





企业简介
科华数据(股票代码002335)前身创立于1988年,近40年来深耕电力电子与数字技术创新,形成数据中心、高端电源、清洁能源三大业务矩阵,服务网络覆盖全球100余个国家和地区。公司以"AI+数字能源"为核心,为互联网、金融、交通、石化、通信、电力、政府、医疗、科研教育等行业提供智慧电能及智算解决方案,创造可持续价值。
选型背景及过程
在新能源市场领域,尤其在储能行业(又或其他工业领域)中,以充电桩终端为业务形态的项目组普遍都会存在大量实时数据、测点数据如何高效、安全、稳定、存储读取数据的问题。
此前,我司初期(V1.0)针对实时测点数据高效存储的需求采用的是业内普遍的使用方案,即InfluxDB单节点数据库实例部署,当时的业务体量尚小,单节点的InfluxDB实例尚能支撑业务需求。后随业务发展及系统迭代升级,需要实现数据库高可用和故障转移的功能,但彼时InfluxDB的集群特性只有商业收费版,迫于此,我司基于双机热备的思路,自行实现了一个InfluxDB双节点的架构模式(V2.0),但实际本质上就是将实时测点数据双写到两个各自独立节点上部署的InfluxDB实例。
2024年底,研发组发现当前版本的双写机制,处理数据做法过于粗糙,没有办法保证两个InfluxDB节点数据完全一致,存在数据丢失的可能,且基于市场需求响应信创。研发组开始寻求一个能够以集群方式部署的国产化时序库,经过多轮调研,openGemini进入到研发组的视野。
性能对比
项目组以openGemini v1.3.1多副本与InfluxDB v1.7.1进行性能比照测试,主要测试了业务中典型的三种查询场景。
测试规格:
| 单节点 | ||
查询场景一:统计查询
查询语句:
SELECT count(*) FROM snlog
| 统计时间线规模 | |||
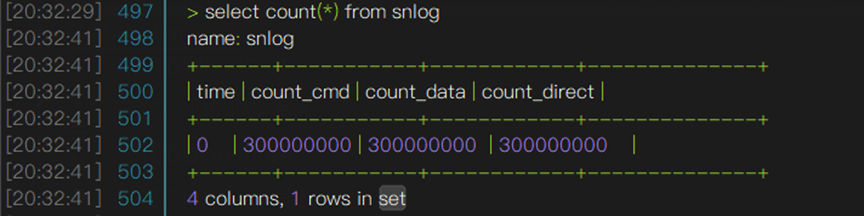
总量统计性能差异巨大,openGemini相较于InfluxDB,在相同量级的时间线内,openGemini比InfluxDB多3倍数据量的情况下,速度仍然比InfluxDB快3倍。
查询场景二:字符串模糊匹配
查询语句:
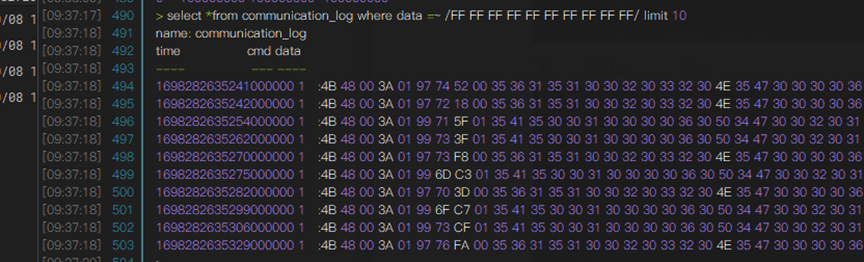
SELECT * FROM Communication_log WHERE data=~/FF FF FF FF FF FF FF/ LIMIT 10
查询场景三:指定TAG查询
查询语句:
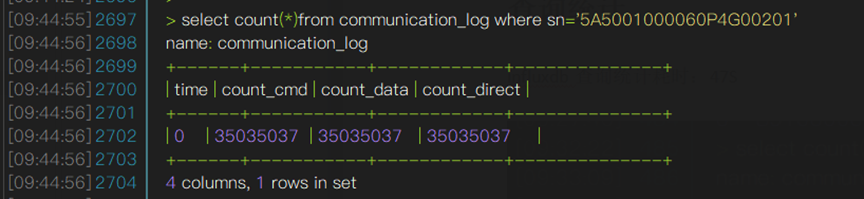
SELECT count(*) FROM communication_log WHERE sn=’5A5001000060P4G00201’
技术架构与数据可靠性保证
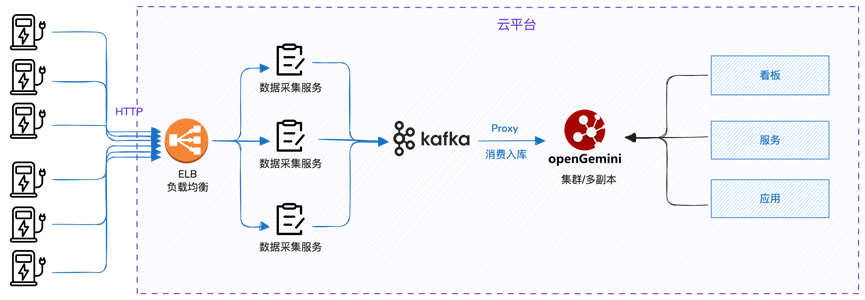
这是一个业界非常典型的技术架构,使用Kafka进行数据汇总,消费后落库openGemini集群。在数据可靠性方面,使用了openGemini的数据三副本能力来保证。
使用openGemini 之后的效果
目前项目已处在试运营阶段,部署了三个节点的三副本openGemini集群,数据写入速率约为x万,系统运行稳定。更换为openGemini之后,解决了我们在原有时序库开发上的很多麻烦,尤其是从旧InfluxDB环境中使用API大多是零修改成本的,直接迁移过来即可使用。相比于使用InfluxDB的方案,在相同的时间范围内(1年),InfluxDB使用磁盘占用空间约为2.3T,查询指定一个设备的10条时间线的数据耗时约为30秒。更换为openGemini后磁盘占用空间约为140G,查询指定设备的10条时间线数据耗时约为2至3秒。另外,集群的部署方式,提升了我们时序库的稳定性以及多节点的高可用性。
结束
希望社区能够有人手及时更新官方的开发文档,当前的文档手册版本大多数内容还是过于早期。
祝愿openGemini能够发展的更加长远。
作者 | Alan
排版 | openGemini

欢迎访问WELCOME TO VISIT
openGemini官网
https://www.openGemini.org
Star for me 🌟
https://github.com/openGemini
更多精彩内容,可以关注openGemini微信公众号查看,还有交流群等你加入哦~

