




金仓数据库(Kingbase)作为国产数据库产品,提供了对MySQL的兼容性支持,以便于MySQL应用能够较为平滑地迁移到金仓数据库环境。
不同版本的金仓数据库(如KingbaseES V7/V8/V9)对MySQL的兼容程度可能有所不同,通常较新版本提供更好的兼容性支持。
以下是金仓数据库兼容MySQL的主要说明:
一、兼容性级别
金仓数据库对MySQL的兼容性主要体现在以下几个方面:
- SQL语法兼容:支持大部分常用的MySQL SQL语法
- 数据类型兼容:支持MySQL常用数据类型的映射
- 函数兼容:支持大量MySQL内置函数的等价实现
- 客户端协议兼容:部分兼容MySQL客户端连接协议
二、主要兼容特性
1. SQL语法兼容
- 支持MySQL风格的LIMIT子句
- 支持MySQL风格的字符串连接操作符
||(在特定模式下) - 支持MySQL风格的注释语法(
--和#) - 支持MySQL风格的AUTO_INCREMENT(映射为SERIAL或IDENTITY)
- 支持MySQL风格的引号使用(反引号
`用于标识符)
2. 数据类型兼容
- MySQL的
INT→ 金仓的INTEGER或INT - MySQL的
VARCHAR→ 金仓的VARCHAR或CHARACTER VARYING - MySQL的
TEXT→ 金仓的TEXT - MySQL的
DATETIME→ 金仓的TIMESTAMP - MySQL的
TINYINT(1)→ 金仓的BOOLEAN(布尔类型) - MySQL的
ENUM和SET类型(有限支持)
3. 函数兼容
- 字符串函数:
CONCAT(),SUBSTRING(),LENGTH()等 - 日期时间函数:
NOW(),DATE_FORMAT(),CURDATE()等 - 数学函数:
ABS(),ROUND(),RAND()等 - 控制流函数:
IF(),CASE WHEN等
4. 客户端兼容
