




在上一篇文章PostgreSQL优化器提示扩展——pg_hint_plan中我们介绍了pg_hint_plan的使用方法以及支持的列表,本篇主要讲述一下其实现原理。
提示类型
当前主要支持扫描方法提示、连接方法提示、连接顺序提示、行数校正提示、并行查询提示、GUC参数配置提示等。
扫描方法提示
扫描方法提示对目标表强制执行特定的扫描方法,pg_hint_plan通过表的别名(如果存在的话)来识别目标表。扫描方法例如:序列扫描、索引扫描等。
扫描提示对普通表、继承表、无日志表、临时表和系统表有效。对外部表、表函数、常量值语句、通用表达式、视图和子查询无效。
=# /*+
SeqScan(t1)
IndexScan(t2 t2_pkey)
*/
SELECT * FROM table1 t1 JOIN table table2 t2 ON (t1.key = t2.key);
连接方法提示
连接方法提示强制指定相关表连接的方法。对普通表、继承表、无日志表、临时表、外部表、系统表、表函数、常量值命令和通用表达式有效。对视图和子查询无效。
连接顺序提示
Leading提示强制两个或多个表的连接顺序。
=# /*+
NestLoop(t1 t2)
MergeJoin(t1 t2 t3)
Leading(t1 t2 t3)
*/
SELECT * FROM table1 t1
JOIN table table2 t2 ON (t1.key = t2.key)
JOIN table table3 t3 ON (t2.key = t3.key);
行数校正提示
行数校正提示会校正由查询优化器导致的行数错误。
=# /*+ Rows(a b #10) */ SELECT... ; 设置连接结果的行数为10
=# /*+ Rows(a b +10) */ SELECT... ; 行数增加10
=# /*+ Rows(a b -10) */ SELECT... ; 行数减去10
=# /*+ Rows(a b *10) */ SELECT... ; 行数增大10倍
并行执行提示
Parallel提示强制扫描的并行执行配置。第三个参数指定强制强度:soft 表示仅修改 max_parallel_worker_per_gather,其他参数由规划器决定;hard 强制修改其他规划器参数。该提示作用于普通表、分区表父表、UNLOGGED表和系统表。外部表、表函数、VALUES 子句、CTE、视图和子查询无效。视图的内部表可通过真实名称或别名指定。
=# EXPLAIN /*+ Parallel(c1 3 hard) Parallel(c2 5 hard) */
SELECT c2.a FROM c1 JOIN c2 ON (c1.a = c2.a);
QUERY PLAN
-------------------------------------------------------------------------------
Hash Join (cost=2.86..11406.38 rows=101 width=4)
Hash Cond: (c1.a = c2.a)
-> Gather (cost=0.00..7652.13 rows=1000101 width=4)
Workers Planned: 3
-> Parallel Seq Scan on c1 (cost=0.00..7652.13 rows=322613 width=4)
-> Hash (cost=1.59..1.59 rows=101 width=4)
-> Gather (cost=0.00..1.59 rows=101 width=4)
Workers Planned: 5
-> Parallel Seq Scan on c2 (cost=0.00..1.59 rows=59 width=4)
=# EXPLAIN /*+ Parallel(tl 5 hard) */ SELECT sum(a) FROM tl;
QUERY PLAN
-----------------------------------------------------------------------------------
Finalize Aggregate (cost=693.02..693.03 rows=1 width=8)
-> Gather (cost=693.00..693.01 rows=5 width=8)
Workers Planned: 5
-> Partial Aggregate (cost=693.00..693.01 rows=1 width=8)
-> Parallel Seq Scan on tl (cost=0.00..643.00 rows=20000 width=4)
GUC参数配置提示
Set提示在查询规划期间临时修改GUC参数。只要不与其他规划方法配置参数冲突,查询规划中的GUC参数可以影响规划。当多个提示修改同一GUC时,最后一个生效。pg_hint_plan的GUC参数也可通过此提示设置,但可能不会生效。
=# /*+ Set(random_page_cost 2.0) */
SELECT * FROM table1 t1 WHERE key = 'value';
...
