




见字如面,我是一臻 90后新手奶爸,探索Doris x AI
90后新手奶爸,探索Doris x AI
点击关注 👇 免费获取数字AI知识库
❝某天晚上11点,小美正准备洗洗睡了,突然看到数据群里有人发了个JSONBench的榜单链接。
作为一位在大数据圈摸爬滚打了8年的程序媛,她的职业病又犯了——每次看到性能测试排行榜,总是先找找Apache Doris在哪个位置。
榜单上,Doris默认配置排第三,前面是ClickHouse的两个版本。她松了一口气,Doris至少没有太丢人。
可是转念一想,这就满足了吗?作为一名资深Doris用户,她总觉得还能再榨一榨...

十亿条JSON数据的较量
JSONBench(https://jsonbench.com/
)是个什么东西?
简而言之,就是用十亿条真实生产环境的JSON数据,跑5个特定的SQL查询,看看谁家的数据库处理半结构化数据更牛逼。
榜单上有ClickHouse、MongoDB、Elasticsearch、DuckDB、PostgreSQL...这些大家都熟悉的名字。

默认测试结果让人眼前一亮:Doris的性能是Elasticsearch的2倍,是PostgreSQL的80倍。
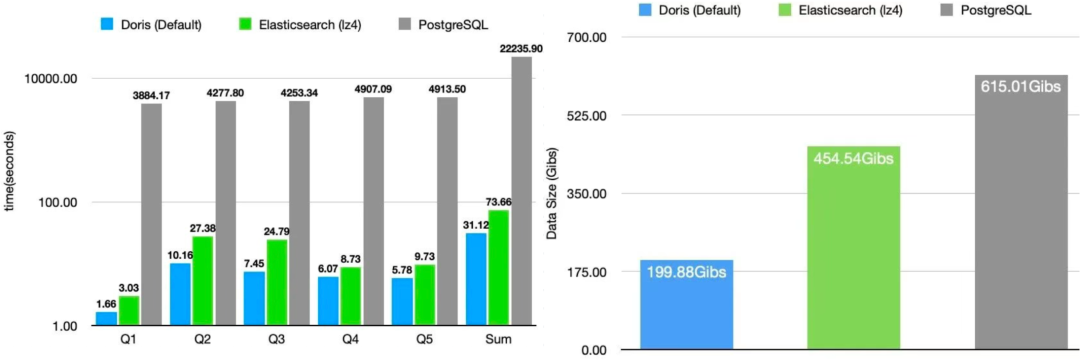
更让人惊喜的是存储占用,Doris只用了Elasticsearch的1/2、PostgreSQL的1/3的空间。
这好比是同样住100平的房子,Doris能放200件家具,Elasticsearch只能放100件,PostgreSQL只能放66件 😄
不甘心的深夜调优
看着榜单,她突然想起了一个朋友的话:"默认配置只能体现产品的基本素质,真正的高手都是在调优中见真章的。
"
于是,她决定找Doris官方反馈,看能不能让Doris的性能再上一个台阶。
最终,Doris社区的伙伴用AWS M6i.8xlarge的机器(32C128G),Ubuntu 24.04,Doris版本是3.0.5
,经过了一夜的操作猛如虎👇
第一招:Schema结构化处理
JSONBench的查询SQL其实都是固定的提取路径,既然Schema是固定的,那是不是可以用生成列的方式把常用字段提取出来。
1. 查看 JSONBench 特定查询 SQL:https://github.com/ClickHouse/JSONBench/blob/main/doris/queries_default.sqlApache Doris
2. 生成列详情:https://doris.apache.org/zh-CN/docs/3.0/sql-manual/sql-statements/table-and-view/table/ALTER-TABLE-ADD-GENERATED-COLUMN/
可以基于GENERATED ALWAYS
改成了这样:
CREATE TABLE bluesky (
kind VARCHAR(100) GENERATEDALWAYSAS (get_json_string(data, '$.kind')) NOTNULL,
operation VARCHAR(100) GENERATEDALWAYSAS (get_json_string(data, '$.commit.operation')) NULL,
collection VARCHAR(100) GENERATEDALWAYSAS (get_json_string(data, '$.commit.collection')) NULL,
did VARCHAR(100) GENERATEDALWAYSAS (get_json_string(data,'$.did')) NOTNULL,
time DATETIME GENERATEDALWAYSAS (from_microsecond(get_json_bigint(data, '$.time_us'))) NOTNULL,
`data` variant NOTNULL
)
这样做的好处是什么?
