




作者:度假的小鱼
原文链接:https://blog.csdn.net/u014096024/article/details/147722433?spm=1001.2014.3001.5502
了解 KWDB
KWDB 是由开放原子开源基金会孵化及运营的开源项目,是一款面向 AIoT 场景的分布式多模数据库产品,支持在同一实例同时建立时序库和关系库并融合处理多模数据,具备千万级设备接入、百万级数据秒级写入、亿级数据秒级读取等时序数据高效处理能力,具有稳定安全、高可用、易运维等特点。
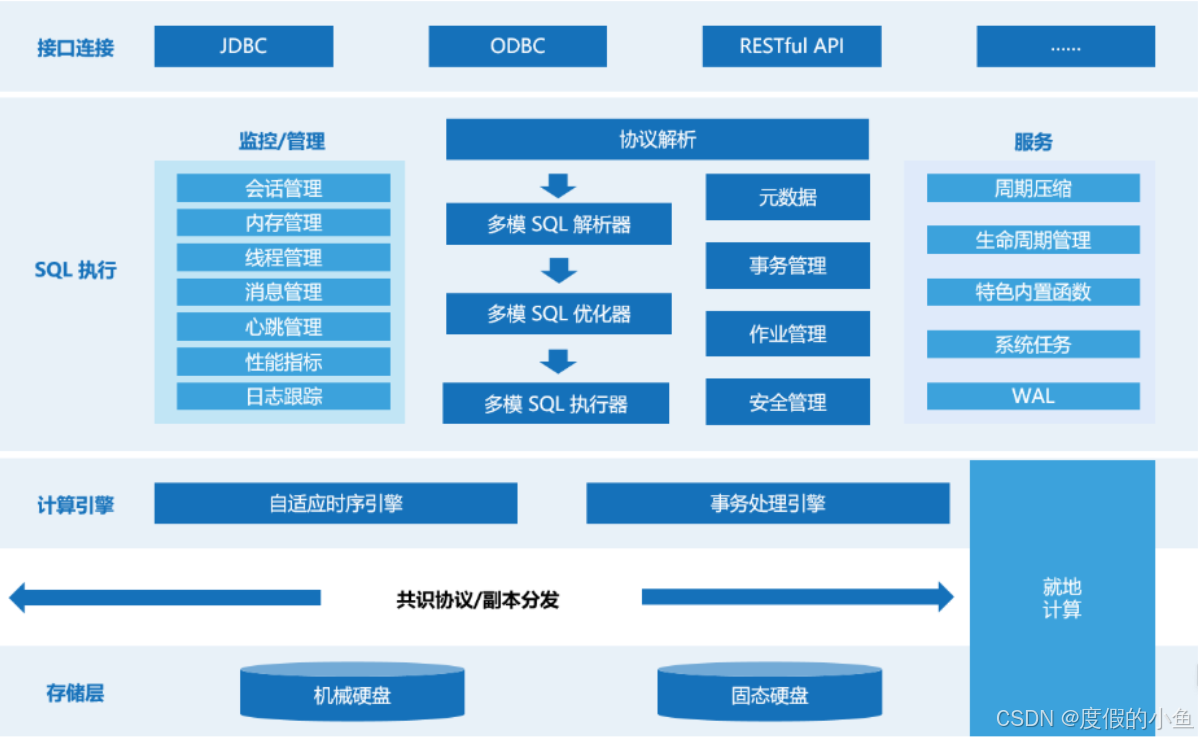
KWDB 基于浪潮 KaiwuDB 分布式多模数据库研发开源,典型应用场景包括但不限于物联网、能源电力、交通车联网、智慧政务、IT 运维、金融证券等,旨在为各行业领域提供一站式数据存储、管理与分析的基座,助力企业数智化建设,以更低的成本挖掘更大的数据价值。
KWDB 为不同角色开发者提供以下支持(包括但不限于):
• 为开发者提供通用连接接口,具备高速写入、极速查询、SQL 支持、随需压缩、数据生命周期管理、集群部署等特性,与第三方工具无缝集成,降低开发及学习难度,提升开发使用效率。
• 为运维管理人员提供快速安装部署、升级、迁移、监控等能力,降低数据库运维管理成本。
关键词:物联网(IoT)、多模数据库、分布式、时序数据处理、云边端协同
1.KWDB数据库安装部署
• 操作系统:支持 Ubuntu 20.04/22.04 LTS 版本、CentOS 7.x/8.x 版本、龙蜥(Anolis OS)8.x 版本。
• 硬件
• 内存:最低 4GB,生产环境推荐 8GB 以上。
• 存储:至少 50GB 可用空间。
• CPU:x86_64 架构,建议 4 核以上。
• 软件依赖:在 Ubuntu 系统上,需要安装 dpkg - dev、devscripts、liblzma - dev、libstdc++ - static 等依赖。此外,若使用 GCC 和 G++ 7.3.0 版本,还需增加 libstdc++ - static 依赖;对于 Ubuntu 18.04 系统,由于默认的 libprotobuf 版本不满足要求,用户需要提前安装 3.6.1 或 3.12.4 等所需版本,并在编译时通过 make PROTOBUF_DIR= 指定高版本路径。
对于生产环境,建议采用集群部署提高可用性,KWDB 集群至少需要 3 个节点1。同时,推荐使用 SSD 或者 NVMe 设备,文件系统建议使用 ext4
1.1 硬件环境要求

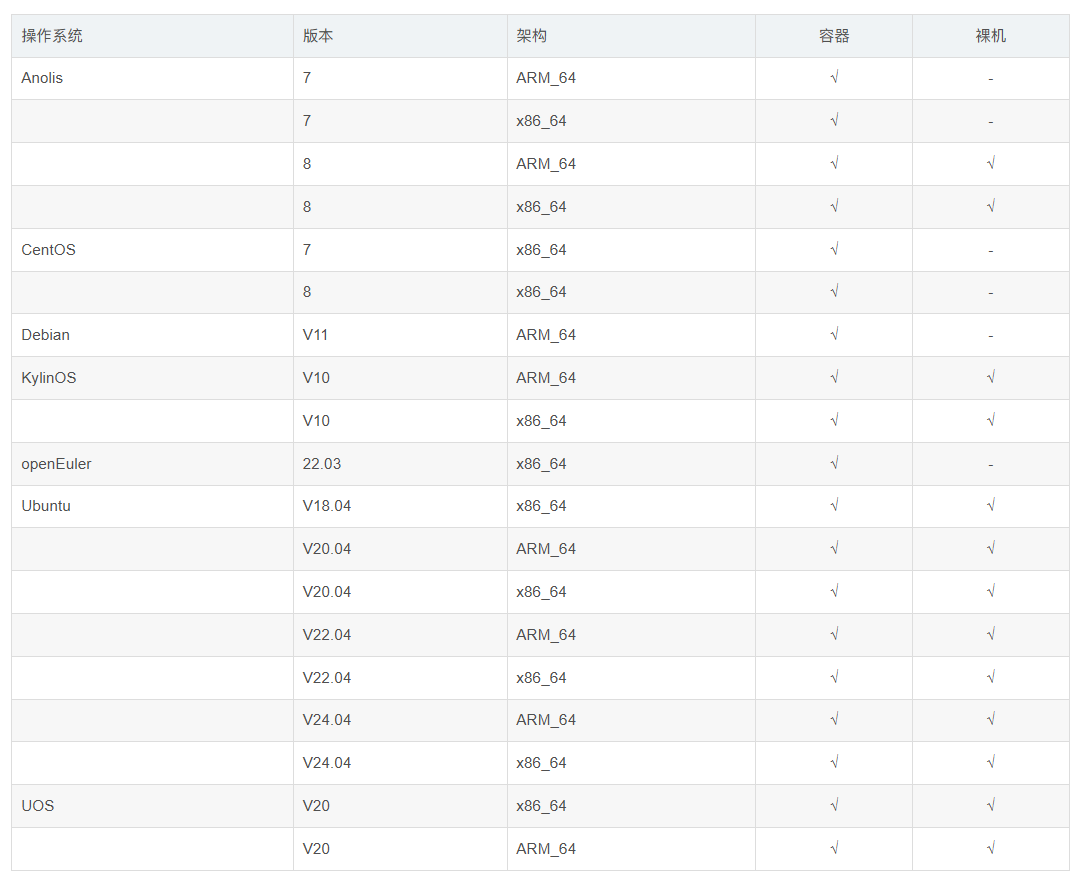
1.2 操作系统及架构
KaiwuDB 支持在以下服务器操作系统进行安装部署。
1.3 Ubuntu 22.04安装KWDB前准备
我们在本地Ubuntu 22.04环境上进行安装