- 提供MySQL协议兼容接口(部分版本)
- 支持使用MySQL客户端工具连接(需配置)
- 支持JDBC/ODBC等驱动兼容模式
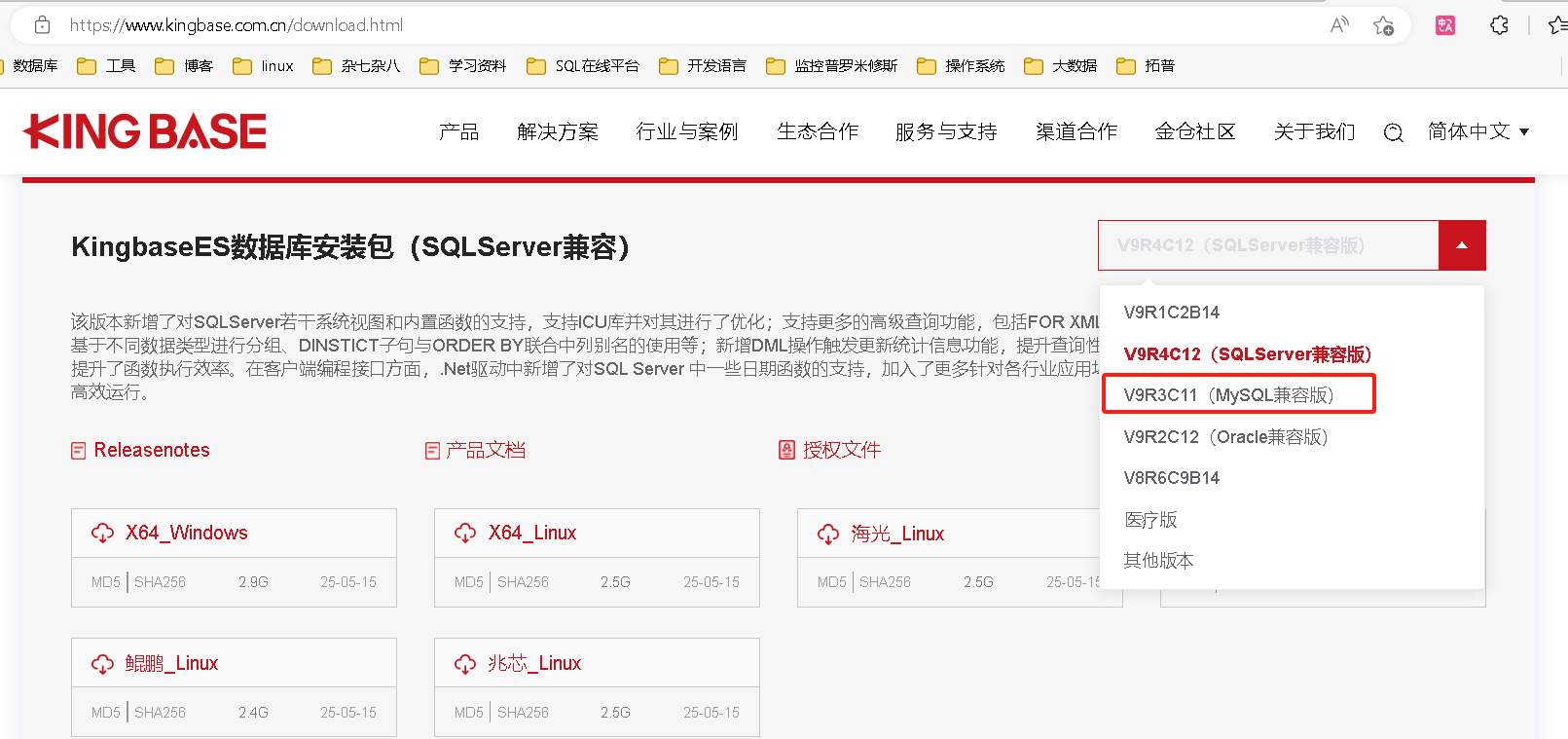
下载并安装MySQL兼容版KES数据库
下载MySQL兼容版数据库
下载地址:https://www.kingbase.com.cn/download.html
务必在下拉框中选择含SQL Server 兼容版的版本,根据操作系统和CPU类型下载对应的安装介质,安装介质较V8R6大一些,有2.48G大小。
下载后上传到/opt目录下。
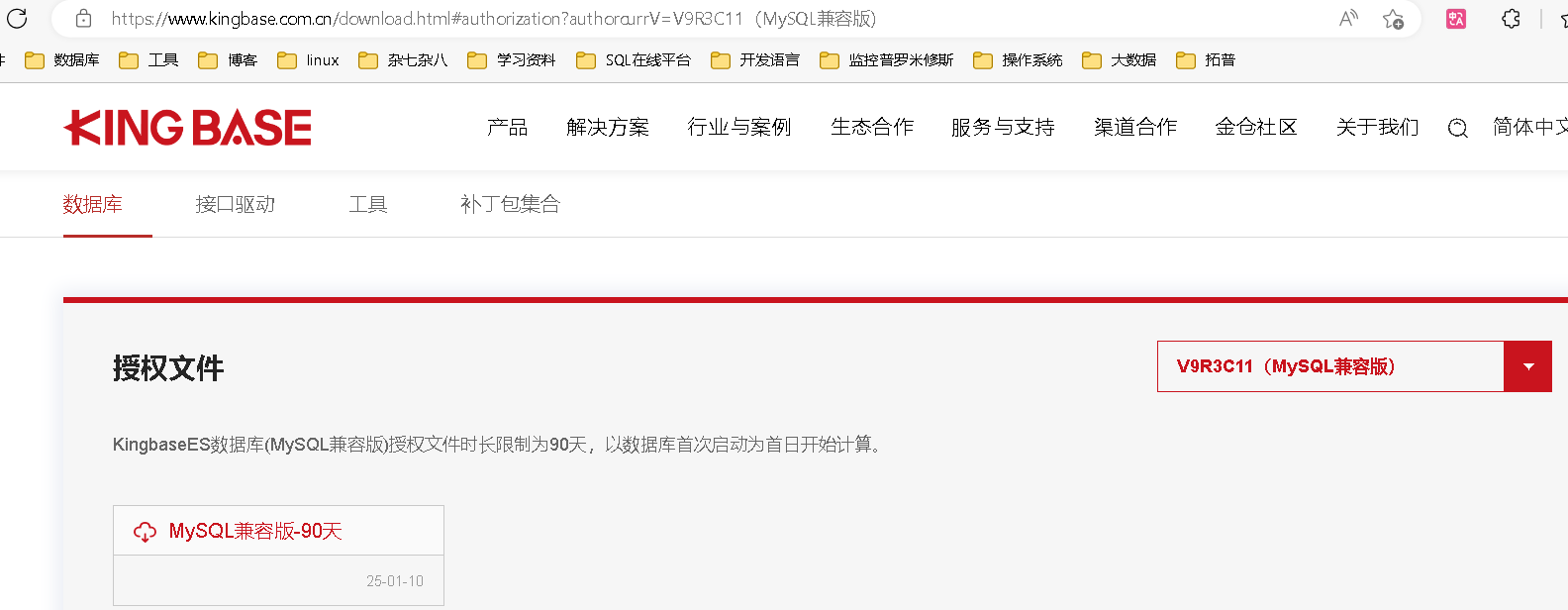
下载授权文件
KingbaseES数据库(MySQL兼容版)授权文件时长限制为90天,以数据库首次启动为首日开始计算。
该版本授权文件下载后直接上传可用,不用像V8R6版本的授权文件需要解压才能用,省却了解压步骤,更方便省时。
下载后上传到/opt目录下。
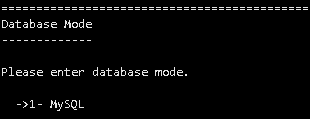
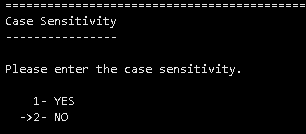
安装MySQL兼容版数据库
安装过程和V8R6一样,安装过程省略,过程中注意数据库模式为MySQL,只支持大小写不敏感。
安装完成后登录数据库查看数据库兼容模式,输出如下:
test=# show database_mode;
database_mode
---------------
mysql
(1 row)
test=# show enable_ci;
enable_ci
-----------
on
(1 row)
注意V8R6版本以后需要使用show enable_ci查看:
返回结果on:表示大小写不敏感;
返回结果off:表示大小写敏感。补充:
在V8R3版本人大金仓数据库客户端执行语句:show case_sensitive;