优化示例
这里我们举一个pg_hint_plan进行优化的示例:
建表,并构造数据:
postgres=# CREATE TABLE employees (id INT PRIMARY KEY, name TEXT, dept_id INT);
CREATE TABLE
postgres=# INSERT INTO employees SELECT generate_series(1, 1000000), 'Emp' || generate_series(1, 1000000), (random() * 9999 + 1)::int;
INSERT 0 1000000
postgres=# CREATE INDEX idx_employees_dept_id ON employees(dept_id);
CREATE INDEX
我们首先进行一个查询,并查看执行计划:
postgres=# explain analyze select * from employees where name = 'Emp100' order by dept_id;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------
Sort (cost=19167.19..19179.69 rows=5000 width=40) (actual time=117.370..117.372 rows=1 loops=1)
Sort Key: dept_id
Sort Method: quicksort Memory: 25kB
-> Seq Scan on employees (cost=0.00..18860.00 rows=5000 width=40) (actual time=0.024..117.364 rows=1 loops=1)
Filter: (name = 'Emp100'::text)
Rows Removed by Filter: 999999
Planning Time: 0.336 ms
Execution Time: 117.398 ms
(8 rows)
Time: 118.740 ms
我们修改这个查询,增加limit 1进行限制,这个语句在实际应用中是top N查询,属于比较常用的场景。
postgres=# explain analyze select * from employees where name = 'Emp100' order by dept_id limit 1;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=0.42..5.52 rows=1 width=40) (actual time=959.849..959.850 rows=1 loops=1)
-> Index Scan using idx_employees_dept_id on employees (cost=0.42..25453.42 rows=5000 width=40) (actual time=959.847..959.847 rows=1 loops=1)
Filter: (name = 'Emp100'::text)
Rows Removed by Filter: 641828
Planning Time: 0.313 ms
Execution Time: 959.878 ms
(6 rows)
Time: 961.651 ms
经过上面的对比,我们发现增加了limit 1后,执行时间明显增加了很多,这显然是不合理的,这是因为优化器在order by limit的场景下,优先走了索引,但实际上,这个索引字段并不是where条件字段,在走索引的情况下,大量的数据被过滤掉,导致执行时间大大增加。怎么解决这个问题呢?其中一个思路就是通过pg_hint_plan强制通过顺序扫描表。
postgres=# /*+ SeqScan(employees) */ explain analyze select * from employees where name = 'Emp100' order by dept_id limit 1;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------
Limit (cost=18885.00..18885.00 rows=1 width=40) (actual time=133.905..133.907 rows=1 loops=1)
-> Sort (cost=18885.00..18897.50 rows=5000 width=40) (actual time=133.903..133.904 rows=1 loops=1)
Sort Key: dept_id
Sort Method: quicksort Memory: 25kB
-> Seq Scan on employees (cost=0.00..18860.00 rows=5000 width=40) (actual time=0.036..133.865 rows=1 loops=1)
Filter: (name = 'Emp100'::text)