1.3.1 检查系统信息
• 使用lsb_release -a命令,该命令可以显示 Ubuntu 系统的发行版信息
1.3.2 查看内核信息
• 使用uname -a命令,它会显示系统的内核名称、版本、主机名等信息。

1.3.3 查看CUP信息
• 查看 CPU 信息可以使用lscpu命令,它能展示 CPU 的架构、核心数、线程数等详细信息。
• 查看内存信息可使用free -h命令,用于显示系统内存的使用情况,包括总内存、已用内存、可用内存等。
1.3.4 查看系统资源使用情况
• top命令可以实时显示系统中各个进程的资源使用情况,包括 CPU、内存等的占用率。

1.3.5 查看网络信息
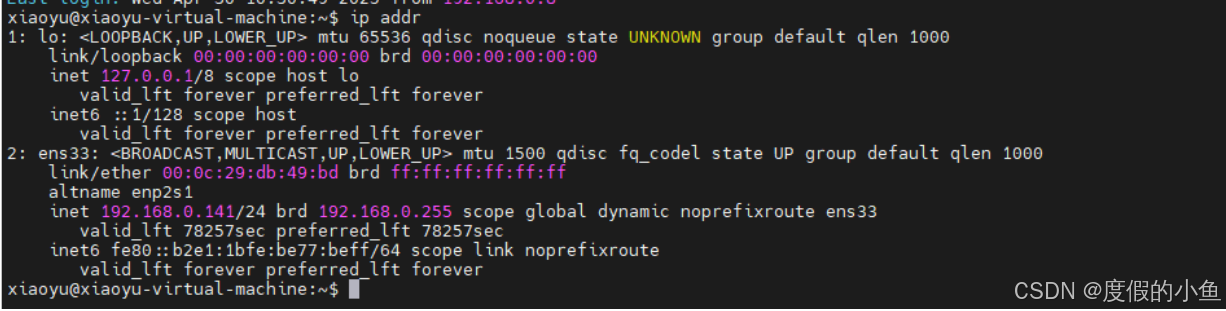
• 使用ip addr命令查看网络接口的配置信息,如 IP 地址、子网掩码、MAC 地址等
在 Ubuntu 18.04 及以后的版本中,ifconfig命令默认不再安装
1.3.6 检查端口
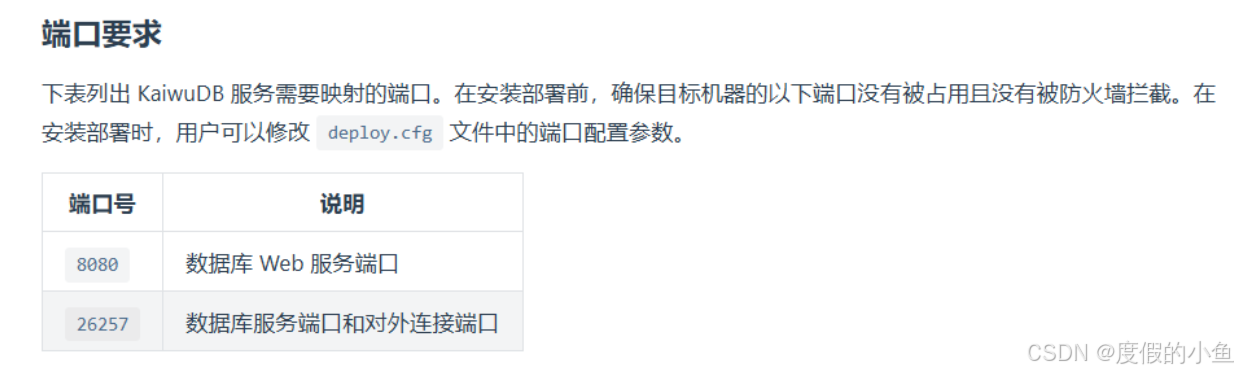
使用ss命令
ss是一个用于显示套接字统计信息的工具,它比netstat更快、更高效。
ss -tuln | grep <端口号>
其中,-t、-u、-l、-n选项的含义与netstat命令中的相同。
若端口被占用,会输出相关信息;若未被占用,则无输出。
在终端输入以下命令:
ss -tuln | grep 8080
ss -tuln | grep 26257

1.3.7 安装 libprotobuf 及相关工具
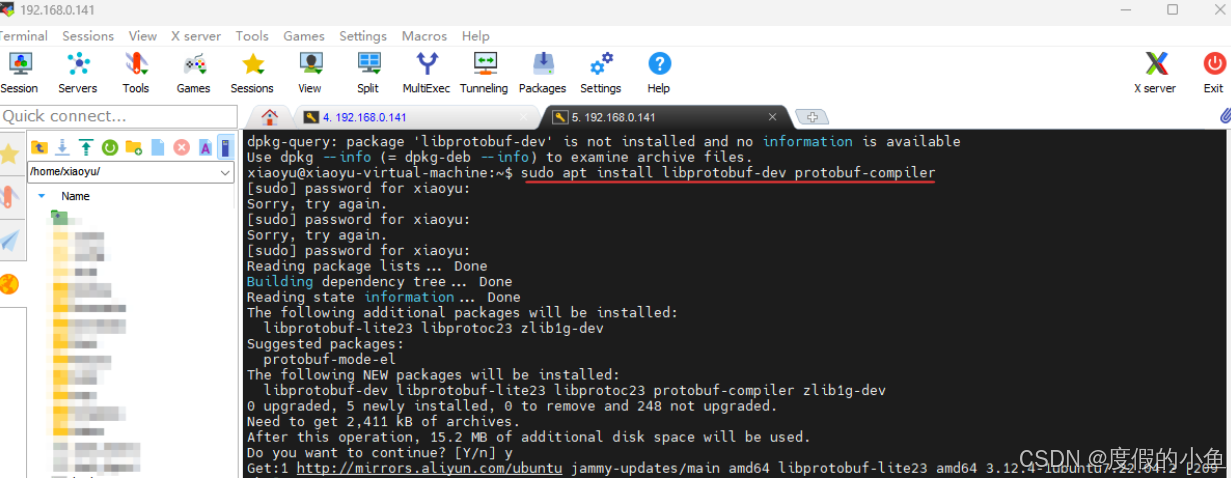
• 检查libprotobuf版本,在终端输入以下命令:
protoc --version
dpkg -s libprotobuf-dev | grep Version
发现查找不到

• 安装libprotobuf及相关工具
执行下面的命令来安装libprotobuf开发库和协议缓冲区编译器。
sudo apt install libprotobuf-dev protobuf-compiler
• 再次执行以下命令查看版本
protoc --version

1.3.8 安装其他依赖
KWDB 支持在 Linux 操作系统进行安装部署,下表列出了编译和运行 KWDB 所需的软件依赖。
编译依赖:
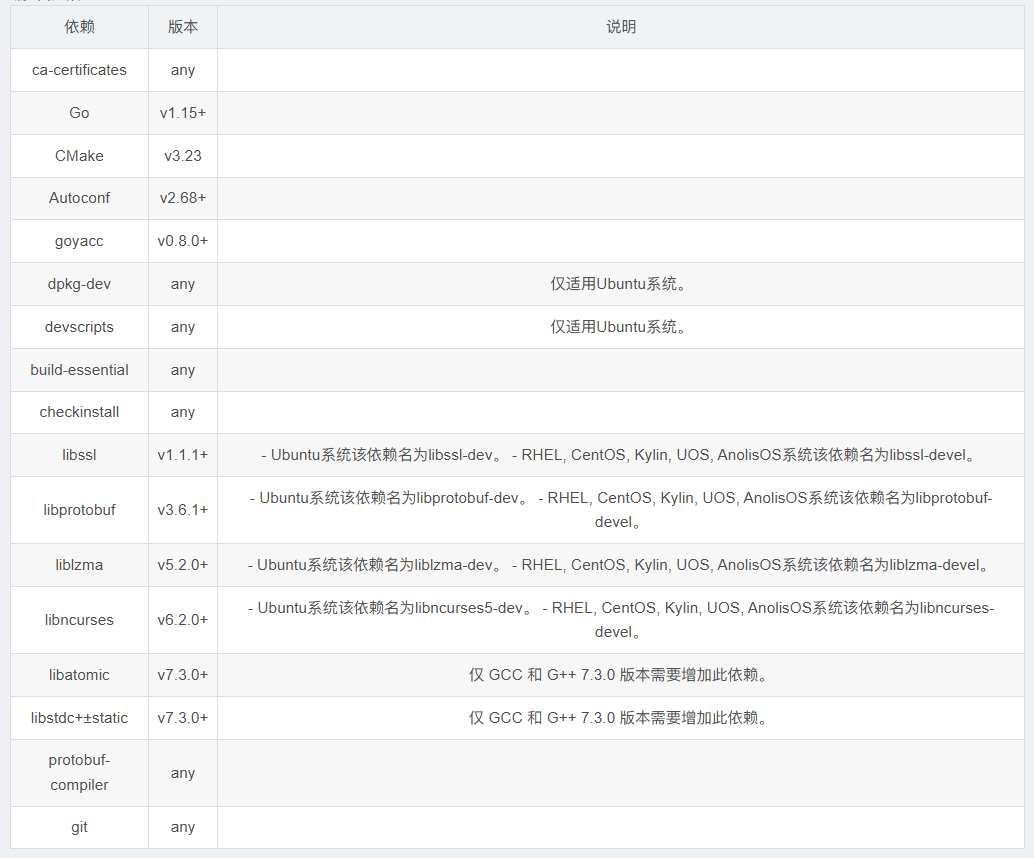
运行依赖:
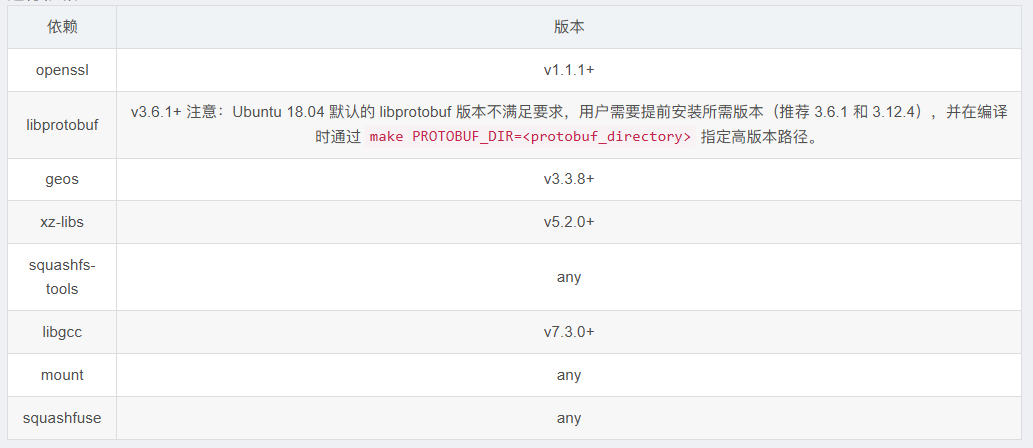
- 安装编译依赖
Go和CMake 之后单独安装,其他依赖使用如下命令:
通过apt一次性安装多个系统依赖
# 示例
sudo apt update && sudo apt install -y <依赖1> <依赖2> ...
