




导读
我们之前已经介绍了3种row_format格式:REDUNDANT,COMPACT,DYNAMIC. 现在来讲最后一种:COMPRESSED
有的小伙伴可能会疑惑之前不是讲过压缩吗? 就那个zlib和lz4那俩啊. 那俩是PAGE级别的压缩,除了FSP的’page’都压; 今天讲的是行级别的压缩,只压缩’行’.
行压缩的结构
行格式为压缩的表的创建方式
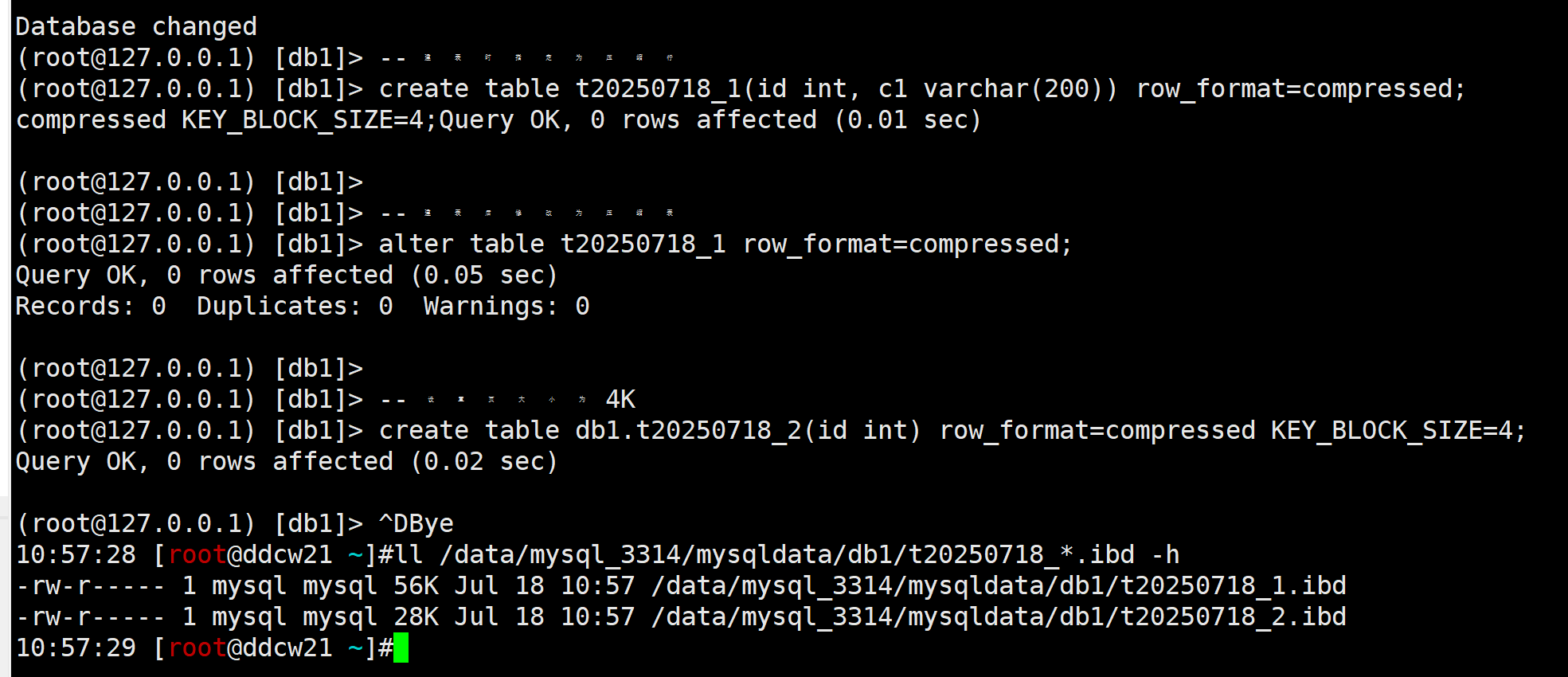
-- 建表时指定为压缩行
create table t20250718_1(id int, c1 varchar(200)) row_format=compressed;
-- 建表后修改为压缩表
alter table t20250718_1 row_format=compressed;
-- 设置页大小为4K
create table db1.t20250718_2(id int) row_format=compressed KEY_BLOCK_SIZE=4;
很简单, 就是执行row_format=compressed.
