




OceanBase 数据库从 V4.1 版本起支持旁路导入的方式向数据库插入数据,该方法支持直接向磁盘文件中直接写入数据的功能,缩短了数据写入通路,从而提高数据的导入效率。
通过为insert 语句加上不同的 hint 条件,最直观地感受旁路导入插入数据和直接插入数据之间,巨大的性能差异。
设计思路
目前,OceanBase主流使用三种导入方式:load data、obloader 和 oms,这些方式都使用 insert 语句将数据写入 OceanBase。
然而,使用 insert 语句写入数据需要经过 SQL、事务和存储。OceanBase 使用 LSM-Tree 结构进行存储。在这种存储结构中,insert 语句会先将数据写入内存表中,然后经过多轮转储和合并,才能最终存入最底层的 SSTable 中。这些过程消耗了大量的系统资源,特别是 CPU 资源,因此导入数据的速度不够理想。
为了加快导入速度,采用了一种绕过中间步骤的技术,将需要导入的数据直接写入最底层的SSTable 中,这种技术称为旁路导入。此外,旁路导入还可以用于加速一些需要大量写入 SQL 的操作例如背景中提到的 insert into select 语句。旁路导入的语法详见官网中几个相关的语法,例如 loaddata。
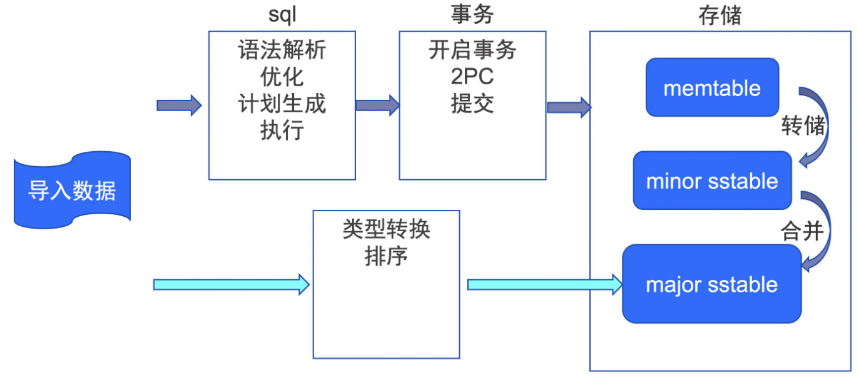
根据上图所示,数据导入可采用两种路径:
- 上方深蓝色箭头所示的传统路径需要经过 SQL查询、事务处理、数据存储等一系列模块。
- 下方的浅蓝色箭头所示旁路导入路径主要是对导入的数据进行类型转换(按需),然后按照主键进行排序(按需),最后将排序后的数据直接写入到major sstable 中。
旁路导入是一条短路径,能减少不少系统资源消耗,加快导入速度。(上图中的LSM-tree 指的是Log-Structured Merge Tree,一种基于内存和磁盘的数据结构,用于高效地插入、删除和查询大量数据。SSTable 指的是 Sorted String Table,一种有序、持久化存储数据的数据结构,可支持高效的读写操作和范围查询)
实现原理
旁路导入是利用 DDL 来实现的,可以认为是一种特殊类型的 DDL。所以主要的执行流程和 DDL类似(DDL的实现原理可以详见夏进的这篇博客《OceanBase Alter Table 原理介绍》),旁路导入的实现分为了几个步骤:
1.创建一张 hidden table(隐藏表),用于导入数据。
2.给原表和 hidden table 加表锁。
3.把原表的数据和新导入的数据合并后写入 hidden table 中。
4.在 hidden table 中重建原表的索引和外键。