返回结果on:表示大小写敏感;
返回结果off:表示大小写不敏感SQL语法兼容测试
数据操作语句
DML操作全兼容(支持多表更新;IGNORE/LIMIT子句;INSERT ON DUPLICATE KEY子句;DML error logging语句;REPLACE INTO语句) ;LOAD DATA INFILE
IGNORE子句
在 Kingbase (金仓) 数据库中,IGNORE 子句通常用于在数据操作时忽略某些错误或冲突,使操作能够继续执行而不中断。这个功能类似于 MySQL 中的 IGNORE 关键字。
语法
在 INSERT 语句中使用 IGNORE
当插入数据时,如果遇到主键或唯一键冲突,IGNORE 会使数据库忽略这个错误并继续执行后续操作,而不是中止整个插入过程。
INSERT IGNORE INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...);在 UPDATE 语句中使用 IGNORE
使用 IGNORE 后,如果更新操作导致重复键冲突等错误,这些错误会被忽略,操作会继续执行。
UPDATE IGNORE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;注意事项
- 金仓数据库的
IGNORE行为可能与 MySQL 不完全相同,具体实现细节需要参考金仓的官方文档。 - 使用
IGNORE会隐藏错误信息,可能导致数据不一致问题,应谨慎使用。 - 在某些情况下,使用
ON CONFLICT或MERGE语句可能是更好的替代方案,可以提供更精确的冲突处理逻辑。
LIMIT子句
金仓数据库(KingbaseES)中的LIMIT子句用于限制查询结果返回的行数,类似于其他数据库系统中的TOP或FETCH FIRST子句。
基本语法
SELECT column1, column2, ...