我们知道Innodb会对表初始分配7个page, 8K的page大小就为56K, 4K的page大小为28K, 所以对于16384的page压缩默认是8K
既然叫行的压缩, 那压缩的肯定就算数据行, 也就是只对FIL_PAGE_INDEX有效. 诶, FIL_PAGE_SDI 也算是FIL_PAGE_INDEX的变种啊, 相当于固定结构的表而已.
既然表元数据信息都可能是压缩的了, 那问题来了, 怎么确定这个表是压缩的呢?
总不能一点点猜吧…
确认表的压缩大小
既然元数据信息被压缩了, 那我们就找更元的元数据信息–FSP, 这个页不会被加密和压缩的. 其中有个叫FSP_SPACE_FLAGS的东西, 如下图::
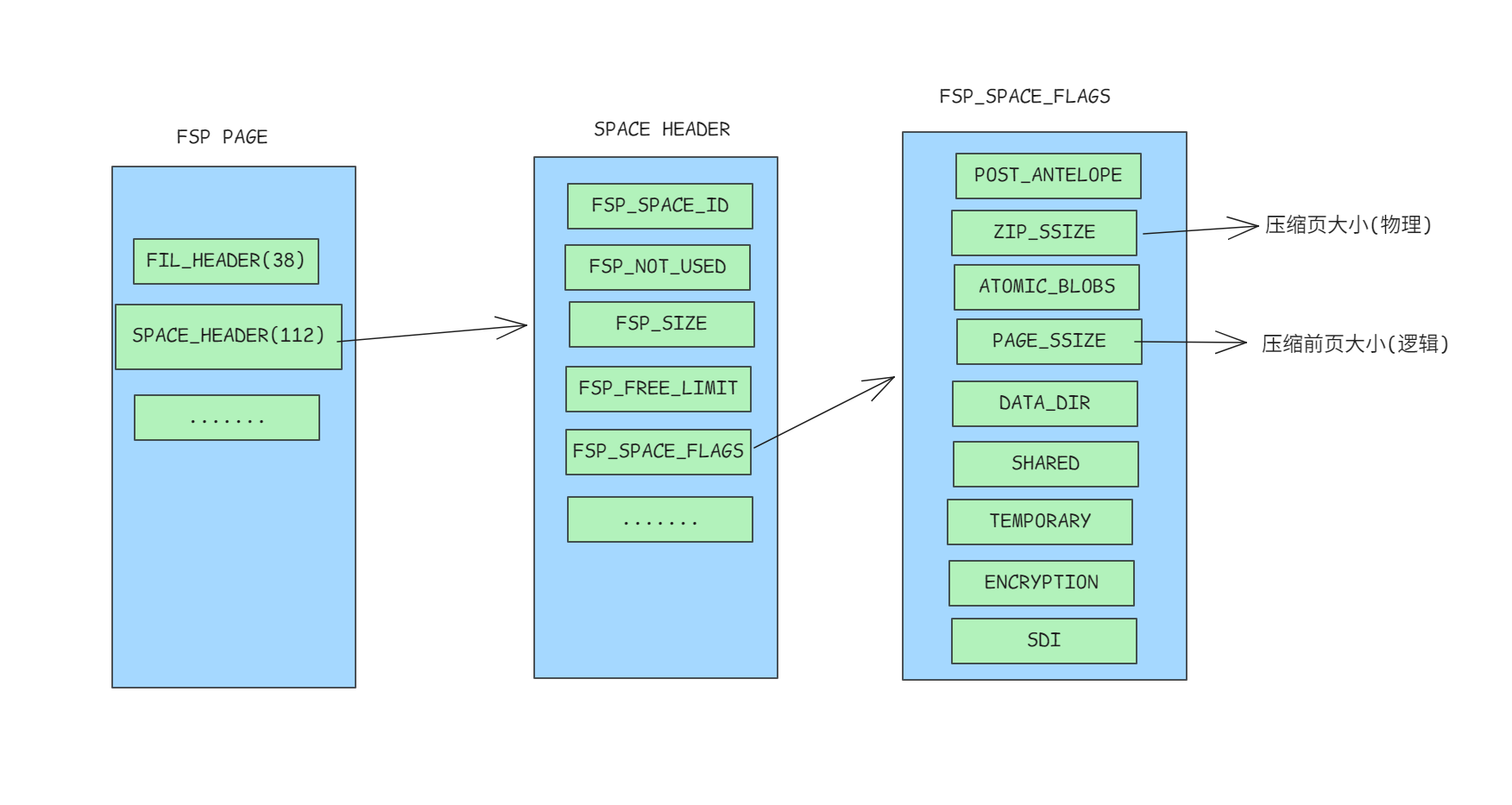
对于计算方式可参考如下py代码(include/fsp0types.h):
def GET_FSP_STATUS_FROM_FLAGS(flags):
logical_size = 16384 if ((flags & 960) >> 6) == 0 else 512 << ((flags & 960) >> 6)
physical_size = logical_size if ((flags & 30) >> 1) == 0 else 512<<((flags & 30) >> 1)
compressed = False if ((flags & 30) >> 1) == 0 else True
return {
'POST_ANTELOPE':(flags & 1) >> 0,
'ZIP_SSIZE':(flags & 30) >> 1,
