




CDC 介绍
CDC ( Change Data Capture )节点指变动数据捕获节点,用于对 GoldenDB 数据库分布式模式下各个分片的 DN 节点进行数据捕获。
CDC 功能说明
CDC 通过获取每个分片的 binlog ,进行合并归档,生成一份单机 DN 可以消费的 binlog ,即全局一致性 binlog 。 CDC 可以作为单一 DN 的 master ,通过建立主备关系,让 DN 消费全局一致性 binlog 。也可以使用第三方回流工具解析全局一致性 binlog 进行消费。
CDC 部署
本节将介绍 CDC 的部署,61303 及之后版本使用下面的方法。
配置项说明
CDC配置项说明表
| 节点 | 配置项 | 参考值 | 生效方式 |
|---|---|---|---|
| CDC | slave_replay_performance | NONE | 动态生效 执行 set global |
| CDC | relay_log_cdc_role | ON | 只读 |
| CDC | rpl_semi_sync_master_enabled | OFF | 动态生效 执行 set global |
| CDC | rpl_semi_sync_slave_enabled | OFF | 动态生效 执行 set global |
| CDC | disable_clone_gtid_persist | ON | 静态生效 修改参数文件 my.cnf 后重启节点 |
| CDC | sql_mode | 和集群 DN 中的 sql_mode 保持一致 | 动态生效 执行 set global |
| CDC | parse_mode | 和集群 DN 中的 parse_mode 保持一致 | 动态生效 执行 set global |
| CDC | cdc_ctid_discard_threshold | 根据最长的事务来,如果大事务会执行一个小时,建议将值配成 min{单分片一个小时生成的 binlog 量,CDC 所在环境系统剩余内存}/ 10K,比如某份偏每小时产生的 binlog 量为 7G/h,内存足够。那么理论 70w 足够,建议配成 200w。 | 动态生效 执行set global |
| CN | filter_dbname | 检查是否有配置 heartbeat_info 和 delay_test | 动态生效 修改参数文件 proxy.ini 后 dbtool -p -lc |
| DN | support_cdc | ON | 动态生效 执行 set global |
安装 CDC 流程
通过 insight 页面,在租户管理 > 集群 > 实例信息,打开集群级
support_cdc开关。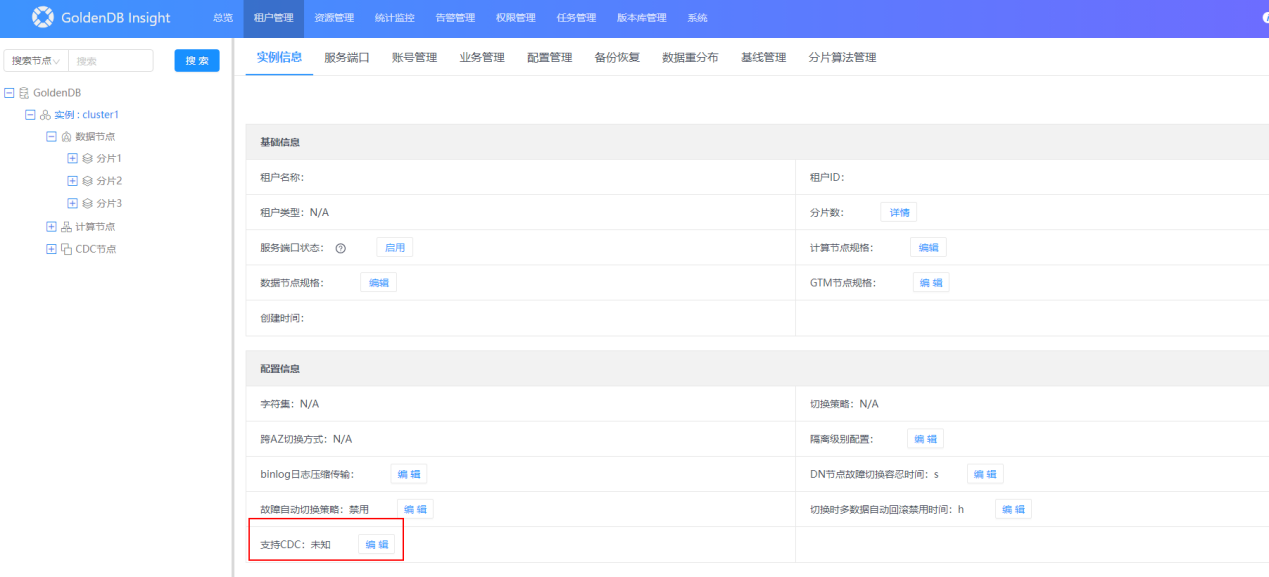
集群级support_cdc开关界面
insight 页面新增