FROM table_name
[WHERE condition]
[ORDER BY column1, column2, ...]
LIMIT number_of_rows [OFFSET offset_value];或
SELECT column1, column2, ...
FROM table_name
[WHERE condition]
[ORDER BY column1, column2, ...]
[OFFSET offset_value] LIMIT number_of_rows;测试过程
--返回前10条记录
SELECT * FROM sales LIMIT 10;
--返回第11到20条记录(跳过前10条,取接下来的10条)
SELECT * FROM sales LIMIT 10 OFFSET 10;
或
SELECT * FROM sales OFFSET 10 LIMIT 10;
--结合ORDER BY使用
SELECT * FROM sales ORDER BY amount DESC LIMIT 5;注意事项
- LIMIT子句通常与ORDER BY子句一起使用,以确保结果的可预测性。没有ORDER BY时,返回的行是不确定的。
- OFFSET表示要跳过的行数,LIMIT表示要返回的行数。
- 对于大型表,高OFFSET值可能会导致性能问题,因为数据库需要扫描并跳过所有前面的行。
- 金仓数据库也支持标准SQL的FETCH FIRST语法:
SELECT * FROM sales FETCH FIRST 10 ROWS ONLY;
--在分页查询中,LIMIT和OFFSET非常有用
-- 第一页
SELECT * FROM sales ORDER BY id LIMIT 10 OFFSET 0;
-- 第二页
SELECT * FROM sales ORDER BY id LIMIT 10 OFFSET 10;INSERT ON DUPLICATE KEY子句
Kingbase(金仓数据库)是基于PostgreSQL开发的关系型数据库,其处理重复键冲突的语法与MySQL的ON DUPLICATE KEY UPDATE类似,但使用的是PostgreSQL风格的ON CONFLICT子句。
语法
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...)
ON CONFLICT [conflict_target] conflict_action;主要组成部分
- conflict_target - 指定可能发生冲突的约束
ON CONFLICT (column_name)- 指定列名ON CONFLICT ON CONSTRAINT constraint_name- 指定约束名
- conflict_action - 冲突时执行的操作
DO NOTHING- 如果冲突发生,不执行任何操作DO UPDATE SET column1 = value1, ...- 如果冲突发生,执行更新操作
测试过程
创建测试表
create table products (id int primary key, name varchar(100), price decimal(20,2));
create table users (email varchar(100) primary key, username varchar(100));
create table orders (order_id varchar(50), customer_id int, amount int);
alter table orders add CONSTRAINT orders_pkey PRIMARY KEY(order_id);
create table employees (emp_id int primary key, name varchar(50), salary decimal(1000,2), department varchar(50));简单插入数据
INSERT INTO products (id, name, price)
VALUES (1, 'Laptop', 999.99)
ON CONFLICT (id)
DO UPDATE SET name = EXCLUDED.name, price = EXCLUDED.price;使用DO NOTHING
INSERT INTO users (email, username)
VALUES ('test@example.com', 'testuser')
ON CONFLICT (email)
DO NOTHING;使用ON CONSTRAINT指定约束名
INSERT INTO orders (order_id, customer_id, amount)
VALUES (1001, 2001, 150.00)
ON CONFLICT ON CONSTRAINT orders_pkey
DO UPDATE SET amount = EXCLUDED.amount;部分更新
INSERT INTO employees (emp_id, name, salary, department)
VALUES (101, 'John Doe', 75000, 'IT')
ON CONFLICT (emp_id)
DO UPDATE SET salary = EXCLUDED.salary;注意事项
- Kingbase的
ON CONFLICT语法与PostgreSQL兼容,与MySQL的ON DUPLICATE KEY UPDATE有所不同 - 必须指定冲突目标(列或约束)
- 使用
EXCLUDED伪表可以引用原本要插入的值 - 在Kingbase V8版本中,此功能可能需要特定配置或扩展支持
REPLACE INTO语句
在KingbaseES(金仓数据库)中,REPLACE INTO语句用于插入数据,如果数据已存在(根据主键或唯一索引判断),则先删除旧记录再插入新记录。
基本语法
REPLACE INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...);
或
REPLACE INTO table_name (column1, column2, ...)
