




背景
通常,数据库中的表数据,会存放在数据库自身的存储空间中,而外表的数据,则存储在外部存储服务中。外表可以访问数据库外部的文件,并读取文件中的数据。在一般的业务场景中,经常遇到需要利用数据库处理外部数据的情况。这些数据可能来源于应用程序产生,也可能是由其他业务系统产生。没有外表时,只能通过 ETL工具将外部数据库导入到数据库内部的表中,再进行分析处理。而外部表可以直接读取外部数据文件,这样做有几个好处:
- 可以减少数据的拷贝,节省数据库存储空间。
- 提高数据的共享,避免数据出现不一致的情况。
- 删除外表时数据不会被删除。
- 外表不支持 DML。
外部表相比普通表具有更丰富的功能:
- 支持多种存储方式:例如数据文件可以放在不同云服务的对象存储服务中。
- 支持多种存储格式:例如 CSV 等格式。
注意事项:
- 当外部文件被删除。
外表访问文件列表中的文件将会不存在,这种情况发生时,外表会忽略不存在的文件。
- 当外部文件被修改。
外表访问外部文件的最新的状态。当外部文件修改与外表查询并发时,可能会产生不符合预期的结果,需要避免在查询外表的同时修改外部文件。
- 当外部目录下有新增文件。
外表仅会访问文件列表中的文件,如果需要将新增文件添加到外表的文件列表中,需要执行“更新外表文件”操作。
示例
创建外部表法一:存放外部数据文件在对象存储服务中
通过外表读取 OceanBase 日志的小 demo,可快速理解外表的作用。
首先来到 OceanBase 的日志目录,里面有一些以 .log 结尾的文件。
外表的数据文件可以放在不同云服务的对象存储服务中。

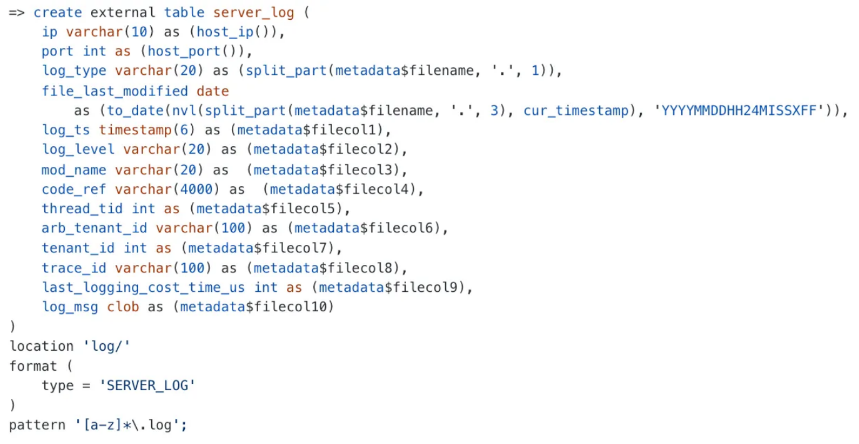
然后创建一张外表。
目前 OceanBase 支持 CSV、PARQUET、ORC 这几种常用文件格式。
 创建好外表之后,就可以像普通表一样进行查询了~
创建好外表之后,就可以像普通表一样进行查询了~

说明:
上面 demo 中的 SERVER_LOG 只是用来作为 demo 示例,并非正式发布的版本中支持的文件格式。
外表可以像普通表一样,与其他表进行链接、聚合、排序等,外表与普通表的差异如下:
- 外表的数据存储在外部文件中,普通表的数据存储在数据库中。
- 外表是只读的,可以在查询语句使用,但不能执行 DML操作。
- 外表不支持添加约束和创建索引。
通常来说,外表的访问速度会慢于普通表。
创建外部表法二:借助hive表
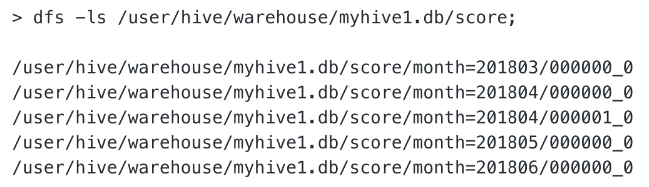
Hive 中的表