CDC,在租户管理 > 集群 > CDC 节点,点击页面左上方的新增按钮。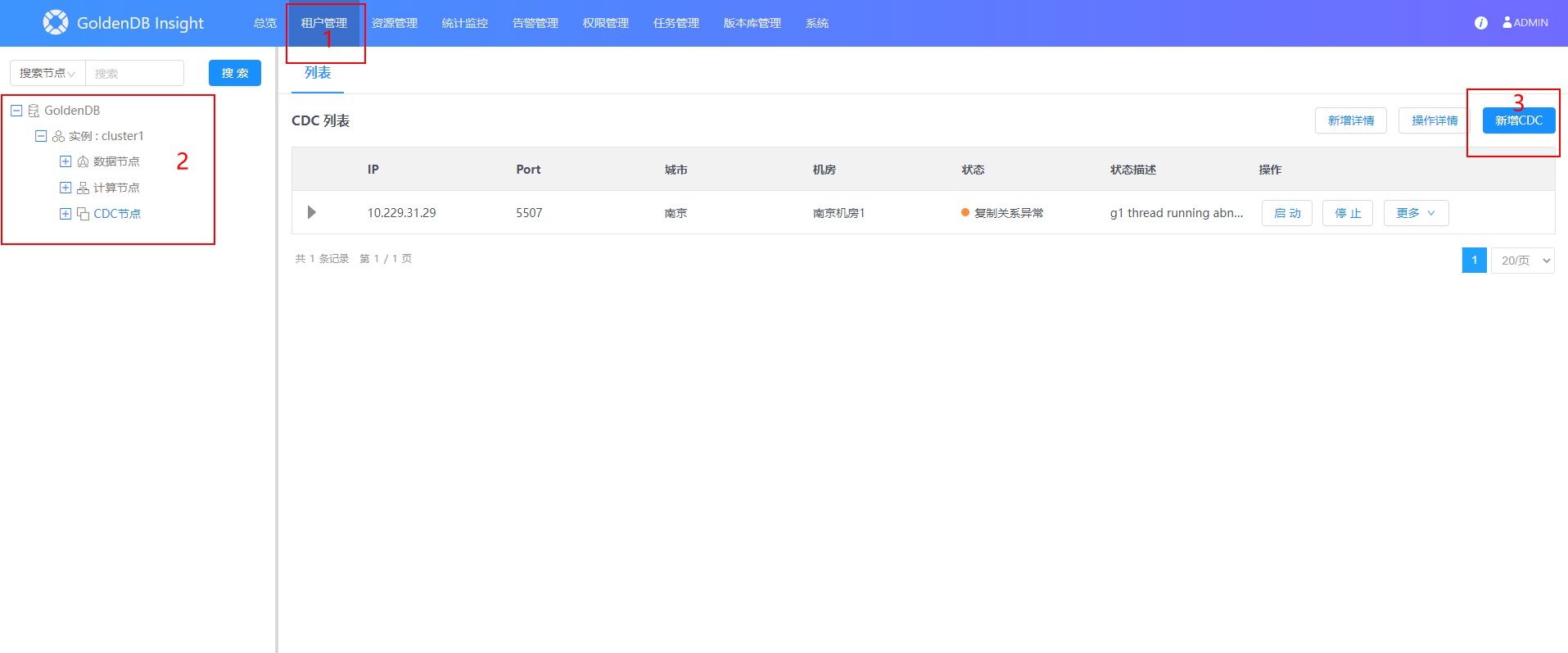
新增CDC页面
通过新增详情可查看新增进度:
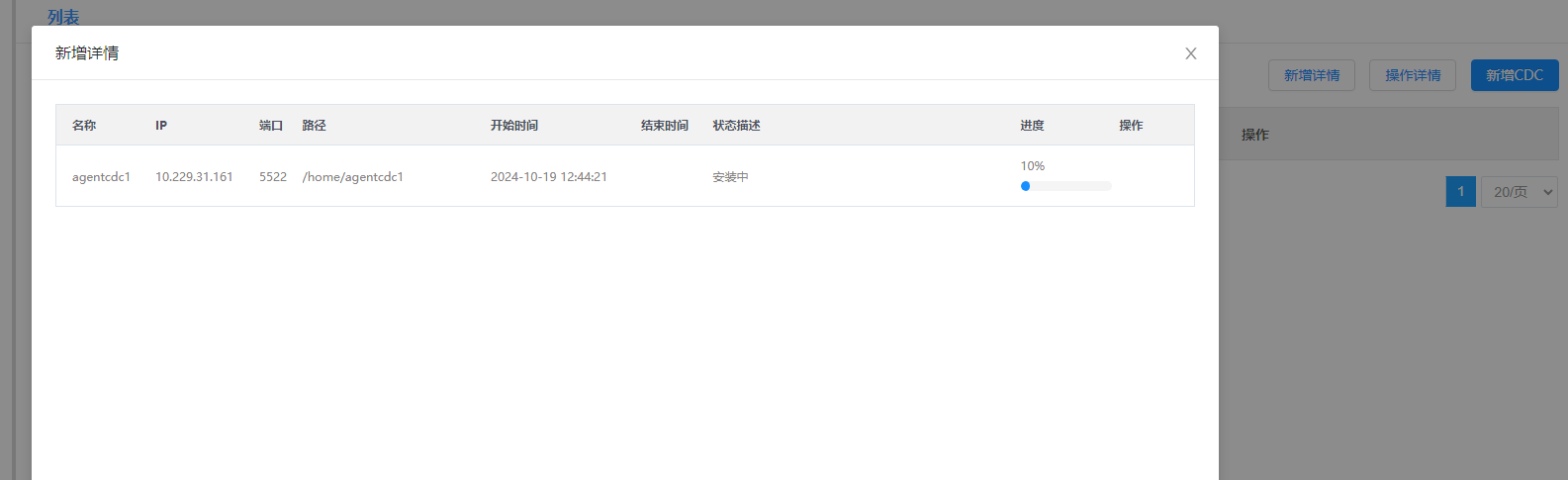
新增CDC进度页面
3. 新增完成后查看 CDC 状态是否正常
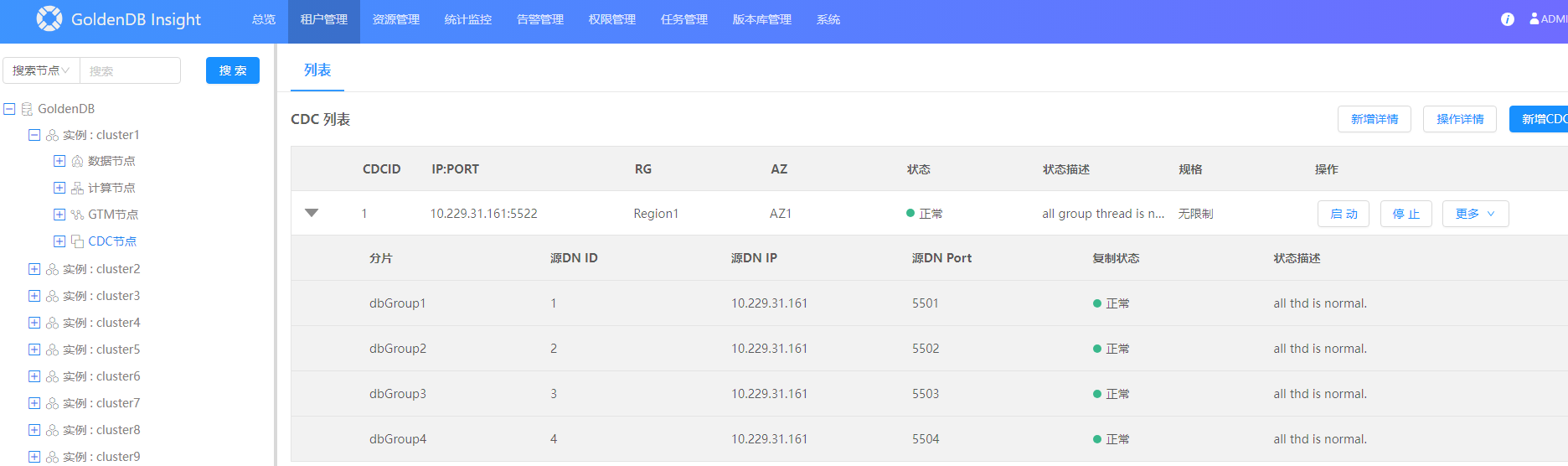
CDC状态展示页面
CDC 的启停、重设点位等可参考 4.3.14 管理CDC节点。
CDC 语法规范
本节将介绍 CDC 支持的语法、应用限制、应用方式,用于帮助业务开发人员了解如何基于分布式数据库或者单机数据库使用变动数据捕获功能。
SQL 语法
START SLAVE CDC 启动备机的
CDC功能,包括IO线程,FETCH线程,COMPOSE线程。START SLAVE CDC COMPOSE_THREAD 单独启动备机
CDC功能中的FETCH线程和COMPOSE线程。START SLAVE IO_THREAD 单独启动
IO线程。STOP SLAVE CDC 停止备机的
CDC功能,包括IO线程,FETCH线程,COMPOSE线程。STOP SLAVE CDC COMPOSE_THREAD 单独停止备机的
CDC功能中的FETCH线程,COMPOSE线程。STOP SLAVE IO_THREAD 单独关闭 IO 线程。
RESET MASTER 清空历史
binlog日志,初始化CDC环境。RESET SLAVE 清空历史
relay-log日志,初始化CDC环境。RESET SLAVE ALL 清空历史
relay-log日志和,清空与各分片的多源复制信息,初始化CDC环境。执行该命令后需要重新与各分片建立多源复制关系。CHANGE MASTER TO … 与某分片建立复制关系。
> CHANGE MASTER TO MASTER_HOST='分片1主机ip',MASTER_PORT=端口号, MASTER_USER='用户名', MASTER_PASSWORD='密码', MASTER_AUTO_POSITION=1 FOR CHANNEL '分片标识';注意:
FOR CHANNEL 参数’分片标识’,需要使用 g1,g2…,其中 g1 代表第一个分片, g2 代表第二个分片,以此类推。
- 【禁止】START SLAVE, STOP SLAVE
CDC节点不提供主备同步功能,禁用以下 SQL :
> START SLAVE;
> STOP SLAVE;- 【禁止】START SLAVE SQL_THREAD, STOP SLAVE SQL_THREAD
CDC节点不提供主备同步功能,没有使用 SQL 线程,禁用以下 SQL :
> START SLAVE SQL_THREAD;
> STOP SLAVE SQL_THREAD;- 【禁止】其他类型 SQL
