




背景
生产环境是OceanBase 3-3-3的主备集群,一共18个节点,其中备机群一个X86节点在7.24版本期间observer无法连接,操作系统负载过高,收到告警信息如下:
集群:obxxxx,主机:192.168.66.11,告警:服务器CPU平均load1超限。CPU平均load1值 5.519 超过 2。
集群:obxxxx,主机:192.168.66.11,告警:OceanBase服务器无法连接。
集群:obxxxx,告警:OceanBase集群存在不工作 OBServer。不工作 OBServer 数量为 1,不工作 OBServer 有 192.168.66.11。
故障排查
首先确认告警信息,观察OCP告警和该节点observer状态确实显示不可用,接着排查observer日志
在告警时间段数据库日志,报错 errcode=-4388 Unexpected internal error happen
**please checkout the internal errcode(errcode=0, file="**ob_freeze_info_snapshot_mgr.cpp", line_no=1121, info=“snapshot_gc_ts not refresh too long”)
遇到未知的内部错误发生,官方文档解释是请联系技术支持人员协助排查。
[admin@panda-1 ~/oceanbase/log]$ grep -iE 'WARN|ERROR' observer.log.wf.20250725002035693
[2025-07-25 00:15:01.368501] ERROR issue_dba_error (ob_log.cpp:2322) [3396930][0][Y0-0000000000000000-0-0] [lt=9] [dc=0][errcode=-4388] Unexpected internal error happen, please checkout the internal errcode(errcode=0, file="ob_freeze_info_snapshot_mgr.cpp", line_no=1121, info="snapshot_gc_ts not refresh too long")
[2025-07-25 00:16:01.678594] ERROR issue_dba_error (ob_log.cpp:2322) [3396930][0][Y0-0000000000000000-0-0] [lt=12] [dc=0][errcode=-4388] Unexpected internal error happen, please checkout the internal errcode(errcode=0, file="ob_freeze_info_snapshot_mgr.cpp", line_no=1121, info="snapshot_gc_ts not refresh too long")
[2025-07-25 00:17:01.982843] ERROR issue_dba_error (ob_log.cpp:2322) [3396930][0][Y0-0000000000000000-0-0] [lt=9] [dc=0][errcode=-4388] Unexpected internal error happen, please checkout the internal errcode(errcode=0, file="ob_freeze_info_snapshot_mgr.cpp", line_no=1121, info="snapshot_gc_ts not refresh too long")
