




1. 业务及数据库表现
业务表现:业务响应慢,业务超时等,服务器资源占用率上升,TPS 下降。
数据库表现:SQL 执行时间长,服务器资源占用率上升。或 SQL 执行超时,前端驱动主动断开。
2. 应急排查方向
数据库响应慢,主要原因有慢 SQL,执行计划不合理,组件异常,数据冲突,服务器资源瓶颈等,针对以上场景制定不同的应急方案。
3. 应急排查流程
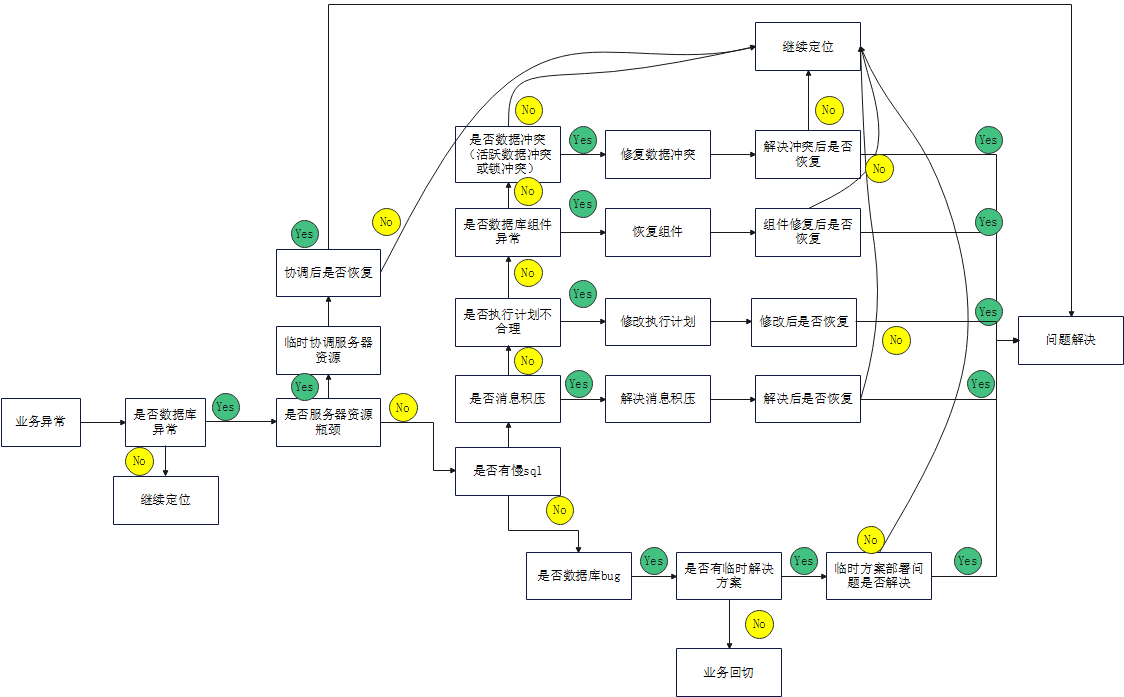
4. 应急流程启动的原则和前置条件
- 所有应急处置需要先获取客户授权审批后进行。
- TOP SQL 导致的数据库响应慢,先找出对应的 SQL,交由业务优化。征得客户同意,可以采用杀 SQL,加黑名单的方式解决 CPU 冲高导致慢的问题。
- 执行计划的变动,可以通过绑定执行计划应对。
- DN 锁等待与数据活跃会造成部分业务响应慢,最终报错。可以依据报错信息识别、处理。
- 组件异常会导致业务报错或短暂的响应慢,数据库会依靠高可用机制在1分钟内自动修复。如果已经自愈,不用处理。如果没有自愈, 参考数据库节点宕机 处理。
- 数据库提供一键诊断工具,包含 CPU 资源、连接数、消息积压等维度的检查诊断,现场已部署,在诊断响应慢的问题时,可以先执行诊断,获取诊断信息,帮助定位问题原因。
5. 应急操作指导
TOP SQL 查询
对于
TOP SQL导致的异常,主要的解决手段之一是优化 SQL,优化后可能会影响部分业务。应急处理操作
定位 TOP SQL
- 登录 Insight,打开 TOP SQL 页面,查询租户的 TOP SQL 。设置查询时间范围、选择 CN 节 点,进行查询。
- 可以通过 列管理 展示 SQL 执行更多维度的信息。
