近似匹配以及语义匹配。

随着预训练语料体量达到 TB 甚至 PB 级别,传统的精确匹配(如两两比对)根本无法承载计算负载,并且无法高效查找出一些内容高度相似但表述不同的内容;而语义去重则涉及向量生成和大规模匹配,开销巨大。
与之相对,MinHash LSH为代表的近似匹配,是百亿数据规模下做数据查重相对成本可控且高效的方式。
02 Minhash LSH如何进行高效查重
MinHash LSH,顾名思义,是由LSH加速MinHash的检索。
那么什么是MinHash ?简单来说,MinHash 就是通过压缩原始集合为固定长度的签名向量,近似估算相似度,从而大幅降低计算开销。
它会先将每个文档拆分成由单词或字符构成的短语切片集合,然后将每个文档的切片集合应用多个哈希函数,并记录每个函数作用后得到的最小哈希值,为每个文档生成一个签名向量。在计算相似度时,两个文档的 MinHash 签名中相同位置的哈希值一致的概率,可以很好地拟合原始切片集合之间的 Jaccard 相似度。
不过,还有一个问题是,即使使用了紧凑的 MinHash 签名,在数百万甚至数十亿个文档中进行两两比对,计算成本依然非常高。此时就需要引入 局部敏感哈希LSH方法(Locality Sensitive Hashing,)。
因此,MinHash LSH的核心思想是:把每个 MinHash 签名划分为 多个带(band),然后将相似条带使用标准哈希函数将其哈希到某个桶中,如果两个文档的任意一个条带落入同一个桶,即被标记为可能相似。通常来说:高度相似的文档往往有很多相同的哈希值,因此至少在某一带中落入同一个桶的概率更高。因此,我们可以通过调整带数和每带的维度数 ,在召回率(找到所有相似对)、精确率(减少误报)和速度之间进行权衡。
基于这一背景,Milvus团队在Milvus2.6版本以及Zilliz Cloud中构建了专门的MinHash -LSH算法,其中,MinHash 负责将文档压缩为签名(目前,minhash 向量需要客户根据需求自行生成)LSH 负责高效缩小搜索空间,从而快速定位潜在重复,帮助企业完成百亿级语料下的预处理优化。
此外,我们还将这一能力原生写入数据库索引系统,API 层面也做了统一,兼容 embedding 插入(此功能仍在迭代优化中,如果您有更多的想法与建议,欢迎与我们沟通交流)索引构建与近似查询。更关键的是,它支持分布式、横向扩展,确保了 TB 甚至 PB 级数据量下的处理能力。
03 百亿数据去重的工程化难点是什么
一直以来,如何将Minhash LSH工程化落地,都是困扰业界的一大难题。
这背后有两大隐藏需求:
(1)能够足够深入的理解Minhash与LSH,并将其深度融合落地。
(2)能用上Minhash LSH的场景,通常是针对百亿、千亿甚至万亿数据的查重,这对服务背后的性能、工程化能力全都提出了极为苛刻的要求。
一年前,一个头部大模型企业,在做Minhash落地的时候,就曾提出以下需求:对百亿数据规模(780d x int32格式)做查重,要求能定期、快速拉起服务,并且快速对数据进行去重与写入。
但是刚一上手,就发现了一个致命问题:多数向量数据库常用的数据格式是float32。但MinHash Vector是uint32_hash值的集合。
看起来,float32多数情况下,也的确能表示uint32的数据类型。
但问题是,float32能表示的无符号整数范围:0~16,777,216;而uint32的表示范围则是:0~4,294,967,295
也就是说,如果MinHash Vector的哈希值 ≤ 16,777,216,float32 自然可以无损存储;若哈希值 > 16,777,216,float32 会丢失尾精度。
但好在,Milvus与Zilliz Cloud支持的binary vector,可以很好的解决这一问题。
当然,这看起来不是一个足够性感的问题,但却需要数据库从早期设计,就考虑到不同用户的数据格式、数据规模以及多样化的需求。如果没有一开始就瞄准企业级市场,那么即使一个微小的数据格式问题,也会在后期成为影响客户体验的重大事故。
此外,客户也对性能提出了严苛的需求。对接现场,客户曾直白提出,“我要每次快速拉起Zilliz Cloud服务,拉起就能做高精度的向量去重;每次导入30GB文件,780维的int32签名数据,但整体导入耗时必须控制在 15min 以内。”
所有人都沉默了三秒。
但很快,大家就给出了答案,不用15分钟, 4分钟就能搞定。
该性能飞跃主要得益于Milvus两项关键优化:首先,引入多文件并行处理机制,打破了传统串行导入的瓶颈,让系统能够同时处理多个数据文件,有效提升整体吞吐能力,显著加快导入速度。其次,集成动态资源分配策略,使系统能够基于任务的体量和复杂度动态调度计算资源,实现更加智能的任务分配与资源利用,避免资源闲置或竞争。通过这些优化,Milvus 能够更充分地发挥现代硬件计算能力与云存储的并发读写特性,为用户提供更高效、近乎实时的数据导入体验。
解决导入问题之后,又该怎么对大规模的数据做快速拉起与计算?