SELECT ... FROM ...;测试过程
基本替换插入
REPLACE INTO employees (emp_id, name, department)
VALUES (1, '张三', '研发部');使用SELECT子句插入
--创建employee_backup表
create table employee_backup as select * from employees where 1<>1;
--使用select子句插入
REPLACE INTO employee_backup
SELECT * FROM employees WHERE department = '研发部';- 如果id=1的记录不存在,则插入新记录
- 如果id=1的记录已存在,则先删除旧记录再插入新记录
注意事项
- REPLACE INTO语句的执行实际上是先尝试删除(如果存在)再插入,因此会触发DELETE和INSERT触发器。
- 如果表有自增字段,使用REPLACE INTO会导致自增值增加,即使只是替换现有记录。
- 金仓数据库的REPLACE INTO功能与MySQL的REPLACE INTO类似,但语法和实现细节可能略有不同。
- 在高并发环境下使用时需注意锁问题,因为它实际上是先删除再插入的操作。
LOAD DATA INFILE语句
KingbaseES (金仓数据库) 提供了类似 MySQL 的 LOAD DATA INFILE 语句,用于高效地从文本文件批量导入数据到表中。
基本语法
LOAD DATA [LOCAL] INFILE '文件路径'
[REPLACE | IGNORE]
INTO TABLE 表名
[CHARACTER SET 字符集]
[FIELDS
[TERMINATED BY '字段分隔符']
[OPTIONALLY] ENCLOSED BY '字段包围符'
[ESCAPED BY '转义字符']
]
[LINES
[STARTING BY '行前缀']
[TERMINATED BY '行结束符']
]
[IGNORE 行数 LINES]
[(列名1, 列名2, ...)]
[SET 列名 = 表达式, ...]参数说明
LOCAL: 表示从客户端而非服务器读取文件REPLACE: 遇到主键/唯一键冲突时替换现有行IGNORE: 遇到主键/唯一键冲突时跳过该行FIELDS TERMINATED BY: 指定字段分隔符(如',')ENCLOSED BY: 指定字段包围符(如'"')LINES TERMINATED BY: 指定行结束符(如'\n')IGNORE n LINES: 跳过文件前n行(常用于跳过标题行)
测试过程
基本导入
将csv文件导入到表 employees
--创建一个CSV文件 employees.csv
cat /home/kingbase/employees.csv
1,张三,5000,销售部
2,李四,4900,技术部
3,王五,3500,人事部
--将csv文件导入到表 employees
LOAD DATA INFILE '/home/kingbase/employees.csv'
INTO TABLE employees
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n';处理带引号的字段
--创建一个CSV文件 employees2.csv
cat /home/kingbase/employees2.csv
"10","张三","5000","销售部"
"20","李四","4900","技术部"
"30","王五","3500","人事部"
--将csv文件导入到表 employees
LOAD DATA INFILE '/home/kingbase/employees2.csv'
INTO TABLE employees
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n';注意事项
- 文件权限:服务器端文件需要数据库服务器有读取权限
- 字符集:如有中文等特殊字符,建议指定字符集(如
CHARACTER SET utf8) - 路径格式:
- Linux/Unix:
/path/to/file.csv - Windows:
C:\\path\\to\\file.csv(注意双反斜杠)
- 性能优化:对于大文件,建议先禁用索引,导入后再重建索引
- 错误处理:使用
SHOW WARNINGS查看导入过程中的警告信息
与MySQL的差异
虽然KingbaseES的LOAD DATA INFILE语法与MySQL非常相似,但可能存在以下差异:
- 某些选项可能不受支持
- 文件路径的解析方式可能不同
- 默认字符集处理可能不同
数据查询语句
GROUP BY WITH ROLLUP 是金仓数据库(KingbaseES)中用于生成分组汇总统计结果的功能,它会为每个分组层级生成小计,并生成一个总计行。其中,ROLLUP 是 GROUP BY 子句的扩展,用于生成分组的小计和总计行。
基本语法
SELECT column1, column2, ..., aggregate_function(column)
FROM table_name
GROUP BY ROLLUP (column1, column2, ...);兼容测试过程
构建测试数据
--创建销售表 sales
CREATE TABLE sales (