- 登录 Insight,打开 TOP SQL 页面,查询租户的 TOP SQL 。设置查询时间范围、选择 CN 节 点,进行查询。
分析执行计划 :
EXPLAIN <SQL>;SHOW CREATE TABLE <table_name>;
如果没有合适的索引,需要通过新增索引解决。继续下一步处理。创建索引 :
CREATE INDEX idx_xxx on TABLE(column);
- 查杀TOP SQL
对于
TOP SQL导致的异常,主要的解决手段之二是查杀TOP SQL,但需要注意的是,直接杀掉这些 SQL 可能会导致相关业务受到影响。
应急处理操作查杀 TOP SQL
通过 Insight 的 实时在线 SQL 分析 功能,设置时延阈值,可以查询当前正在执行的 SQL 的列表。找出执行时长最长的TOP SQL,执行kill操作。实时在线 SQL 分析功能使用说明
Insight:统计监控→诊断→实时在线 SQL 分析。查询超过时长阈值的 SQL
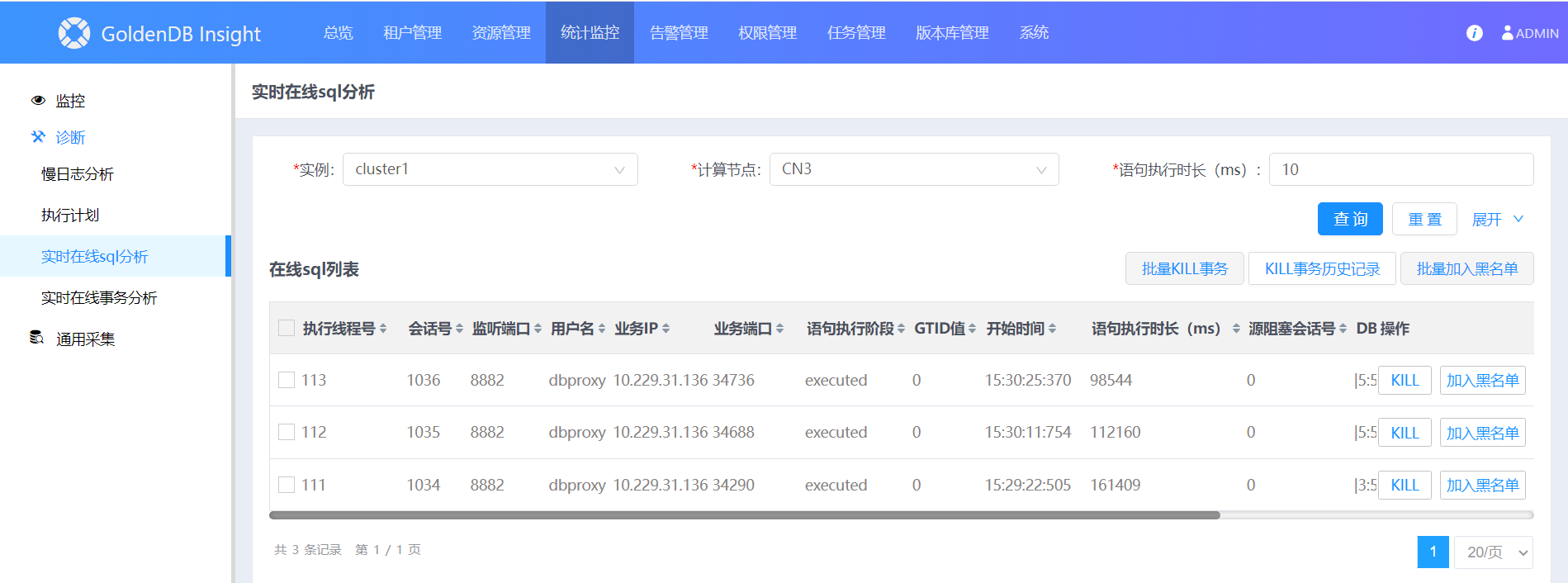
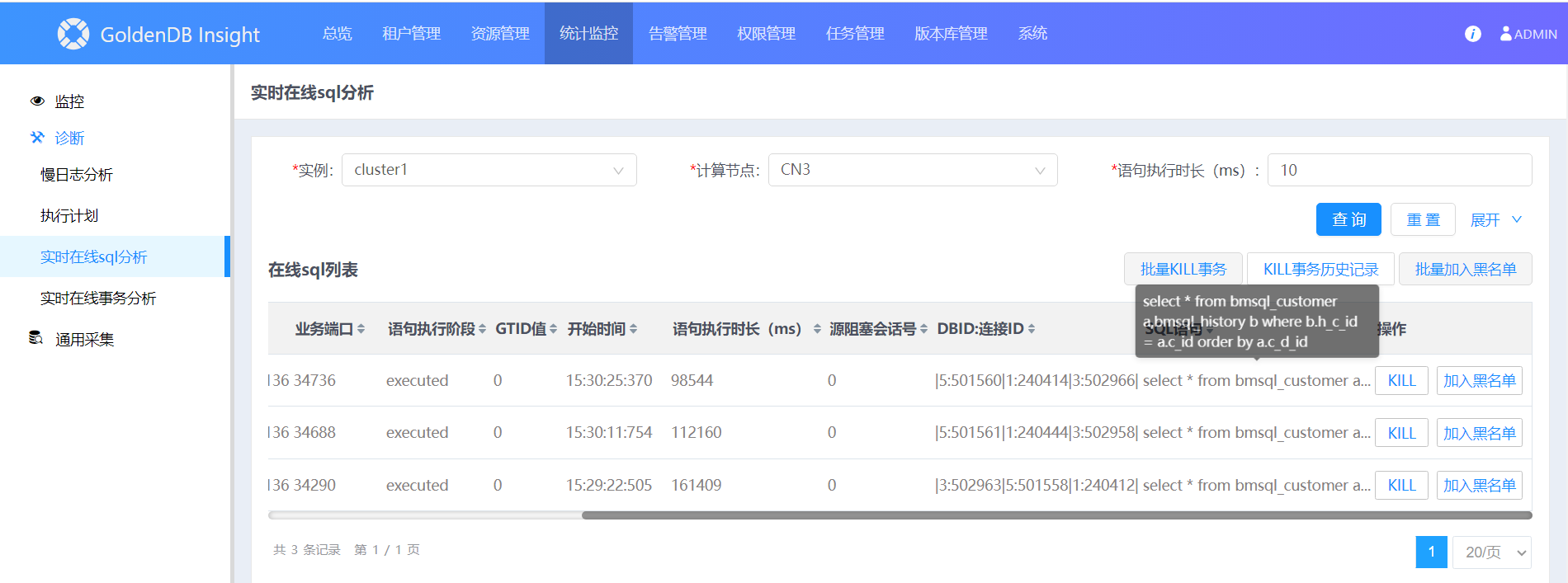
缩小分析对象
上面图中,关注两个字段:语句执行时长、语句执行阶段。根据这两个字段缩小分析对象。对于语句执行时长很长,语句执行阶段为executing、executed的 SQL,是重点怀疑对象。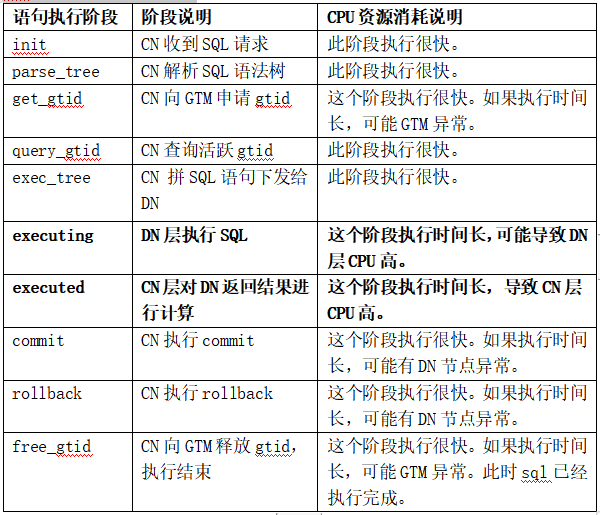
分析执行计划
再分析上面怀疑的 SQL 语句的执行计划进行判断,可通过 Insight:统计监控→诊断→执行计划,获取语句的执行计划。分布式执行计划实例(语句实例与字段含义说明结合在一起,帮助快速了解分布式执行计划。另一个例子 参见统计监控 节。
SQL 黑名单