命令如下:请直接复制以下完整命令(一行式),避免换行符引起的解析问题
sudo apt update && sudo apt install -y ca-certificates autoconf byacc dpkg-dev devscripts build-essential checkinstall libssl-dev libprotobuf-dev liblzma-dev libncurses-dev libatomic1 libstdc++6 protobuf-compiler
解释说明
sudo apt update && sudo apt install -y \
ca-certificates \
autoconf \ # 包名需小写
byacc \ # goyacc 的替代包
dpkg-dev \
devscripts \
build-essential \
checkinstall \
libssl-dev \ # 开发库通常以 -dev 结尾
libprotobuf-dev \
liblzma-dev \
libncurses-dev \
libatomic1 \ # 运行时库,非开发库
libstdc++6 \ # 静态库通常由这个包提供
protobuf-compiler
- 安装运行依赖
命令如下:
sudo apt update && sudo apt install -y openssl libgeos-dev liblzma-dev squashfs-tools libgcc-s1 mount squashfuse
解释说明:
sudo apt update && sudo apt install -y \
openssl \
libgeos-dev \ # 地理空间库
liblzma-dev \ # xz-libs 的正确名称
squashfs-tools \
libgcc-s1 \ # libgcc 的正确名称
mount \
squashfuse
到这里环境准备工作基本就完成了
1.4 开始安装KWDB
在终端依次输入以下命令:
1.4.1 更新软件源
sudo apt update
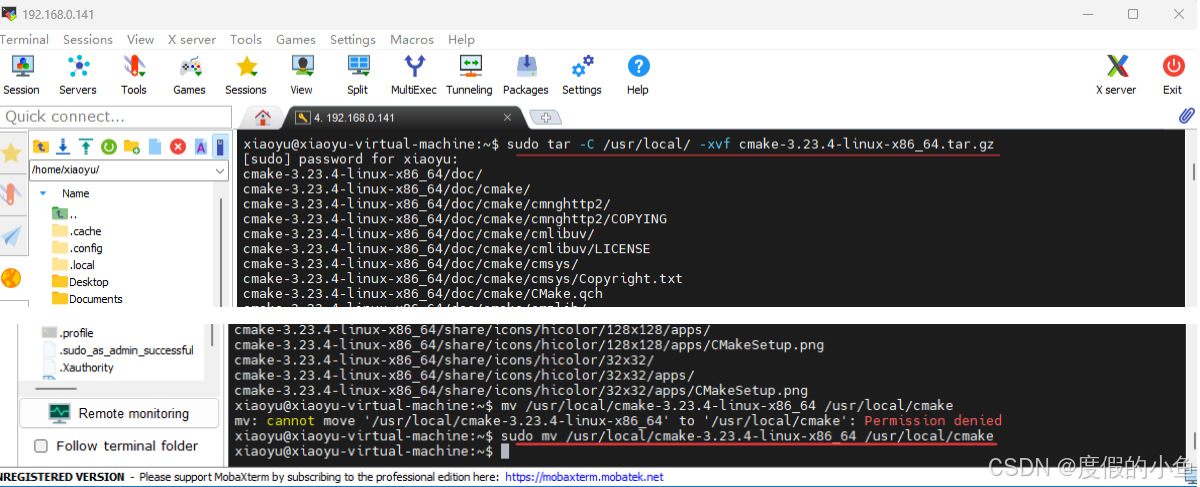
1.4.2 下载和解压 [CMake 安装包]
下载和解压 CMake 安装包
sudo apt install cmake —发现使用阿里云镜像直接安装后查看版本是3.22版本
还是使用官方提供的操作进行
sudo tar -C /usr/local/ -xvf cmake-3.23.4-linux-x86_64.tar.gz
sudo mv /usr/local/cmake-3.23.4-linux-x86_64 /usr/local/cmake
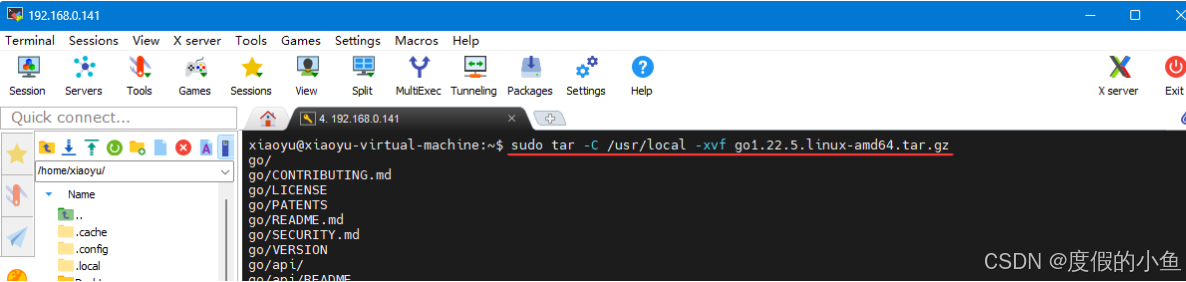
1.4.3 下载和解压 [Go 安装包]
下载和解压 Go 安装包
sudo tar -C /usr/local -xvf go1.22.5.linux-amd64.tar.gz
1.4.4 创建用于存放项目代码的代码目录
mkdir -p /home/xiaoyu/go/src/gitee.com
1.4.5 设置 go,CMake 环境变量
一般而言,通过包管理器安装的 CMake,其可执行文件会自动添加到系统的PATH环境变量中。不过,要是你从源码编译安装了 CMake,就需要手动设置环境变量。
- (1)打开环境变量配置文件:同样以
~/.bashrc为例,使用以下命令打开该文件:
nano ~/.bashrc
- (2)添加 CMake 环境变量:假设 CMake 的可执行文件所在目录为
/usr/local/cmake/bin,在文件末尾添加以下内容:
由于之前CMake移动到了 /usr/local/cmake/bin,目录下
# 设置Go的安装目录
export GOROOT=/usr/local/go
# 设置Go的工作目录,可根据需求修改,$HOME 会自动指向当前用户目录(如 /home/xiaoyu)
export GOPATH=/home/xiaoyu/go
# 将Go和CMake的可执行文件目录添加到系统的PATH环境变量中
export PATH=$PATH:/usr/local/go/bin:/usr/local/cmake/bin

