





本文字数:9779;估计阅读时间:25 分钟
作者:The ClickStack team

本月初,我们发布了 ClickStack,这是一款基于 ClickHouse 构建的开源可观测性 (observability) 堆栈,让日志、指标、追踪和会话重放的统一变得比以往更加简单。其背后是同一款被 Netflix、eBay 等企业信赖的高性能引擎。
ClickStack 最大的优势之一在于,它将高基数、宽表事件数据的快速搜索与快速聚合结合在一个开源、低成本的解决方案中。通过采用 OpenTelemetry 进行数据采集,并以 HyperDX 作为 UI 层,ClickStack 提供了从数据摄取到强大可视化探索的完整开箱即用可观测性方案。
在 ClickHouse 的世界里,一个月就能带来巨大的变化。自首次发布以来,我们持续不断地为 ClickStack 增添新功能和改进,致力于让它更强大、更易用。从本月开始,我们会定期分享最新进展,帮助你快速在 ClickStack 部署中应用这些最新改进。

首先,我们要感谢本月的新开源贡献者。开源堆栈的构建离不开社区的共同努力,感谢每一位为 ClickStack 贡献力量的朋友——无论是通过 OpenTelemetry collector、Helm chart,还是 HyperDX。我们对你们的付出表示衷心感谢。
Huynguyen-anduin, OhJuhun, mGolestan98
本月 ClickStack 的最大更新虽简单,但意义重大。我们为 ClickStack 新增了对 ClickHouse 原生 JSON 列类型的测试版支持。这一功能为基于 ClickHouse 的可观测性 (observability) 工作负载带来了全新的扩展性、性能和压缩能力——在我们的测试中,查询速度相比 Map 类型最高提升了 9 倍。
为什么需要支持 JSON?
在构建可观测性解决方案时,用户往往希望能够直接“发送事件”,而不必受限于严格的 Schema。实际情况是,可观测性数据来源复杂多样——不同的应用、团队,甚至组织,各自的结构不断演变。尽管结构化日志和 OpenTelemetry 等标准有所帮助,但团队依然需要捕获任意数量、类型和层级的标签与字段。
此前,ClickStack 中用于 OpenTelemetry 数据的 Schema 主要依赖 Map 类型,来处理如 LogAttributes、ResourceAttributes 和 SpanAttributes 这类包含动态属性的列。尽管这种方案可行,但也存在明显的不足:
类型精度的损失:Map 的键和值都被存储为字符串,所有数据被强制转为单一类型。数值比较只能在查询时转换类型,既冗长又影响性能,同时占用更多内存。
单列顺序扫描:使用 Map 类型时,所有 JSON 路径都存储在一个列中,查询某个键时需要加载并扫描整个 Map。当键数量众多时,导致大量不必要的 I/O,查询效率低下。用户通常通过物化列来预先提取需要的值以规避这一问题。
不支持原生嵌套:Map 类型在处理原始值时尚可,但对嵌套的 Map 和数组支持较差,所有内容都被转成字符串。复杂数据需序列化成 JSON 字符串,查询繁琐且低效。例如,LogAttributes 结构中:
{"service.name": "user-service","service.version": "1.2.3","http.status_code": "200","user.preferences": "{\"theme\":\"dark\",\"notifications\":{\"email\":true,\"push\":false}}","error.stack": "[\"AuthError: Invalid token\",\" at validateToken (auth.js:45)\",\" at middleware (app.js:23)\"]"}
像 service.name 和 http.status_code 这样的原始值虽然能被自然存储,但失去了类型信息,无法直接进行数值或日期计算。而类似 user.preferences 和 error.stack 的复杂嵌套数据则被转为 JSON 字符串,查询和分析十分不便。如果要从 user.preferences 中提取布尔值,必须在 Map 的字符串值上使用 JSONExtractBool。
SELECT JSONExtractBool(LogAttributes['user.preferences'], 'notifications', 'email')