CDC节点原则上禁止执行除文档中列出的各个 SQL 以及查询操作以外的 SQL 命令,避免引发不可知的错误。
CDC 状态显示
SHOW SLAVE CDC STATUS 用来显示
CDC状态。CDC状态项如下: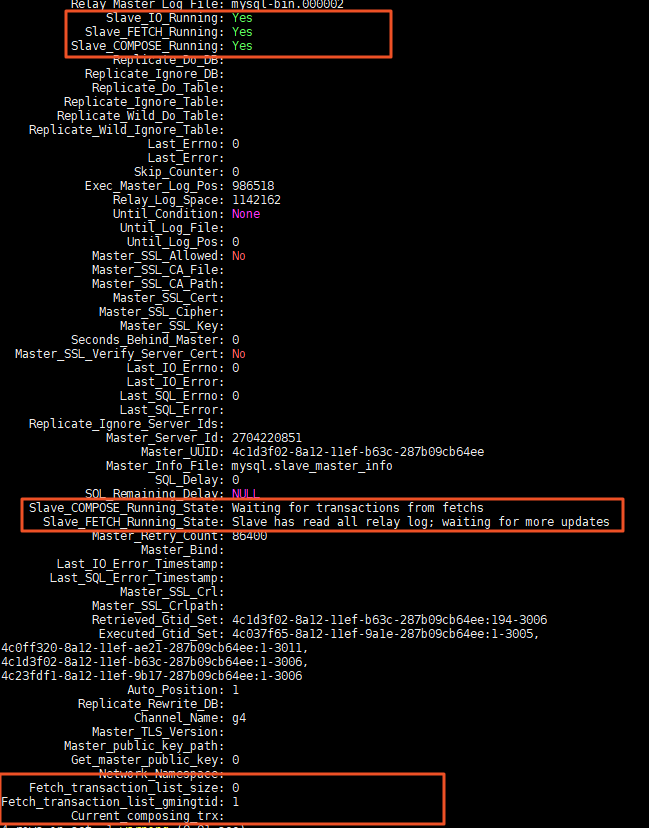
cdc功能状态展示
其中每项说明如下:
- Slave_FETCH_Running
FETCH线程是否启动。YES 表示已启动;NO 表示关闭 - Slave_COMPOSE_Running
COMPOSE线程是否启动。YES 表示已启动;NO 表示关闭 - Slave_FETCH_Running_State(当前FETCH线程状态),包含下表三种状态:
Slave_FETCH_Running_State状态说明表
| 状态显示内容 | 含义 |
|---|---|
| Waiting for [Channel_name] transaction queue free | Channel_name 的 FETCH 线程的队列已满,等待 FETCH 线程释放出空闲的位置 |
| Fetch has read all relay log from [Channel_name]; waiting for more updates | Channel_name 的 FETCH 线程已经读完它对应的 relay log,等待 GDB 的更新 |
| Fetching distribute transaction from [Channel_name] | 正在从 Channel_name 获取事务 |
- Slave_COMPOSE_Running_State(当前 COMPOSE 线程状态),包含下表三种状态:
Slave_COMPOSE_Running_State状态说明表
| 状态显示内容 | 含义 |
|---|---|
| Waiting for transactions from fetchs | 当前所有 FETCH 线程的队列都为空,没有需要合并的事务 |
| Waiting for an transaction from [Channel_name] | 当前 COMPOSE 线程需要 Channel_name 上的事务 |
| Composing distribute transaction | 正在合并分布式事务 |
- Fetch_transaction_list_size 当前
FETCH线程事务队列大小 - Fetch_transaction_list_gmingtid 当前
FETCH线程事务队列中最大的GMINGTID的值 - Current_composing_trx 当前正在合并的事务信息
CDC 使用说明
本节将介绍 CDC 的使用说明。
- 【规则】设置位点
方法一:DBAgent 自动设置位点 运行过程中,DBAgent 组件内部处理,一般情形下,不需要人工干预。