SQL 导致的异常,主要的解决手段是将 SQL 加黑名单,执行黑名单中的 SQL 时会直接返回失败。某些涉及黑名单中 SQL 的业务会执行失败。
应急处理操作
通过 Insight 的 实时在线 SQL 分析功能 ,设置时延阈值,可以查询当前正在执行的 SQL 的列表。找出执行时长最长的
TOP SQL,可以将其加入 SQL 黑名单。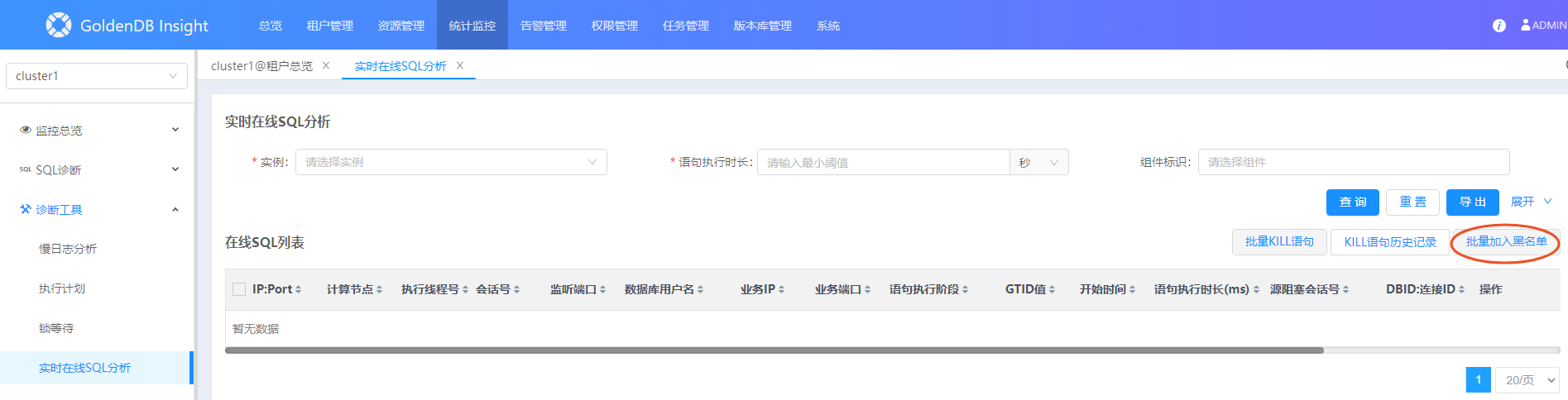
Insight 有一个专门的 SQL 黑名单功能 ,也可以将 SQL 加入黑名单。可以将前面查询到的 SQL 加入黑名单,阻止它的运行。黑名单支持精确匹配(即参数要完全一致才匹配)或模糊匹配(参数模式化,类似
prepare),可以根据需要选择。
DN 绑定执行计划
DN 层绑定执行计划如下:
绑定执行计划可以将SELECT语句的执行计划写入到系统表mysql.execution_plan,再次执行同类型的SELECT语句,即可复用相应的执行计划。对于mysql.execution_plan系统表中的执行计划,可以进行更新、删除、启用和禁用的操作(需要相应的系统表权限)。相关语法如下:
打开固定执行计划功能:SET GLOBAL persist_execution_plan = on; EXPLAIN FOR PERSIST SELECT stmt;固定执行计划 ,
INSERT执行计划到系统表mysql.execution_plan(需要系统表的INSERT权限),如果已存在,报错处理。EXPLAIN FOR FORCE PERSIST SELECT stmt;固定执行计划 ,同样
INSERT执行计划到系统表mysql.execution_plan(需要系统表的INSERT权限),如果已存在,进行UPDATE操作,否则仍进行INSERT操作。EXPLAIN FOR ENABLE PERSIST SELECT stmt;启用已固定的执行计划 ,从系统表