[2025-07-25 00:18:02.274850] ERROR issue_dba_error (ob_log.cpp:2322) [3396930][0][Y0-0000000000000000-0-0] [lt=9] [dc=0][errcode=-4388] Unexpected internal error happen, please checkout the internal errcode(errcode=0, file="ob_freeze_info_snapshot_mgr.cpp", line_no=1121, info="snapshot_gc_ts not refresh too long")
[2025-07-25 00:19:02.583788] ERROR issue_dba_error (ob_log.cpp:2322) [3396930][0][Y0-0000000000000000-0-0] [lt=9] [dc=0][errcode=-4388] Unexpected internal error happen, please checkout the internal errcode(errcode=0, file="ob_freeze_info_snapshot_mgr.cpp", line_no=1121, info="snapshot_gc_ts not refresh too long")
[2025-07-25 00:20:02.905195] ERROR issue_dba_error (ob_log.cpp:2322) [3396930][0][Y0-0000000000000000-0-0] [lt=10] [dc=0][errcode=-4388] Unexpected internal error happen, please checkout the internal errcode(errcode=0, file="ob_freeze_info_snapshot_mgr.cpp", line_no=1121, info="snapshot_gc_ts not refresh too long")
[admin@panda-1 ~/oceanbase/log]$ grep -iE 'WARN|ERROR' rootservice.log
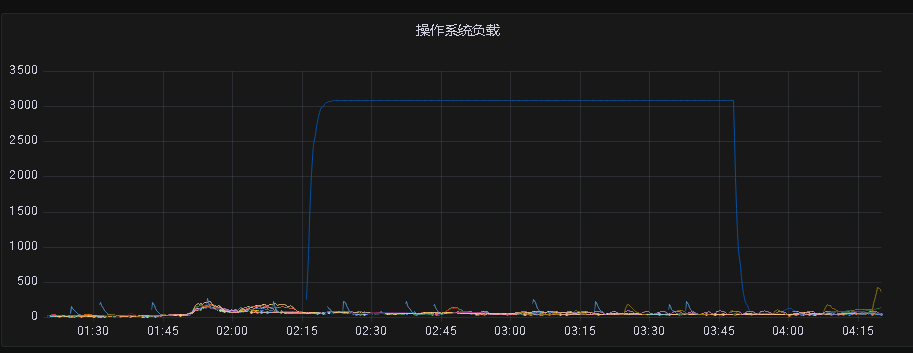
**继续排查,**观察OCP各项指标平稳,CPU正常但是服务器负载很高
操作系统负载3000,CPU空闲却有99%,说明CPU并不忙,可能大量进程在阻塞或者等待IO
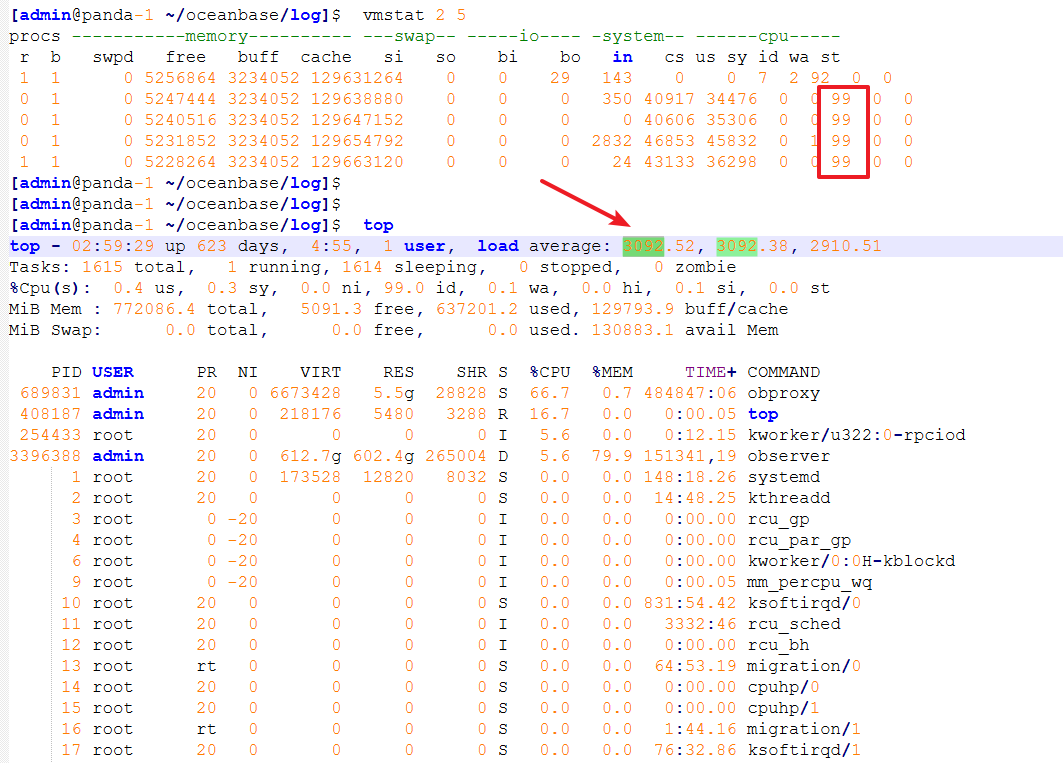
观察有一个进程卡在内核态D(不可中断睡眠状态)
[admin@panda-1 ~/oceanbase/log]$ ps -eo state,pid,cmd | grep "^D" | wc -l
1
[admin@panda-1 ~/oceanbase/log]$ ps -eo state,pid,cmd | grep "^D" | head -20
D 3396388 /home/admin/oceanbase/bin/observer
observer大量线程卡在不可中断的 D 状态,猜测可能是在等待 I/O 或 资源阻塞

原因分析:内存硬件故障
排查系统日志,最后确定是内存故障导致,内存故障可能导致observer获取不到特定资源,处于D状态。
该状态是指进程处于睡眠状态且进程是不可中断的。而且这时候的不可睡眠状态是不会立即响应异步信号的的,也就是说kill -9可能杀不死该进程。
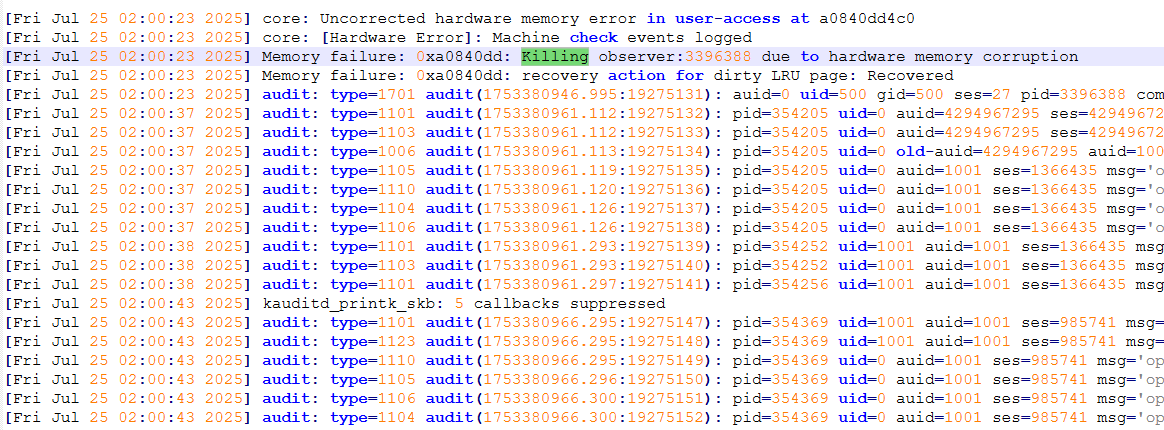
[admin@panda-1 ~]$ dmesg -T|grep -iE error
[Fri Jul 25 02:00:23 2025] core: Uncorrected hardware memory error in user-access at a0840dd4c0
[Fri Jul 25 02:00:23 2025] core: [Hardware Error]: Machine check events logged
[admin@panda-1 ~]$ dmesg -T|grep -i memory
