




💡 目录 💡
01 LLM 服务实现负载均衡的难点
02 技术选型:Envoy 原生、Higress、AIBrix
03 负载均衡算法
04 使用方法
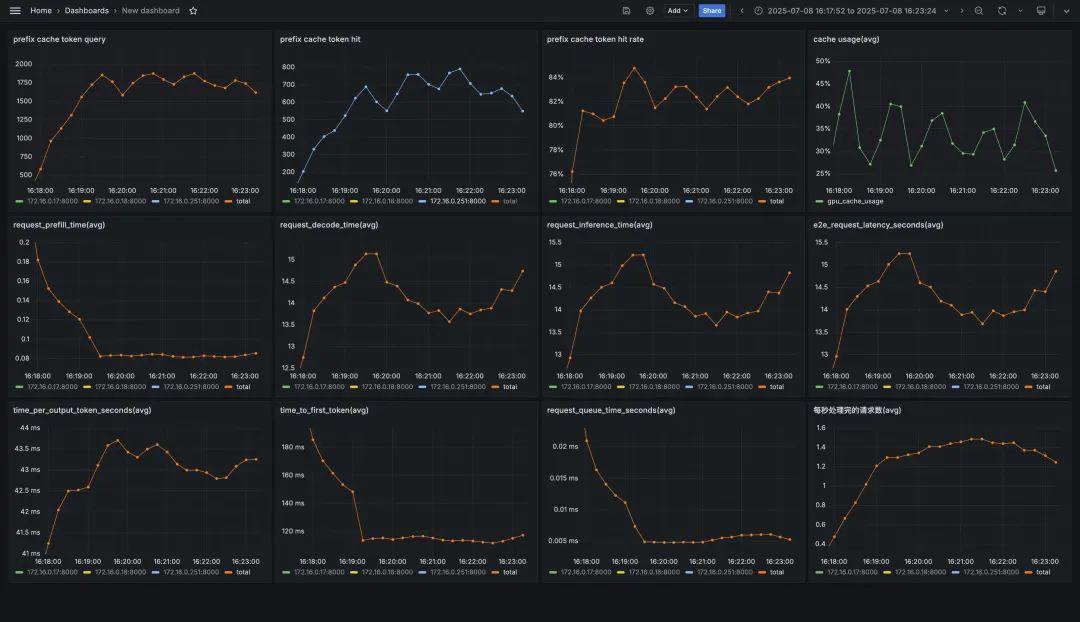
05 压测结果与 vLLM 监控大盘比对
01
LLM 服务实现负载均衡的难点
传统的负载均衡算法主要设计用于通用的 Web 服务或微服务架构中,其目标是通过最小化响应时间、最大化吞吐量或保持服务器负载平衡来提高系统的整体效率,常见的负载均衡算法有轮询、随机、最小请求数、一致性哈希等。然而,在面对 LLM 服务时,这些传统方法往往暴露出以下几个关键缺陷:
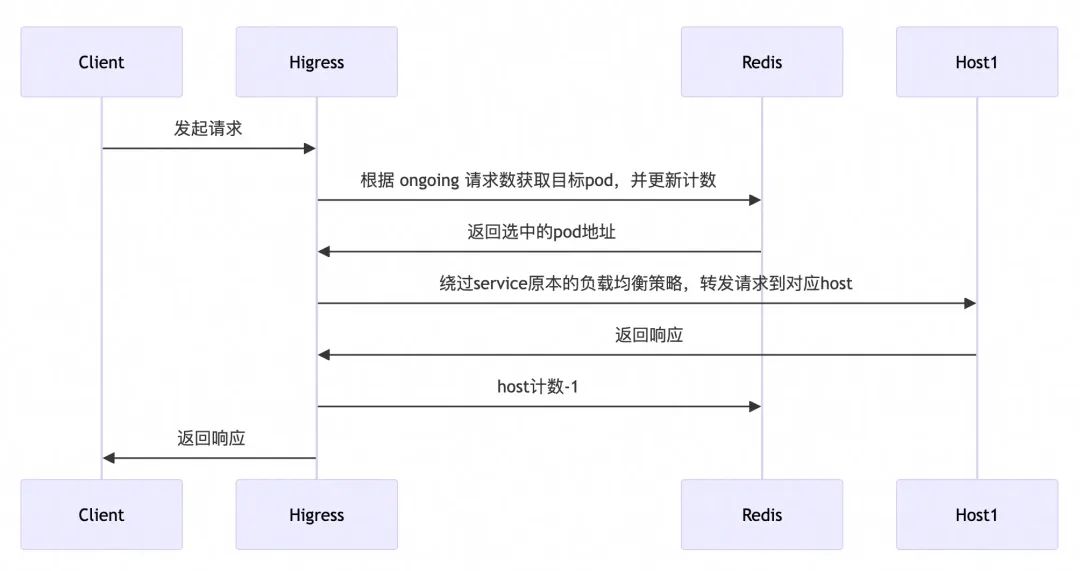
忽略任务复杂度差异:LLM 推理请求的复杂度差异极大。例如,一个长文本生成任务可能需要数十倍于短文本分类任务的计算资源。而传统负载均衡器无法感知这种差异,容易导致某些节点过载,而其他节点空闲,造成资源浪费和响应延迟。 缺乏对 GPU 资源水位的感知:在 LLM 推理服务中,计算瓶颈主要集中在 GPU 上,传统负载均衡器往往无法感知到这一细粒度的资源消耗情况,导致某些 GPU 节点因显存不足而拒绝请求或响应缓慢,而其他节点却处于空闲状态。 