mysql.execution_plan中UPDATE相应的执行计划的enabled字段为yes(需要系统表的UPDATE权限),如果不存在,报错处理。EXPLAIN FOR DISABLE PERSIST SELECT stmt;禁用已固定的执行计划 ,从系统表
mysql.execution_plan中UPDATE相应的执行计划的enabled字段为no(需要系统表的UPDATE权限),如果不存在,报错处理。EXPLAIN FOR DELETE PERSIST SELECT stmt;删除已固定的执行计划 ,从系统表
mysql.execution_plan中DELETE相应的执行计划(需要系统表的DELETE权限),如果不存在,报错处理。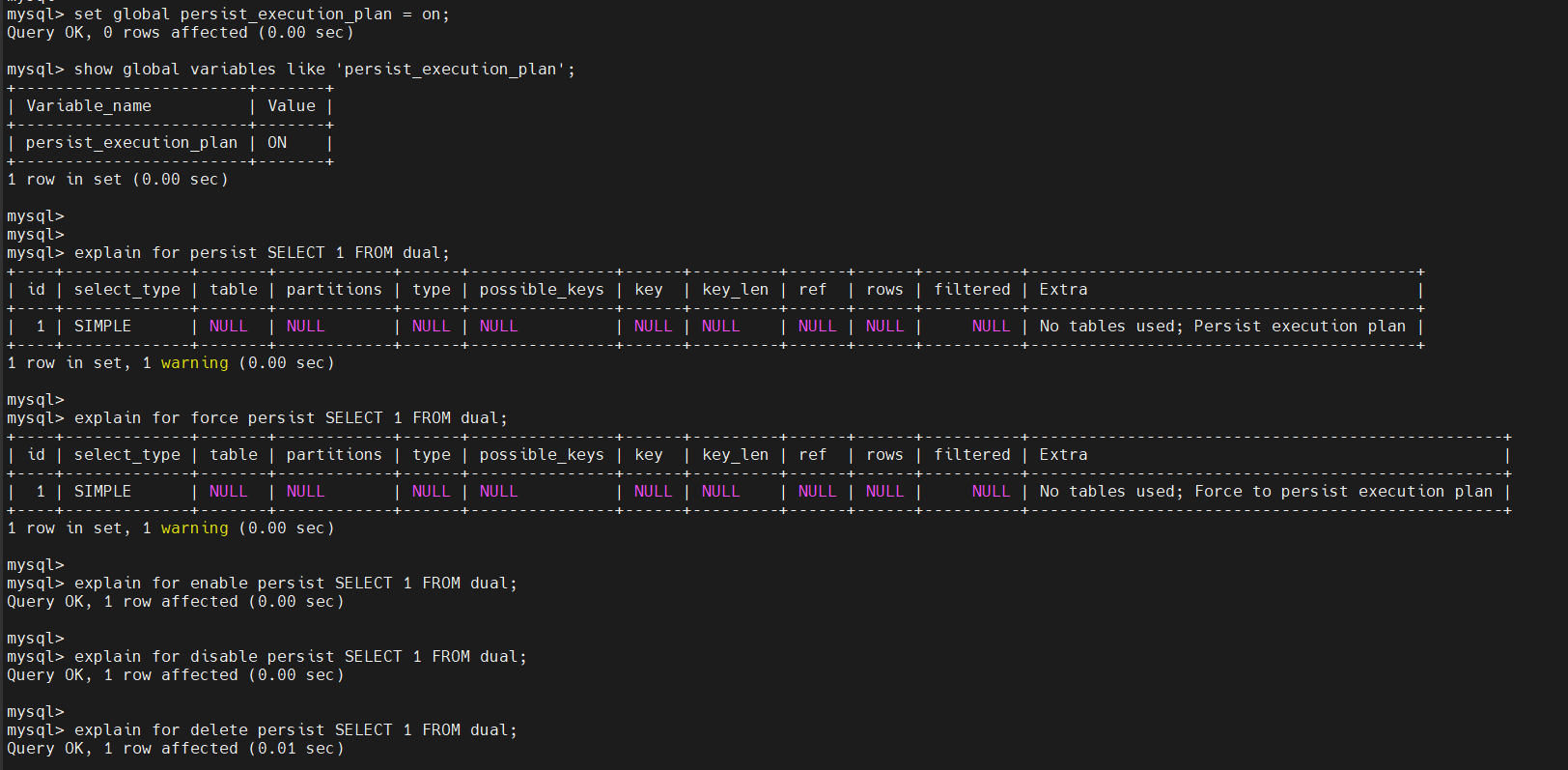
示例
对 SQL
SELECT * FROM a WHERE a3 in('1', '2') AND a4 < 40 AND a2 > 1000;的执行计划进行绑定。CREATE TABLE a(a1 int, a2 int, a3 VARCHAR(10), a4 int, INDEX(a1), INDEX(a2, a3), INDEX(a3, a4), INDEX(a4)); PREPARE cmd FROM 'SELECT digest, database_name, pattern, pattern_len, enabled, query_block_num, table_join_order, optimizer_switch_status FROM mysql.execution_plan'; TRUNCATE TABLE mysql.execution_plan; -- 