





点击蓝字,关注我们
本文介绍了基于 DolphinScheduler 的离线数据治理平台,解决了任务依赖黑洞和扩展性瓶颈问题。通过 YAML 动态编译和血缘自动捕获,实现了高效的任务依赖管理和数据追踪。平台使用 Neo4j 图数据库进行血缘存储,支持秒级影响分析和根因定位。此外,结合自研高性能导入工具,大幅提升数据传输效率。
1
背景与挑战
在日均处理PB级数据的背景下,原有调度系统面临两大核心问题:
任务依赖黑洞:跨系统任务(Hive/TiDB/StarRocks)依赖关系人工维护,故障排查耗时超30分钟 扩展性瓶颈:单点调度器无法支撑千级任务并发,失败重试机制缺失导致数据延迟率超5%
2
技术选型
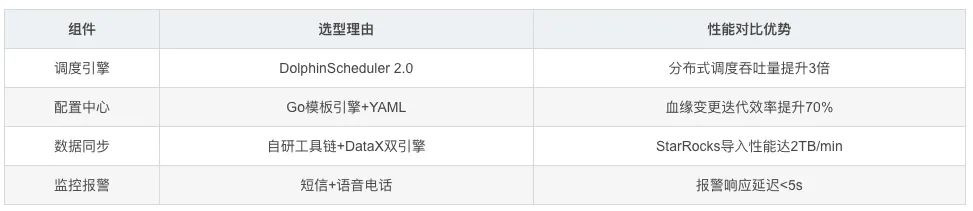
3
核心架构设计
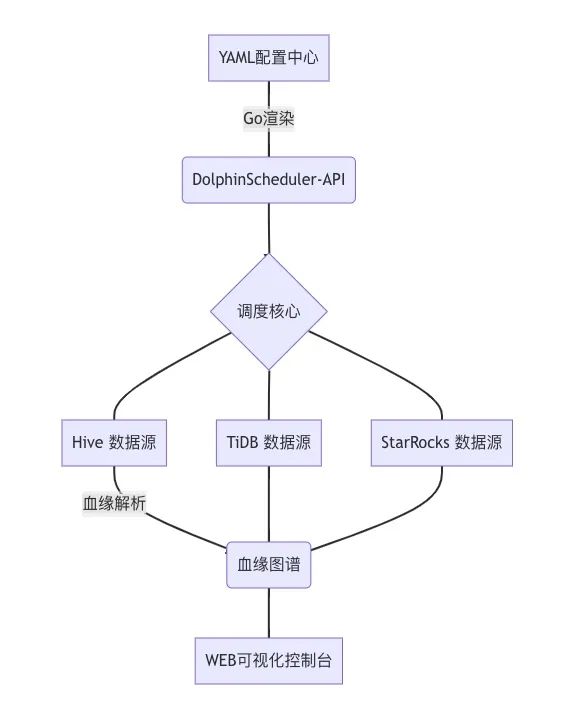
关键技术实现:
YAML动态编译
type TaskDAG struct {Nodes []Node `yaml:"nodes"`Edges []Edge `yaml:"edges"`}func GenerateWorkflow(yamlPath string) (*ds.WorkflowDefine, error) {data := os.ReadFile(yamlPath)var dag TaskDAGyaml.Unmarshal(data, &dag)// 转换为DolphinScheduler DAG结构return buildDSDAG(dag)}
通过拦截SQL执行计划解析输入/输出表 非SQL任务通过Hook捕获文件路径
# StarRocks Broker Load血缘捕获def capture_brokerload(job_id):job = get_job_log(job_id)return {"input": job.params["hdfs_path"],"output": job.db_table}
4
核心难题解决方案
零事故迁移方案
双跑比对:新老系统并行运行,DataDiff工具校验结果一致性 灰度发布:按业务单元分批次切割流量 回滚机制:5分钟内完整回退能力

核心优化点:
基于Go的协程池实现批量提交 动态缓冲区调整策略
func (w *StarrocksWriter) batchCommit() {for {select {case batch := <-w.batchChan:w.doBrokerLoad(batch)// 动态调整batchsizew.adjustBatchSize(len(batch))}}}
5
血缘管理实现
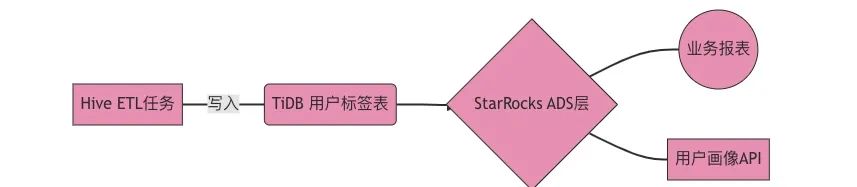
血缘存储采用图数据库Neo4j,实现:
影响分析:表级变更秒级定位影响范围 根因定位:故障时30秒内追踪问题源头 合规审计:满足GDPR数据溯源要求
6
性能收益

原文链接:https://blog.csdn.net/guichenglin/article/details/149216068


用户案例
迁移实战
发版消息
加入社区
关注社区的方式有很多:
GitHub: https://github.com/apache/dolphinscheduler 官网:https://dolphinscheduler.apache.org/en-us 订阅开发者邮件:dev@dolphinscheduler@apache.org X.com:@DolphinSchedule YouTube:https://www.youtube.com/@apachedolphinscheduler Slack:https://join.slack.com/t/asf-dolphinscheduler/shared_invite/zt-1cmrxsio1-nJHxRJa44jfkrNL_Nsy9Qg
同样地,参与Apache DolphinScheduler 有非常多的参与贡献的方式,主要分为代码方式和非代码方式两种。
📂非代码方式包括:
完善文档、翻译文档;翻译技术性、实践性文章;投稿实践性、原理性文章;成为布道师;社区管理、答疑;会议分享;测试反馈;用户反馈等。
👩💻代码方式包括:
查找Bug;编写修复代码;开发新功能;提交代码贡献;参与代码审查等。

你的好友秀秀子拍了拍你
并请你帮她点一下“分享”
文章转载自海豚调度,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