Rows Removed by Filter: 999999
Planning Time: 0.223 ms
Execution Time: 133.933 ms
(9 rows)
Time: 135.182 ms
可以看到,通过顺序扫描表后,查询执行时间回归到正常值。
postgres=# select * from employees where name = 'Emp100' order by dept_id limit 1;
id | name | dept_id
-----+--------+---------
100 | Emp100 | 6428
(1 row)
Time: 893.404 ms
postgres=# /*+ SeqScan(employees) */ select * from employees where name = 'Emp100' order by dept_id limit 1;
id | name | dept_id
-----+--------+---------
100 | Emp100 | 6428
(1 row)
Time: 169.947 ms
可以关注一下SQL Plan Baseline技术
实现原理
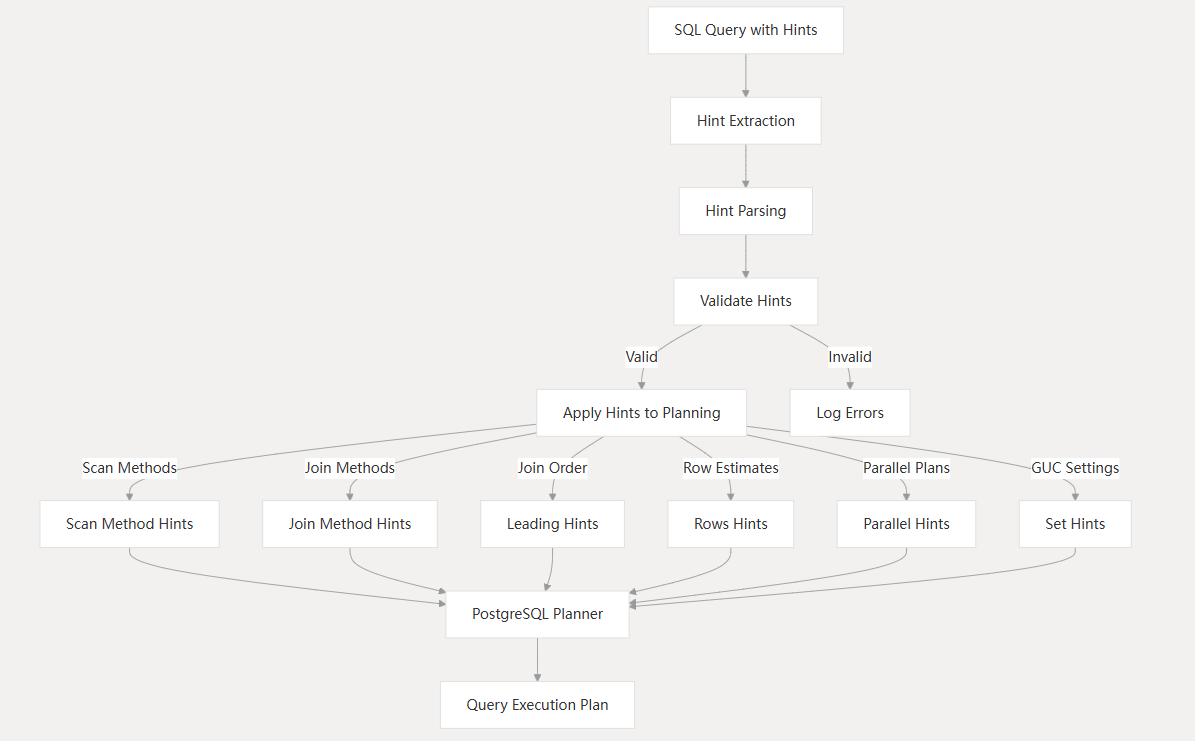
我们分析一下pg_hint_plan的实现原理,看一下内核中是如何处理提示的。
主要处理流程:
- 扩展加载时注册钩子函数和配置参数
void _PG_init(void)
{
DefineCustomBoolVariable("pg_hint_plan.enable_hint", ...);
// 省略部分GUC配置参数...
// 注册钩子函数
prev_planner = planner_hook;
planner_hook = pg_hint_plan_planner;
// 省略部分钩子函数注册...
}
- 查询执行时,pg_hint_plan_planner钩子被调用
// 该函数主要是从注释或提示表中获取提示信息,并设置HintState
static PlannedStmt *pg_hint_plan_planner(Query *parse, const char *query_string, int cursorOptions, ParamListInfo boundParams)
{
// 获取当前SQL的提示信息
// 1. 如果开启了提示表功能,则从提示表中获取提示信息
// 2. 如果未开启提示表功能或者提示表中没有提示信息,则从注释中获取提示信息
get_current_hint_string(parse, query_string, NULL);
{
// 1. 如果开启了提示表功能,则从提示表中获取提示信息
// 2. 如果未开启提示表功能或者提示表中没有提示信息,则从注释中获取提示信息
// 3. 提取的方式为字符串匹配
current_hint_str = get_hints_from_comment(query_str);
}
// 设置HintState,解析hint字符串中的Hint名以及参数
HintState *hstate = create_hintstate(parse, pstrdup(current_hint_str));
}
- 从注释或提示表中获取提示信息
- 解析提示信息并存储在HintState中
- 在查询规划过程中,其他钩子函数会根据提示调整执行计划
- 查询执行完毕后清理提示状态
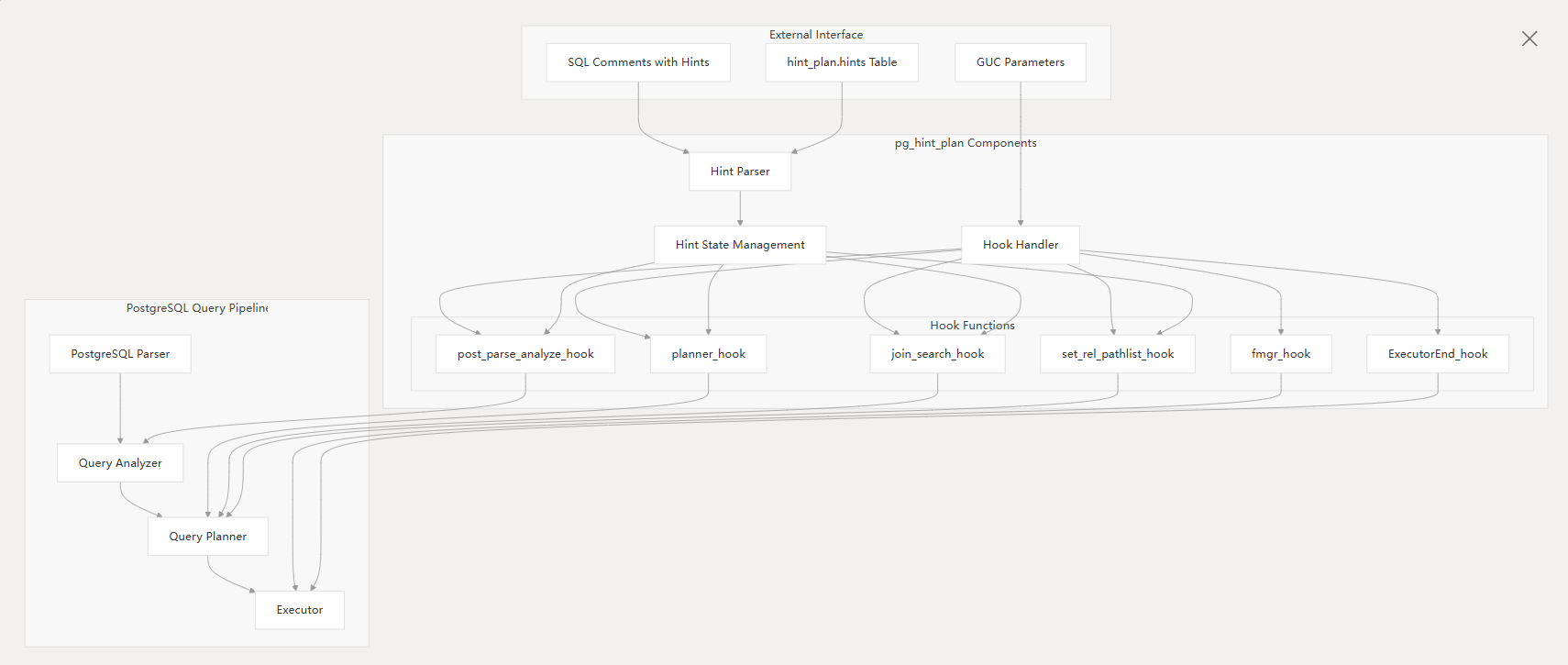
扫描方法提示实现原理
对扫描方法提示的实现是在pg_hint_plan_set_rel_pathlist函数中实现的。
在查询优化中,会先调用set_rel_pathlist生成基表的最短路径,也就是会生成基表的所有扫描方式的路径:顺序扫描、索引扫描、TID扫描。
static void set_rel_pathlist(PlannerInfo *root, RelOptInfo *rel, Index rti, RangeTblEntry *rte)
{
// 生成基表所有扫描方式路径
set_plain_rel_pathlist(root, rel, rte);
// 走之前注册的钩子函数pg_hint_plan_set_rel_pathlist
// 处理扫描路径
if (set_rel_pathlist_hook)
(*set_rel_pathlist_hook) (root, rel, rti, rte);
}
那么扫描方式提示的核心实现思路是什么呢?
- SeqScan: 如果指定顺序扫描,则设置
enable_seqscan = true,其他扫描方式GUC参数设置为false,例如enable_indexscan = false - 如果是指定索引扫描,则设置
enable_indexscan = true,其他扫描方式为false,例如enable_seqscan = false - 其他依次类推。
- 如果限制使用某个索引进行扫描,则修改