-
(3)保存并退出文件:在
nano编辑器中,按下Ctrl + X,然后按Y确认保存,最后按Enter键退出。 -
(4)使环境变量生效:执行以下命令使修改后的环境变量立即生效:
source ~/.bashrc #个人用户设置
source /etc/profile #系统全局设置
- (5)验证 CMake 环境变量是否设置成功:执行以下命令查看 CMake 的版本信息:
cmake --version

- (6)验证 Go 环境变量是否设置成功
在终端执行以下命令查看 Go 的版本信息:
go version
若能正常输出版本信息,就说明 Go 环境变量设置成功。

CMake
CMake 是一个开源、跨平台的自动化构建系统配置工具,它本身并不直接构建出最终的软件,而是为其他构建工具(如 Make、Ninja 等)生成相应的构建文件,比如在 Unix/Linux 系统中生成 Makefile 文件。其用途主要体现在以下方面:
-
跨平台项目构建:当你开发的项目需要在不同的操作系统(如 Windows、Linux、macOS)和编译器(如 GCC、Clang、MSVC)上进行构建时,CMake 能根据不同平台和编译器的特性生成对应的构建文件,保证项目在各平台上都能顺利构建。
-
简化构建配置:在大型项目中,手动编写和维护复杂的构建脚本(如 Makefile)是一项艰巨的任务。CMake 通过简单的 CMakeLists.txt 文件来描述项目的结构和构建规则,开发者只需编写一次 CMakeLists.txt 文件,CMake 就能自动生成适用于不同平台的构建文件。
-
依赖管理:CMake 可以方便地管理项目的依赖项,通过find_package命令查找系统中已安装的库,或者通过ExternalProject_Add命令下载和编译外部依赖库。
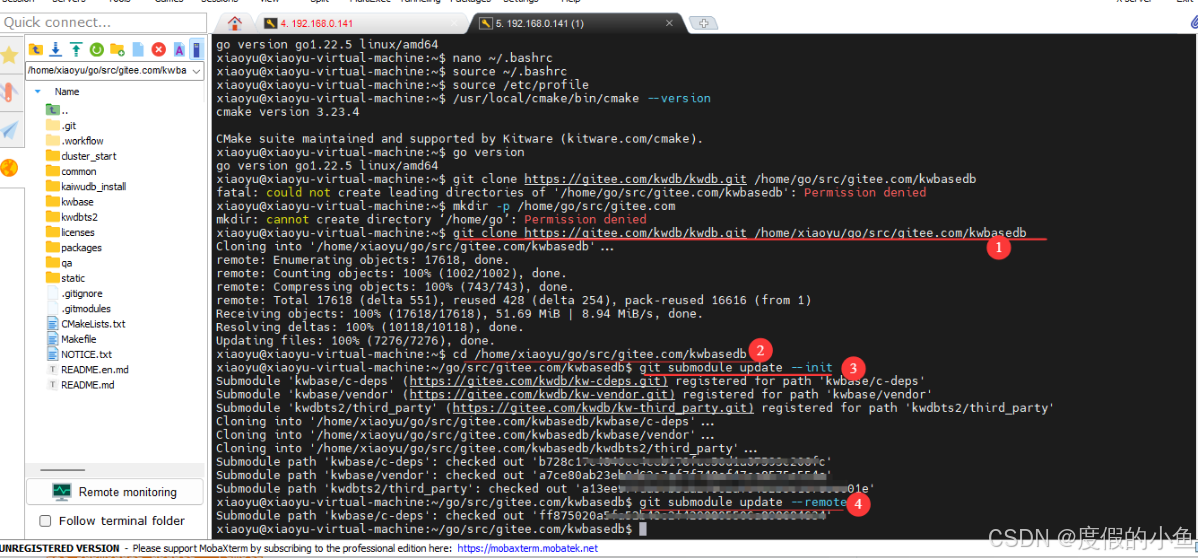
1.4.6 下载KWDB代码
使用 git clone 命令
git clone https://gitee.com/kwdb/kwdb.git /home/xiaoyu/go/src/gitee.com/kwbasedb
cd /home/xiaoyu/go/src/gitee.com/kwbasedb
git submodule update --init
git submodule update --remote
1.4.7 构建
- 在项目目录下创建并切换到构建目录。
cd /home/xiaoyu/go/src/gitee.com/kwbasedb
mkdir build && cd build # 当前工作目录下创建一个名为 build 的目录,并在创建成功后进入该目录。
- 运行 CMake 配置。
修改文件和目录的所有者和权限
不想频繁使用sudo ,可以将 build 目录及其子文件和子目录的所有者修改为当前用户,并且赋予当前用户足够的权限。
- 修改所有者
使用 chown命令将 build 目录及其子内容的所有者修改为当前用户(假设当前用户是 xiaoyu):
sudo chown -R xiaoyu:xiaoyu /home/xiaoyu/go/src/gitee.com/kwbasedb/build
这里的-R 选项表示递归操作,即对 build 目录及其所有子目录和文件都进行修改。
- 修改权限
使用chmod 命令赋予当前用户读写和执行权限:
chmod -R 755 /home/xiaoyu/go/src/gitee.com/kwbasedb/build
755 表示所有者具有读、写、执行权限,而所属组和其他用户具有读和执行权限。
执行 CMake 配置(明确指定 Release/Debug)
参数说明: CMAKE_BUILD_TYPE:指定构建类型,默认为 Debug。可选值为 Debug 或 Release,首字母需大写。
cmake .. -DCMAKE_BUILD_TYPE=Release
- 禁用Go模块功能
操作同1.4.5
nano ~/.bashrc
export GO111MODULE=off

source ~/.bashrc