方法二:连主集群,SHOW MASTER STATUS; 手动 CHANGE MASTER,可能会有多分片 直连集群中每个分片的主 DN,获取每个分片中主机的 GTID 集合。 将这些主机的 GTID 集合做个并集。
CDC顺序执行 STOP SLAVE CDC; RESET SLAVE ALL; RESET MASTER; SET GTID_PURGED=’GTID 集合的并集’; CHANGE MASTER …; START SLAVE CDC;
- 【规则】channel 名字需要为 g1,g2…
CDC角色执行 CHANGE MASTER … FOR CHANNEL ‘g1’; 命令时,需要加FOR CHANNEL参数,并且需要使用g1,g2… 其中 g1 代表第一个分片,g2 代表第二个分片,以此类推。
- 【规则】检查 GTID 信息
- 人工获取
CDC同步的位点时,需要解析binlog检查每个分片查询到的GTID前后的逻辑关系,以及分片之间的前后关系,尤其是删库、删表、修改表的一系列操作,减少回放CDC数据冲突的可能。
- 【规则】如果想要不 RESET MASTER;从某一个 GTID 开始回放
- 以三个分片为例,
CDC回放完三个分片的 GTID 集合均为 1-5,想要在不清理binlog的情形下,实现从 8 开始回放,具体步骤如下:CDC所在用户下执行 dbmoni -stop;mysql.server start; 连上CDC,查询表mysql.gtid_executed;执行更新操作: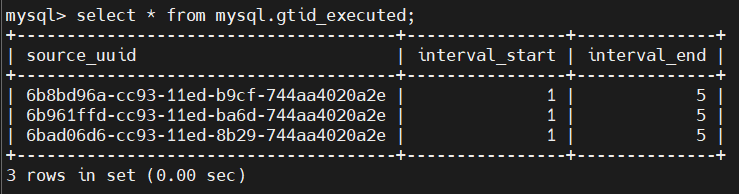 执行 mysql.server stop;dbmoini -start;
执行 mysql.server stop;dbmoini -start;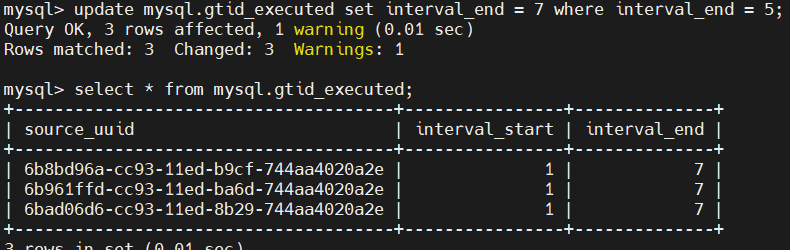
- 【规则】主集群不要直连每个分片的 DN,执行一样的 DDL,比如创同一张表
- 直连不同的 DN 创建同一张表时,由于直连 DN 执行的语句没有
CTID( CN 下发),DN 认为是单机事务,正常合并,但是在其他备机回放CDC的数据时,引发回放失败。
- 【规则】
CDC节点使用期间,主 DN 的binlog和原生不兼容,不要使用第三方工具消费;但全局一致性binlog和原生兼容,可以使用第三方工具消费
- 为了实现
CDC事务内 DML 排序功能,增加了support_cdc开关。 集群中 DN 的support_cdc开关开启,DML 携带seq信息后会将信息记录在table map event中。此时主 DN 的binlog和原生不兼容。CDC在消费集群binlog的过程中,根据事务内排序的 seq 进行排序,会去掉相关的 seq。此时CDC的binlog和原生兼容。
- 【规则】必须保证 DN、CN、GTM 打开