绑定执行计划 INSERT INTO mysql.execution_plan VALUES('87f989a7cf1965f74079d19279ddf498', 'xf_db', 'SELECT `*` FROM `xf_db`.`a` WHERE ((`a3` in (?,?)) AND (`a4` < ?) AND (`a2` > ?))', 82, 'YES', 1, '{"1": [["xf_db", "a", "scans_params", 14, [2, "KEY (`a3`,`a4`)"], 1000, 2, [1.0, 0.21, 0.0, 0.0], 18446744073709551615]]}', '{"1": [["a"]]}', 45612543, '2021-10-11 05:55:00'); SET GLOBAL persist_execution_plan = ON; -- 验证 EXPLAIN SELECT * FROM a WHERE a3 in('1', '2') AND a4 < 40 AND a2 > 1000; EXECUTE cmd;
DN 锁等待
DN 锁等待,主要解决问题的手段是定位锁等待 SQL。数据库中锁等待的问题属于并发类性能问题或应用设计问题,此类问题在各系统环境中属于高发问题。当发生锁等待时,应用层面通常会表现很慢,甚至于无响应。
应急处理操作
根据应用侧返回 SQL 报错,确认出现锁等待的数据节点
锁等待时,应用侧会出现如下报错:
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction(Proxyid:1 Clusterid:1 Groupid:1 DBid:2),please rollback!
