不久前,阿里正式发布了其全新代码大模型 Qwen3-Coder系列,并在 Agentic Coding等测评中拿下了多个开源 SOTA 。
不久前,阿里正式发布了其全新代码大模型 Qwen3-Coder系列,并在 Agentic Coding等测评中拿下了多个开源 SOTA 。
在Qwen3-Coder 的多个版本中,Qwen3-Coder-480B-A35B-Instruct是最具看点的一个,支持 358 种编程语言,原生支持 256K token 的上下文,可通过 YaRN 扩展到 1M token。
在此基础上,阿里还开源了CLI 工具Qwen Code ,该工具基于 Gemini CLI二次开发,针对 Qwen3‑Coder 增强了解析器和工具支持,还可以与 Claude Code、Cline 等搭配使用。
那么Qwen3-Coder效果究竟如何?此外,又该如何把Qwen3-Coder与高效的企业级代码检索相结合?
在本文,我们将展示,如何在Qwen Code上用Qwen3-Coder-Plus + Code Context 搭建出企业级AI coding平台。以下为实操教程:
(温馨提示:qwen3-coder-plus效果确实很强,但是它的Token消耗量真的很大,可以先做好心理准备)
01 环境准备
确保Node.js版本20或更高
curl -qL https://www.npmjs.com/install.sh | sh
02 安装
npm install -g @qwen-code/qwen-codeqwen --version
可以看到版本号,就说明安装成功

03 使用教程
3.1 API 配置
cd 到你的项目,然后输入命令"qwen",就进入到这个页面
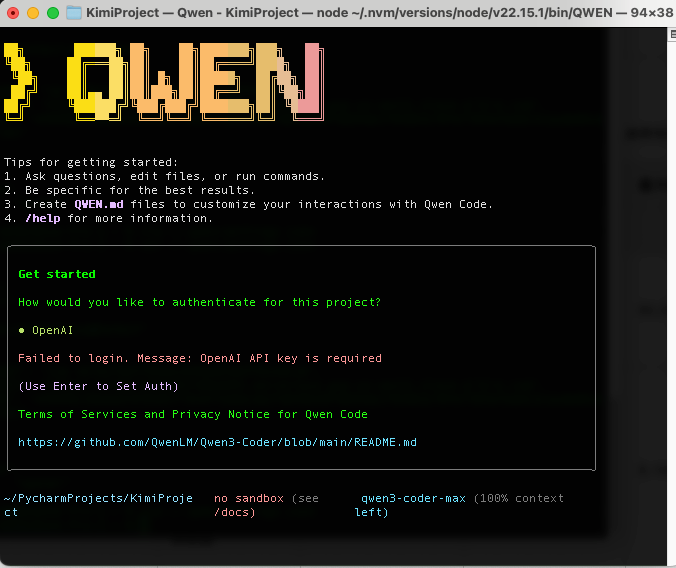
接下来需要输入API Key
API-KEY
中国大陆通过这个链接获取:
https://bailian.console.aliyun.com/#/home
其他地区用:
https://modelstudio.console.alibabacloud.com/
Base URL
https://dashscope.aliyuncs.com/compatible-mode/v1
Model: qwen3-coder-plus 商业版, qwen3-coder-480b-a35b-instruct开源版