缺乏对 KV Cache 的复用能力:在并发请求处理中,如果多个请求具有相似的前缀,则它们的 KV Cache 可能存在重叠部分,可以通过共享或压缩的方式减少显存占用并提升生成速度。传统负载均衡策略并未考虑请求之间的语义相似性或 KV Cache 的可复用性,难以将具有潜在复用价值的请求分配到同一 GPU 实例上,从而错失优化机会。
针对 LLM 服务的特点,Higress AI 网关以插件形式提供了面向 LLM 服务的负载均衡算法,包括全局最小请求数负载均衡、前缀匹配负载均衡以及 GPU 感知负载均衡,能够在不增加硬件成本的前提下,提升系统的吞吐能力、降低响应延迟,并实现更公平、高效的任务调度。
以前缀匹配负载均衡为例,压测工具使用 NVIDIA GenAI-Perf,设置每轮输入平均为 200 token,输出平均为 800 token,并发为 20,每个会话包含 5 轮对话,共计 60 个会话,性能指标前后对比如下:
指标 | 无负载均衡 | 前缀匹配负载均衡 |
TTFT(首Token延迟) | 240 ms | 120 ms |
平均 RT | 14934.85 ms | 14402.36 ms |
P99 RT | 35345.65 ms | 30215.01 ms |
Token 吞吐 | 367.48 (token/s) | 418.96 (token/s) |