5.交换原表和 hidden table 的 table_id(如果中间任何一步出现错误,不交换 table id 就可以保证原子性,只有当全部步骤都成功,才会交换 tableid)。
6.解表锁。
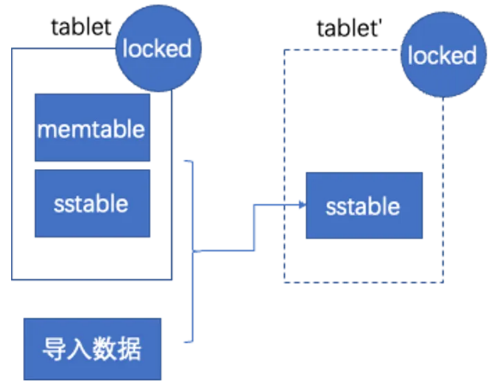
如果原表不是空表,已经有一些数据了,就会把原表里的数据和导入数据一起整合到 hidden table 里面。
例如下图中 tablet 是原表的 tablet,tablet'是 hidden table 的 tablet,旁路导入会把原表的memtable、sstale,以及导入的数据一起归并到新的 hidden table 里。
例如通过 load data 命令进行旁路导入,整体的数据流向是:类型转换、根据分区键转发到对应节点、在节点上按需进行排序,最后写入 major sstable。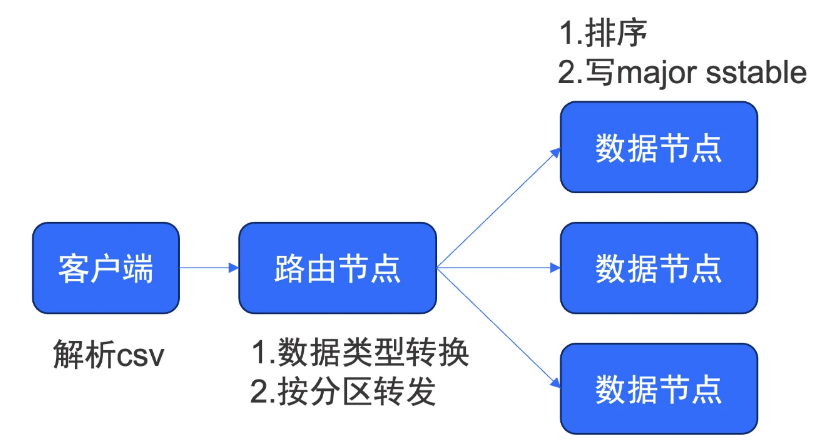
对数据类型转换的优化、数据排序、解析 csv 等过程都做了大量的优化。对于数据类型转换:例如 csv 文件里的内容是 string,但是实际的列类型是 number(在 MySQL 模式下相当于 decimal),这时候就需要根据 number format 进行一个非常复杂的隐式类型转换,在这里对隐式类型转换中的 to_number 函数最常用的一些 number format 进行了非常极致的短路优化,性能比直接调用 to number 能提升四五倍的样子。
对于数据的排序:
- 因为 OB 都是索引组织表,所以如果对于无主键表,是不需要进行排序的(写入时一个隐藏的.increment pk 列会自动保证有序),直接写入 major sstable 就可以了,这也就是无主键表比有主键表的旁路导入速度还能再快上几倍的原因。
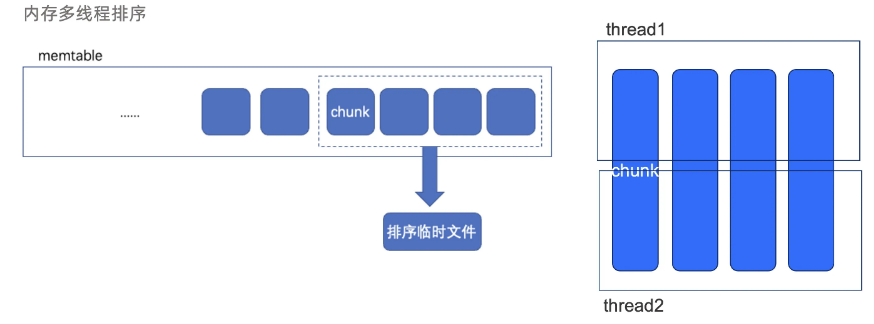
- 对于有主键表,那就不得不按照主键进行排序了,如果输入的数据已经是有序的(例如 csv 文件中的数据就有序),还提供了一个选项,支持用户通过指定要导入的数据是否有序来决定能否进行优化,如果已经有序,内部就只会做归并排序。完全无序时才会走完整的排序流程,无序时为了充分利用内存资源,会对数据进行一个归并的外排,首先先利用最大可用内存对数据进行排序,然后落盘,最后再对磁盘上的各个有序的数据文件进行一个多线程的归并排序,这样不仅可以充分利用内存资源,还可以有效减少落盘的次数。
注意事项
用户在日常使用中,如果不了解目前旁路导入一些要注意的地方,很可能会遇到各种问题,以下就是使用旁路导入时需要注意的几个点:
- 旁路导入期间会加表锁,表无法被写入其他数据,整个过程中表是只读的。
- 全量旁路导入的实现是 DDL 而非 DML(增量旁路导入是 DML),这点要特别留意!