rel->indexlist,将不希望使用的索引过滤掉。这里的rel->indexlist为RelOptInfo->indexlist字段,存储了基表的所有可用的索引信息。这个值是在query_planner->build_simple_rel->get_relation_info中获取的。
钩子函数实现如下:
void pg_hint_plan_set_rel_pathlist(PlannerInfo * root, RelOptInfo *rel, Index rti, RangeTblEntry *rte)
{
setup_hint_enforcement(root, rel, NULL, &phint)
{
// 限制扫描方式,根据hint提示,修改GUC参数
// 如果指定顺序扫描,则enable_seqscan为true,enable_indexscan等为false
// 其他扫描方式依次类推
setup_scan_method_enforcement(shint, current_hint_state);
// 限制可以使用的索引,将不期望使用的索引过滤掉
// 如果是SeqScan或者TidScan,则将rel->indexlist设置为空
// 其实顺序扫描这种方式是不会被删除的,因为它是最基本的扫描方式
restrict_indexes(root, shint, rel, using_parent_hint);
}
// 根据hint提示修改后,重新生成基本路径
set_plain_rel_pathlist(root, rel, rte);
}
static void restrict_indexes(PlannerInfo *root, ScanMethodHint *hint, RelOptInfo *rel, bool using_parent_hint)
{
// 如果是SeqScan或者TidScan,则将rel->indexlist设置为空
if (hint->enforce_mask == ENABLE_SEQSCAN || hint->enforce_mask == ENABLE_TIDSCAN)
{
list_free_deep(rel->indexlist);
rel->indexlist = NIL;
hint->base.state = HINT_STATE_USED;
return;
}
// 遍历基表所有的索引
foreach (cell, rel->indexlist)
{
IndexOptInfo *info = (IndexOptInfo *) lfirst(cell);
char *indexname = get_rel_name(info->indexoid);
ListCell *l;
bool use_index = false;
// 遍历hint提示中的索引
foreach(l, hint->indexnames)
{
char *hintname = (char *) lfirst(l);
bool result;
// 如果名称匹配,则result为ture
if (hint->regexp)
result = regexpeq(indexname, hintname);
else
result = RelnameCmp(&indexname, &hintname) == 0;
if (result)
{
use_index = true; // 表示这个索引是期望被使用的
break;
}
// 如果索引期望被使用,则不从列表中删除,否则删除掉
if (!use_index)
rel->indexlist = foreach_delete_current(rel->indexlist, cell);
}
}
}
调用栈:
pg_hint_plan.so!pg_hint_plan_set_rel_pathlist(PlannerInfo * root, RelOptInfo * rel, Index rti, RangeTblEntry * rte) (contrib\pg_hint_plan\pg_hint_plan.c:4718)
set_rel_pathlist(PlannerInfo * root, RelOptInfo * rel, Index rti, RangeTblEntry * rte) (src\backend\optimizer\path\allpaths.c:541)
set_base_rel_pathlists(PlannerInfo * root) (src\backend\optimizer\path\allpaths.c:353)
make_one_rel(PlannerInfo * root, List * joinlist) (src\backend\optimizer\path\allpaths.c:223)
query_planner(PlannerInfo * root, query_pathkeys_callback qp_callback, void * qp_extra) (src\backend\optimizer\plan\planmain.c:276)
grouping_planner(PlannerInfo * root, double tuple_fraction) (src\backend\optimizer\plan\planner.c:1442)
