




Apache Cloudberry™ (Incubating) 是 Apache 软件基金会孵化项目,由 Greenplum 和 PostgreSQL 衍生而来,作为领先的开源 MPP 数据库,可用于建设企业级数据仓库,并适用于大规模分析和 AI/ML 工作负载。
GitHub: https://github.com/apache/cloudberry
在构建现代向量化数据仓库系统的过程中,数据重分布(redistribution)是一个绕不开的关键步骤。它既是 MPP 查询执行的协作桥梁,也是吞吐性能的敏感点。表面上,这是一件“非常工程”的事情:把数据根据分布 key 分到对应节点,再做下一步处理。但深入底层大家会发现,重分布不仅决定着 CPU 和网络资源的使用效率,还深藏着复杂度陷阱,尤其是在 Filter 与 Take 算子协同作用时。
本文将拆解 Cloudberry 在重分布路径中遇到的一个典型性能瓶颈,并分享我们如何通过调度机制的结构性重构,将其从 O(N²) 优化为 O(1)。
向量化重分布流程回顾
在 Cloudberry 的向量化执行模型中,重分布流程可简化为三步:
Hash:根据分布 key 对数据进行 hash 分桶。 Filter:为每个目标节点构建布尔筛选向量,挑出应发往该节点的行。 Take:根据筛选结果,从原始 RecordBatch 中抽取数据构造目标批次。
这个流程可以看作是:
for each target_node:
mask = filter(records, where node_id == target_node)
result[target_node] = take(records, mask)
当节点数较少时,这套逻辑运行顺畅。但当我们将系统扩展到几十上百个节点时,问题就暴露出来了:执行耗时呈指数级上升,网络负载加剧,CPU 使用率暴涨。
Filter+Take 的复杂度陷阱
核心问题在于该段逻辑的复杂度:
for each node:
mask = filter(...)
output = take(input, mask)
这在每一个节点维度都进行了一次 filter 和 take。对于一个拥有 N 个节点、M 行数据的批次,最坏情况下就是 执行了 N 次 filter + take 操作,且每次遍历 M 行数据,其时间复杂度达到 O(N × M)。
进一步细化:
Filter 构建一个布尔掩码,代价为 O(M); Take 则是按掩码重新构建向量,需要 O(K); 并且每个节点都执行一遍(哪怕命中数据很少),构成冗余。
在集群节点增多、批次数据量增大时,这种“线性乘积”放大效应愈发明显。
实例指标(某查询下)
大家可以看到,节点数扩大 16 倍,耗时扩大了 18 倍以上,远远超过线性增长,典型的复杂度爆发。
火焰图:性能崩塌点直观可见
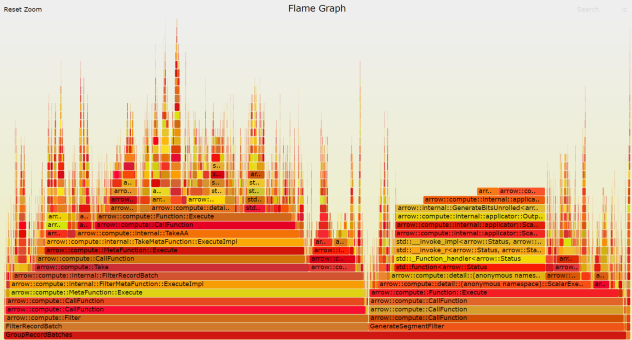
我们使用 perf
和火焰图分析 CPU 调用栈,发现热点集中于:
FilterExec::EvaluateBatchTakeExec::MaterializeArrow 相关函数如 AllocateBitmap
、MakeArray
这些函数堆栈高度在火焰图中连续升高,形成“平台状火焰墙”,说明系统在反复执行 filter 和 take,并频繁进行内存构建操作。
同时,我们将节点数量与耗时绘制为曲线图,可以清晰看到:
起初性能线性增长; 节点数超过 32 后,出现拐点; 节点数越多,增长斜率越陡,说明瓶颈效应在放大。
这意味着:原有机制不适合在大规模场景下运行,必须重构。
分组调度机制重构:O(1) 的启发式路径
我们提出的解决方案核心思想是:从“逐节点处理”转向“全局排序+切分”。
新流程如下:
每行预计算目标节点编号 → segment_id对整个 RecordBatch 按 segment_id
排序记录每个 segment 的 (offset, length)直接 slice
排序后数据构造子批次
相当于一次排序后就完成了所有的分发分段操作,避免了对每个节点都跑一遍 filter+take。
复杂度对比:
| 总复杂度 |
局部性优化:提升 cache 亲和性
除了算法复杂度,我们还关注了内存访问局部性:
排序后的数据是分段连续存储的,每个节点对应的数据紧凑集中,有利于 cache 命中。 在后续算子(如 Shuffle、Encode)中处理这些分段数据时,可实现零 copy、无缓存碎片。 进一步支持分段并发处理时,每个线程只需要处理一个连续段,调度简单、内存局部性强。 这类结构性优化为系统带来的不仅是“更快”,还有“更稳”和“更可控”。
多维基准测试对比
我们设计了多维度对比测试,用以验证优化效果:
此外,内存使用量也减少了约 20%,线程切换次数减少 40%,整体系统负载更加均衡。