通过 ClickHouse 25.3 中正式推出的 JSON 类型,ClickStack 现在可以原生摄取和存储真正的半结构化数据。每个独立的 JSON 路径都对应自己的子列,类型得以保留,I/O 显著减少,查询性能大幅提升。即使是深度嵌套或不断变化的 Schema,也能高效处理。
想了解 JSON 类型在可观测性领域的高层次应用,可以参考我们去年发布的文章[https://clickhouse.com/blog/evolution-of-sql-based-observability-with-clickhouse]。如果你对底层实现细节感兴趣,欢迎阅读我们最初发布的博客,里面有详细介绍[https://clickhouse.com/blog/a-new-powerful-json-data-type-for-clickhouse]。
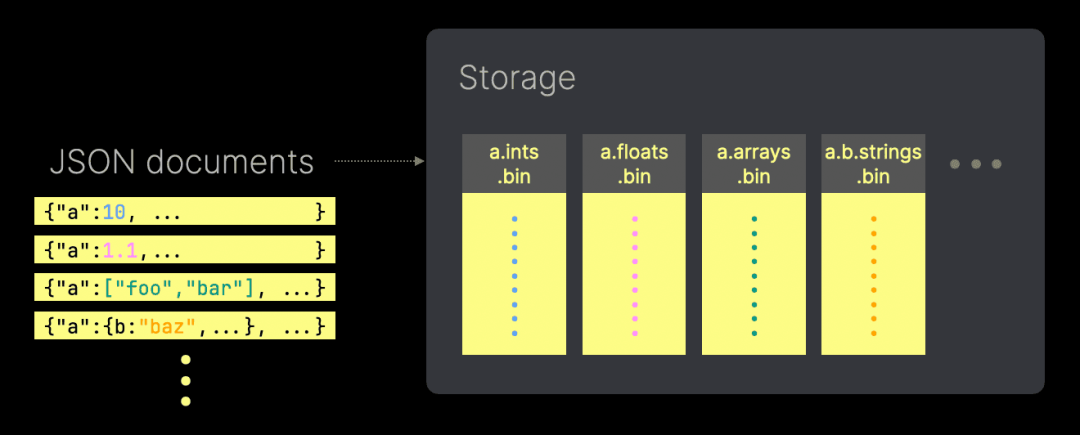
这意味着你可以直接将从 OpenTelemetry collectors 采集的增强型日志、追踪和指标发送至 ClickStack,无需担心严格的 Schema 或手动展开数据。ClickStack 的 UI 层 HyperDX 充分发挥了这一优势,支持更智能的过滤、JSON 路径的自动补全,以及更快速的搜索和可视化。
回到之前的示例——现在我们可以将所有数据以原始形式存储,完整保留其自然的结构与数据类型:
{"service": {"name": "user-service","version": "1.2.3"},"http": {"status_code": 200},"user": {"preferences": {"theme": "dark","notifications": {"email": true,"push": false}}},"error": {"stack": ["AuthError: Invalid token"," at validateToken (auth.js:45)"," at middleware (app.js:23)"]}}
查询也变得更加直观:
SELECT LogAttributes.user.preferences.notifications.email
返回的仍然是之前的布尔值,而且我们无需再去关心数据的嵌套层级或类型!
为 OpenTelemetry 添加支持
在支持 HyperDX 之前,我们首先需要确保 ClickStack 的每一层都能正确支持 JSON。要为 ClickHouse 的 OpenTelemetry exporter 增加支持,首先需要让 clickhouse-go 客户端支持 JSON 类型——exporter 在插入数据时使用这一客户端。客户端会将 JSON 列以序列化的 JSON 字符串插入,ClickHouse 再解析该字符串,自动识别新列及其类型。
此外,我们还对数据插入的逻辑进行了多项优化。我们更新了 Go 驱动,使其支持通过 ClickHouse 的原生 API 进行 TCP 和 HTTP 连接,这样在将 OpenTelemetry 的数据结构转换为 ClickHouse 的原生列式格式时,性能大幅提升。我们还借助 pprof 对主插入循环进行了性能分析和优化,大多数优化点集中在对 OpenTelemetry 结构中 getter 的冗余调用。
ClickHouse exporter 对 JSON 的支持最近已通过 feature flag 合并[https://github.com/open-telemetry/opentelemetry-collector-contrib/pull/40547]。通过这一改动,所有原本使用 Map 类型的列现已全面切换为 JSON 类型。
为 HyperDX 添加支持
在 OpenTelemetry Collector 支持 JSON 类型后,我们将注意力转向了 UI 层 HyperDX 的适配。
为了在 HyperDX 中实现对 JSON 的完整支持,我们需要更新 UI 以支持嵌套对象,这在过去的 Map 类型中是难以实现的。因此,我们对前端的多个组件进行了重构,以便能够正确渲染和交互深度结构化的 JSON 数据。同时,部分查询也需要重写,采用新的 JSON 路径符号来高效访问嵌套字段。当前阶段,部分操作仍然需要将 JSON 值转换为字符串或浮点数,但未来我们计划引入更智能的元数据缓存机制,这样在字段类型始终一致的情况下,就可以完全跳过类型转换。
展望未来,我们还将继续优化 Schema,增设更多针对 JSON 工作负载的索引和性能优化,进一步提升 ClickStack 架构下的查询性能。
如何启用 JSON 支持?