完整操作流程(避免重复错误)
# 1. 进入项目根目录(若未在此处)
cd /home/xiaoyu/go/src/gitee.com/kwbasedb
# 2. 直接进入已有的 build 目录(无需再次创建)
cd build
# 3. 清理旧文件(可选,按需执行)
rm -rf *
# 4. 执行 CMake 配置(明确指定 Release/Debuge # 或 Debug
cmake .. -DCMAKE_BUILD_TYPE=Release
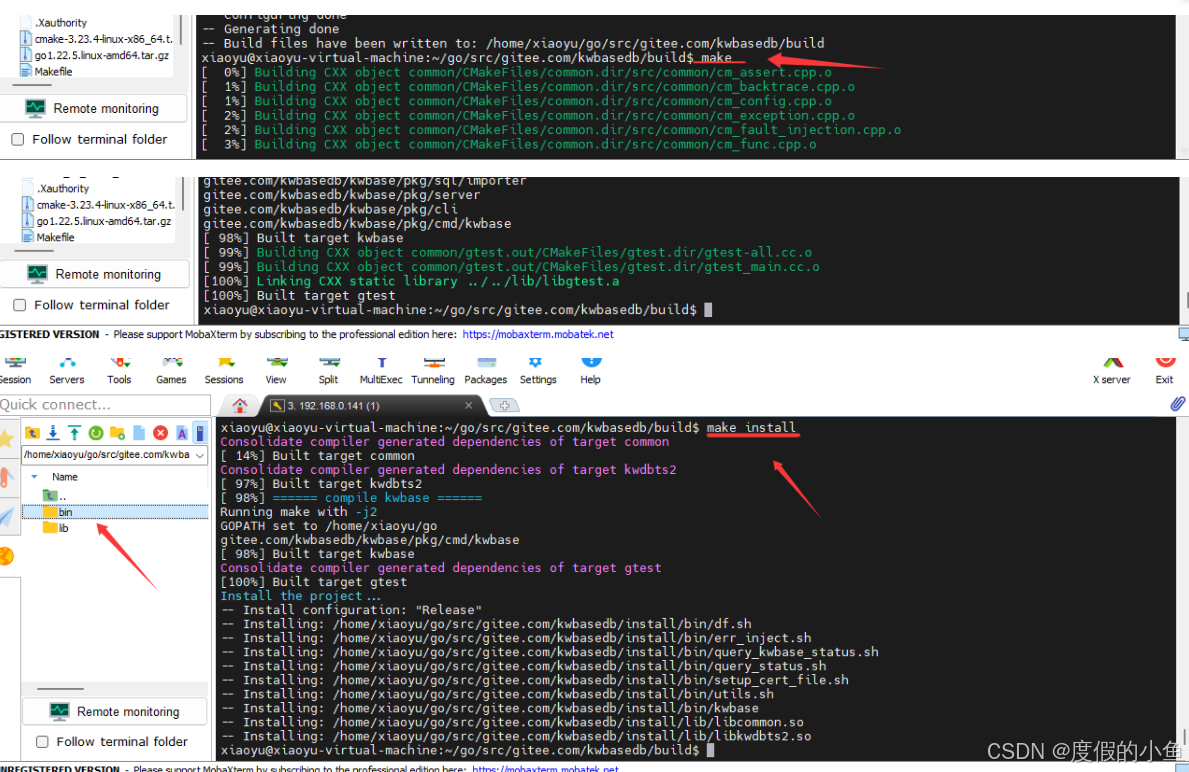
# 5. 构建项目(如果生成 Makefile)
make
# 6. 将软件安装到系统中
make install
# 7. 查看是否安装成功
进入 `kwbase` 脚本所在目录
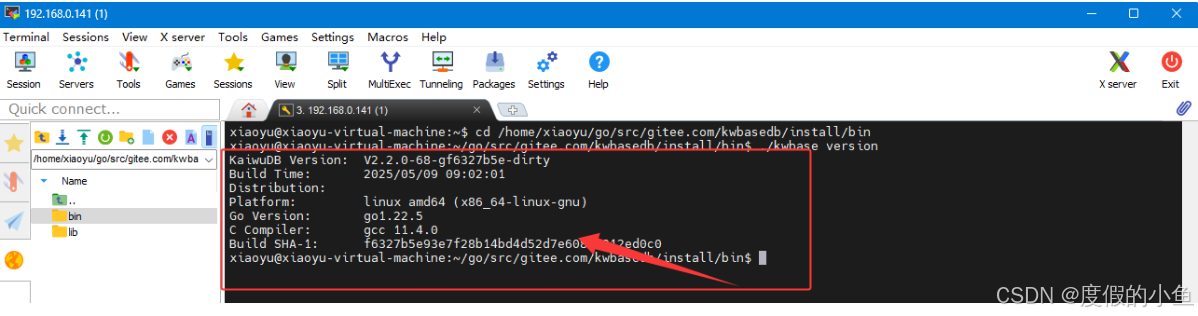
cd /home/xiaoyu/go/src/gitee.com/kwbasedb/install/bin
./kwbase version
操作记录图
1.5 启动数据库
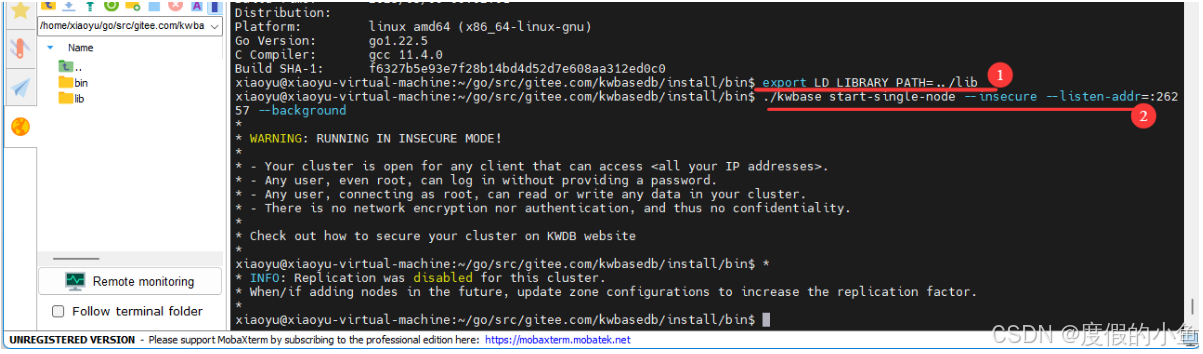
- 进入
kwbase脚本所在目录。
cd /home/xiaoyu/go/src/gitee.com/kwbasedb/install/bin
- 设置共享库的搜索路径。
export LD_LIBRARY_PATH=../lib
- 启动数据库。
./kwbase start-single-node --insecure --listen-addr=:26257 --background
1.6 连接数据库
安装部署完 KWDB 以后,用户可以使用使用 KaiwuDB 开发者中心连接 KWDB连接和管理 KWDB
- 从KWDB社区下载了免安装的KWDB开发者中心
- 直接解压到一个文件夹下
- 点击
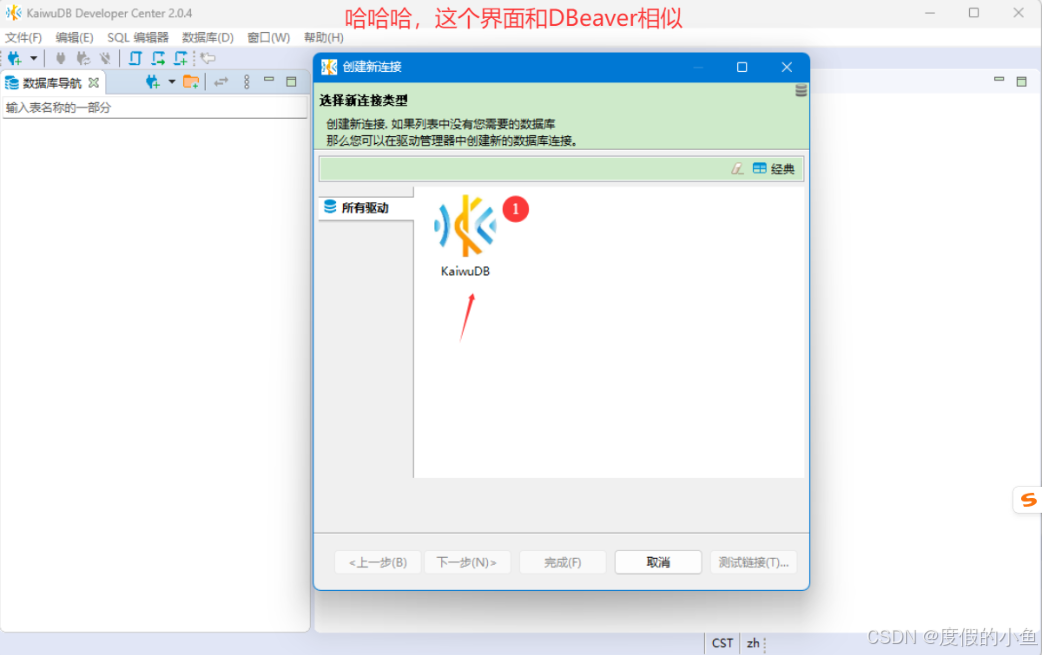
KaiwuDB Developer Center.exe程序启动
选中【KaiwuDB】图标,点击【下一步】
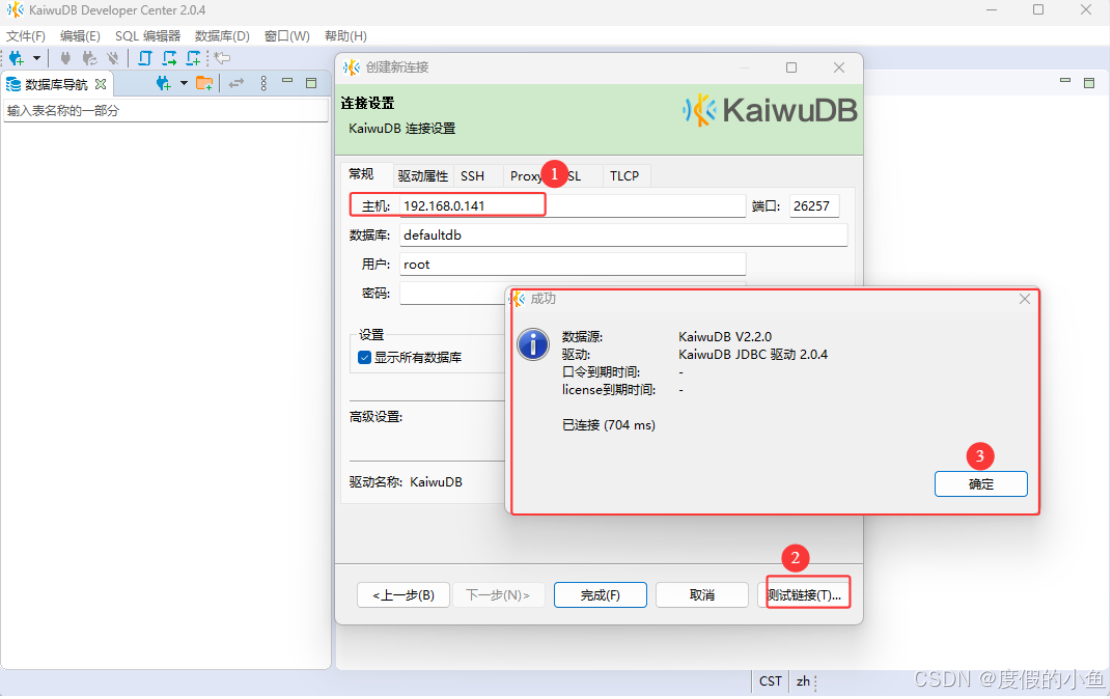
在常规页签,设置主机、端口、数据库、用户和密码(如果采用非安全部署模式,则无需设置密码)。
- 连接成功如下图所示
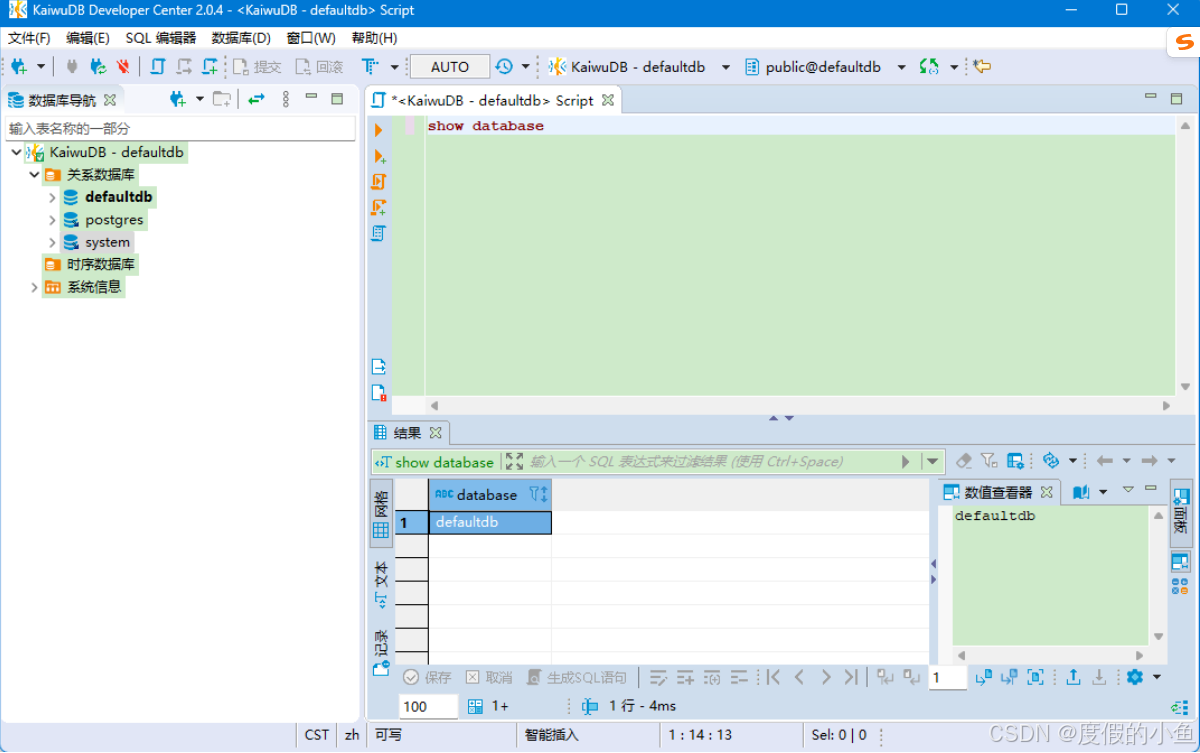
1.6.1 有趣的功能提醒
2.传感器案例练习
2.1 创建关系数据库
以下是一个针对关系数据的简化版SQL示例,可用于练习增删改查操作哈:
-- 1. 创建数据表
CREATE TABLE device_metrics (
id SERIAL PRIMARY KEY, -- 自增主键
ts TIMESTAMP NOT NULL, -- 时间戳
device_id VARCHAR(50) NOT NULL, -- 设备编号
metric_name VARCHAR(50) NOT NULL, -- 指标名称
value DOUBLE PRECISION NOT NULL, -- 数值
UNIQUE(device_id, ts, metric_name) -- 确保同一设备的同一时刻只有一条记录
);
-- 2. 插入测试数据
INSERT INTO device_metrics (ts, device_id, metric_name, value) VALUES
('2023-10-01 10:00:00', 'Sensor_A', 'Temperature', 26.5),
('2023-10-01 10:00:00', 'Sensor_A', 'Humidity', 45.2),
('2023-10-01 10:05:00', 'Sensor_B', 'Pressure', 1013.25);
-- 3. 查询所有数据
SELECT * FROM device_metrics;
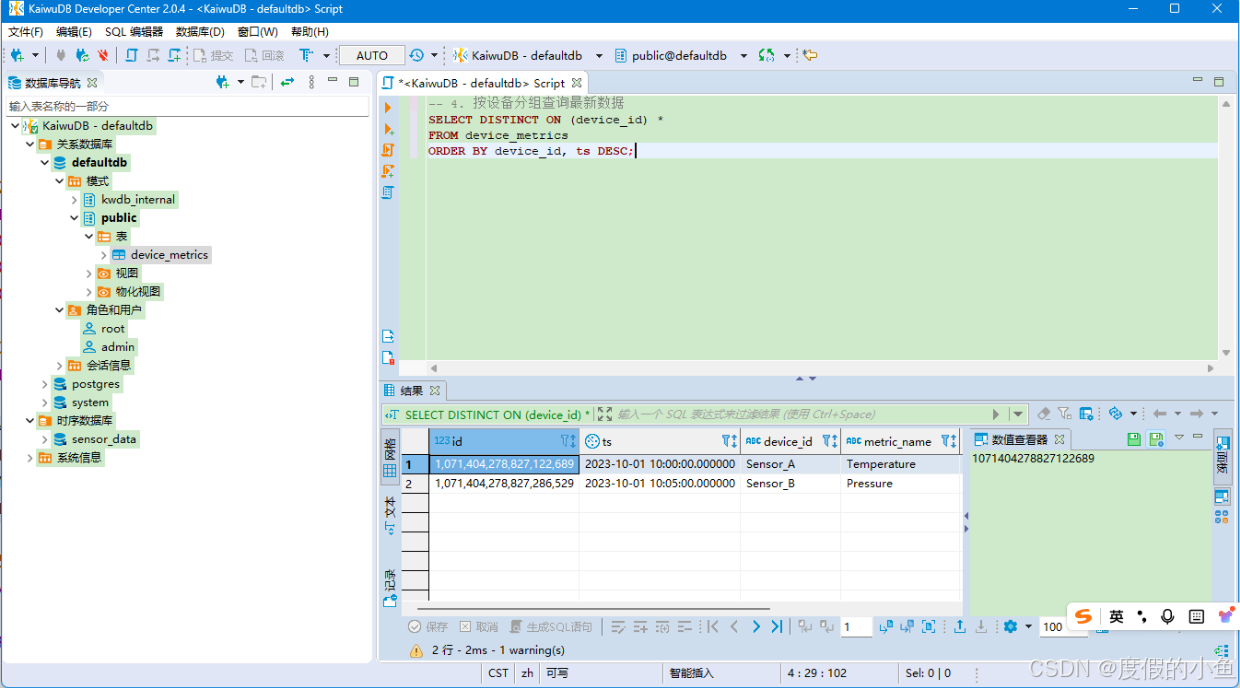
-- 4. 按设备分组查询最新数据
SELECT DISTINCT ON (device_id) *
FROM device_metrics
