




如果说监督微调(SFT)是教大模型“背答案”,那么强化学习(RL)则是教它们“学方法”,在一次次试错与反思中自我进化。
2025年第三季度,RL在LLM领域迎来了新一轮突破性进展。研究重点已从简单应用转向了对RL本质的深度思考:这项技术是在开发新能力,还是在优化现有知识的提取效率?熵调控机制如何影响模型的学习极限?我们是否能够借助少量数据甚至无监督学习,推动模型实现自我迭代升级?
这篇盘点将带您潜入 Hugging Face 上 Q2 热度最高的RL论文:《Reflect, Retry, Reward: Self-Improving LLMs via Reinforcement Learning》,一窥当前最前沿的思想碰撞。让我们一起看看,强化学习究竟如何为大模型注入灵魂,重塑其能力的未来。
论文较长,分为上下两篇,本篇为上篇:

摘要:
我们探索了一种通过自我反思和强化学习来提高大型语言模型性能的方法。通过激励模型在回答错误时产生更好的自我反思,我们证明了即使在生成合成数据不可行并且只有二进制反馈可用时,模型解决复杂、可验证任务的能力也可以得到增强。我们的框架分两个阶段运作:
首先,在给定任务失败后,模型生成一个自我反思的评论,分析其先前的尝试;
第二,该模型被赋予在情境中自我反思的任务的另一种尝试。如果随后的尝试成功,则奖励在自我反思阶段生成的令牌。
我们的实验结果显示,在各种模型体系结构中,性能都有显著提高,数学等式书写提高了34.7%,函数调用提高了18.1%。
值得注意的是,较小的微调模型(15亿到70亿个参数)的性能优于10倍大的同类模型。
因此,我们的新范式是通向更有用和更可靠的语言模型的令人兴奋的途径,这些语言模型可以在有限的外部反馈下自我改进具有挑战性的任务。
1
介绍
大型语言模型(LLM)在广泛的自然语言处理任务中表现出令人印象深刻的能力,数学也是如此,编码和推理。然而,尽管有这些进步,模型仍然有盲点,并且不能保证在一个任务中成功的模型在另一个任务中也会成功,即使任务是相似的类型。解决这个问题的最直接的方法是对代表失败任务的数据重新训练或微调模型,但是如果不存在这样的数据集,这可能是不可能的。此外,如果最大的最先进的模型也难以完成任务,我们同样不能使用它们来生成合成的训练数据。
另一种解决方案是提示模型解释其推理或自我反思失败的原因。例如,流行的思维链(CoT)范式研究表明,如果除了简单地给出一个答案之外,还提示模型展示他们的推理,那么模型在算术、常识和推理任务中的表现明显更好。自我反思的工作原理与此类似,如果我们能够检测到LLM何时提供了不正确的响应,我们就可以促使它反思其推理中的任何缺陷,并可能再次尝试。这些方法的主要优点是它们不需要任何额外的训练数据,然而它们的有效性直接依赖于推理/思考提示的有效性。
在本文中,我们调查了LLM可以在多大程度上学会产生更好的自我反思,以便在下游任务中自我改进。更具体地说,如果一个模型在第一次尝试中未能完成任务,它会生成一个自我反射,用于进行第二次尝试。如果模型第二次尝试成功,我们使用强化学习(RL),特别是群组相关策略优化(GRPO),奖励自我反省中的代币,以便将来的自我反省将更有效。通过这种方式,模型可以学习如何改进所有类型的任务,而不需要任何特定于任务的数据;相反,他们只是优化如何反思错误。
因此,我们的主要贡献是一种新的方法来训练一个模型,以产生更好的自我反思,从而以任务不可知的方式改进具有挑战性的任务。重要的是,这种方法只需要来自响应验证器的二进制成功/失败信号,这使得它非常适合于可以容易地验证成功的任务。为了证明我们方法的有效性,我们在APIGen函数调用数据集上进行了实验和倒计时方程式任务。
2
相关著作
2.1自我反省
LLMs中的自反射自反射,也称为内省,是一种元提示策略,其中语言模型分析自己的推理,以便识别和纠正潜在的错误。这种范式在大型语言模型(LLM)研究中获得了动力,作为一种提高多步推理和问题解决性能的手段,特别是在算术、常识推理和问题回答等领域。通常,自我反思包括生成一个初始答案,产生自然语言反馈以评论该答案,然后基于该评论完善响应。这个过程可以迭代地应用,通常使用相同的模型来生成和评估解决方案,并且可能包括诸如内存缓冲区或显式元指令指南之类的模块。