Hive 分区表存储的目录结构:
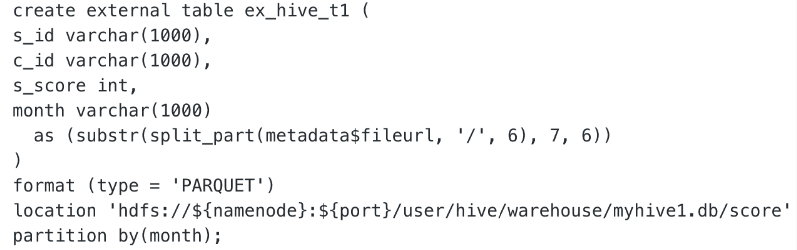
通过外表读取 Hive 的数据:
性能测试示例
下面对外表进行简单的性能测试,以本地文件场景和 CSS 文件场景为例,测试环境如下:
CPU Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz
DATA:TPCH 1G 的文本文件,文件格式 CSV,每个表的数据拆成 10 个文件
兼容模式:Oracle(社区版虽然没有 Oracle 模式,但区别不大,领会精神即可)
0B 版本:4.2(朝花夕拾版)
场景 1:本地文件场景
串行扫描
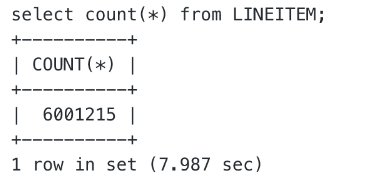
并行扫描
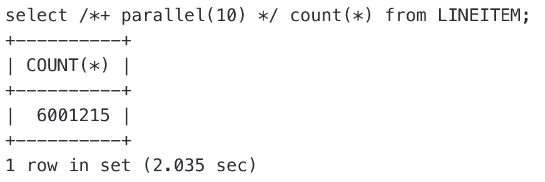
场景 2:OSS 文件
串行扫描
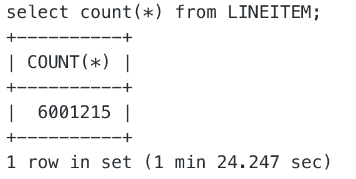
并行扫描
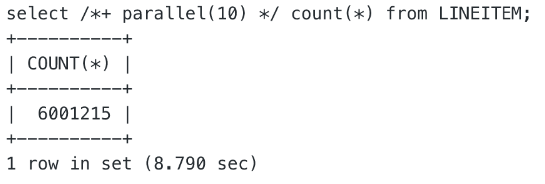
其他复杂 SQL 的场景示例
示例 1
外表可以像普通表一样与其他表进行链接,谓词过滤,聚合,排序等操作。外表可以通过 parallel hint 开启并行查询。下面例子中,customer/orders/lineitem 均为外表

示例 2
外表可以与普通表组合进行查询操作。
下面例子中,temp 是普通表,orders 是外表。

示例3
外表可以实现将外部数据导入普通表的操作。
下面例子中,lineitem import 为普通表,lineitem 为外部表,通过 PDML功能可以将外表 lineitem 数据并行导入普通表 lineitem_import.

外部表的用法
准备外部表数据
在阿里云的对象存储 OSS 中存放了 TPCH 1G 的数据,其中 lineitem 的表的数据分成了 10 个文件放在 mydata/tpch 1g data/lineitem 中。
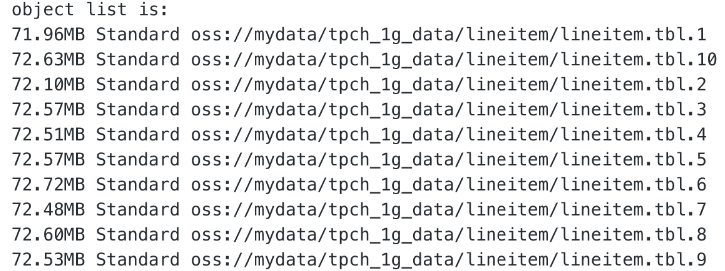
创建外表
外表的用法和普通表非常相似,比普通表多了 LOCATION 和 FORMAT 属性。其中 LOCATION 用于指定数据文件所在位置,FORMAT 指定数据文件的格式。

如果文件中的列顺序和表中的列顺序不一致,可以通过通过 metadataSfilecolN 伪列进行对应。
查看外表的文件
外表创建时,会将 LOCATION 下的文件列表保存在一个文件列表中,外表扫描时只会访问这个列表下的外部文件。通过以下语句可以查看外表的文件列表:

当外部数据文件有变化时,可以执行以下语句更新外表的文件列表。

如果文件被删除且未更新文件列表,外表查询时会自动忽略这个文件。
查询外表
外表查询时,通过外表的驱动层直接读取外部文件,并按照文件格式进行解析,转换成 OceanBase 内部的数据类型后返回数据行。