'ATOMIC_BLOBS':(flags & 32) >> 5,
'PAGE_SSIZE':(flags & 960) >> 6,
'DATA_DIR':(flags & 1024) >> 10,
'SHARED':(flags & 2048) >> 11,
'TEMPORARY':(flags & 4096) >> 12,
'ENCRYPTION':(flags & 8192) >> 13,
'SDI':(flags & 16384) >> 14,
'logical_size':logical_size, # logical page size (in memory)
'physical_size':physical_size, # physical page size (in disk)
'compressed':compressed
}
这里的ZIP_SSIZE就是实际上在磁盘上存储的大小, 使用4bit表示(512一个block). 比如值为4时, 物理块大小就为: 512<<4(8192), 即磁盘上的块大小为8192.
PAGE_SSIZE就是逻辑大小, 也就是innodb_page_size. 数据解析的时候, 我们先要把压缩后的大小(ZIP_SSIZE)解压到压缩前的大小(PAGE_SSIZE) 然后就可以当作普通页(DYNAMIC)来处理了.
压缩行结构
如果每次数据更新我们都要压缩和解压的话, 成本有点高啊.
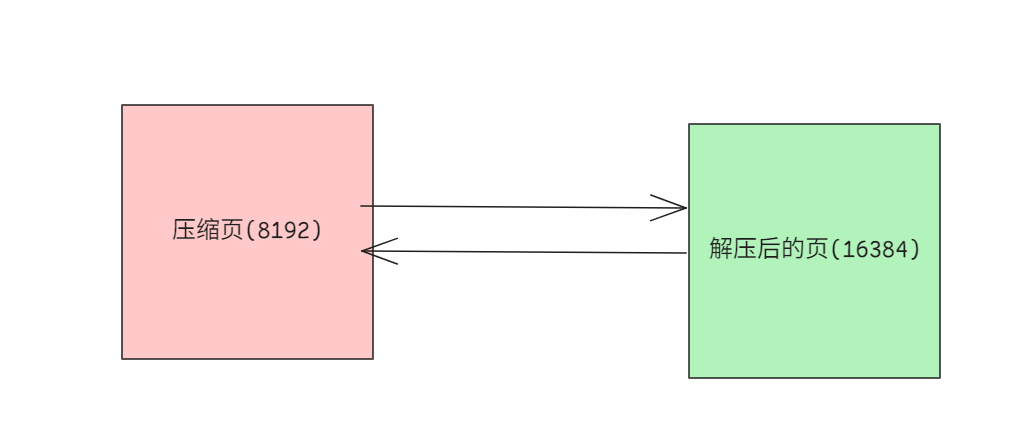
所以应该只压缩其中的一部分数据,
新insert进来的, 就直接放压缩数据后面, 待空间不够之后再去压缩.