方法和限制LLM中的自我反思方法沿着几个轴变化。一些方法仅对失败的或低置信度的查询应用自校正,而其他方法对每个响应使用自校正;反馈可以以标量分数、外部注释或自然语言的形式提供,并且可以由人类、外部模型或LLM本身生成。虽然在许多情况下,促使LLM进行自我反思确实提高了准确性,但最近的工作表明,有效性在很大程度上取决于环境:挑战包括无法在没有真实预言的情况下可靠地识别自我错误,重复反思的回报递减,以及更容易的提示或高性能基础模型的性能恶化风险。特别是在初始准确率低、问题难度高、有外部验证的情况下,自我反思最有效。相反,学习管理人员有时可能没有意识到他们自己的错误,但当这种监督存在时,他们仍然可以从外部反馈中受益。
基于训练的方法最近的方向集中于在模型训练期间结合自我改进能力,或者通过对自我校正轨迹进行微调,或者通过将该过程公式化为多轮强化学习问题。这些基于训练的方法表明,在学习过程中利用模型自己的评论会产生持续的改进——即使没有进行测试时的自我反思。然而,这些方法通常依赖于用于数据生成或监督的更大的教师模型,这可以被视为知识升华的一种形式。
我们的方法基于先前研究的见解,我们建议只纠正由外部验证者识别的失败案例,将其二进制反馈转换为自我反思提示,并训练模型使用自我反思在第二次尝试中成功。这种基于oracle的条件计算利用训练时间的优势来减少测试时间开销,并保证提高或保持性能,因为纠正只适用于最初不正确的示例。对于培训,我们采用组相关策略优化(GRPO),将在下一节介绍。值得注意的是,这种方法仅仅从模型自身的输出中引导,而不依赖于外部的LLM。
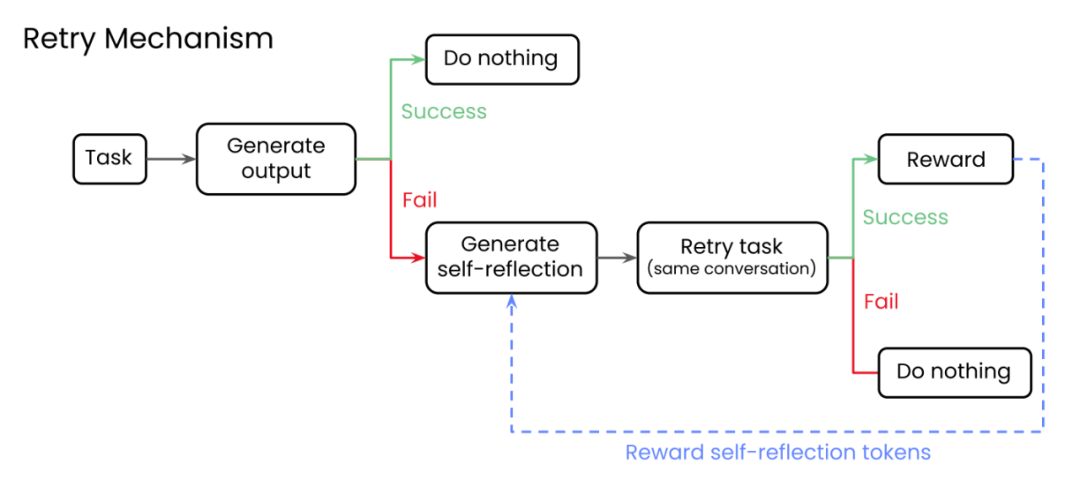
(表 1:反映、重试、奖励机制首先根据用户查询提示模型完成任务。如果初始响应是正确的,则该过程停止。如果没有,模型被提示产生如何改进的自我反思。然后,该模型重试相同的任务,这一次包括其自我反思,并评估新的答案。如果第二次尝试成功了,模型就知道它产生了有效的自我反思。)
2.2语言模型的强化学习
GRPO集团相对策略优化(GRPO)是一种基于结果的强化学习方法,旨在解决微调线性逻辑模型时面临的独特挑战,例如在复杂的数学推理任务中遇到的挑战。不同于传统的方法,如近似策略优化(PPO),GRPO省去了单独的价值(评价)网络,而是通过比较一组取样完井的结果来直接评估优势。这使得GRPO特别适合监管稀疏且仅在一代人结束时可用的环境——例如,一个完整的数学解决方案是否正确。在这种环境中,模型必须在接收任何反馈之前生成整个序列,通常以反映输出质量或正确性的标量奖励的形式。
我们的方法在这项工作中,我们采用GRPO作为强化学习的唯一机制,不涉及额外的监督微调阶段。最近的研究表明,修改GRPO的奖励结构可以有效地鼓励模型在失败后继续存在,例如通过奖励失败后的重试,从而促进自我纠正和稳健性。GRPO在需要复杂、结果监督行为的相关领域进一步展现了潜力,包括工具使用和高级数学问题解决,为各种LLM应用提供了灵活高效的优化策略。
3
反思、重试、奖励
我们新颖的反思、重试、奖励方法操作如下,如所示Figure 1.
首先,模型被提示完成一项任务。如果它成功了,我们什么也不做,因为模型已经满足了我们的需求。然而,如果它失败了,我们会促使它对可能出错的地方进行自我反思。请注意,这需要一个验证器来自动评估响应是成功还是失败(二进制)。虽然有时可以定义一个任务相关的验证器来满足这个标准,而不需要实际标签,比如在基本的API函数调用中(API调用是否返回了有效的响应?)、数学方程(方程是否评估到目标答案?),或者代码(生成的代码执行吗?),某些任务类型可能需要黄金标准的目标答案。
生成自我反映后,该模型将利用对话历史中的自我反映,再次尝试完成任务。如果还是失败,我们什么都不做;自我反省不足以把失败变成成功。然而,如果它成功了,我们就用GRPO来奖励那些在自我反省中产生的记号。这可以通过将所有其他生成的令牌的优势项设置为零来实现。我们这样做是因为我们希望模型学习如何更普遍地进行自我反思,而不是针对特定的任务进行专门化。换句话说,我们不奖励正确的答案,我们只奖励自我反省。
内容来源:
https://huggingface.co/papers/2505.24726
(机翻)
未完待续.......