DBid:2 提示了出现锁等待的 DN 节点信息。前往当前 DN,查看锁等待日志
- 在 Insight 页面的[ 租户管理→配置管理 ]页面查看
innodb_lock_wait_log锁等待日志开关是否已经打开。 如果为ON表示已打开,OFF表示未打开。锁等待日志路径为参数innodb_lock_wait_log_dir的值,同样可以在页面上查看。 - 继续执行业务,锁等待日志记录信息。
- 登录 DN 所在用户,查看锁等待日志。
- 在 Insight 页面的[ 租户管理→配置管理 ]页面查看
锁等待日志分析
查看锁等待日志:
vi innodb_lock_wait.log
内容示例:
说明:
req_thd_id 请求锁事务对应的 thread_id;
req_trx_id请求锁事务对应的事务 ID;
req_trx_seq 请求锁事务对应的交易流水号(没有则显示 0);
req_gtm_gtid 请求锁事务对应的 GTM GTID(没有则显示 0);
req_sql 请求事务对应当前 SQL 语句;
blk_thd_id 阻塞事务对应的 thread_id;
blk_trx_id 阻塞事务对应的事务 ID;
blk_trx_seq 阻塞事务对应的交易流水号(没有则显示 0);
blk_gtm_gtid 阻塞事务对应的GTM GTID(没有则显示 0);
blk_key_data 阻塞事务锁住记录对应的 KEY 值,可以是主键,也可以是二级索引 blk_sql 阻塞事务对应的 SQL 语句。
协助应用侧分析当前 SQL 产生锁等待的原因
根据锁等待日志定位到具体业务分析锁等待原因,比如持有锁的事务是否是长事务,是否业务测异常导致未提交等。如果某个事务长时间持有锁,并阻塞其他事务,在和业务确认后,可以 kill 持有锁的事务。
方法:连接发生锁等待的主 DN,执行
SELECT trx_id,trx_mysql_thread_id FROM information_schema.innodb_trx WHERE trx_id=<blk_trx_id>; blk_trx_id: 锁等待日志中的事务 id。 trx_mysql_thread_id: SELECT 返回的结果中 trx_mysql_thread_id。数据活跃