Prefix Cache 命中率 | 40 % + | 80 % + |
02
技术选型
目前已经有很多优秀的开源项目,例如 Envoy AI Gateway、AIBrix 等,基于 Envoy External Processing 机制外接一个负载均衡器实现面向 LLM 的负载均衡,负载均衡器以 sidecar 或者 K8s 服务形式部署。
Higress AI 网关以 wasm 插件形式提供了面向 LLM 服务的核心负载均衡能力,具有如下特点:
免运维:以 wasm 形式提供负载均衡能力,不需要用户额外维护 sidecar,只需要在 Higress 控制台开启插件即可,部署运维成本大大降低。 热插拔:即插即用,用户仅需要在控制台进行策略配置即可,开启插件时采用面向 LLM 服务的专属负载均衡策略,关掉插件后自动切换为服务基础的负载均衡策略(轮询、最小请求数、随机、一致性哈希)。 易扩展:插件本身提供了多种负载均衡算法,并且在不断丰富完善中,采用Go 1.24 编写,代码开源,如果有特殊需求,用户可以基于现有插件进行定制。 全局视野:借助 Redis,网关的多个节点具有全局视野,负载均衡更加公平、高效。 细粒度控制:插件可以在实例级、域名级、路由级、服务级等不同粒度进行生效,方便用户做细粒度的控制。
03
负载均衡算法
