




背景
最近开发反馈有个任务偶尔性的执行变慢,平时都是10分钟左右完成,偶尔1小时完成。如果超过2小时的话可能就会影响业务后续进度,因此让我排查一下或优化一下SQL。
- 查看任务执行日志如下:
select start_time 创建日期,end_time 结束日期,
to_char(TRUNC(sysdate) + (end_time - start_time), 'HH24:MI:SS') 执行耗时
from summary_log l
order by 1 desc;
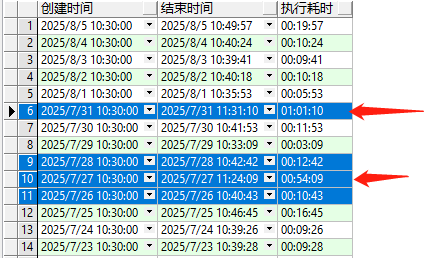
- 确实快的时候2-3分钟完成,慢的时候1小时+还没有跑完
- SQL 脱敏如下:
INSERT INTO T1
(......)
SELECT
......
FROM T1 A
LEFT JOIN (SELECT
......
FROM T2
WHERE CREATE_DATE >= to_date('2025-07-27','yyyy-mm-dd')
AND CREATE_DATE < to_date('2025-07-28','yyyy-mm-dd')
GROUP BY ACCT_ID) SUBQUERY
ON SUBQUERY.ACCT_ID = A.ACCT_ID
LEFT JOIN T2 B ON B.ACCT_ID = A.ACCT_ID
WHERE A.CREATE_DATE >= to_date('2025-07-26','yyyy-mm-dd')
AND A.CREATE_DATE < to_date('2025-07-27','yyyy-mm-dd')
AND B.STATUS= 0;
排查分析
根据sql_id 生成执行计划报告
- 手动执行脚本
@?/rdbms/admin/awrsqrpt.sql
- 默认生成html格式
- 选择天数
- 选择Snap ID
- 填写SQL_id:4af6vusvps6cu

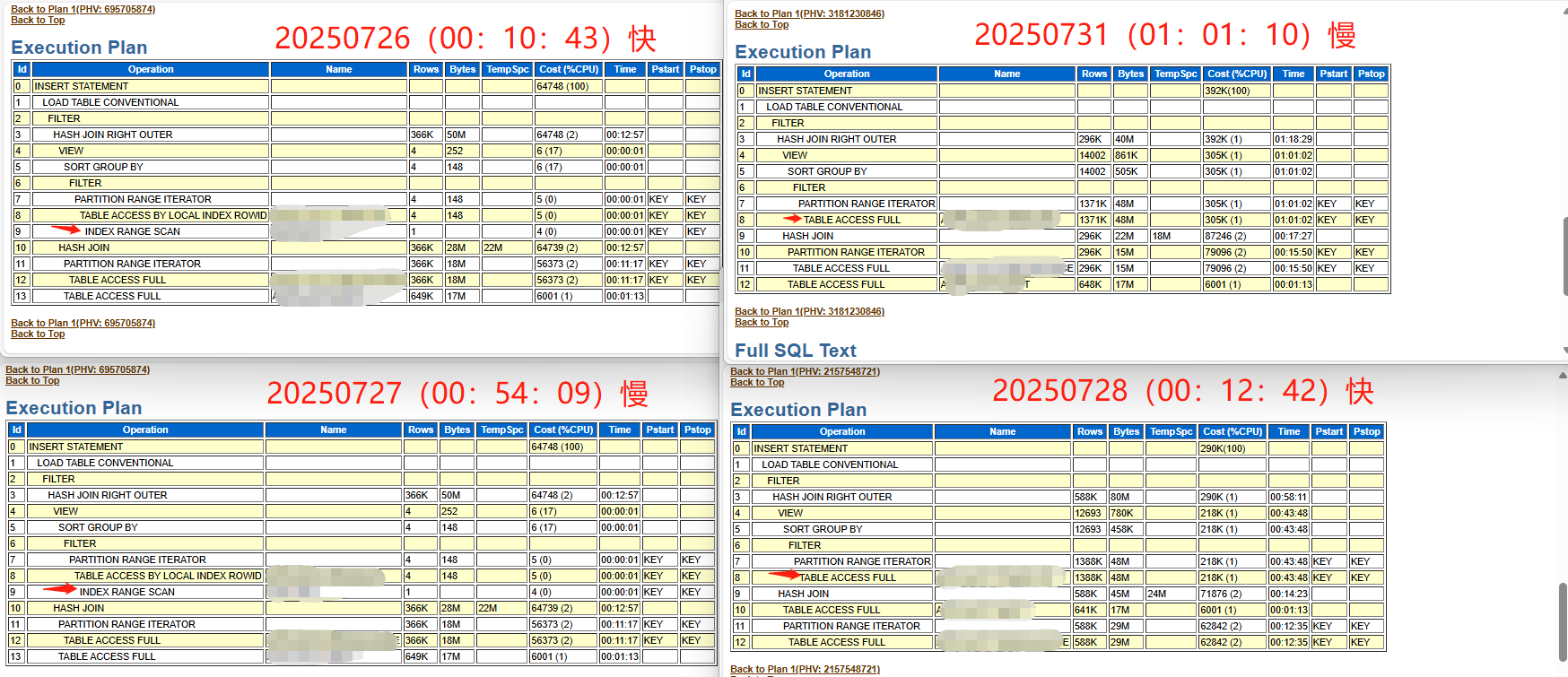
查看20250726(00:10:43)、20250727(00:54:09)、20250728(00:12:42)、20250731(01:01:10)的AWR_SQL报告
- awr_sql 性能瓶颈发现在IO