原来每次查询都要现场解析JSON,现在直接用结构化的列,速度自然快了不少。
查询SQL也要相应调整,例如这条SQL原来是:
SELECT cast(data['commit']['collection'] AS TEXT ) AS event, COUNT(*) AS count FROM bluesky GROUP BY event ORDER BY count DESC;
现在可以改为:
SELECT collection AS event, COUNT(*) AS count FROM bluesky GROUP BY event ORDER BY count DESC;
简洁多了,性能也提升了!
第二招:Page Cache优化
改完Schema后,开启profile
看执行情况,会发现了一个问题:Page Cache命中率很低,会导致热读测试过程中存在一部分冷读操作。
- CachedPagesNum: 1.258K (1258)
- TotalPagesNum: 7.422K (7422)
这意味着什么?就像你家冰箱太小,买的菜放不下,每次做饭都要跑超市。
于是,把be.conf中的storage_page_cache_limit
从默认的20%调到了60%,重新跑了一遍:
- CachedPagesNum: 7.316K (7316)
- TotalPagesNum: 7.316K (7316)
现在命中率100%了,好比直接把冰箱换成了大容量的,菜全放得下,做饭效率自然高了。
第三招:CPU火力全开
既然是32核的机器,那就就让它全力工作:
// 单个 Fragment 的并行度
set global parallel_pipeline_task_num=32;
直接让原来只用了8个人干活,现在32个人一起上,速度能不快吗❓
技术背后的思考
经过官方这三轮调优,结果让小美都惊讶了:
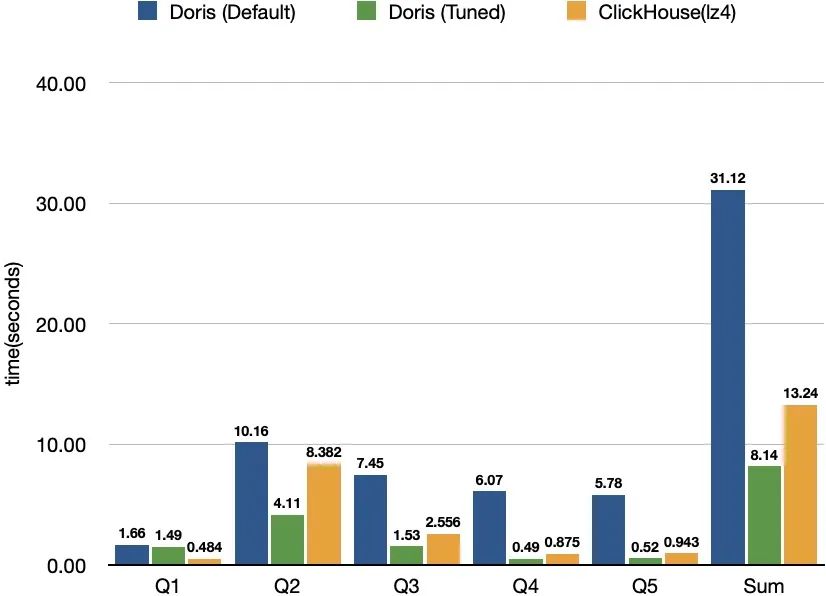
调优后的Doris查询整体耗时降低了74%,比原榜单第一的ClickHouse还要快39%。
这个结果让她想起了一句话:"每个产品都有自己的潜力,关键是你会不会挖掘。
"
从这次调优经历的结果,她也想到了几个问题:
产品的真实实力到底怎么看?
很多人习惯看默认配置的性能测试,就像买车只看厂家公布的油耗。
但真正的用户体验,往往在结合应用场景,调优后才能体现出来。
半结构化数据处理的未来在哪里?
JSON数据在现代应用中越来越普遍,从API响应到日志存储,从用户行为分析到实时监控。
能够高效处理这类数据的系统,将在未来占据重要地位。
工程师的价值在哪里?
工具再好,也需要人去使用。
同样的产品,在不同人手里能发挥出不同的效果。深入理解产品原理,掌握调优技巧,这才是我们的核心竞争力。
Doris在半结构化数据处理方面的表现,让小美对它的未来充满期待。
据说接下来还会有更多优化:
1. 优化 Variant 类型稀疏列的存储空间,支持万列以上的子列;
2. 优化万列大宽表的内存占用;
3. 支持 Variant 子列根据列名的 Pattern 自定义类型、索引等。
届时,Doris在处理复杂JSON数据时的优势将更加明显,也会给大家带来更加优质、高效的分析体验。
结语
深夜的调优让人不禁想起了年轻时写代码的激情,那种不断优化、追求极致的感觉。
技术的魅力就在于,你永远不知道下一次调优能带来多大的惊喜。
这次JSONBench的经历告诉我们,选择工具很重要,但更重要的是知道如何用好它。
Doris的表现确实让人刮目相看,至少在处理十亿条JSON数据这件事上,它已经证明了自己的实力。
现在小美可以很自信地说:看完Doris这份十亿JSONBench的结果,我真的可以忘了ClickHouse,Elasticsearch,PostgreSQL...

完
👇欢迎扫描下方二维码 👇
备注 666 免费领取资料  加入Doris官方群和PowerData数据社区❗️
加入Doris官方群和PowerData数据社区❗️