附:外表文件格式
CSV

Parquet /ORC
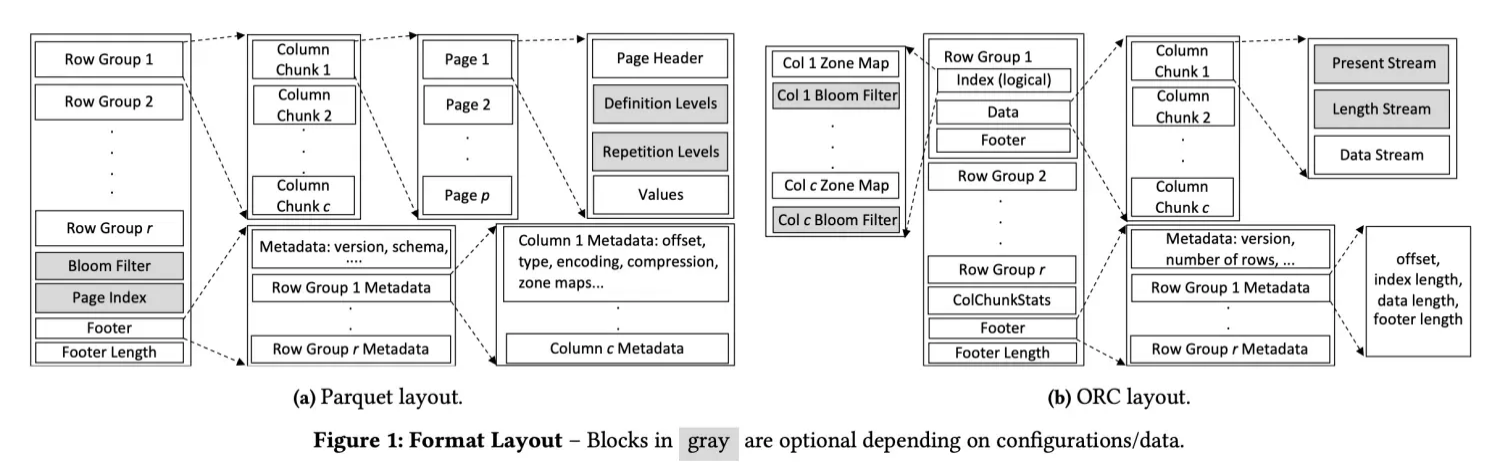
嵌套数据类型的 Schema
Parquet 是一个由 Google Dremel 格式启发而来的列存格式,在大数据领域通常作为存储格式,被iceberg 等湖、各种查询引擎能够合理的使用。
Parquet schema模型能比较简洁处理嵌会和重复。嵌会关系用“属性组”(groups)表示,重复属性用"重复度"(repeated field)表示。一个属性的"重复度"可以有几种定义:
- required:刚好出现一次
- optional:出现0或1次
- repeated:出现0或多次
Parquet 存储数据的例子:
假如有 schema 是:
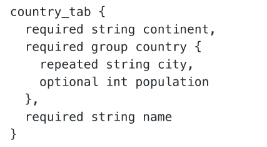
country_tab 记录包含 continent、countny、name三个属性,其中country是一个属性组,包含 city、population两个属性。city是一个repeated 字段,因此可以有多个值,从而表达了数组。
存储下面一行数据:

其中,city 是个数组,数组中元素可以是任意个,假设 population 可能是未知的,可以被设置为NULL,其他属性都是不能为 NULL 的。
Parquet 认为以上 schema 有4列(仅存储叶子结点)
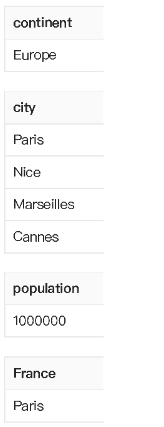
假如有 2 行数据,因为一行中的数据可以 repeat,也可以为 nul,如何区分一个 column chunk 中的数据到底是属于哪一行的?
通过数据上定义的 defination level 和 repetitive level.
类似地,Maps,List or Sets 都可以用重复和属性组(groups+repeated field)表达出来。
相比之下,ORC 使用一个单独的 bitmap 来存储节点是否存在,比较容易理解。
1. Struet 只记录 Struet 本身的 PRESENT。
2. List = Present Stream + Length Stream.
3.Map = Map 等价于一种很奇怪的 List 和 List 表现一样,但后面有一组 Key 一组 Value。
4.Union 分成 PRESENT+Tag,后面接不同种类的 Stream。