- TABLE ACCESS FULL 与 NDEX RANGE SCAN的执行结果都有快与慢的时候,因此分析与执行计划无关。
生成ash报告
- 手动执行脚本
@?/rdbms/admin/ashrpt.sql
- 发现在执行慢的ash报告中,SQL引发的db file sequential read等待事件占比30-40%左右
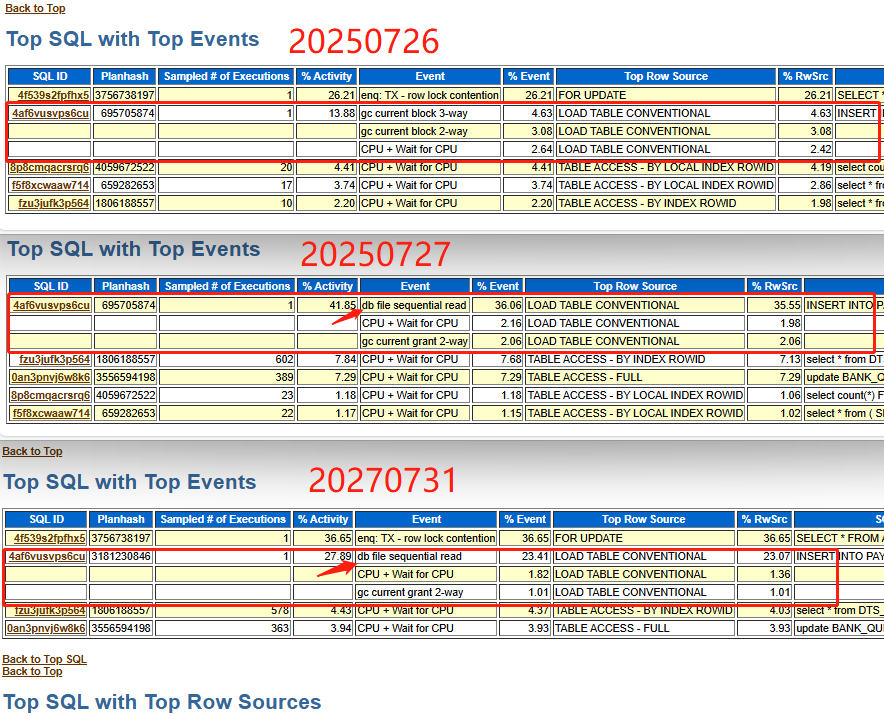
- db file sequential read
Oracle数据库中一种常见的I/O相关等待事件,表示数据库进程正在从数据文件中顺序读取数据块到SGA(系统全局区)中。遇到的案例:Insert 引起的 db file sequential read有细节介绍。 - 查看引发此事件的对象
select o.OBJECT_NAME,h.event,h.sql_opname,h.sql_plan_operation,h.machine,h.SAMPLE_TIME
from dba_hist_active_sess_history h
join dba_objects o on o.OBJECT_ID=h.current_obj#
where h.SAMPLE_TIME >= to_date('2025-08-07 10:30:00', 'yyyy-mm-dd hh24:mi:ss')
and h.SAMPLE_TIME <= to_date('2025-08-07 11:30:00', 'yyyy-mm-dd hh24:mi:ss')
AND h.sql_id='4af6vusvps6cu';
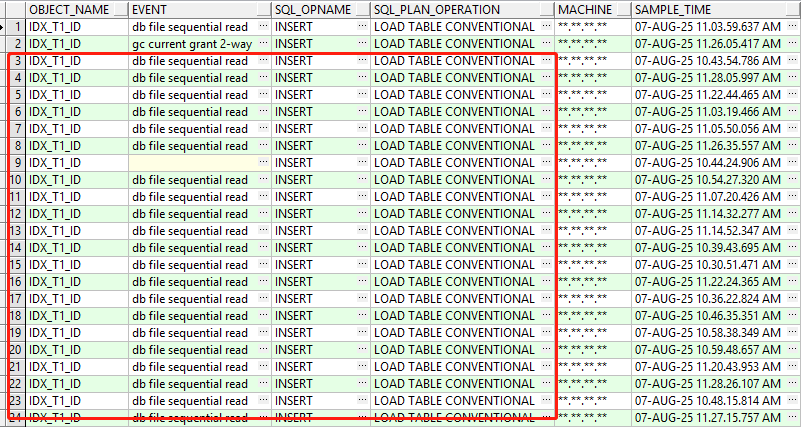
Insert操作引发db file sequential read
虽然insert操作本身主要是写入操作,但在以下情况下会引发db file sequential read等待事件:
1、索引维护开销
当表上有索引时,insert操作需要同时维护所有相关索引,这会导致:
- 数据库需要查询索引块以确定新记录的插入位置;
- 每次索引块查询都会产生单块读取,表现为db file sequential read;
- 索引分裂(当索引块空间不足时)会产生额外的单块读取;
2、高并发insert场景
在高并发insert环境下:
- 多个会话同时维护相同索引会导致索引块访问冲突;
- 索引块可能频繁从磁盘读取到SGA,增加db file sequential read等待;
3、索引碎片问题
当索引存在严重碎片时:
- 索引维护需要访问更多分散的索引块;
- 增加单块读取的次数和等待时间;
- 行迁移和行链接也会导致额外的单块读取;
模拟生产环境