数据活跃时,SQL 涉及对活跃数据的操作,其响应会变慢,客户端收到报错:
ERROR 10810 (HY000): The data is in the active state,the active GTID is xxxxxxxxx, please try again later。应急处理操作
查看活跃的 GTID 现在是否已经释放
登录主 GTM 所在节点,执行
dbtool - gtm -sg -cid=$ClusterID查看对应的ProxyID如果查不到此活跃的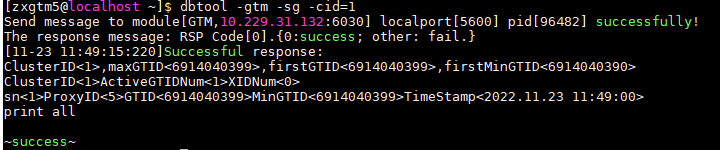
GTID, 说明GTID已经正常释放,无需人工处理,处理结束。 如果仍查到此活跃的GTID, 说明GTID仍未释放,继续下一步骤。查看是否存在已提交事务回滚失败
查看 Insight 页面, 告警管理 中是否存在已提交事务回滚失败告警。
附加信息中写明了已提交事务回滚失败的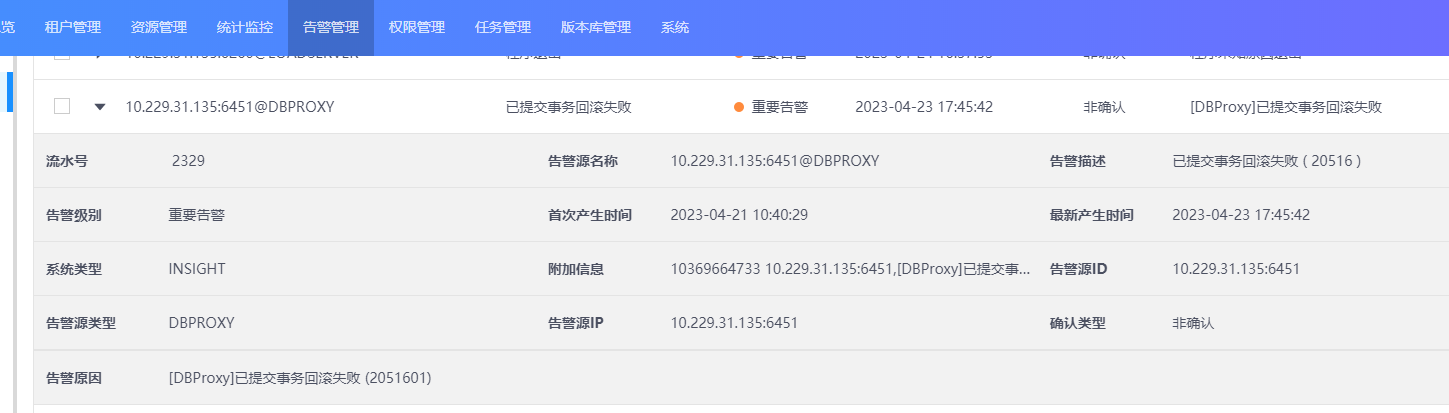
GTID。重试已提交事务回滚
登录管理节点 Manager 所在用户,执行命令
dbtool -p[roxy]m[anager] -rollback clusterid=<clusterid> gtid=<gtid>,重试回滚。其中clusterid为数据库租户 ID(ClusterID),gtid为活跃的GTID。
组件异常
数据库组件异常的不同场景,会导致关联业务直接失败或是短暂的无响应。此种异常场景由数据库高可用机制进行检测与修复,修复后业务恢复正常。组件异常会产生告警,可根据告警消息获知组件异常。如果已经自愈,不用处理。如果没有自愈, 参考数据库节点宕机 处理。- CN 节点宕机 ,其上业务直接失败。CN 节点掉电,业务请求短时间内无响应,业务侧会有 60s 超时检测机制返回报错,新的业务请求会负载均衡到其他正常 CN 业务恢复正常。CN 节点夯住,会有 60s 无响应,监控进程 60s 超时发现 CN 夯住,会杀进程重启。随后业务恢复正常。
- 主 DN 节点宕机 ,CN 直接报业务失败。主 DN 节点掉电、夯住,DBAgent 会检测到主 DN 异常,该分片上的相关业务会在超时后报错。管理节点在 30s 内完成 DN 主备切换,业务恢复正常。