ORDER BY device_id, ts DESC;
-- 5. 更新温度数据
UPDATE device_metrics
SET value = 27.0
WHERE device_id = 'Sensor_A' AND metric_name = 'Temperature';
-- 6. 删除过期数据(保留最近7天)
DELETE FROM device_metrics
WHERE ts < NOW() - INTERVAL '7 days';
操作4如下图
2.2 创建时序数据库
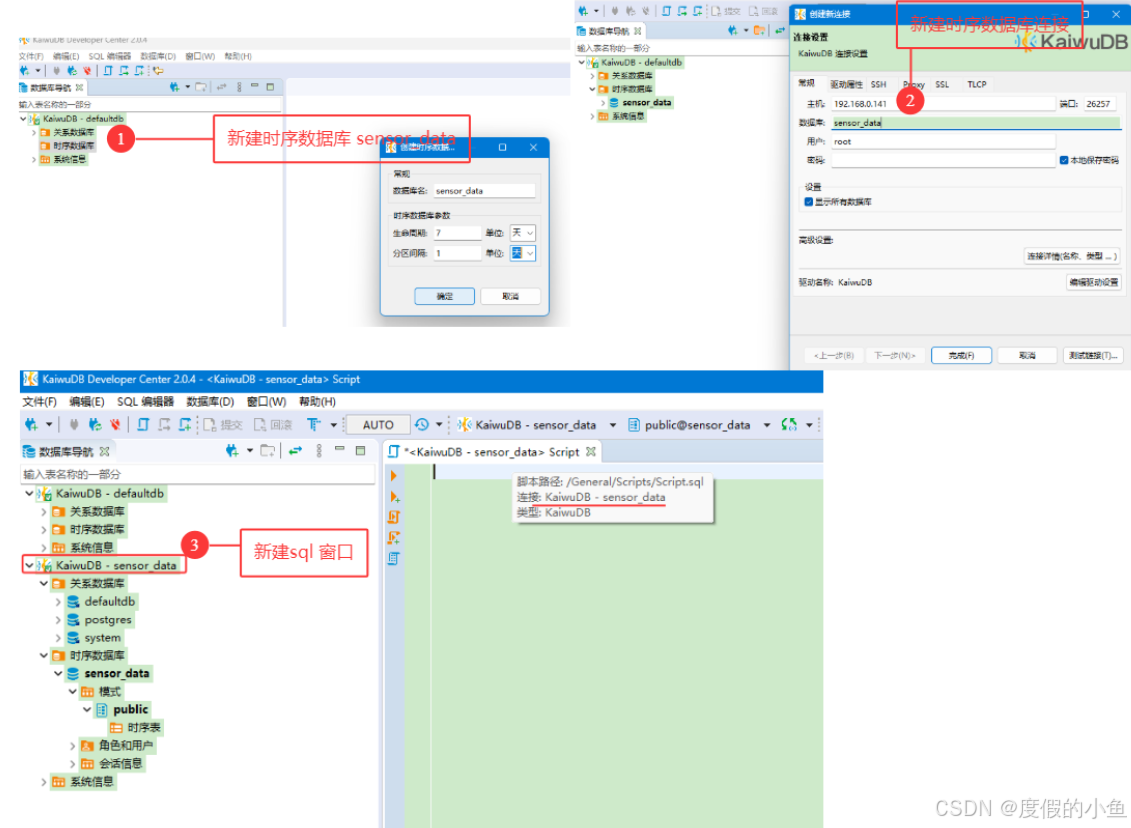
以下以浪潮开务数据库(如KaiwuDB)的工业物联网场景为例,提供一个时序数据库增删改查(CRUD)的完整案例。案例基于假设的工业设备时序数据表,包含设备ID、时间戳、温度值、振动值等字段,涵盖建表、数据插入、查询、更新和删除操作。
2.2.1 案例背景
某汽车制造工厂需要实时监控1000台工业机器人的运行状态,采集温度、振动等时序数据,用于设备健康预测性维护。要求数据库支持高频写入、毫秒级查询响应,并实现历史数据归档与异常检测。
2.2.2 表结构设计
创建名为robot_sensor_data 的时序表,包含以下字段:
-
设备ID:
device_id(字符串,主标签,非空) -
时间戳:
timestamp(时间戳,非空,索引) -
温度值:
temperature(浮点数) -
振动值:
vibration(浮点数) -
状态码:
status_code(整数,可选)
-- 创建时序数据库(可选,若未预创建)
CREATE DATABASE sensor_data WITH (type = 'timeseries');
-- 切换到工业物联网数据库
USE sensor_data;
-- 创建时序表
CREATE TABLE robot_sensor_data (
timestamp TIMESTAMPTZ NOT NULL,
temperature FLOAT,
vibration FLOAT,
status_code INT
) TAGS (
device_id VARCHAR(32) NOT NULL
) PRIMARY TAGS (device_id);
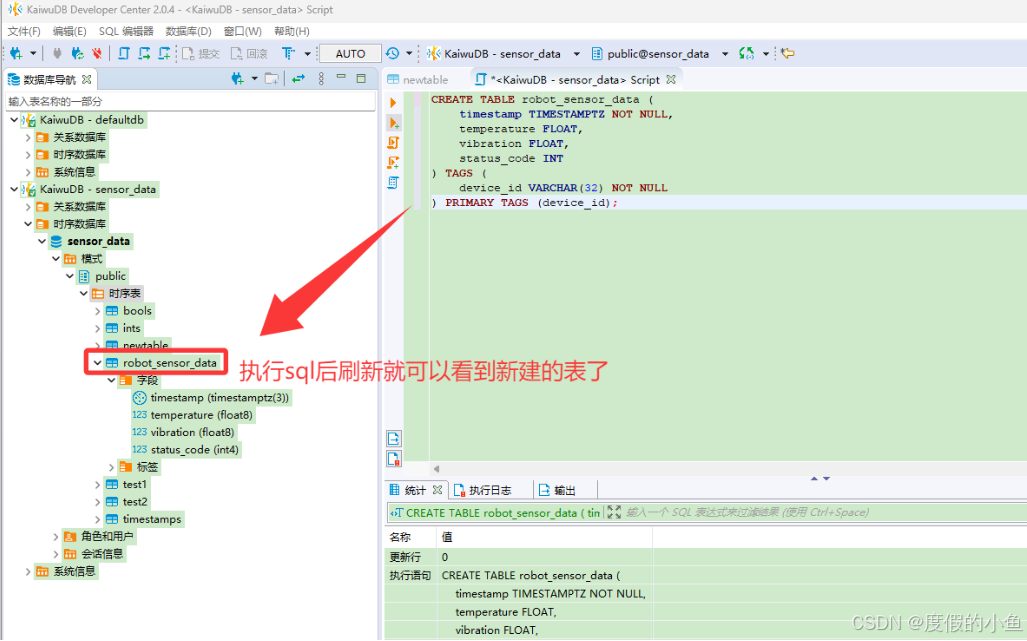
数据插入(Create)
- 单条插入
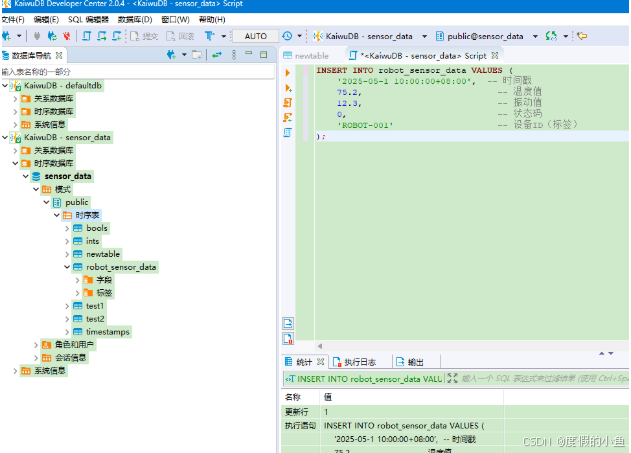
INSERT INTO robot_sensor_data VALUES (
'2025-05-1 10:00:00+08:00', -- 时间戳
75.2, -- 温度值
12.3, -- 振动值
0, -- 状态码
'ROBOT-001' -- 设备ID(标签)
);
批量插入1000条数据(Python操作)
模拟设备实时上报数据,批量插入多条时序记录:
使用 Psycopg 2 连接 KaiwuDB
Psycopg 是最受欢迎的 PostgreSQL 数据库适配器,专为 Python 编程语言而设计。Psycopg 完全遵循 Python DB API 2.0 规范,支持线程安全,允许多个线程共享同一连接,特别适合高并发和多线程的应用场景。
KaiwuDB 支持用户通过 Psycopg 2 连接数据库,并执行创建、插入和查询操作。
pip install psycopg2-binary
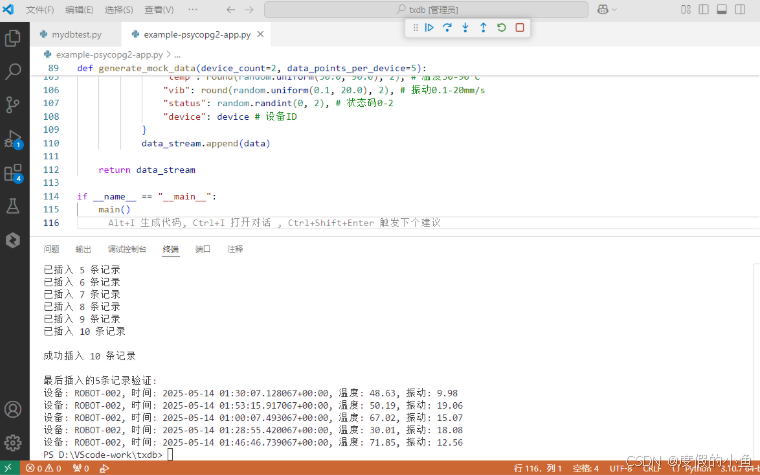
以下代码简单的批量插入10条数据进行测试成功
#!/usr/bin/env python3
# -*- coding: UTF-8 -*-
import psycopg2
import random
from datetime import datetime, timedelta, timezone
def main():
try:
# 连接到KaiwuDB
con = psycopg2.connect(
database="sensor_data",
user="root",
password="",
host="192.168.0.141",
port="26257"
)
print("成功连接到KaiwuDB!")