目前,JSON 支持仍处于测试阶段,可以在部署任一堆栈模式时,通过 feature flag 启用[https://clickhouse.com/docs/use-cases/observability/clickstack/getting-started]。
docker run -e BETA_CH_OTEL_JSON_SCHEMA_ENABLED=true -e OTEL_AGENT_FEATURE_GATE_ARG='--feature-gates=clickhouse.json' -p 8080:8080 -p 4317:4317 -p 4318:4318 docker.hyperdx.io/hyperdx/hyperdx-all-in-one:2-nightly
启用 JSON 类型支持需要配置两个环境变量:
BETA_CH_OTEL_JSON_SCHEMA_ENABLED=true 用于在 ClickHouse 中启用 JSON 支持,OTEL_AGENT_FEATURE_GATE_ARG='--feature-gates=clickhouse.json' 用于在 OTel collector 中开启 JSON 数据摄取。
如果你想通过示例数据体验 JSON 类型,可以参考我们的入门指南[https://clickhouse.com/docs/use-cases/observability/clickstack/getting-started/sample-data],里面提供了公共数据集。我们非常期待听到你的反馈,欢迎在我们的公共仓库提交 issue 或建议[https://github.com/hyperdxio/hyperdx/tree/main]。
现在,JSON 已在整个堆栈中实现了支持,用户几乎无需感知就能立即受益。
需要注意的是,JSON 类型的引入带来了全新的 Schema,与旧的基于 Map 的 Schema 不兼容。希望使用 JSON 的用户,可以选择在 HyperDX 中为基于 JSON 的 Schema 配置单独的数据源,或通过简单的 INSERT INTO ... SELECT 操作来迁移现有数据。
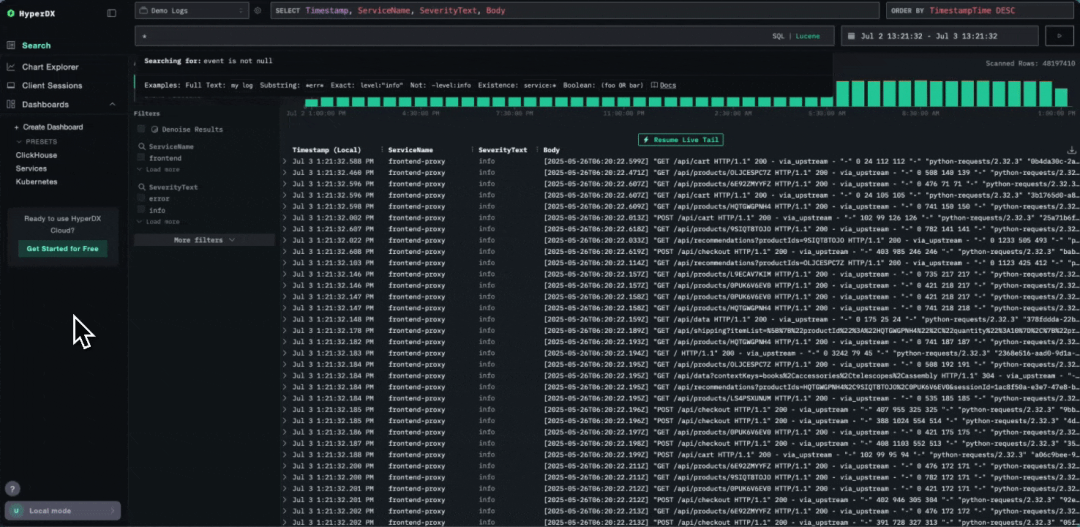
整体的用户体验几乎没有变化,不过在查看如 LogAttributes 等属性列时,视觉上会有一些细微的不同。以前的层级结构会被扁平化,子层级通过点符号表示(例如 k8s.pod.name),而现在,属性结构以完整的层级形式呈现。
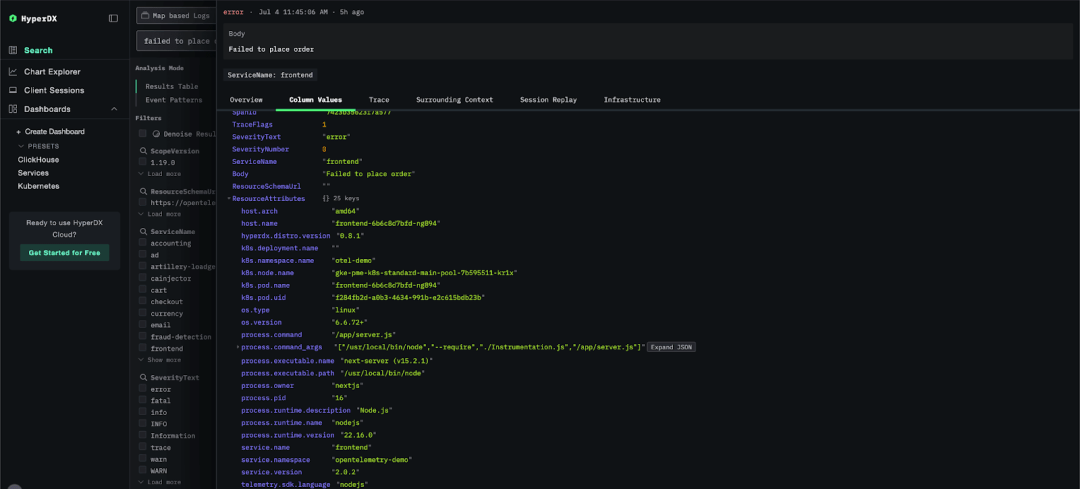
基于 Map 类型的属性渲染
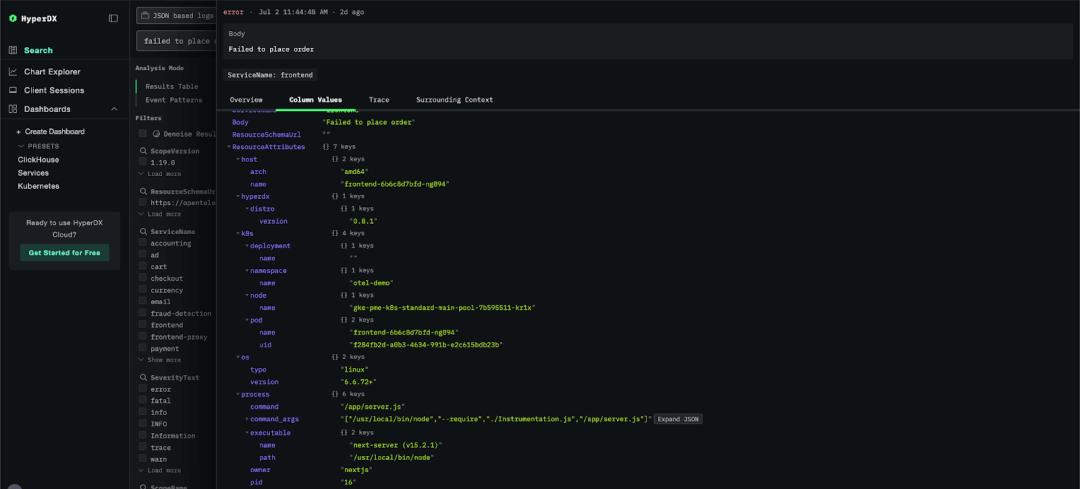
基于 JSON 类型的层级属性渲染
那么 JSON 类型到底有多大提升?