在大模型训练数据管理场景下,无论是导入数据量,还是底库中已有的数据量,都非常庞大。其峰值VPS 4.4万向量检索,同样是一个罕见的高并发场景。
与此同时,随着数据不断插入,底库越来越大,计算量在后期会变得越来越大,对数据库性能带来的挑战也会不断增加。
这就需要高效的并发计算能力,来加速这一过程。而Zilliz Cloud的云原生分布式特性,恰好可以很好地解决这一问题。
未来,Minhash LSH工还将继续迭代成为Zilliz Cloud独有Cardinal 引擎的一部分,进一步加快非结构化数据处理的效率。
Cardinal 是用现代 C++ 语言和实用的近似最近邻搜索(ANNS)算法构建的多线程、高效率向量搜索引擎,能够在有限的资源内处理更多用户请求。
算法层面,Cardinal 针对IVF和图索引等算法做了大量针对性优化,用于平衡性能与RAM的成本;
工程层面,Cardinal 设计了专门的内存分配器和内存池,以及组件的层次结构,促进将元素组合成各种搜索papiline,针对特定、关键用例做了代码定制。
此外,Cardinal还包含了许多不同目的的计算内核,每个内核都为特定的硬件平台和用例专门编写和优化。
以上这些功能的深度优化,使得 Cardinal 能够时刻全力运行,成为行业内最快的向量搜索引擎。
而有了 Cardinal 搜索引擎的加持,Zilliz Cloud 实现了 10 倍性能提升(与开源 Milvus 相比),以及超快的查询速度外加高召回率。无论是处理大型数据集还是对快速响应有高要求的场景,Cardinal 都能为此保驾护航,提升用户体验,提升 AI 应用的竞争力。
尾声
实际上,大模型训练数据查重,只是如今非结构化数据利用的一个缩影。
根据IDC的预测,到2027年,全球范围内,没有统一格式、缺乏明确定义字段的非结构化数据,总量将达到近250ZB,占比达到整体数据总量的86.8%。
与之对应的是,相比传统结构化数据,这些非结构化数据的处理成本和存储成本会大大攀升,而其信息密度又往往低于传统的结构化数据。
然而,无论是文本、图像、音频、视频、传感器日志、社交媒体内容、PDF、网页、代码片段亦或是医疗影像和卫星照片,这些非结构化数据本身的价值往往难以忽视。
如何低成本、高效率的利用这些不断增加的非结构化数据,这不止是大模型与向量数据库企业急需解决的难题,更是千行百业所面临的共同课题。
end
此处插入一条干货分享:
7.31 20:00,Zilliz Senior SRE 刘川丰将在线分享《如何让 Milvus 更稳定:运维部署最佳实践》。不止干货,还有自由提问互动,感兴趣请戳链接https://mp.weixin.qq.com/s/xDwemxOYMyRVhGT1DYWnfA