- 按理说 insert into select 可以在事务里面的,但是例如 Oracle 的 DDL如果出现在事务中,就会在 DDL执行结束之后提交事务,然后再继续处理事务中的后面的内容,DDL类似于事务中的一个 barrier。因为 DDL 在事务中的特殊表现,所以暂时不支持旁路导入出现在多行事务中,只能出现在 autocommit 的单行事务中,否则会报错 not supported。
- 还有一个要注意的点是 DDL 框架比较重,导入1行数据可能就需要 2s,所以不适合用于导入量特别小的数据(例如 100M 以下的数据)。
- 由于 DDL 实现逻辑的限制(在 RS 上会有一段儿逻辑需要串行执行),暂时不能很好地支持大规模多条旁路导入并行。比如并发执行几百个普通的insert into select 是没问题的,但是并发执行几百个旁路导入的 insert into select,可能就会有一堆 DDL 排队等着 RS 的调度了。
说明:
当表中已有数据,想要导入增量数据时,可选择增量旁路导入功能来完成。虽然通过全量旁路导入能够导入增量数据,但是通过全量旁路导入来导入增量数据的过程将重写所有的原始数据,导入性能不佳。增量旁路导入功能与全量旁路导入不同的是,导入流程将只会操作增量数据,能够保证导入性能。
- 如果租户的内存特别大,或者说数据量比 memtable 还要小,那内存的 memtable 就能兜住全部要导入的数据,旁路导入可能就没啥优势了。因为旁路导入是要写磁盘的,肯定比不过只写内存不需要转储、合并的场景。
- 原表和 hidden table 交换 table id 以后,这个是一个 schema 操作(或者叫类 DDL 操作),会导致所有和这个表有关的 plan cache 全部失效,执行计划需要重新生成。
- 使用 INSERTINTO SELECT 语句旁路导入数据时,只支持 PDML(Parallel Data ManipulationLanguage,并行数据操纵语言),非PDML不能用旁路导入,详见:官网文档。
总结
0B 目前的旁路导入功能,最适用于:
1.大表的首次导入场景;
2.10 GB~TB 级别的数据迁移场景;
3.还有就是 CPU 和 内存都不是特别充裕的场景。因为旁路导入的执行路径很短,可以省掉非常多的CPU 开销。
实验
OceanBase 数据库 V4.2.1,以 MySQL 模式为例。
实操服务器配置:单机版下 2C8G 。数据导入的效率会因为环境和机器规格不同而有所差异。
1. 连接数据库
使用 test 用户登录
obclient -h127.0.0.1 -utest@sys -P2881 -Dtestdb -A
--参数说明
testdb 数据库已预建完成,不需要手动创建。
test 用户拥有管理权限,已预授权。2. 创建测试表 t1、t2、t3
create table t1(c1 bigint,c2 bigint);
create table t2(c1 bigint,c2 bigint);
create table t3(c1 bigint,c2 bigint);3. 设置超时时间
set ob_query_timeout = 1000000000;4. 在 t1 表内生成 1000W 条随机数据
insert into t1 select uniform(1,10000000,RANDOM()),uniform(1,10000000,RANDOM()) from table(generator(10000000));5. 使用普通 insert into 语句把 t1 表内数据插入到 t2 表内,查看执行所需时间。
insert /*+ enable_parallel_dml parallel(8)*/ into t2 select * from t1;输出如下:
obclient [testdb]> insert /*+ enable_parallel_dml parallel(8)*/ into t2 select * from t1;
Query OK, 10000000 rows affected (4 min 28.402 sec)
Records: 10000000 Duplicates: 0 Warnings: 0通过上述执行结果可知,此语句执行时间耗时 4分钟左右。
6. 使用旁路导入 insert into 语句把 t1 表内数据插入到 t3 表内,查看执行所需时间。
insert /*+ append enable_parallel_dml parallel(8)*/ into t3 select * from t1;输出如下:
obclient [testdb]> insert /*+ append enable_parallel_dml parallel(8)*/ into t3 select * from t1;
Query OK, 10000000 rows affected (47.397 sec)
Records: 10000000 Duplicates: 0 Warnings: 0通过上述执行结果可知,此语句执行时间耗时 47秒左右。