support_cdc之后产生的binlog才可以用CDC消费
- 只有 DN、CN、GTM 节点都打开后,产生的
binlog才是CDC可以消费的,不然CDC会报错,全局一致性binlog也可能不准确。
- 【规则】系统视图/库级别下数据的过滤
CDC如果需要过滤某个系统视图/库,需要在表mysql.cdc_ignore_table_info插入对应的数据。例如:表中存在记录(‘cdc_01’,’’,’’),(‘cdc_02’,’’,‘g1’),库cdc_01和库cdc_02下的数据都会被丢弃。需要结合stop slave cdc;start slave cdc;才能生效。
- 【建议】尽可能不要直连分片的 DN,执行 SQL,不安全
- DN 是集群一部分,给整个集群服务的,通常通过 CN 执行一系列 SQL,而不是 DN。
- 另外,直连 DN 执行 SQL 的话,会引发回放
CDC上binlog的备机存在异常的风险。
- 【建议】
CDC上不要手动执行一些 DDL/DML 的 SQL,免得影响后续回放
CDC的主要功能是同步集群中所有分片的binlog,并合并。这个过程如果收到执行一些 DDL/DML 会干扰 GTID 集合和binlog,可能会影响数据的回放。
- 【建议】不要频繁的用不同的分片方式创建删除一张表,如先建 t1 表,分发规则为 hash,再删了,再建成复制表,来回反复
- 理论上操作是可行的。但是,分发规则是复制表的时候,
CDC根据表mysql.cdc_ignore_table_info的配置保留某个分片上特定的binlog,频繁的操作还涉及到系统表的更新,不建议这么做。另外,频繁使用不同分发规则创建删除表的时候,遇到该表涉及的问题,影响定位的效率,给定位问题增加难度。
- 【建议】不要执行某个分片时间过长的大事务
- 以两个分片为例,长事务中,分片 1 上存在大量的语句,而分片 2 的语句特别少,该事务是大事务且是不均匀分布的,这样会引发
CDC在合并的时候,少的分片会等多的分片场景,降低CDC的合并速率,影响性能。 同时,如果一个事务一天都没执行完,在CDC很有可能会认为是不合理的,从而忽略这个事务,如果真有这样的大事务,请同步增大配置项cdc_ctid_discard_threshold(主集群中单分片一日binlog产生量/ 10k)和cdc_ctid_discard_seconds(默认为一天,事务超过一天没执行完,CDC会自动丢弃)。
- 【建议】回滚失败的事务,及时释放 GTID,避免 GTM 不释放 GTID
- 正常情形下,回滚失败的事务,释放
GTMGTID不需要人工参与,但是有可能存在异常发生,例如服务器断电重启,可能会引发释放GTMGTID失败,引发最小的GTMGTID一直不增加。 - 当
GTMGTID不增加的时候,CDC在合并的时候会引起事务的GTID集合出现空洞发生,此时需要检查最小的GTMGTID是否是已提交回滚失败的事务或者属于很早之前的事务。如果是,那么需要手动释放相应的最小 GTID 。以释放单个GTMGTID为例,GTM 所在用户下执行dbtool -gtm -dg -cid=N GTID。