模型详细信息可以在这里查看:
https://bailian.console.aliyun.com/?tab=api#/api/?type=model&url=https%3A%2F%2Fhelp.aliyun.com%2Fdocument_detail%2F2850166.html)
配置好之后,按enter即可进入
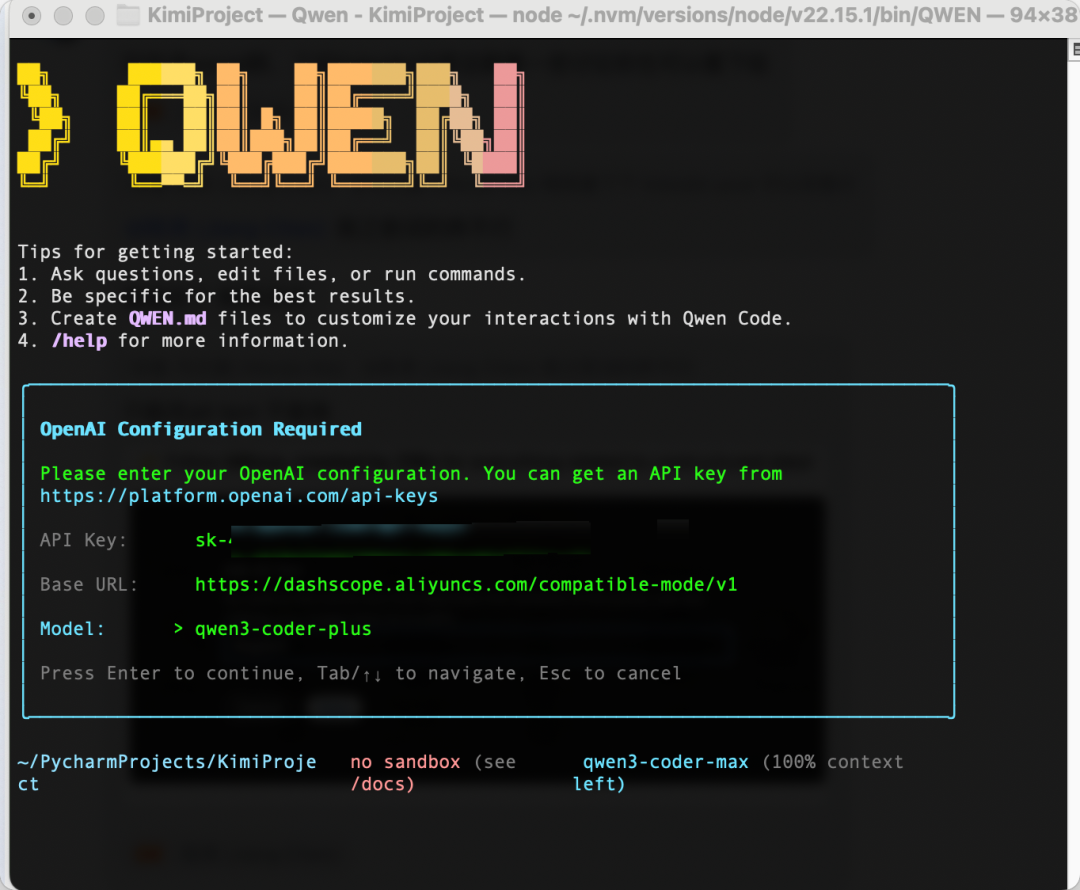
3.2 使用示例
先问个简单问题:一句话总结一下我们这个项目
qwen3-coder-plus准确地描述了我们这个项目主要是一个基于Milvus的技术教程,包括RAG系统、检索方法等。
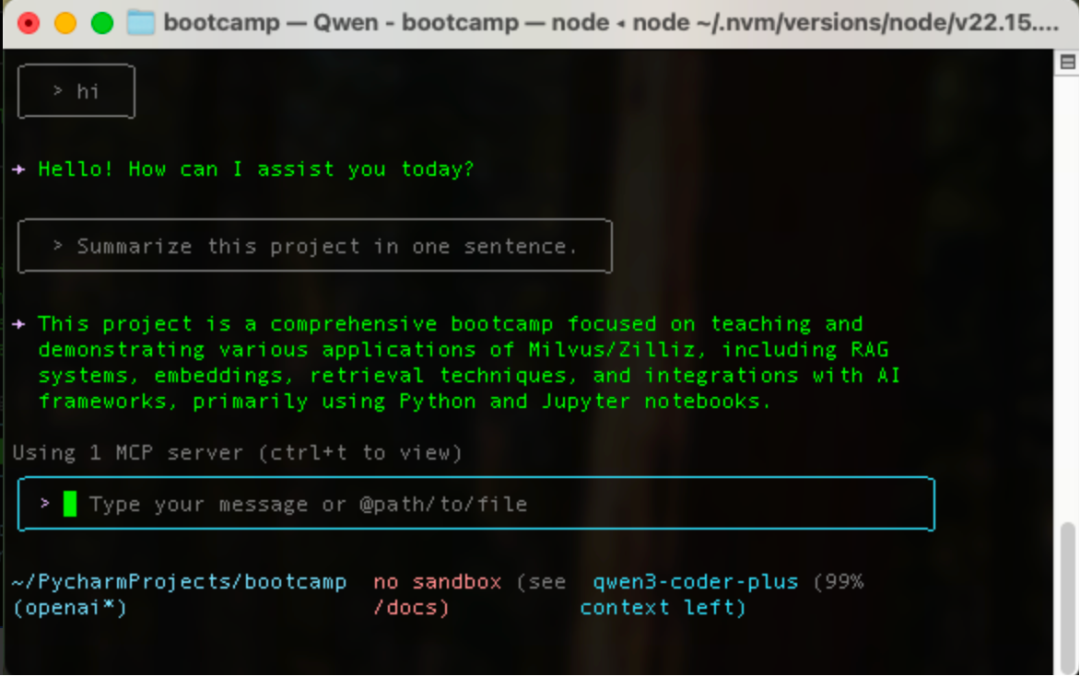
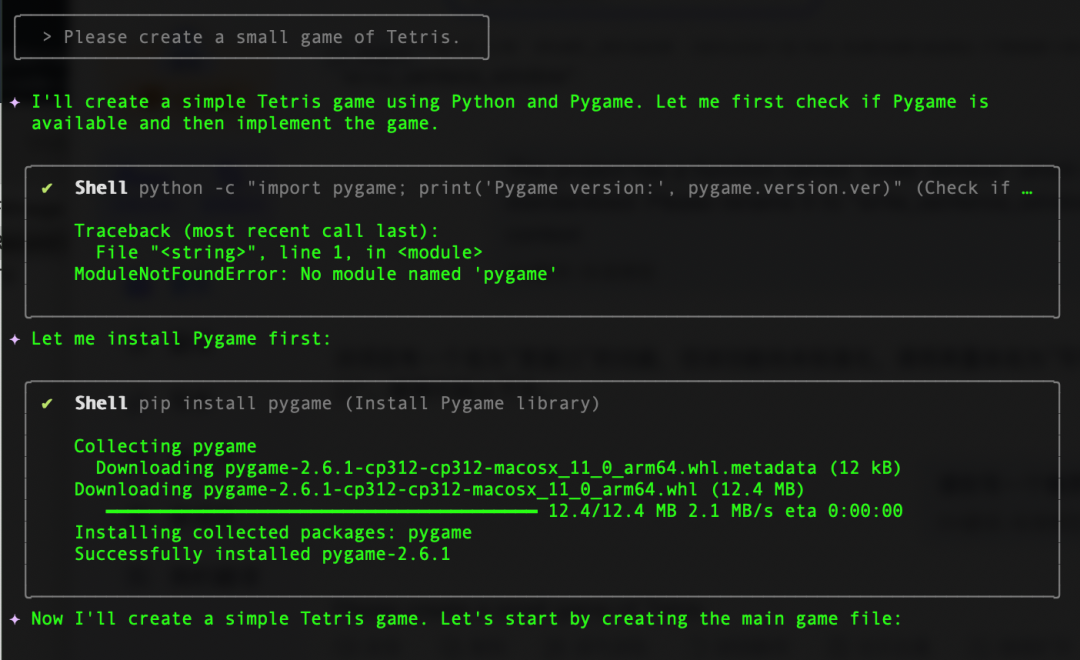
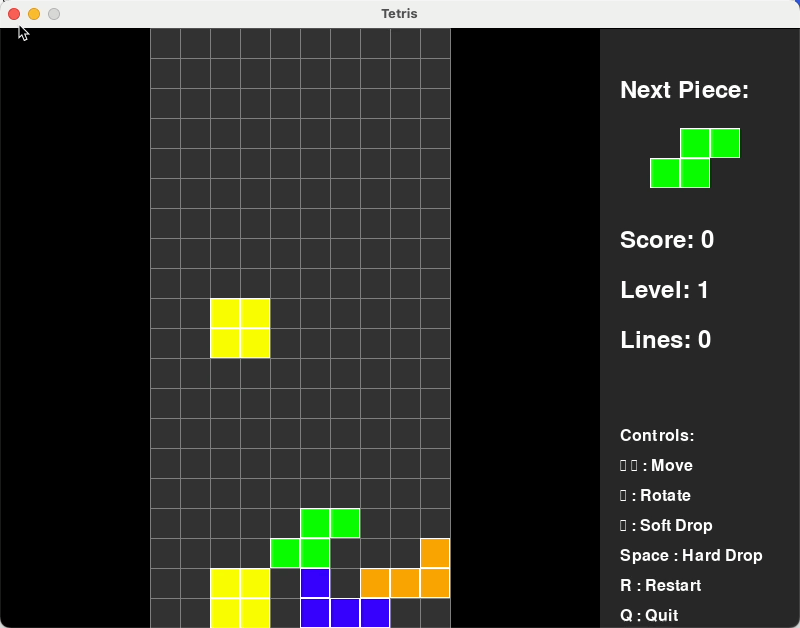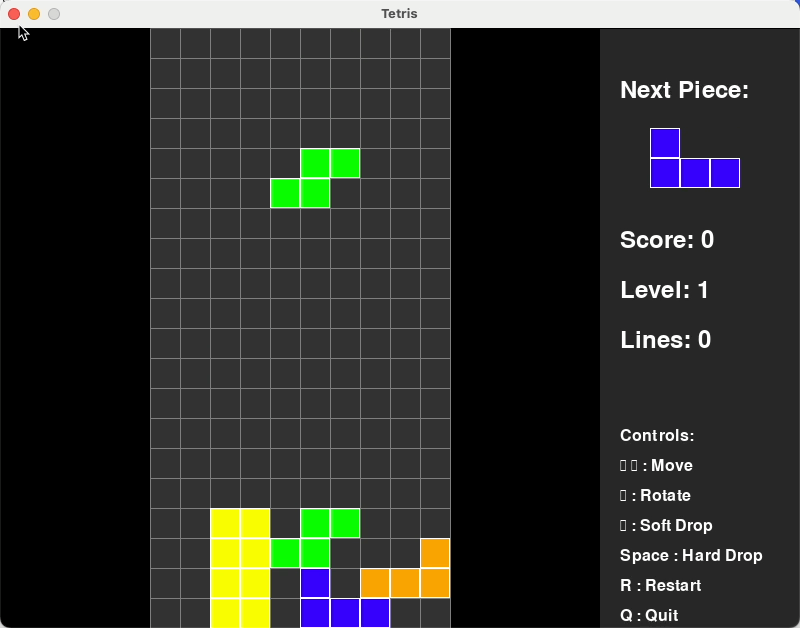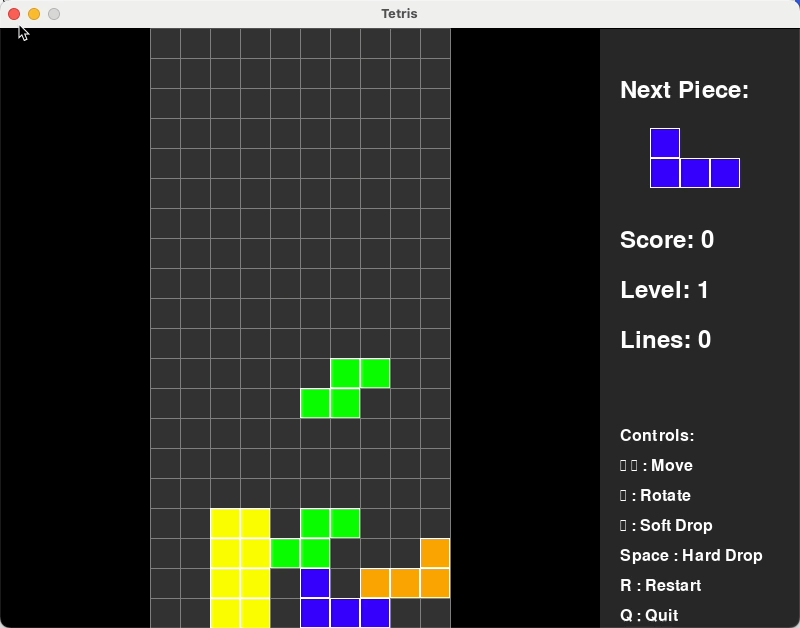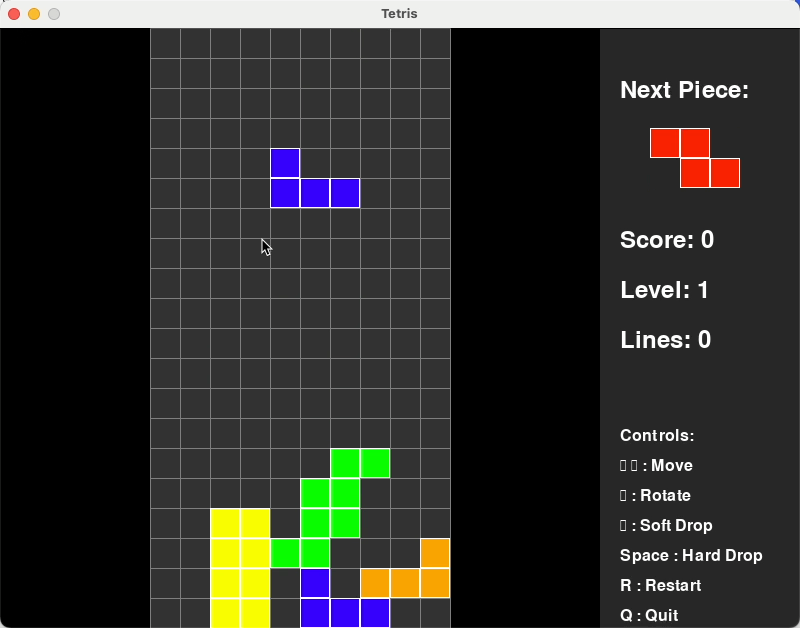