而要删除的数据也是应该只打标记即可. 于是我们翻阅源码(page_zip_decompress_low)后得到如下结构:
| 对象 | 大小 | 描述 |
|---|---|---|
| FIL_HEADER+PAGE_HEADER | 94 | 页基础信息 |
| compressed_data | x | 压缩的数据 |
| uncompressed_data | y | 未压缩部分的数据 |
| … | 未使用的空间 | |
| overflow page | 20*m | 溢出页的记录信息, 还是每条20字节 |
| trx_id+rollptr | 13*n | 事务和回滚指针相关信息 |
| page diretory | 2*n | page dir信息 (基于压缩前的页) |
看起来合情合理, 那我们简单的验证下呢.
验证压缩行结构
我们就没必要把页大小还原回去了. 我们直接开解:
先准备测试数据
create table db1.t20250718_compressed(c1 int, c2 varchar(20), c3 text) row_format=compressed;
insert into db1.t20250718_compressed values(1,'xx','yy');
insert into db1.t20250718_compressed values(1,'zz',repeat('a',10000));
然后使用python来打开ibd文件并解析. 先看下fsp中的FSP_SPACE_FLAGS的相关信息
# 声明 GET_FSP_STATUS_FROM_FLAGS 略(见上文)
import struct,zlib
f = open('/data/mysql_3314/mysqldata/db1/t20250718_compressed.ibd','rb')
data = f.read(38+112)
FSP_SPACE_FLAGS = struct.unpack('>L',data[38+16:][:4])[0]
print(GET_FSP_STATUS_FROM_FLAGS(FSP_SPACE_FLAGS))
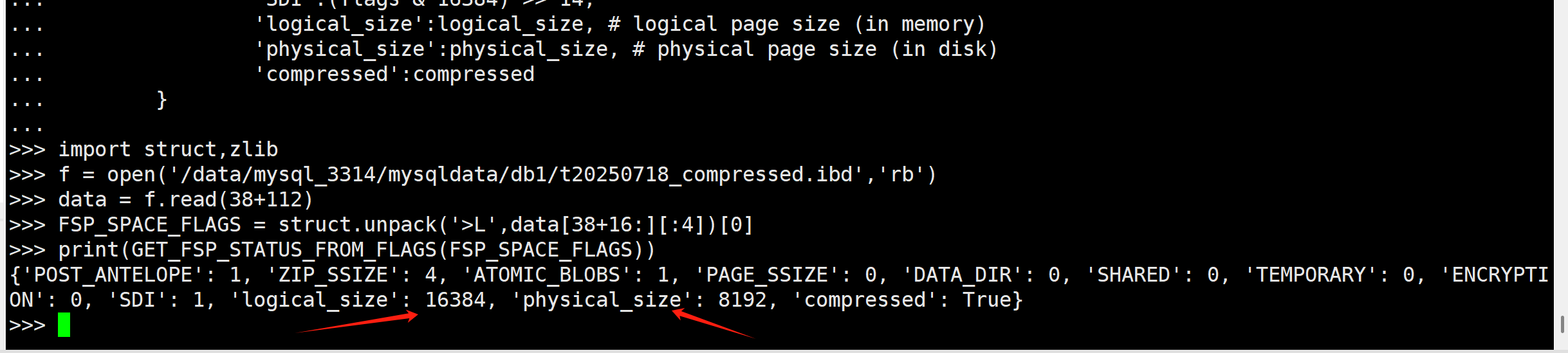
我们可以看到:物理页大小是8K, 逻辑页大小是16K, 存在sdi信息…
然后我们来解析数据, 由于我们不知道压缩的数据大小, 所以我们得基于流来解析,故使用zlib.decompressobj
f.seek(8192*4,0)
data = f.read(8192)
d = zlib.decompressobj()
c = d.decompress(data[94:])
# 初始化基础页信息
unpage = data[:94]
# infimum & supremum
unpage += struct.pack('>BBB',0x01,0x00,0x02)
unpage += data[-2:]
unpage += struct.pack('>8B',0x69, 0x6e, 0x66, 0x69, 0x6d, 0x75, 0x6d, 0x00)
unpage += b'\x03'
unpage += struct.pack('>12B',0x00,0x0b,0x00,0x00,0x73,0x75,0x70,0x72,0x65,0x6d,0x75,0x6d)
# 加上压缩页信息
unpage += c
# 加上未压缩部分的信息
unpage += d.unused_data
# 解析page dir信息:
n_dense = struct.unpack('>H',data[42:44])[0] & 32767
page_dir = struct.unpack(f'>{n_dense-2}H',data[-(2*(n_dense-2)):])
print(page_dir )
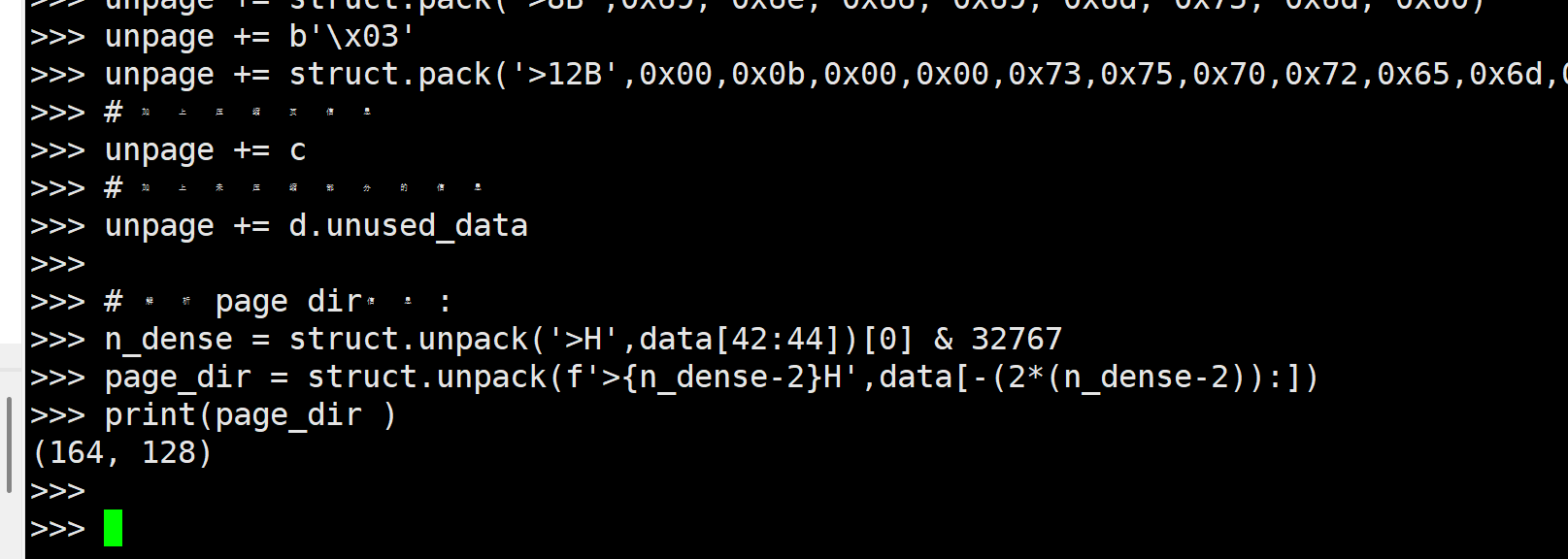
看到了熟悉的offset, 这里的page dir是记录的所有行(不含infimum & supremum)的偏移量. 然后我们来解析trxid和rollptr
# trxid&rollptr
trxid_rollptr_data = data[-(2*rows+13*rows):-(2*rows)]
for i in range(rows):
print(int.from_bytes(trxid_rollptr_data[i*13:][:6],'big'),int.from_bytes(trxid_rollptr_data[i*13:][6:13],'big'))

这部分信息其实没多大用…
然后我们再来看数据
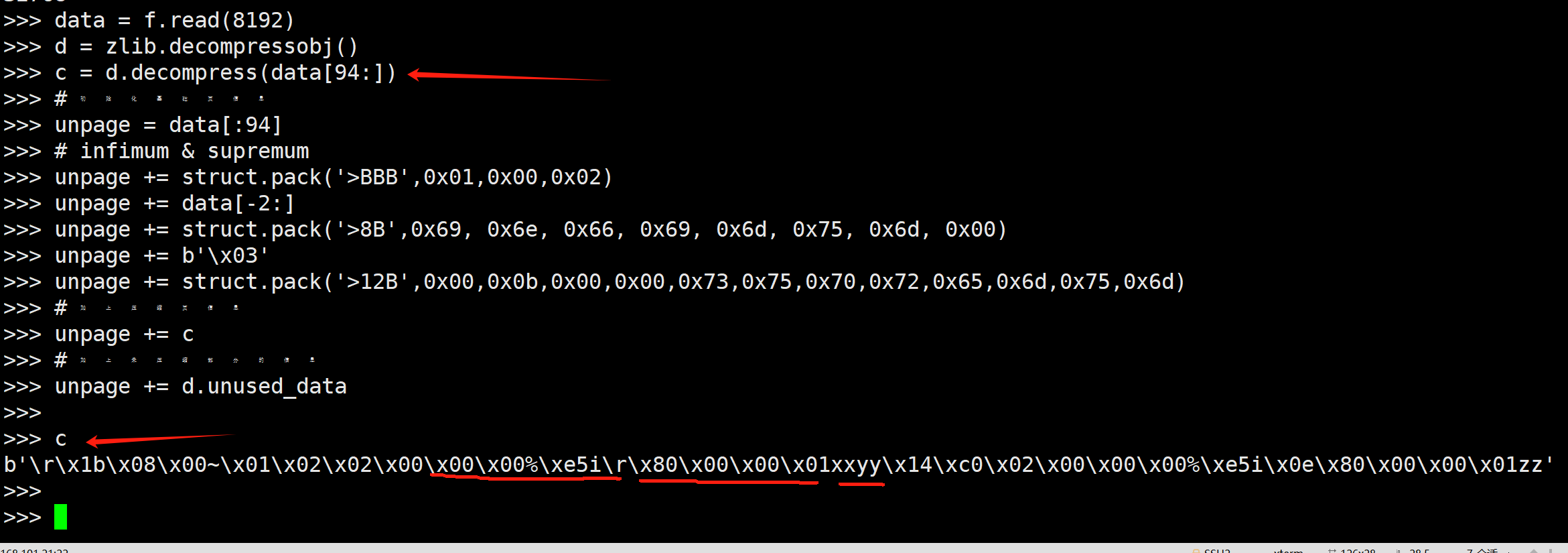
f.seek(8192*4,0)
data = f.read(8192)
d = zlib.decompressobj()
c = d.decompress(data[94:])
# 初始化基础页信息
unpage = data[:94]
# infimum & supremum
unpage += struct.pack('>BBB',0x01,0x00,0x02)
unpage += data[-2:]
unpage += struct.pack('>8B',0x69, 0x6e, 0x66, 0x69, 0x6d, 0x75, 0x6d, 0x00)
unpage += b'\x03'
unpage += struct.pack('>12B',0x00,0x0b,0x00,0x00,0x73,0x75,0x70,0x72,0x65,0x6d,0x75,0x6d)
# 加上压缩页信息
unpage += c
# 加上未压缩部分的信息
unpage += d.unused_data

我们的压缩数据部分为啥只有个b'\r\x1b\x08\x00~\x01'呢? 这也不是我们的数据啊!
前面有讲: Insert部分数据会先先非压缩部分, 不然每次都解压又压缩的, 成本老高了.
那这6字节是啥呢? 你猜(提示:可以更改表结构,数据类型来观察其变化)
如果此时我们重新设置表row_format=compressed,则会将之前未压缩部分的数据进行压缩.
alter table db1.t20250718_compressed row_format=compressed;
细心的小伙伴可能会发现压缩前每行数据前面好像有个 ID/NO 之类的东西, 但是压缩进来后就没了
溢出页我们就不看了, 格式是和DYNAMIC一样的, 只是存储的位置换到了rollptr位置处.
总结
mysql有2种压缩方式, 1种是基于行的(row_format=compressed),另一种是基于page的(compression=zlib/lz4); 后者需要OS的文件系统支持才行. 当然我们的ibd2sql下个版本也会支持这种格式的.

参考:
https://dev.mysql.com/doc/refman/8.0/en/innodb-row-format.html
https://github.com/mysql/mysql-server/tree/trunk/storage/innobase
