




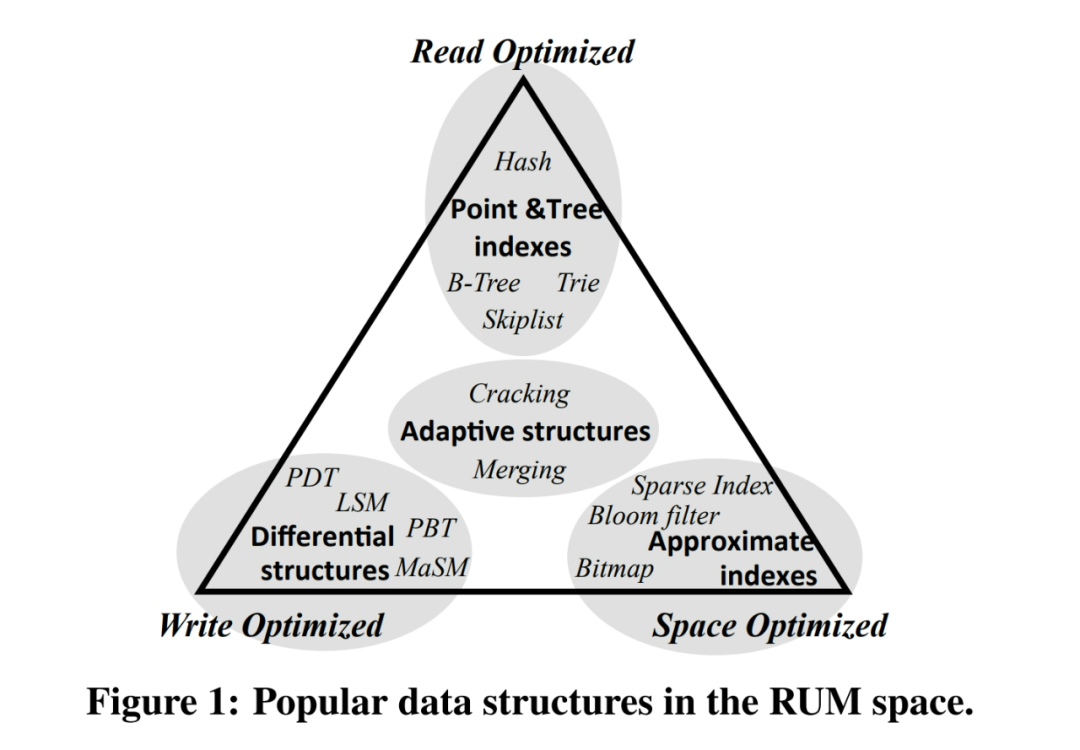
图来自《Designing Access Methods: The RUM Conjecture 》
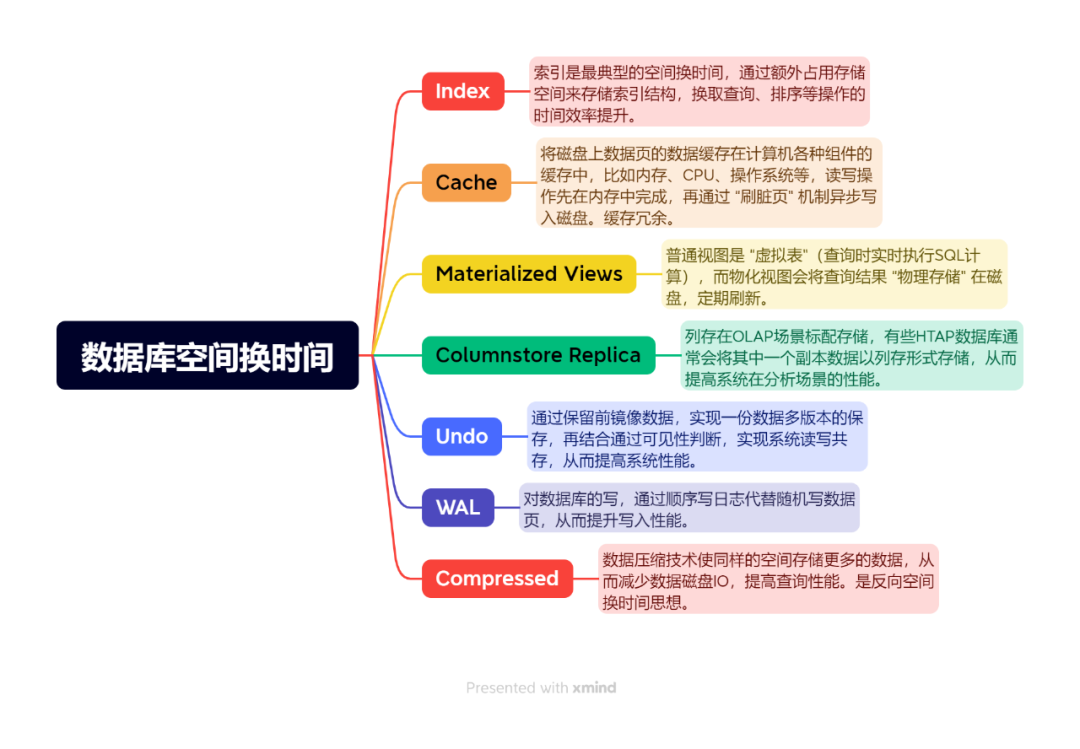
索引(Index)
索引是数据库“空间换时间”的最经典代表。作为一种独立于基础数据的辅助数据结构,通过占用额外存储空间,搭建起数据与物理地址的映射关系。在查询场景中,通过索引避免低效的全表扫描,将查询复杂度由O(N) 提升为O(log n)。
缓存(Cache)
缓存也几乎是所有数据库性能优化的核心组件,通过把磁盘上的数据页缓存到内存、CPU、操作系统等计算机组件中。当数据库收到读写请求,先在内存完成,后再通过“刷脏页”异步写入磁盘。
这就像把常用的数据放在高逼格的临时仓库,只要这部分数据被使用就可以快速响应请求,让读写不再频繁访问慢速永久仓库(磁盘)。用缓存的空间冗余,换来了读写效率的提升 ,极大缩短操作等待时间。
物化视图(Materialized Views)
普通视图(View)是 “虚拟”的,仅保存 SQL 查询逻辑不存储实际数据,每次调用视图都需重新执行底层 SQL(关联表、计算聚合、过滤条件等),相当于 “实时计算结果”。而物化视图(Materialized View)是 “物理”的, 需要独立占用存储空间,存储的是 SQL 查询的计算结果,本质上是一张 “预计算好的表”。物化视图的收益是后续查询直接读取这张表的数据,无需重复执行原始 SQL,从而提高查询效率。
物化视图除了存储代价,若原始数据更新,它需通过 “刷新”同步结果,而刷新过程中可能产生临时表、日志文件等开销,进一步增加空间成本。因此,物化视图通常使用在OLAP 等场景,把经常查询且原始表相对静态的数据持久化存储,从而提高查询性能。
列存副本(Columnstore Replica)
在OLTP 场景,数据通常以行存的形式存储;而在OLAP场景,列存更符合统计分析查询需求。因此,部分 HTAP 数据库主数据以行存的格式支持OLTP,而副本以列存形式存储用于支持OLAP,从而实现一个数据库既能支持在线交易,又可以支持统计分析,实现混合事务模型。