课堂实操
准备工作
创建存放外部数据目录
mkdir -p /home/admin/external_table_files
cd /home/admin/external_table_files创建存放外部数据数据
cat data1.csv
1,"lin",98
2,"hei",90
3,"ali",95通过本地 Unix Socket 连接集群的 MySQL 租户
在 OBserver 节点上,通过本地 Unix Socket 连接集群的 MySQL 租户。
obclient -S /home/admin/oceanbase/observer/run/sql.sock -utest@sys -Dtestdb -A通过本地 Unix Socket 连接 OceanBase 数据库的具体操作及说明,可参见 secure_file_priv。
配置数据库可以访问的路径
SET GLOBAL secure_file_priv = "/home/admin/external_table_files/";注意:命令执行成功后,需要重启会话后,修改才能生效。
重新连接数据库
使用 test 用户登录
exit
obclient -h127.0.0.1 -utest@sys -P2881 -Dtestdb -A
--参数说明
testdb 数据库已预建完成,不需要手动创建。
test 用户拥有管理权限,已预授权。创建外表
CREATE EXTERNAL TABLE ext_t1(id int, name char(10),score int)
LOCATION = '/home/admin/external_table_files/'
FORMAT = (
TYPE = 'CSV'
FIELD_DELIMITER = ','
FIELD_OPTIONALLY_ENCLOSED_BY ='"'
)
PATTERN = 'data1.csv';查询外表
场景1:普通查询
select * from ext_t1;输出如下:
obclient [testdb]> select * from ext_t1;
+------+------+-------+
| id | name | score |
+------+------+-------+
| 1 | lin | 98 |
| 2 | hei | 90 |
| 3 | ali | 95 |
+------+------+-------+
3 rows in set (0.004 sec)问题处理
问题描述:创建外部表后查询提示ERROR 9731 (HY000): insufficient privileges to do direct path access
obclient [testdb]> select * from ext_t1;
ERROR 9731 (HY000): insufficient privileges to do direct path access问题原因:配置数据库可以访问的路径后未重启库
解决办法:退出重新登录后查询正常。
场景2:外表之间进行组合查询
外表可以通过 parallel hint 开启并行查询
创建存放外部数据文件
创建 data2.csv 文件用于存放外部数据。
cd /home/admin/external_table_files
cat data2.csv
1,"aaa",100
2,"bbb",80
3,"ccc",90
4,"aaa",60
5,"bbb",39
6,"ccc",75
7,"aaa",90
8,"bbb",100
9,"bbb",50连接数据库
obclient -h127.0.0.1 -utest@sys -P2881 -Dtestdb -A创建外表 ext_t2
CREATE EXTERNAL TABLE ext_t2(id int, name varchar(10),score int)
LOCATION = '/home/admin/external_table_files/'
FORMAT = (
TYPE = 'CSV'
FIELD_DELIMITER = ','
FIELD_OPTIONALLY_ENCLOSED_BY ='"'
)
PATTERN = 'data2.csv';ext_t1 与 ext_t2 关联查询
SELECT /*+ parallel(10) */
ext_t2.id,ext_t2.name,ext_t2.score
FROM ext_t1,
ext_t2
WHERE ext_t2.name = 'aaa'
AND ext_t2.id= ext_t1.id
AND ext_t2.score >90
ORDER BY ext_t2.score DESC, ext_t2.id;输出如下:
+------+------+-------+
| id | name | score |
+------+------+-------+
| 1 | aaa | 100 |
+------+------+-------+
1 row in set (0.077 sec)通过外表将外部数据导入普通表
ext_t3 为普通表,ext_t1 为外部表,通过 PDML 功能可以将外表 ext_t1 数据并行导入普通表 ext_t3。
创建普通表 ext_t3
CREATE TABLE ext_t3(id int, name char(10),score int);外表数据插入 ext_t3 中
INSERT /*+ enable_parallel_dml parallel(10) */ INTO ext_t3
SELECT * FROM ext_t1;场景1:查询 ext_t3 数据
select * from ext_t3;输出如下:
obclient [testdb]> select * from ext_t3;
+------+------+-------+
| id | name | score |
+------+------+-------+
| 3 | ali | 95 |
| 2 | hei | 90 |
| 1 | lin | 98 |
+------+------+-------+
3 rows in set (0.004 sec)场景2:外表与普通表组合进行查询
ext_t3 是普通表,ext_t1 是外表。
SELECT ext_t3.* from ext_t3, ext_t1 WHERE ext_t3.id = ext_t1.id limit 2;输出结果如下:
+------+------+-------+
| id | name | score |
+------+------+-------+
| 1 | lin | 98 |
| 2 | hei | 90 |
+------+------+-------+
2 rows in set (0.005 sec)