subquery_planner(PlannerGlobal * glob, Query * parse, PlannerInfo * parent_root, _Bool hasRecursion, double tuple_fraction) (src\backend\optimizer\plan\planner.c:1019)
standard_planner(Query * parse, const char * query_string, int cursorOptions, ParamListInfo boundParams) (src\backend\optimizer\plan\planner.c:402)
plan_filter.so!limit_func(Query * parse, const char * queryString, int cursorOptions, ParamListInfo boundParams) (contrib\pg_plan_filter\plan_filter.c:134)
pg_hint_plan.so!pg_hint_plan_planner(Query * parse, const char * query_string, int cursorOptions, ParamListInfo boundParams) (contrib\pg_hint_plan\pg_hint_plan.c:3170)
planner(Query * parse, const char * query_string, int cursorOptions, ParamListInfo boundParams) (src\backend\optimizer\plan\planner.c:269)
pg_plan_query(Query * querytree, const char * query_string, int cursorOptions, ParamListInfo boundParams) (src\backend\tcop\postgres.c:850)
pg_plan_queries(List * querytrees, const char * query_string, int cursorOptions, ParamListInfo boundParams) (src\backend\tcop\postgres.c:942)
exec_simple_query(const char * query_string) (src\backend\tcop\postgres.c:1136)
PostgresMain(int argc, char ** argv, const char * dbname, const char * username) (src\backend\tcop\postgres.c:4606)
BackendRun(Port * port) (src\backend\postmaster\postmaster.c:4539)
BackendStartup(Port * port) (src\backend\postmaster\postmaster.c:4261)
ServerLoop() (src\backend\postmaster\postmaster.c:1748)
PostmasterMain(int argc, char ** argv) (src\backend\postmaster\postmaster.c:1420)
main(int argc, char ** argv) (src\backend\main\main.c:211)
GUC参数配置提示实现原理
Set提示的实现比较简单,更改GUC参数。
static PlannedStmt *pg_hint_plan_planner(Query *parse, const char *query_string, int cursorOptions, ParamListInfo boundParams)
{
// 1. 从注释或提示表中获取提示信息,并设置HintState
// 2. 处理Set hint提示,内部会调用set_config_option设置GUC参数
setup_guc_enforcement(current_hint_state->set_hints,
current_hint_state->num_hints[HINT_TYPE_SET],
current_hint_state->context);
// 3. 调用查询优化器
if (prev_planner)
result = (*prev_planner) (parse, query_string,
cursorOptions, boundParams);
else
result = standard_planner(parse, query_string,
cursorOptions, boundParams);
}
参考文档:
pg_hint_plan
SQL优化:一篇文章说清楚Oracle Hint的正确使用姿势
PolarDB对ordering index代价计算的改进