- 主 GTM 节点宕机 ,CN 直接报业务失败。主 GTM 节点掉电、夯住,CN 会去等待 GTM 节点发生主备切换后去新主 GTM 上获取 GTID。管理节点在 15s 内完成 GTM 主备切换,业务恢复正常。
- CN 节点宕机 ,其上业务直接失败。CN 节点掉电,业务请求短时间内无响应,业务侧会有 60s 超时检测机制返回报错,新的业务请求会负载均衡到其他正常 CN 业务恢复正常。CN 节点夯住,会有 60s 无响应,监控进程 60s 超时发现 CN 夯住,会杀进程重启。随后业务恢复正常。
CN 消息积压
Insight 页面出现告警 20515:CN 线程积压,确认发生此问题
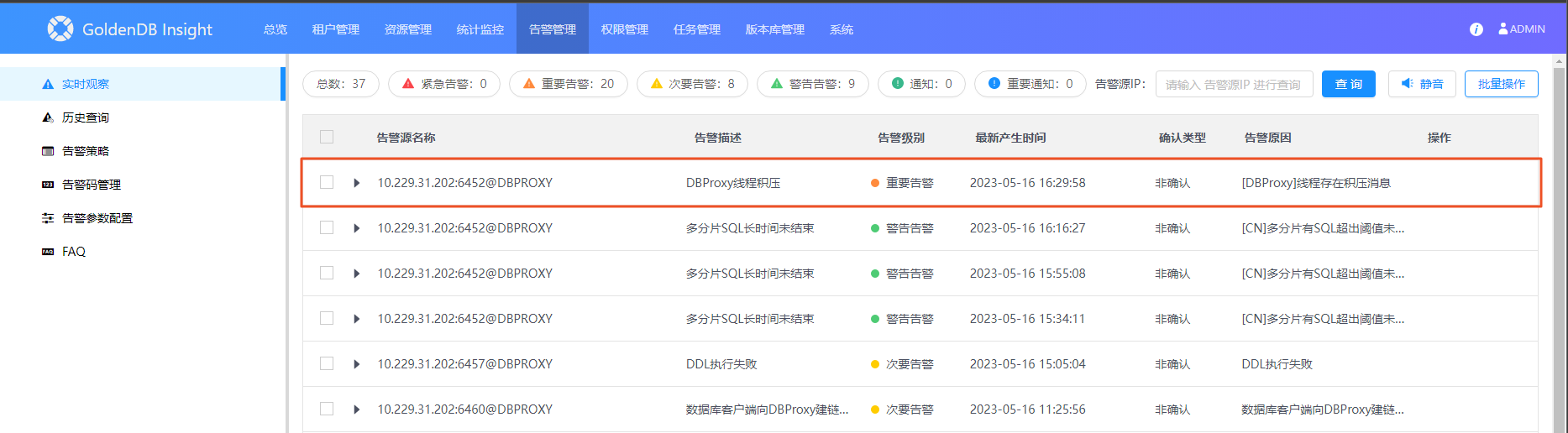
登录该 CN 用户,执行 dbtool 命令,确认出现了线程消息积压
dbtool -p -thdmsg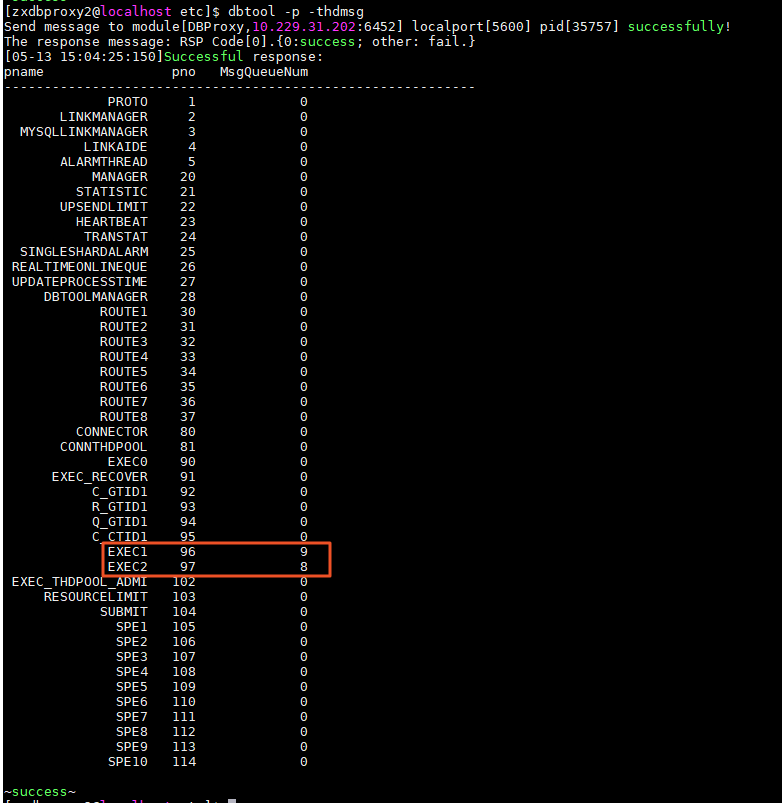
MsgQueueNum列为对应线程上消息积压数。pname列为线程名称,EXEC* 为执行线程名,ROUTE* 列为路由线程名。找出导致积压的 SQL
若某执行线程上消息积压数量过多,到该用户家目录的
log/dbproxy.log中搜索关键字too long,可确定在 CN 上执行时间过长的 SQL。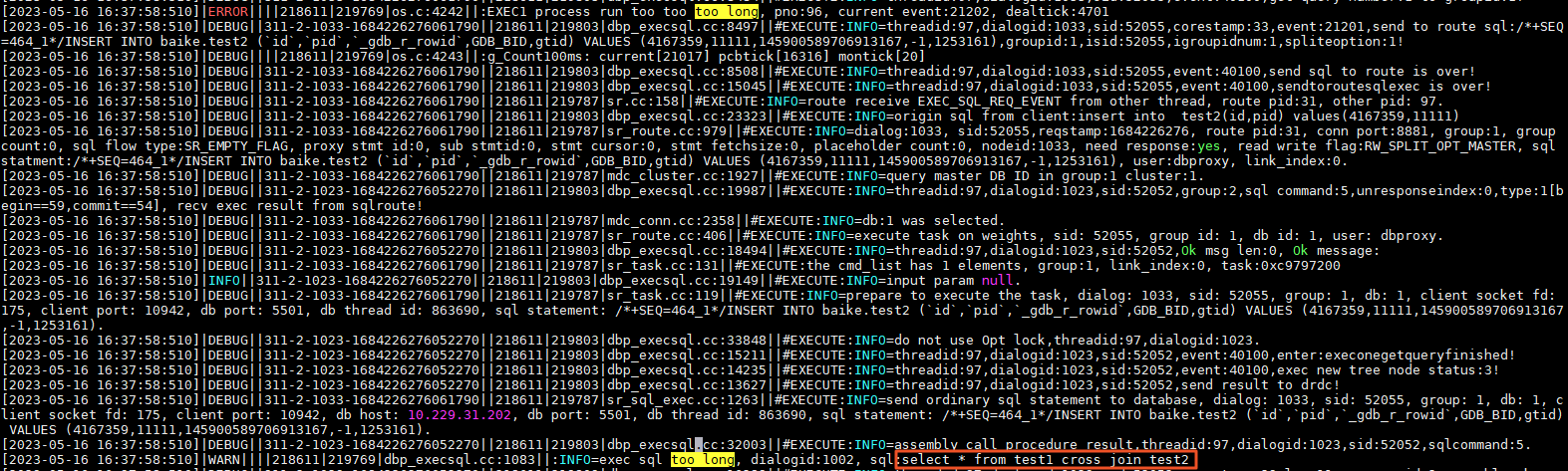
记录该 SQL,提交业务进行优化。
对于当前 SQL,跟业务确认,是否可以杀掉
若 SQL 可以杀掉,执行下面步骤:
通过 Insight 的 实时在线 SQL 分析 功能,设置时延阈值,查询当前正在执行的 SQL 的列表。找到积压 SQL,执行
kill动作。
一键诊断
GoldenDB 提供一键诊断工具,可以对数据库运行过程中各个组件的多个维度监控指标进行检查,如果指标监控值超过阈值,会输出到诊断报告中。查看诊断报告,可以获得组件运行过程中发生的异常事件,为定位问题提供线索。
一键诊断工具部署后自动调起,之后持续运行收集监控信息。手工执行诊断命令,可以针对指定时间段内的历史监控信息进行诊断分析汇总。
诊断工具总控部署在管理节点上,对租户业务的影响较小。
6. 业务监控
业务侧 SQL 响应时间恢复到正常水平,TPS恢复到正常水平。