得益于 HyperDX 对列自动补全和类 Lucene 查询构造的支持,用户最直观的收益就是 OTel 列(如 LogAttributes 等属性)上的查询速度大幅提升,I/O 明显减少。更重要的是,属性的真实数据类型得以保留,不再像之前那样全部转换为字符串。这意味着,当你传入数值或日期类型的属性时,类型信息不会丢失,能够直接高效地进行比较。
为了让这种优势更直观,我们以 ClickStack playground(play-clickstack.clickhouse.com,底层是 sql.clickhouse.com 的 ClickHouse 实例)中的示例日志 OTel 数据集为例,该数据集大约有 9000 万行。以下是基于 Map 类型的 Schema:
CREATE TABLE otel_v2.otel_logs(`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),`TimestampTime` DateTime DEFAULT toDateTime(Timestamp),`TraceId` String CODEC(ZSTD(1)),`SpanId` String CODEC(ZSTD(1)),`TraceFlags` UInt8,`SeverityText` LowCardinality(String) CODEC(ZSTD(1)),`SeverityNumber` UInt8,`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),`Body` String CODEC(ZSTD(1)),`ResourceSchemaUrl` LowCardinality(String) CODEC(ZSTD(1)),`ResourceAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),`ScopeSchemaUrl` LowCardinality(String) CODEC(ZSTD(1)),`ScopeName` String CODEC(ZSTD(1)),`ScopeVersion` LowCardinality(String) CODEC(ZSTD(1)),`ScopeAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),`LogAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),INDEX idx_trace_id TraceId TYPE bloom_filter(0.001) GRANULARITY 1,INDEX idx_res_attr_key mapKeys(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,INDEX idx_res_attr_value mapValues(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,INDEX idx_scope_attr_key mapKeys(ScopeAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,INDEX idx_scope_attr_value mapValues(ScopeAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,INDEX idx_log_attr_key mapKeys(LogAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,INDEX idx_log_attr_value mapValues(LogAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,INDEX idx_body Body TYPE tokenbf_v1(32768, 3, 0) GRANULARITY 8)ENGINE = MergeTreePARTITION BY toDate(TimestampTime)PRIMARY KEY (ServiceName, TimestampTime)ORDER BY (ServiceName, TimestampTime, Timestamp)
对应的基于 JSON 类型的 Schema:
CREATE TABLE otel_json.otel_logs(`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),`TimestampTime` DateTime DEFAULT toDateTime(Timestamp),`TraceId` String CODEC(ZSTD(1)),`SpanId` String CODEC(ZSTD(1)),`TraceFlags` UInt8,`SeverityText` LowCardinality(String) CODEC(ZSTD(1)),`SeverityNumber` UInt8,`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),`Body` String CODEC(ZSTD(1)),`ResourceSchemaUrl` LowCardinality(String) CODEC(ZSTD(1)),`ResourceAttributes` JSON CODEC(ZSTD(1)),`ScopeSchemaUrl` LowCardinality(String) CODEC(ZSTD(1)),`ScopeName` String CODEC(ZSTD(1)),`ScopeVersion` LowCardinality(String) CODEC(ZSTD(1)),`ScopeAttributes` JSON CODEC(ZSTD(1)),`LogAttributes` JSON CODEC(ZSTD(1)),INDEX idx_body Body TYPE tokenbf_v1(32768, 3, 0) GRANULARITY 8)ENGINE = MergeTreePARTITION BY toDate(TimestampTime)PRIMARY KEY (ServiceName, TimestampTime)ORDER BY (ServiceName, TimestampTime, Timestamp)
你会发现,新的 Schema 明显简洁了不少,主要是因为 Map 类型的键和值不再需要布隆过滤器。ResourceAttributes、ScopeAttributes 和 LogAttributes 中的各个字段现在都作为独立的子列存储,布隆过滤器因此变得不再必要。
比如我们希望查看每个 pod 的日志流量。虽然 HyperDX 会自动生成查询语句,但底层的 SQL(这里是简化版)本质上是一次聚合操作。使用 Map 类型时:
SELECTResourceAttributes['k8s.pod.name'] AS pod_name,count() AS cFROM otel_v2.otel_logs WHERE pod_name !=''GROUP BY pod_nameORDER BY c DESCLIMIT 10
这里有几个关键点:查询耗时 2.7 秒,扫描了整个数据集,内存占用 1.6GB,读取的数据量高达 30GB!