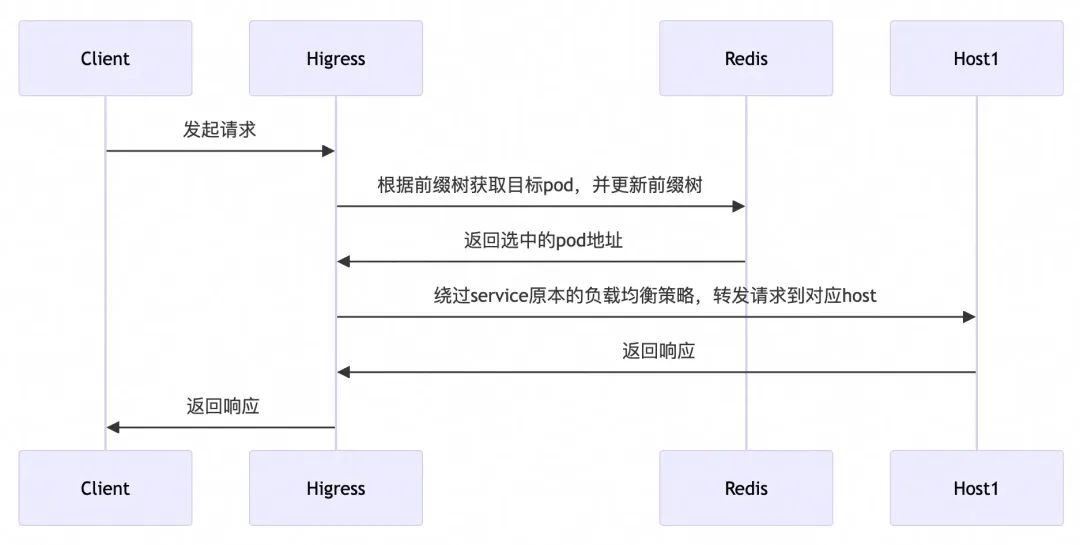

假设有一个请求被划分成了 n 个 block,在进行前缀匹配时:
sha-1(block 1)是否存在
如果不存在,前缀匹配失败,采用全局最小请求数选择 pod,pod 选取结束,根据当前请求内容更新前缀树 如果存在,前缀匹配成功,记录当前的 pod,转步骤2
sha-1(block 1) XOR sha-1(block 2)是否存在
如果不存在,前缀匹配失败,步骤1中选出来的 pod 即为目标 pod,根据当前请求内容更新前缀树,pod 选取结束 如果存在,前缀匹配成功,转步骤3
sha-1(block 1) XOR sha-1(block 2) XOR ... XOR sha-1(block n)是否存在
如果不存在,前缀匹配失败,步骤2中选出来的 pod 即为目标 pod,根据当前请求内容更新前缀树,pod 选取结束 如果存在,前缀匹配成功,pod 选取结束
通过以上过程,能够将同一个会话的多次请求路由至同一个 pod,从而提高 KV Cache 的复用。
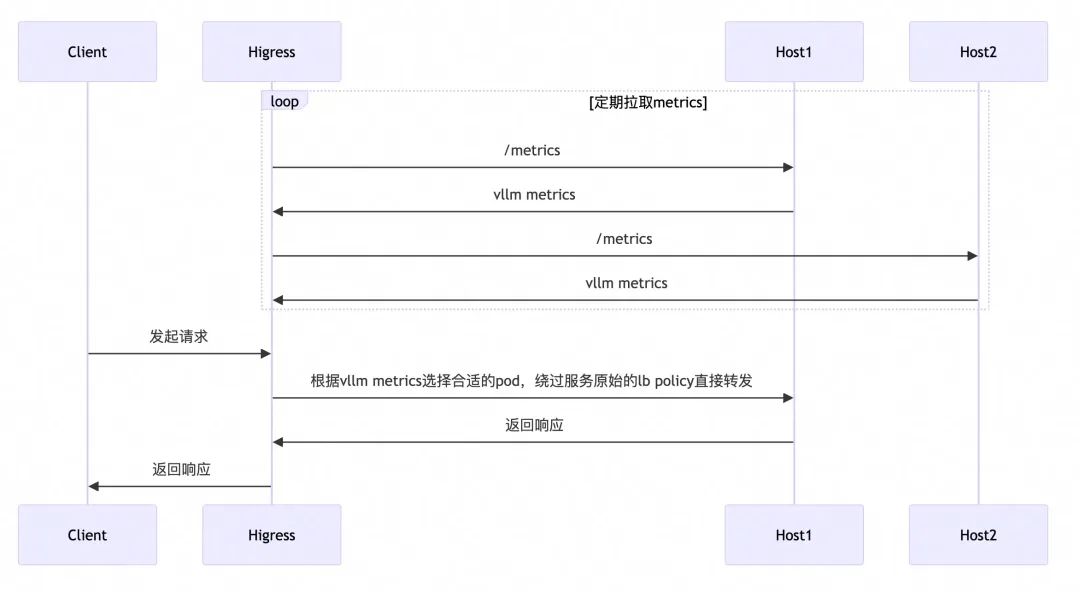
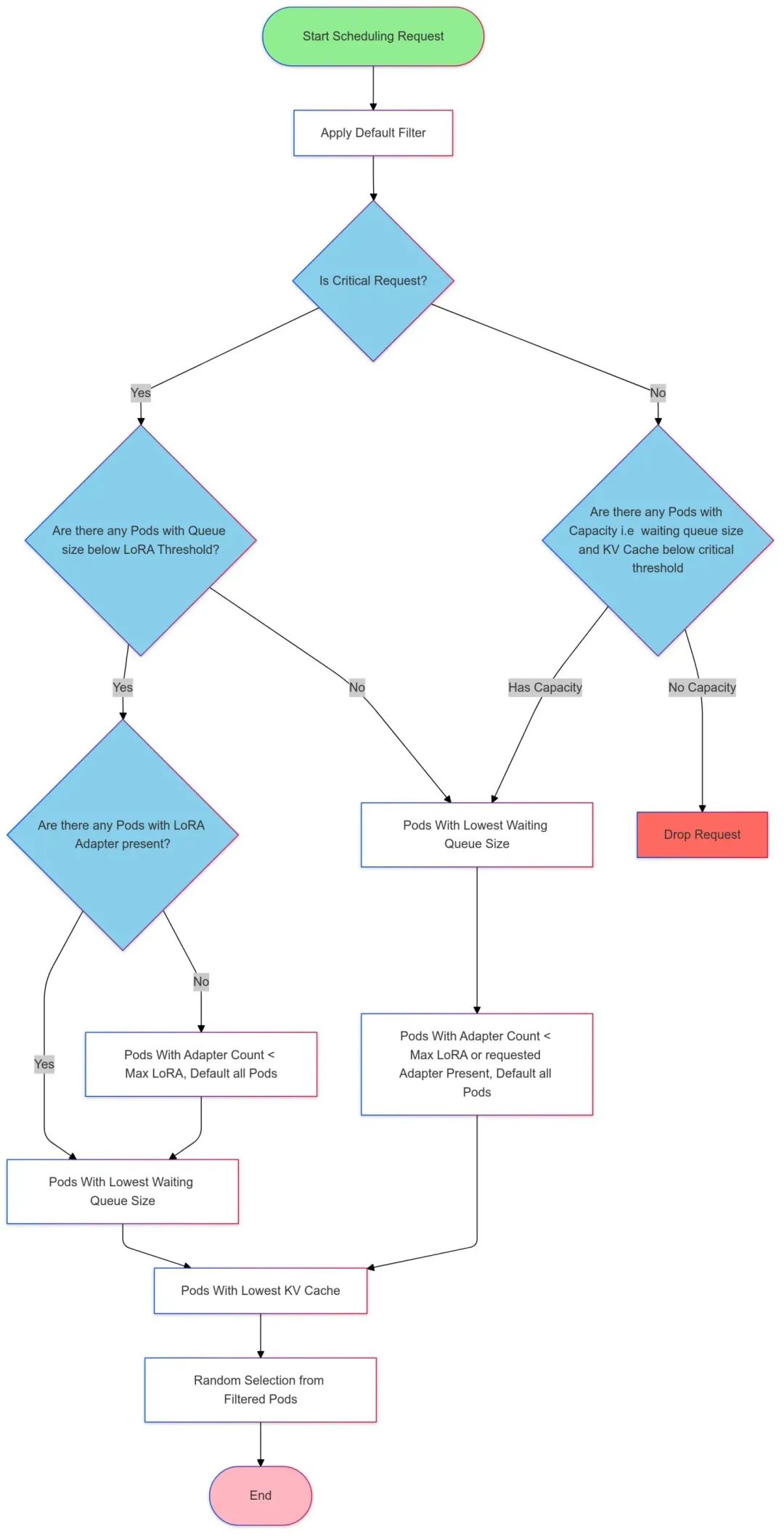
GPU 感知负载均衡
