




总结一下hive分区表。
what?
分区表是将大表的数据分成称为分区的许多小的子集,将数据按照某种符合逻辑的方式进行组织。
how?
hive中既然有分区表的概念,那我们怎么样来创建一个分区表并进行使用呢?下面来介绍。
创建分区表

hive (a)> create table employees_p(name string,salaryfloat,subordinates array<string>,deductions map<string,float>,addressstruct<street:string,city:string,state:string,zip:int>) partitioned by(state string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' COLLECTION ITEMSTERMINATED BY ':' MAP KEYS TERMINATED BY '-' LINES TERMINATED BY '\n' STORED ASTEXTFILE;
使用partitioned by (字段名 类型)在创建hive表时进行分区。注意partitioned by后的字段名不能是表中的字段名。此处我们使用了state做为了分区字段名。
导入数据到表
可在load data时指定分区的名称,将数据集的内容导入到分区表中。如下:

hive (a)> load data local inpath '/home/sparker/lixy/data1.txt' into table employees_p partition(state='Oak Park IL');
导入完成之后,我们到相应的hive/warehouse目录下查询目录结构:
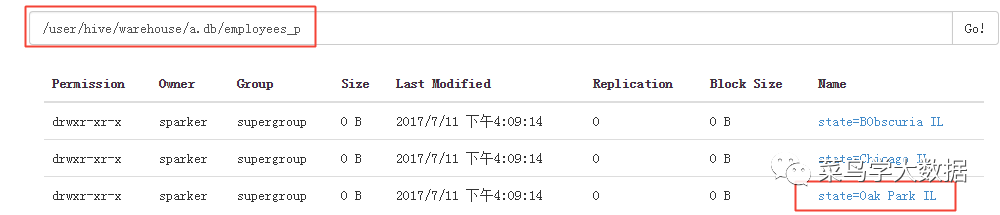
发现表employees_p下多了文件夹state=Oak Part IL,这个就是我们导入数据时指定的partition的字段值。
查询数据到表
除了使用load data 方式指定partition分区的值之外,还可以使用查询语句从另外一张表取得相应的数据插入到分区表中。如下:

hive (a)> insert overwrite table employees_p partition(state='Oak Park IL') select * from employees where address.state='Oak Park IL';
该方式和上面导入数据到表产生的效果一样。
以上两种方式都是静态插入,也就是说partition的字段名的值是指定的,这种情况下需要写的sql比较多,所以hive支持了动态分区插入,它能根据分区字段的内容自动创建分区,并在每个分区插入相应的内容。
动态分区插入
使用动态插入分区需设置:hive.exec.dynamic.partition.mode=nonstrict.
使用命令alter table employees_p drop partition (state='Oak Park IL');可删除分区。
动态分区插入方式如下:

from employees insert overwrite table employees_p partition(state) select name,salary,subordinates,deductions,address,address.state;
注意的是:我们需要将分区字段在select语句中写明,这样会比原表多一个字段,此处我们的分区字段是address.state。
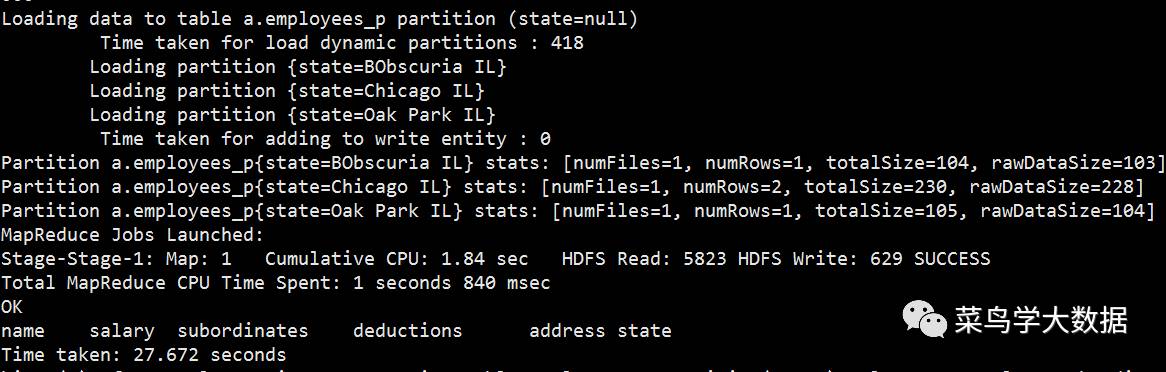
我们得到了三个分区。在hdfs中的hive/warehouse目录查看:
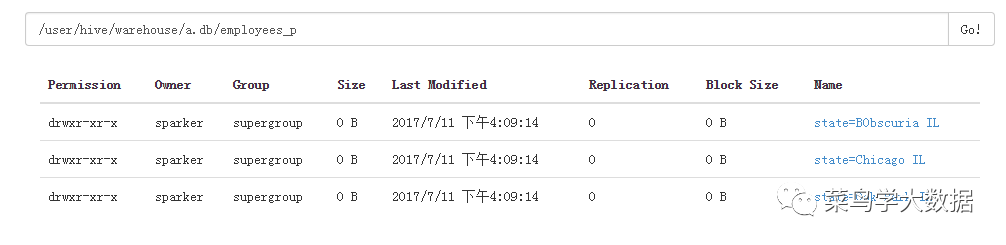
分区表介绍完毕。
如有问题,欢迎指正。