回滚段(Undo)
数据库的 undo 机制亦是典型的空间换时间。通过存储数据前镜像构建多版本链,使 MVCC 快照读能基于可见性判断获取一致性视图,规避读写冲突,提高系统的并发和性能。
当然类似PG 数据库并没有独立的 undo 组件,但也是通过存储历史数据的不同版本实现MVCC,从而提升系统读写性能。其设计思想仍然是通过空间换时间。此外需要注意的是,部分数据库在写入undo的产生的变化也会写入事务日志,用于实例意外关机时做崩溃恢复。
预写日志(WAL)
数据库的预写日志(Write-Ahead Logging,WAL)也是典型的空间换时间,通过牺牲一定的存储空间,将数据持久化由随机写数据页变成顺序写WAL 日志实现,从而提高数据库的写入能力。
当然WAL 日志主要是为了满足数据库核心需求之一是 “持久性”, 即确保用户写入的数据后,那怕服务器在断电、崩溃等异常时数据仍然不丢失。若不使用 WAL,数据写入需直接修改磁盘上的数据文件,但这种方式会出现大量随机写,无法满足数据库的写入性能。
压缩(Compressed)
数据压缩看似和空间换时间相反,实则能更高效的利用空间,实现同等容量的空间下存储更多的数据,从而实现数据库系统的性能提升。
数据库一般都有最小读写存储单元,称为块或者页,默认通常为8k或者16k。数据压缩技术实现了同样存储单元,可以存取更多的数据,意味着读写数据可以减少磁盘IO。虽然压缩和解压要消耗计算资源(时间),但减少了数据传输、存储的空间,从整体看,通过减少IO耗时,用计算空间(压缩算法的处理)和存储调整,换来了查询性能提升,是反向的空间换时间设计思想
总结
以上就是数据库设计中从不同维度诠释空间换时间,除此以外在数仓领域的分层设计、表字段冗余以及数据副本存储等数据库架构设计,也出处体现着该设计思想。

作者介绍
司马辽太杰,10余年数据库架构和运维管理经验,擅长常见关系型、NoSQL、MPP 等类型数据库。业余热爱历史、足球,读点闲书。欢迎关注个人公众号“程序猿读历史”。有需要联系的可以从公众号上扫码加我好友,感谢。