con.set_session(autocommit=True)
cur = con.cursor()
# 测试插入一条简单记录
test_insert(cur)
# 生成并插入模拟数据
mock_data = generate_mock_data(device_count=2, data_points_per_device=5)
insert_count = 0
for data in mock_data:
try:
# 关键修改:使用字符串格式的时间戳,不带时区信息
timestamp_str = data["time"].strftime("%Y-%m-%d %H:%M:%S.%f")
insert_sql = """
INSERT INTO robot_sensor_data VALUES (
%s, %s, %s, %s, %s
)
"""
cur.execute(insert_sql, (
timestamp_str, # 直接传递格式化后的字符串
data["temp"],
data["vib"],
data["status"],
data["device"]
))
insert_count += 1
print(f"已插入 {insert_count} 条记录")
except psycopg2.Error as e:
print(f"插入数据时出错: {e}")
print(f"出错的数据: {data}")
# 继续尝试下一条记录而非中断
continue
print(f"\n成功插入 {insert_count} 条记录")
# 验证最后插入的5条记录
print("\n最后插入的5条记录验证:")
for data in mock_data[-5:]:
print(f"设备: {data['device']}, 时间: {data['time']}, 温度: {data['temp']}, 振动: {data['vib']}")
except psycopg2.Error as e:
print(f"连接数据库时出错: {e}")
finally:
if 'cur' in locals():
cur.close()
if 'con' in locals():
con.close()
def test_insert(cur):
"""测试插入一条简单记录"""
try:
test_sql = """
INSERT INTO robot_sensor_data VALUES (
NOW(), 25.5, 1.2, 0, 'TEST-001'
)
"""
cur.execute(test_sql)
print("测试记录插入成功")
# 查询验证
cur.execute("SELECT * FROM robot_sensor_data WHERE device_id = 'TEST-001'")
row = cur.fetchone()
if row:
print("测试查询结果:", row)
else:
print("未找到测试记录")
except psycopg2.Error as e:
print(f"测试插入失败: {e}")
def generate_mock_data(device_count=2, data_points_per_device=5):
"""生成10条模拟工业机器人传感器数据(2台设备,每台5条)"""
base_time = datetime.now(timezone.utc) - timedelta(hours=24) # 生成过去24小时的数据
devices = [f"ROBOT-{str(i).zfill(3)}" for i in range(1, device_count + 1)]
data_stream = []
for device in devices:
for i in range(data_points_per_device):
# 生成随机时间戳
timestamp = base_time + timedelta(
seconds=random.randint(0, 3600),
milliseconds=random.randint(0, 999)
)
data = {
"time": timestamp,
"temp": round(random.uniform(30.0, 90.0), 2), # 温度30-90°C
"vib": round(random.uniform(0.1, 20.0), 2), # 振动0.1-20mm/s
"status": random.randint(0, 2), # 状态码0-2
"device": device # 设备ID
}
data_stream.append(data)
return data_stream
if __name__ == "__main__":
main()
以下代码简单的批量插入1000条数据进行测试成功
#!/usr/bin/env python3
# -*- coding: UTF-8 -*-
import psycopg2
import random
import math
from datetime import datetime, timedelta, timezone
def generate_mock_data(device_count=10, data_points_per_device=100):
"""
生成模拟工业机器人传感器数据
参数:
device_count: 设备数量 (默认10台)
data_points_per_device: 每台设备数据点数 (默认100条)
返回:
包含模拟数据的列表
"""
base_time = datetime.now(timezone.utc) - timedelta(days=30) # 30天内的数据
devices = [f"ROBOT-{str(i).zfill(3)}" for i in range(1, device_count + 1)]
data_stream = []
for device in devices:
device_base_time = base_time + timedelta(
hours=random.randint(0, 24*7) # 每台设备数据分布在不同的时间段
)
for i in range(data_points_per_device):
# 时间递增但加入随机波动
timestamp = device_base_time + timedelta(
minutes=i*15 + random.randint(-5, 5),
seconds=random.randint(0, 59),
milliseconds=random.randint(0, 999)
)
# 生成更真实的传感器数据模式
base_temp = random.uniform(30.0, 40.0)
temp_variation = math.sin(i/10) * 10 # 周期性波动
current_temp = round(base_temp + temp_variation + random.uniform(-2, 2), 2)
# 振动数据与温度相关性
base_vib = max(0.1, (current_temp - 35) / 10)
current_vib = round(base_vib + random.uniform(-0.5, 0.5), 2)
# 设备状态 (0正常, 1警告, 2故障)
status = 0
if current_temp > 75:
status = 1
elif current_temp > 85 or current_vib > 15:
status = 2
data = {
"timestamp": timestamp,
"temperature": current_temp,
"vibration": current_vib,
"status_code": status,
"device_id": device
}
data_stream.append(data)
# 按时间排序
data_stream.sort(key=lambda x: x["timestamp"])
return data_stream
def main():
try:
# 连接到KaiwuDB
con = psycopg2.connect(
database="sensor_data",
user="root",
password="",
host="192.168.0.141",
port="26257"
)
print("成功连接到KaiwuDB!")
con.set_session(autocommit=True)
cur = con.cursor()
# 检查实际表结构
print("\n正在检查表结构...")