CDC 使用限制说明
本节将介绍 CDC 的使用限制说明。
部分对象不下 DN,将不会回流
- 以下对象不下到 DN 上,DN 上的
binlog中无相应对象,因此不会回流,如:走 MPP 创建的视图、存储过程、触发器、函数、用户、SEQUENCE、包、自定义类型、事件。
不支持 XA 事务
XA事务在分布式架构中,是新的实现方式,还需要补充完善,CDC暂不支持该用法。如果使用了XA事务,可能出现数据冲突,导致回流失败。
不支持串行化 DDL
- CN配置项
ddl_execute_serial其默认值为 0, 表示不使用串行 DDL 。
不支持 EVENT
- 当前版本中,使用
CDC功能时不能使用EVENT。 - 通过 CN 创建事件后,事件都是由各分片 DN 各自驱动执行。事件触发写入的
binlog记录中缺少CDC合并所需CTID信息。可能导致数据冲突或 DDL 冲突,CDC回流失败。
DDL 语句涉及非 InnoDB 表
版本中创建表,若不指定表类型,默认为 InnoDB表
涉及
MYISAM表的 DDL 操作不会记录commit hint信息,因此使用MYISAM表会导致回流失败。禁止业务上创建和使用
MYISAM表。
非ROW格式binlog
版本中默认的binlog格式为ROW格式。
CDC所有binlog合并的设计都是基于ROW格式的binlog,因此使用非ROW格式的binlog将导致CDC功能不可用。禁止将集群中
binlog格式设置为ROW以外的格式。
并发 DDL 场景下无法保证提交序,可能会回流失败
- 当前的架构下,对于并发 DDL 支持执行前后对于数据没有影响的场景,对于数据有影响的是不受控的,可能会导致回流失败。比如说业务在并发的插入数据,然后后台不断的
truncate table,这种时候truncate table之后的表数据是多少谁也不知道,这种依赖数据库时序,是不符合业务逻辑的。需要业务在truncate table之后,收到成功响应后,触发后续的业务逻辑插数据。其余的建库,删库,建表等都是同理。
直连 DN 执行单机写业务
- 对于直连DN操作的单机写事务是没有
CTID信息的,因此CDC会将单机写事务直接写入binlog,这就导致在回流时可能会因为冲突而失败。 - 所有业务需要通过 CN 操作,禁止直连 DN 执行单机写事务。
新增分片/删除分片
CDC环境不可随意新增分片/删除分片,否则会导致合并异常或数据丢失。- 如果真的要新增分片/删除分片,请等
CDC合并结束,停止CDC,并根据当前分片信息重新建立主备关系。
违背业务逻辑的 SQL
- 违背业务逻辑的 SQL 是指与业务上下文明显矛盾的 SQL,比如先把分区范围改成 <= 100,然后插入分区键为 200 的行。这种明显矛盾的 SQL,在分布式框架中表现可能为部分分片成功,部分分片失败,最终导致