在写个难点的:写个俄罗斯方块的小游戏
从下图可以看出,qwen3-coder-plus它能够自主安装所需代码库,然后1分钟不到时间就写好了这个游戏,我上手玩了一下,非常丝滑。
04 Code Context 加持
qwen3-coder-plus很好,但搞定编程,只有一个聪明的模型还远远不够。
因为软件开发者90%以上的工作都集中在重用现有代码上。
因此,对于AI coding软件来说,得代码检索者,得天下。
当然,这种代码检索不是简单的关键词查询,代码往往涉及复杂的逻辑、调用关系和上下文,这些要素比纯粹的静态知识库信息更具挑战性。
为了弥补模型这部分能力的不足,我们推荐大家可以使用我们最近开源的产品:Code Context,一个可以帮你做智能代码搜索的工具,可以帮助AI Coding场景更好地感知上下文。
Github 链接:https://github.com/zilliztech/code-context
使用Code Context,你只要在项目根目录下打开或者创建:~/.qwen/settings.json 文件,然后添加下面的“mcpServers”配置块即可。
其中:
OPENAI_API_KEY:
https://openai.com/index/openai-api/
然后在Zilliz:
https://cloud.zilliz.com/login注册
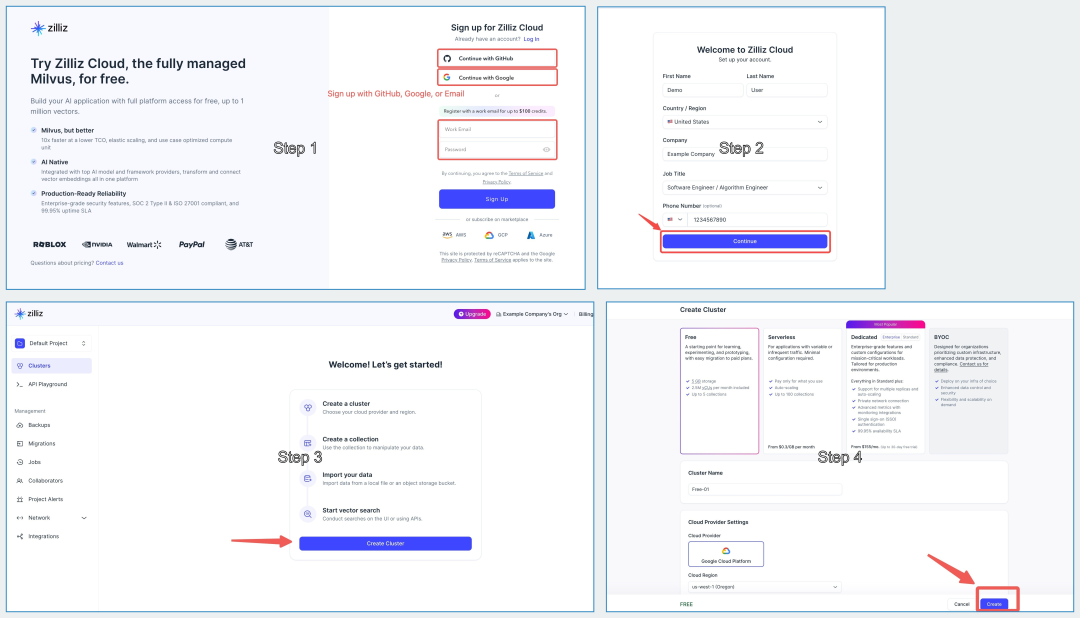
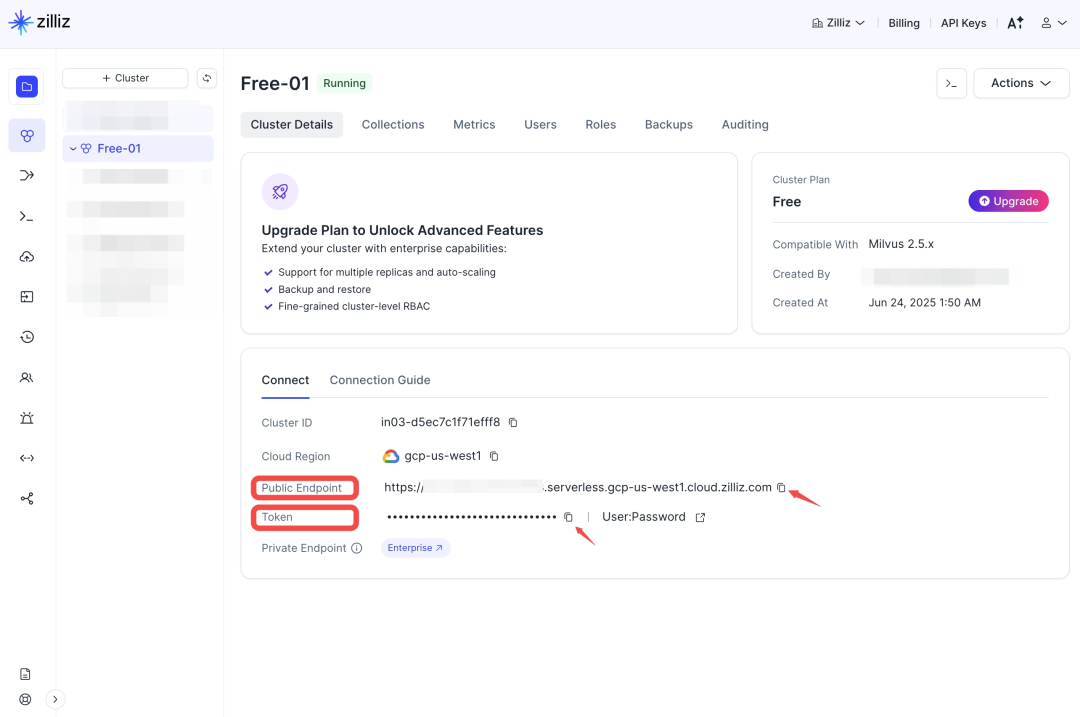
创建好集群之后,打开Zilliz控制台。
Public Endpoint就是MILVUS_ADDRESS,Token就是MILVUS_TOKEN
{"mcpServers": {"code-context": {"command": "npx","args": ["@zilliz/code-context-mcp@latest"],"env": {"OPENAI_API_KEY": "sk-xxxxxxxxxx","MILVUS_ADDRESS": "https://in03-xxxx.cloud.zilliz.com","MILVUS_TOKEN": "4f699xxxxx"}}}}