[Fri Jul 25 02:00:23 2025] core: Uncorrected hardware memory error in user-access at a0840dd4c0
[Fri Jul 25 02:00:23 2025] Memory failure: 0xa0840dd: Killing observer:3396388 due to hardware memory corruption
[Fri Jul 25 02:00:23 2025] Memory failure: 0xa0840dd: recovery action for dirty LRU page: Recovered
因为该节点不止一个部门的业务确定在下个版本维修,迁移数据源
恢复措施与建议
主要是硬件内存故障导致OBSERVER不可用,主要现象是CPU使用率很低,操作系统平均负载很高,并由此判断出可能是IO阻塞、操作系统资源争用等,排查发现操作系统进程作业超限,大量处于不可中断的休眠状态,再由demsg诊断是否是CPU、内存、磁盘等硬件故障。当晚持续1h没有下去的迹象,因为是在版本期间并且是备库节点,直接kill了observer进程,再在OCP重启observer和OBproxy后恢复。但不建议这么操作。
kill进程,OCP重启
[admin@panda-1 ~]$ ps -ef | grep observer
admin 469260 464771 0 03:47 pts/0 00:00:00 grep --color=auto observer
admin 3396388 1 99 2023 ? 6305-21:20:04 /home/admin/oceanbase/bin/observer
[admin@panda-1 ~]$
[admin@panda-1 ~]$
[admin@panda-1 ~]$ kill -9 3396388
[admin@panda-1 ~]$ ps -ef | grep observer
admin 469683 464771 0 03:48 pts/0 00:00:00 grep --color=auto observer
admin 3396388 1 99 2023 ? 6305-21:35:17 [observer] <defunct>
[admin@panda-1 ~]$ ps -ef | grep observer
admin 471156 464771 0 03:49 pts/0 00:00:00 grep --color=auto observer
建议恢复过程可由OCP白屏操作重启:进入OCP集群 -->概览 -->下滑找到集群机器 -->重启(ocp重启obserevr,停止进程前执行转储操作,可加快恢复速度)
后续**observer节点维修**也可通过OCP白屏操作更加安全:停止服务前转储 --> 停止observer服务 --> 设置下线时间 --> 停止observer进程 --> 维修结束,启动进程 --> 启动服务
相关节点维修需要注意机器的是否存在业务,下线时间,如果 OBServer 停机时间超过server_permanent_offline_time下线时间触发了永久下线,则需要执行副本 rebuild 操作,需要的时间可能很久。
-- 转储 root用户sys租户
alter system minor freeze;
-- 查询结果为”0”表示转储结束
select count(*) from __all_virtual_memstore_info where is_active=0;
-- 查看业务IP
SELECT substr(host,1,13) proxy_ip, count(*) process_cnt
FROM oceanbase.__all_virtual_processlist
group by substr(host,1,13) order by process_cnt desc;
-- WHERE tenant = 'sys' OR tenant = 'oceanbase';
重启主机或observer后需要判断是否需要重启OBPROXY、操作系统的绑核工作。