CDC回流失败。
数据重分布
- 数据重分布功能导致的表的分发规则的改变
CDC目前无法识别,例如单节点复制表经过重分布之后变成多节点复制表,CDC仍会将其当做单节点复制表进行处理,回流时可能会有部分事务冲突而失败。
不支持非分布式函数,触发器
版本中已经配置CN的parse_mode = 2, 不会存在非分布式函数与非分布式触发器。
非分布式函数与非分布式触发器指的是 CN 下压到每个分片的主 DN 执行的函数与触发器。函数与触发器写入的
binlog记录中缺少CDC合并所需CTID信息,合并时可能出现数据冲突,导致CDC回放失败。CN 配置 parse_mode = 2,CN 不会下压函数与触发器到 DN 上。
不支持使用临时表
开启CDC后版本已禁止创建临时表,从CN执行报错。
开启
CDC功能后,不支持在 CN 上使用临时表。对临时表的 DML 操作使得 CN 无法精准给CDC提示哪些分片上存在数据变更,不能准确下发GMAP。CDC事务合并受到影响。
不支持业务事务内存在部分 DDL 的隐式提交
开启CDC后版本已禁止在事务中执行这些 DDL,从 CN 执行报错。
CDC不支持在业务的事务内出现以下 DDL/DCL 操作:
1)LOCK TABLE</BR>
2)UNLOCK TABLES</BR>
3)CHECK TABLE</BR>
4)ANALYZE TABLE</BR>
5)OPTIMIZE TABLE</BR>
6)FLUSH TABLE</BR>
7)CREATE/DROP/REVOKE/GRANT ROLE</BR>由于在事务内执行 DDL/DCL 会导致事务隐式提交,对下游 CDC 合并会产生干扰,导致数据可能异常,所以暂不支持事务内出现以上 DDL/DCL 的隐式提交。如果需要使用以上 DDL/DCL 语句,请在事务外执行。
不支持非分布式存储过程
开启CDC后版本已禁止非分布式存储过程创建,从 CN 执行报错。
非分布式存储过程会直接下压DN 执行call语句,由于不知道涉及到多少个分片,因此导致存储过程中的DML语句不带
CTID,会导致回流时事务顺序错乱而失败。建议业务上使用分布式存储过程,禁止使用非分布式存储过程。
分布式存储过程的语法格式:
> DELIMITER $$
CREATE PROCEDURE moti.sp1( i INTEGER)
BEGIN
SELECT 1 FROM DUAL;
END DISTRIBUTED BY HASH(i)(g1)$$
DELIMITER ;添加全局唯一索引或者唯一索引校验失败的场景
添加(全局)唯一索引失败,可能存在 DDL 在部分分片成功,部分分片失败的场景,可能影响回流。下面分情况介绍:
场景一:表中(全局)唯一索引存在重复数据,导致的失败。 原集群添加(全局)唯一索引失败后,一般应该处理重复数据后,重试DDL添加(全局)唯一索引。CN 会过滤部分分片索引已存在的错误,客户端将收到成功响应。 对于