region VARCHAR(50),
product VARCHAR(50),
year INT,
amount DECIMAL(10,2)
);
--插入测试数据
insert into sales values('BeiJing','稻香村',2,3);
insert into sales values('ShangHai','口水鸭',5,13);
insert into sales values('YunNan','米粉',5,13);单字段分组汇总
SELECT region, SUM(amount) as total_sales
FROM sales
GROUP BY region WITH ROLLUP;输出如下:
region | total_sales
----------+-------------
| 32.00
ShangHai | 13.00
YunNan | 13.00
BeiJing | 6.00
(4 rows)结果将包含每个地区的销售额小计,以及一个所有地区的总计行。
两个字段分组汇总
SELECT region, product, SUM(amount) AS total_sales
FROM sales
GROUP BY ROLLUP (region, product);输出如下:
region | product | total_sales
----------+---------+-------------
| | 32.00
BeiJing | 稻香村 | 6.00
YunNan | 米粉 | 13.00
ShangHai | 口水鸭 | 13.00
ShangHai | | 13.00
YunNan | | 13.00
BeiJing | | 6.00
(7 rows)该查询会返回:
- 每个region和product组合的明细行
- 每个region的小计行(product列显示为NULL)
- 总计行(region和product列都显示为NULL)
多字段分组汇总
SELECT region, product, year, SUM(amount) AS total
FROM sales
GROUP BY ROLLUP (region,product, year);输出如下:
region | product | year | total
----------+---------+------+-------
| | | 32.00
BeiJing | 稻香村 | 2 | 6.00
ShangHai | 口水鸭 | 5 | 13.00
YunNan | 米粉 | 5 | 13.00
BeiJing | 稻香村 | | 6.00
YunNan | 米粉 | | 13.00
ShangHai | 口水鸭 | | 13.00
ShangHai | | | 13.00
YunNan | | | 13.00
BeiJing | | | 6.00
(10 rows)结果将包含:
- 每个地区-产品-年份组合的销售额
- 每个地区-产品组合的小计
- 每个地区的小计
- 总计
识别ROLLUP行
可以使用GROUPING函数来识别哪些行是ROLLUP生成的汇总行
SELECT
CASE WHEN GROUPING(region) = 1 THEN '所有地区' ELSE region END AS region,
CASE WHEN GROUPING(product) = 1 THEN '所有产品' ELSE product END AS product,
SUM(amount) AS total_sales
FROM sales
GROUP BY ROLLUP (region, product);输出如下:
region | product | total_sales
----------+----------+-------------
所有地区 | 所有产品 | 32.00
BeiJing | 稻香村 | 6.00
YunNan | 米粉 | 13.00
ShangHai | 口水鸭 | 13.00
ShangHai | 所有产品 | 13.00
YunNan | 所有产品 | 13.00
BeiJing | 所有产品 | 6.00
(7 rows)部分ROLLUP
可以对部分列使用ROLLUP
SELECT region, product, year, SUM(amount)
FROM sales
GROUP BY region, ROLLUP (product, year);输出如下:
region | product | year | SUM
----------+---------+------+-------
BeiJing | 稻香村 | 2 | 6.00
ShangHai | 口水鸭 | 5 | 13.00
YunNan | 米粉 | 5 | 13.00
BeiJing | 稻香村 | | 6.00
YunNan | 米粉 | | 13.00
ShangHai | 口水鸭 | | 13.00
ShangHai | | | 13.00
YunNan | | | 13.00
BeiJing | | | 6.00
(9 rows)注意事项
- NULL值处理:汇总行中对应列会显示为NULL,表示"所有值"。
- 顺序重要:ROLLUP的分组顺序与GROUP BY子句中列的顺序一致。
- 性能考虑:大数据集上使用ROLLUP可能会影响性能。适当的索引可以改善性能。