cur.execute("""
SELECT column_name, data_type
FROM information_schema.columns
WHERE table_name = 'robot_sensor_data'
""")
columns = {col[0]: col[1] for col in cur.fetchall()}
print("实际表结构:")
for col_name, col_type in columns.items():
print(f"{col_name}: {col_type}")
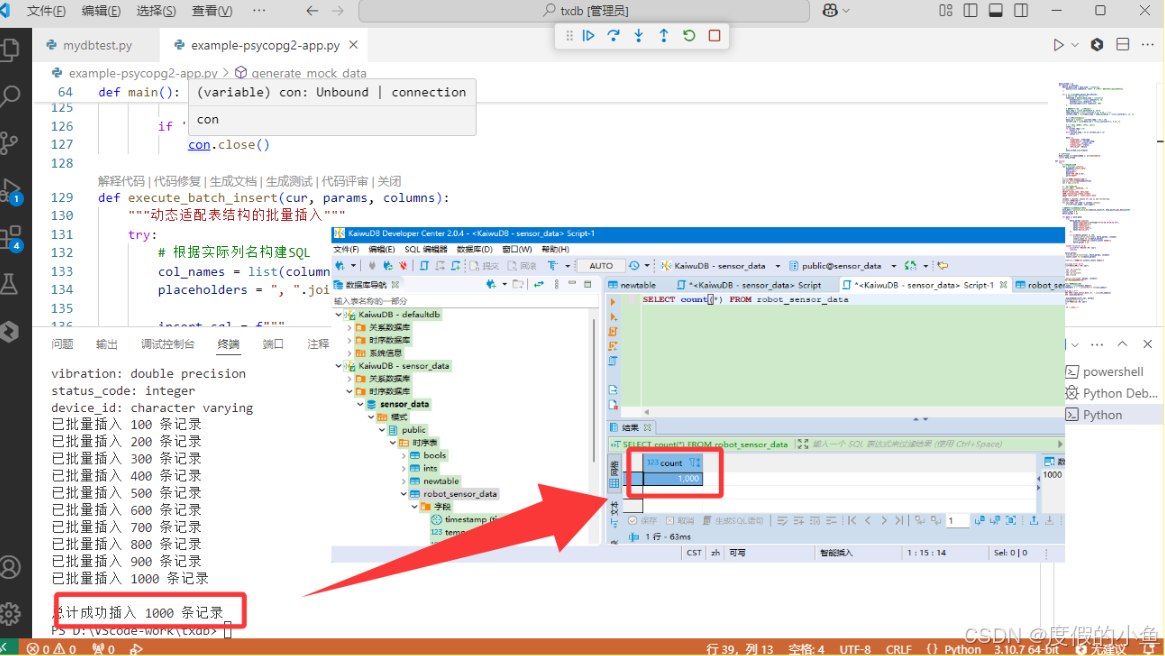
# 生成并插入1000条模拟数据
mock_data = generate_mock_data(device_count=10, data_points_per_device=100)
insert_count = 0
batch_params = []
for data in mock_data:
try:
batch_params.append((
data["timestamp"].strftime("%Y-%m-%d %H:%M:%S.%f"),
data["temperature"],
data["vibration"],
data["status_code"],
data["device_id"]
))
if len(batch_params) >= 100:
execute_batch_insert(cur, batch_params, columns)
insert_count += len(batch_params)
print(f"已批量插入 {insert_count} 条记录")
batch_params = []
except Exception as e:
print(f"准备数据时出错: {e}")
continue
if batch_params:
execute_batch_insert(cur, batch_params, columns)
insert_count += len(batch_params)
print(f"\n总计成功插入 {insert_count} 条记录")
except psycopg2.Error as e:
print(f"数据库操作出错: {e}")
finally:
if 'cur' in locals():
cur.close()
if 'con' in locals():
con.close()
def execute_batch_insert(cur, params, columns):
"""动态适配表结构的批量插入"""
try:
# 根据实际列名构建SQL
col_names = list(columns.keys())
placeholders = ", ".join(["%s"] * len(col_names))
insert_sql = f"""
INSERT INTO robot_sensor_data ({", ".join(col_names)})
VALUES ({placeholders})
"""
cur.executemany(insert_sql, params)
except psycopg2.Error as e:
print(f"批量插入出错: {e}")
raise
if __name__ == "__main__":
main()
数据查询(Select)
- 查询某设备最近1小时数据
SELECT * FROM robot_sensor_data
WHERE device_id = 'ROBOT-001'
AND timestamp > NOW() - INTERVAL '1 hour'
ORDER BY timestamp DESC;
数据更新(Update)
时序数据库通常不支持直接更新历史数据,需通过先删除后插入实现:
-- 删除设备ROBOT-001在2025-05-1 10:00:00的数据
DELETE FROM robot_sensor_data
WHERE device_id = 'ROBOT-001'
AND timestamp = '2025-05-1 10:00:00+08:00';
-- 插入修正后的数据
INSERT INTO robot_sensor_data VALUES (
'2025-05-1 10:00:00+08:00',
74.8, -- 修正后的温度
12.1, -- 修正后的振动
0,
'ROBOT-001'
);
数据删除(Delete)
- 删除单条数据
-- 删除设备ROBOT-001在2025-05-1 10:00:00的数据
DELETE FROM robot_sensor_data
WHERE device_id = 'ROBOT-001'
AND timestamp = '2025-05-1 10:00:00+08:00';
- 删除设备ROBOT-001超过30天的历史数据
DELETE FROM robot_sensor_data
WHERE device_id = 'ROBOT-001'
AND timestamp < NOW() - INTERVAL '30 days';
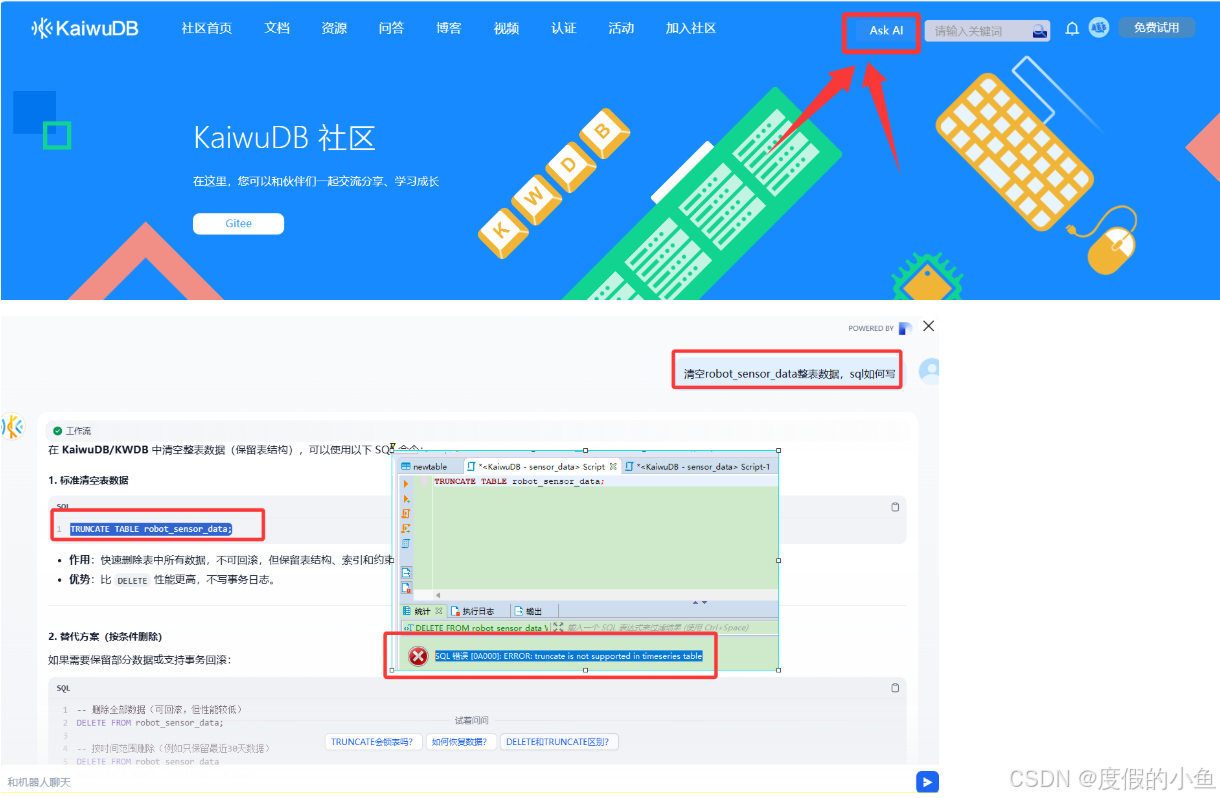
- 清空整表(谨慎操作)
TRUNCATE TABLE robot_sensor_data; -- 操作了一下这个sql没有成功,可能不支持这样写
delete from robot_sensor_data; --执行成功删除数据
通过以上案例,可以熟悉浪潮开务数据库在时序数据场景下的增删改查操作,并应用于工业物联网、能源监控等实际场景。
3.其他+踩坑
3.1 KWDB_AI
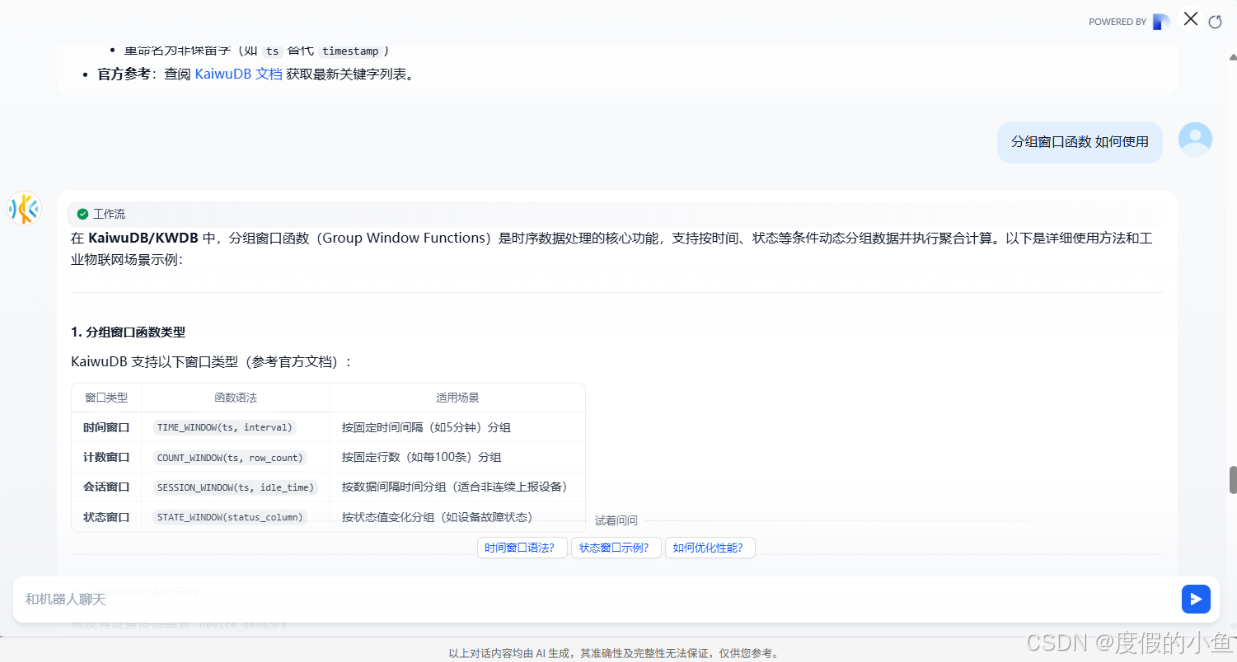
官网提供了 AI智能数据库交互问答 小助手,貌似不太理想,如果可以给出结果在链接到官方文档就更方便了.
3.2 Python连接数据库写入数据

问题出在 KaiwuDB 对时间戳数据类型的处理上。以下是针对性的解决方案:
问题诊断
-
错误信息:
unsupported input type *tree.CastExpr -
触发场景:尝试插入包含
datetime对象的数据时 -
测试对比:
直接使用 NOW() 的测试插入成功
使用 Python datetime 对象插入失败
# 修改后
base_time = datetime.now() - timedelta(hours=24)