这种巨量的数据读取正是 Map 类型的瓶颈所在。因为所有子字段都存储在同一个 LogAttributes 列中,哪怕只要 JSON 字段 'k8s.pod.name',也不得不读取整列。
相比之下,使用 JSON 类型查询同一字段时,'k8s.pod.name' 已经作为单独的列存在。
SELECTCAST(ResourceAttributes.k8s.pod.name, 'String') AS pod_name,count() AS cFROM otel_json.otel_logs WHERE pod_name !=''GROUP BY pod_nameORDER BY c DESCLIMIT 10
性能提升极其显著——查询速度快了 9 倍。虽然处理的行数一样,但实际读取的数据量减少了超过 10 倍,仅读取了所需列的对应值。
虽然 JSON 类型是本月 ClickStack 更新的明星功能,但我们的优化远不止于此。我们在 ClickStack 的多个细节上都做了精心打磨,虽然每项改动都不算巨大,但整体体验却因此变得更加流畅和愉悦。以下是一些亮点更新。
Helm chart 的增强
本月,我们对 HyperDX 的 Helm chart 进行了多项优化,帮助用户部署更灵活、更易掌控。主要更新包括:支持接入自有的 MongoDB 服务[https://github.com/hyperdxio/helm-charts/pull/29]、配置自定义的 ClickHouse 用户凭据[https://github.com/hyperdxio/helm-charts/pull/26]、优化 PVC 配置[https://github.com/hyperdxio/helm-charts/pull/32]。此外,还增加了对 nodeSelector 和 tolerations 的支持[https://github.com/hyperdxio/helm-charts/pull/56]、服务类型及注解的配置能力[https://github.com/hyperdxio/helm-charts/pull/57]、HyperDX [https://github.com/hyperdxio/helm-charts/pull/44]及应用[https://github.com/hyperdxio/helm-charts/pull/41]的 ingress 能力增强,以及 OpenTelemetry collector 支持设置自定义环境变量[https://github.com/hyperdxio/helm-charts/pull/46]。这些改进让用户可以根据自身基础设施与工作负载的特点,更好地定制 HyperDX。
搜索结果支持 CSV 下载
针对用户呼声较高的需求,我们新增了搜索结果的导出功能。基于性能考虑,目前支持导出最多 4000 行,但这对于需要进一步分析或共享数据的用户而言,已非常实用。导出文件为 CSV 格式,方便直接在表格或其他工具中使用。
Elastic 迁移指南
应社区的需求,我们发布了 Elastic Stack 迁移指南[https://clickhouse.com/docs/use-cases/observability/clickstack/migration/elastic],帮助希望从 Elastic(前称 Elastic Stack 或 ELK Stack)迁移的用户。迁移后的优势显而易见:更好的压缩率、更高的资源利用率,以及更低的总体拥有成本。尽管迁移过程中可能存在一定复杂性,但我们力求让过程尽可能平滑。指南中详细对照了两种技术的概念映射,并提供了语言 SDK 和代理迁移的清晰路径,帮助用户快速完成切换。未来几个月,我们还会陆续推出针对其他传统可观测性方案的迁移指南,敬请期待。
Docker 镜像体积优化
为了让大家的入门体验更轻松,我们也致力于缩减容器镜像的体积。最早的用户反馈之一就是 all-in-one 镜像体积太大。现在,我们已经将其从 3GB 缩减至 2.2GB,应用本身的体积也从约 2GB 减至 1.2GB,几乎瘦身一半。我们仍在不断优化,持续让镜像更轻、更快,助你几乎无障碍地快速上手。
/END/
试用阿里云 ClickHouse企业版
轻松节省30%云资源成本?阿里云数据库ClickHouse 云原生架构全新升级,首次购买ClickHouse企业版计算和存储资源组合,首月消费不超过99.58元(包含最大16CCU+450G OSS用量)了解详情:https://t.aliyun.com/Kz5Z0q9G


征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