- 在测试环境对T1表进行历史数据恢复,然后保留1年内的基础数据,其它历史数据进行truncate partition update indexes 操作,使索引产生大量碎片。
| 表名 | 索引 | 实际大小GB | 产生碎片后大小GB | 碎片率 |
|---|---|---|---|---|
| T1 | IDX_T1_ID | 12.01 | 40.01 | 70% |
| T1 | IDX_T1_CUST | 7.6 | 7.3 | - |
| T1 | SYS_C00722650 | 15.38 | 48.14 | 68% |
- 执行消耗对比:
| 性能指标 | 无碎片 | 有碎片 |
|---|---|---|
| Elapsed | 00:01:01.73 | 00:15:38.00 |
| recursive calls | 187 | 33 |
| db block gets | 6,103,959 | 3,407,341 |
| consistent gets | 1,311,473 | 818,618 |
| physical reads | 977,810 | 1,384,066 |
| redo size | 1,696,362,588 | 587,160,312 |
| rows processed | 644,921 | 644,921 |
- 等待事件
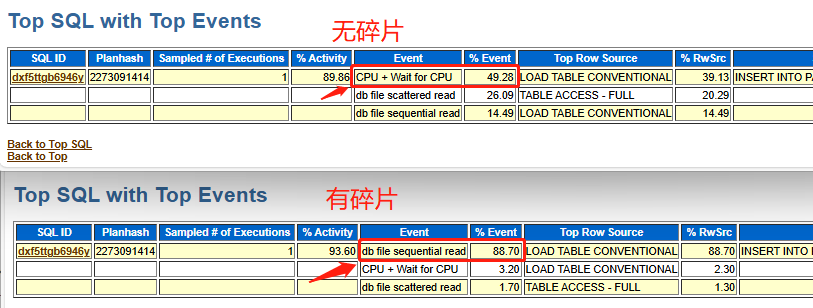
总结
根据以上模拟实验,基本可以肯定是因为碎片导致insert 产生的db file sequential read(单块读)从而引起SQL的偶发性变慢。
- 碎片分析
将生产表通过expdp/impdp操作导入到测试库中查询其索引大小,然后与生产对比大小
SELECT a.owner, b.table_name,b.INDEX_NAME, round(a.GB,2) GB
FROM (SELECT OWNER,
SEGMENT_NAME,
TABLESPACE_NAME,
(SUM(BYTES) / (1024 * 1024 * 1024)) AS GB
FROM DBA_SEGMENTS
GROUP BY OWNER, SEGMENT_NAME, TABLESPACE_NAME
) a
left join ALL_INDEXES b on a.SEGMENT_NAME = b.INDEX_NAME
where b.table_name IN ('T1')
order by 2,3,4

- 最终对涉及到的表进行索引重建完成碎片整理,后续继续观察执行效果。
欢迎赞赏支持或留言指正

「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