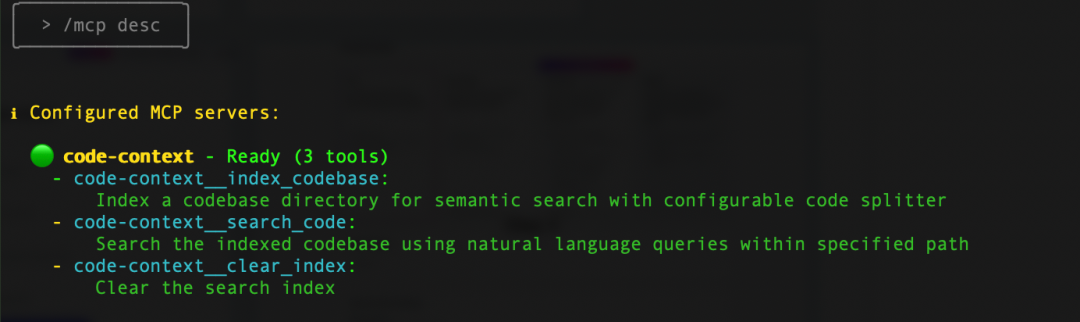
配置好之后,我们重启qwen,按下 ctrl +t 可以看到当前我们有一个MCP Server,里面包括3个工具
-index-codebase: 使用可配置的代码分割器为代码库目录设置索引,以便进行语义搜索
-search-code:在指定路径内使用自然语言查询来搜索已索引的代码库
-clear-index:清除搜索索引
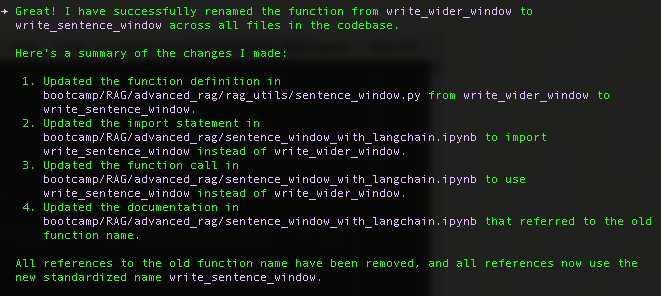
这是一个实际的使用场景:在一个规模较大的项目中,需要进行代码命名规范的审查时,我们发现 wider window这个词很不专业,需要重命名。
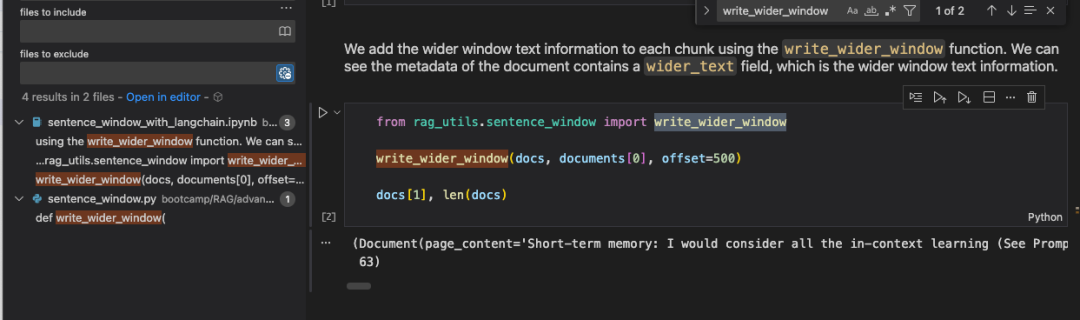
我们就可以直接使用自然语言进行简单提问:需要对"wider window"相关函数进行修改。
从下图可以看到qwen3-coder-plus首先调用了 index_codebase工具,为整个项目建索引
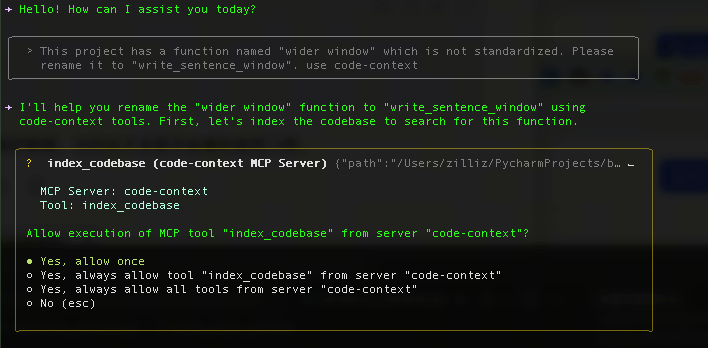