CDC来说,部分成功的 DDL 也会合并。第一次添加全局索引时,会将部分成功的分片的 DDL 合并。第二次添加全局索引时,仍然是部分分片成功(没有索引的分片成功,有索引的分片报错索引存在,CN 过滤错误),CDC会将部分成功的DDL合并。结果是CDC合并的binlog中将出现两条添加唯一索引的 DDL。 对于回流的数据库来说,第一次回流添加全局索引,回流库同样有重复数据,DDL 回流会报错。继续回流处理重复数据的 SQL,再回流第二次加索引的 DDL, 此时没有重复数据,预期成功。场景二:其他场景导致的失败(如分片异常)。 分片异常的情况下,对于原集群来说,一般处理是修复异常分片后再次尝试加索引的 DDL。 对于
CDC来说,此场景类似场景一,重试的 DDL 也会合并,binlog中有多条加索引的 DDL。 对于回流的数据库来说,此时第一次加全局索引,没有重复数据,预期成功。回流后面的加索引的 DDL,预期报错(索引已存在)。
不支持表包含唯一索引,不同分片之间含有重复数据
- 表中唯一索引存在分片内部数据唯一但是不同分片之间存在重复数据的情况,
CDC合并该表相关操作时会成功合并重复数据,预期表现在回流部分则是含有唯一索引的表插入重复数据失败报错。
不支持不同分片不同分区
开启 CDC 后版本已禁止该类型表创建,从 CN 执行报错。
不同分片不同分区指对同一张表,在不同分片上分区方式不同,如表在 g1 分片上是 hash 分区,在 g2 分片上是 range 分区。
使用不同分片不同分区表有可能导致回流失败,原因是不同分区表,每个分片上的建表语句
CDC都会合并,binlog中将记录多条同一张表的创表语句。同时,回流时表的分区只能有一种,CDC无法选定使用哪种分区。所以禁止业务上创建和使用不同分片不同分区表。
涉及复制表的多级分片表
开启 CDC 后版本已禁止该类型表创建,从CN 执行报错。
多级分片表示例:
> CREATE TABLE t1(Customer_Number int primary key, Corporation varchar(30), Public_Private_Type int, Bloc varchar(30), Customer_Name varchar(30))
DISTRIBUTED BY CASE CORPORATION
WHEN '北京' THEN g1;
ELSE SUBDISTRIBUTED BY DUPLICATE(g2,g3,g4);
END CASE; //上表数据在 g2-g4 间一致,g1 与 g2-g4 不一致,并不是真正的复制表,对于这种场景, CDC 无论是当复制表还是非复制表处理,回流都有可能冲突而失败。
不支持增删主键
- 开启
CDC后版本不支持增删主键:ALTER TABLE ADD/DROP PRIMARY KEY,从 CN 执行报错。