一些 LLM Server 框架(如vllm、sglang等)自身会暴露一些监控指标,这些指标能够实时反应 GPU 负载信息,基于这些监控指标可以实现 GPU 感知的负载均衡算法,使流量调度更加适合 LLM 服务。
目前已经有一些开源项目基于 envoy ext-proc 机制实现了 GPU 感知的负载均衡算法,但 ext-proc 机制需要借助一个外部进程,部署与维护较为复杂,Higress AI 网关实现了后台定期拉取 metrics 的机制(目前支持 vllm),以热插拔的插件形式提供了 GPU 感知的负载均衡能力,并且场景不局限于k8s环境,任何 Higress AI 网关支持的服务来源均可使用此能力。
04
使用方法
lb_policy: prefix_cache
lb_config:
serviceFQDN:redis.dns
servicePort:6379
username:default
password:xxxxxxxxxxxx
redisKeyTTL:60
05
压测结果与 vllm 监控大盘比对
无负载均衡
GenAI-Perf 统计结果如下:

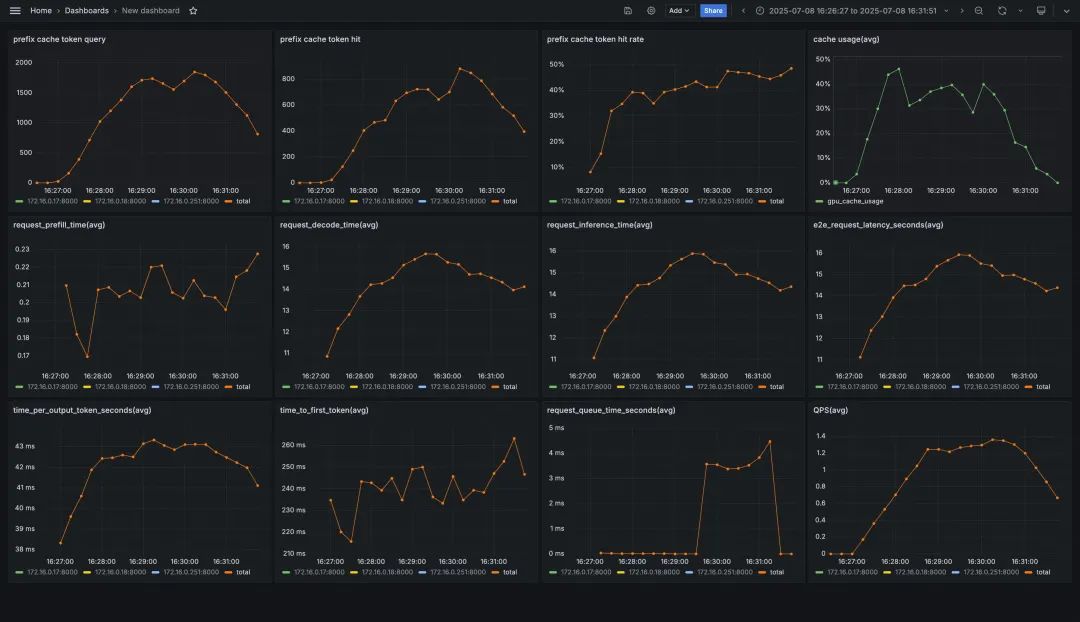
前缀匹配负载均衡
GenAI-Perf 统计结果如下:

LLM 负载均衡能力已在 Higress v2.1.5 中开源。
本文作者:

