




阿玛拉定律(Amara's Law)
阿玛拉定律,这个很有名,经常被人提起,是由美国未来学家**罗伊·阿玛拉(Roy Amara)提出,其核心观点为:“人们倾向于高估技术的短期影响,而低估其长期影响。”
(英文表述:We tend to overestimate the effect of a technology in the short run and underestimate the effect in the long run.)
为什么开篇先说一个定律,做一些重复性的事情,比如自己做过了,或者别人做过了。做这些工作,需要的是经验。
如果创新到一定境界,就需要回到本源,哲学就比较重要了。搞技术足够深入,往往喜欢谈论或者思考哲学不无道理。
大模型时代的高估和低估
回到大模型这个领域,我们也会发现,存在同样的问题。
一开始,大家会对这个领域特别兴奋,觉得是另外一个互联网时代的开启之类的。随着应用过程中碰到的各种问题,以及预期的AGI 没能到来,浇灭了很多人对大模型的热情。
但是我们认真看下,大模型其实在切切实实重构和颠覆现在的架构和技术。今天我给大家梳理下,最新的变化和发展。
下面这个图是抽象的技术架构,红色是关键变化
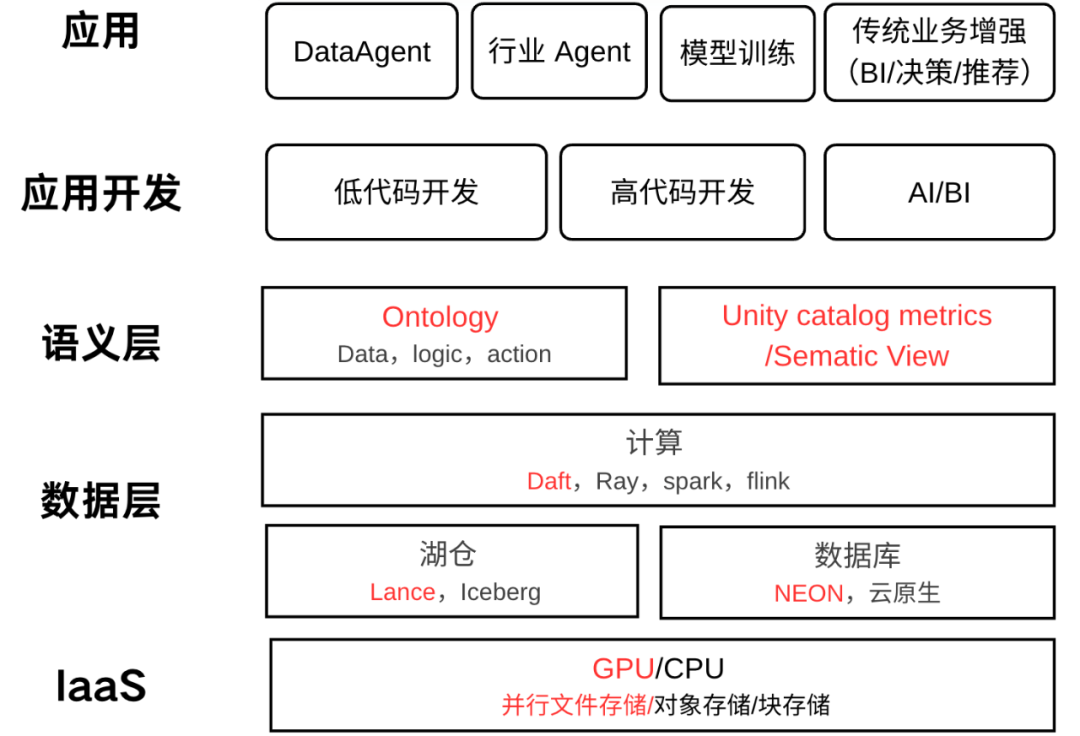
新的变化
我们从底下往上讲。
1、 IaaS:传统基础设施,主要是 CPU,块存储,对象存储。今天大模型关键的技术栈是 GPU,并行文件系统。
2、数据层:诞生了新的技术框架,存储格式和新的数据库范式。
2.1、Daft 是更原生的多模态数据库处理框架,Daft的强大之处在于它是Python原生的开源数据处理引擎,专门设计用于快速处理从文本到音频和视频等不同模态的数据。
2.2、Lance:多模态湖仓存储,原生支持向量。LanceDB 的 “多模态湖仓一体平台(Multimodal Lakehouse)”来实现。该平台基于开源的 Lance 格式构建,是专为 AI 设计的统一引擎,支持存储、检索和计算所有多模态数据。
2.3、Lakebase:databricks 收购了 NEON,合入 databricks 整体技术栈,重新命名为 Lakebase。这些新的数据库核心接近的是数据库是 Agent 创建和管理,支持 instance branch 等功能,天然和上层代码开发体验一致。
3、语义层:大模型的知识是训练的时候是固化的,在解决 2B 场景会力所不及。所以基本上云厂商,各种创业公司都在想办法给大模型提供足够的上下文。其中 Palantir 的 Ontology 抽象最为完善,通过 Ontology 对业务的数字孪生建模,实现 Data,logic,action 三位一体。不但提供了语义,还能实现决策的闭环。同时这个建模又是人和大模型能理解的,确保 human in the loop,Agent 可以越用越准,效果越来越好。
4、应用开发层:传统应用高逻辑,代码开发为准。面向大模型的新应用,数据驱动为主,所以低代码框架,AI/BI 越发重要。
5、应用层:Agent 成为新的开发范式,基本成为行业共识。传统的一些应用也在部分的被变更或者优化。
展望
新的业务需要底层持续的积累,到一定程度才能爆发。这个苗头,越来越明显了。