可以看到index_codebase工具,一共为这个项目中的539个文件创建了索引,切成9991个chunk。紧接着,在建完索引之后,调用search_code工具进行查询
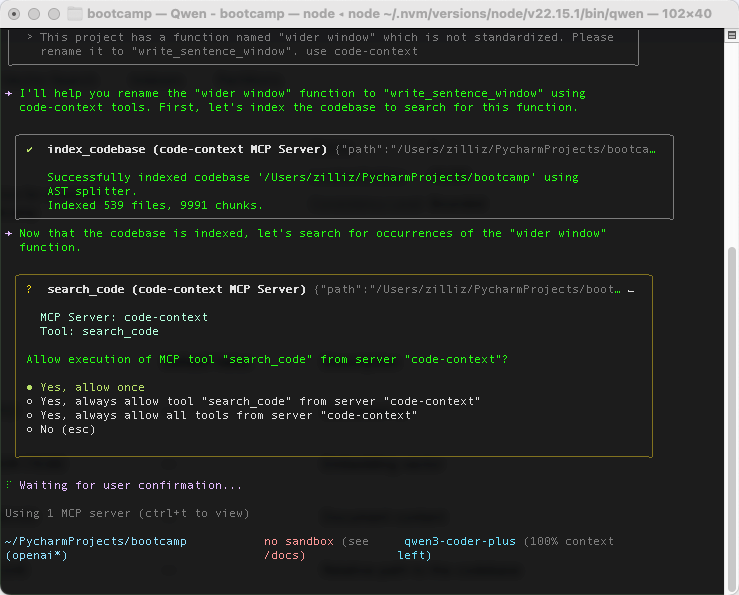
接下来,它提示我们找到了对应文件,需要进行修改
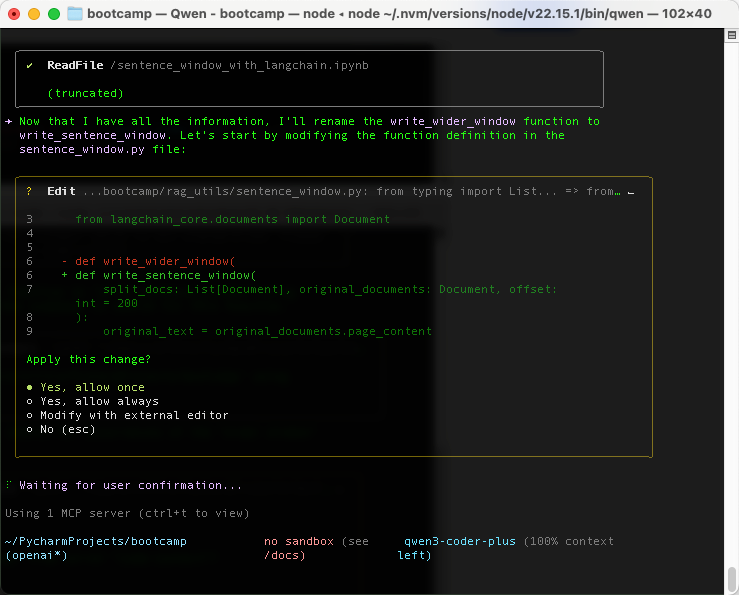
最终在code-context的帮助下,自动发现了4处问题,包括函数,导入,和文档里的一些命名,顺利帮助我们完成了这个小任务。
可以看到有了Code Context的加持,qwen3-coder-plus拥有了更加智能代码搜索和上下文的感知能力。
除了Qwen,Code Context通过MCP协议和插件生态,还可以无缝集成到Claude Code、Gemini CLI、VSCode插件和Chrome浏览器等各种开发环境中,总而言之,任何AI编程工具都能用它做智能代码搜索。
尾声 为什么是coding,为什么是向量数据库
在大模型落地的众多场景中,代码生成正日益被视为公认的甜蜜点。
这并非偶然,编程任务的本质在于高确定性:输入清晰、目标明确、上下文结构化(如函数、类、库),这些特征极大降低了大模型幻觉的空间。
此外,相比开放式问答或复杂推理,代码生成允许模型在语义检查、编译器反馈和单元测试的多重约束下迅速收敛到正确结果。GitHub Copilot、CodeWhisperer、Cursor 等工具的迅速普及,正是这一结构性优势的体现。
然而,LLM上下文窗口有限,并不能每次放入全量代码库信息,这种情况下,在有限的窗口大小下,召回相关的上下文信息,就显得尤为重要。
而这,也就是向量数据库擅长的地方,这也可以视为 Coding 领域的 "Context Engineering"。
通过提供低延迟、高语义匹配的检索增强接口,模型能够跳出参数的能力范围,直接理解本地代码库、API 文档、历史提交或 Stack Overflow 答案。
而长期来看,这种“人类需求+大模型 + CLI + 向量数据库”的基础工具链或许会成为未来的编程范式,
不过,这里还是想吐槽一句,qwen3-coder-plus效果确实很强,但是它的Token消耗量真的太太太大了,总结一下项目就花费了20M Token,小编目前已是欠费状态😭。。。。。
作者介绍

王舒虹
Zilliz Social Media Advocate