






非结构化和向量数据处理困难:针对非结构化数据,采取数据和元数据分离存储方式,存在数据一致性问题,使用时需要先读路径,再读原始文件,带来二次I/O开销;针对向量,无法直接进行高效的向量近似性检索,依赖外部向量库。 数据读写存在I/O瓶颈:在ML场景下,需要快速小批量的随机访问,传统数据湖仓擅长全量扫描/大批量顺序读,适合JOIN等聚合操作,在ML场景下带来严重的读I/O放大和延迟。 异构资源调度低效:AI开发工作流中的任务,通常同时使用CPU和GPU资源,传统数据湖仓无法协调全链路中异构资源的调度,导致资源利用率低。 Python生态割裂:传统数据湖仓以SQL/Dataframe API为主,非原生Python支持。比如DataFrame传递给PyTorch DataLoader时,数据需跨越JVM和Python两个技术生态,带来额外的序列化/反序列化开销。 多模态数据管理复杂:结构化数据、图片等非结构化数据以及向量数据,分散存储,管理复杂,难以关联访问。
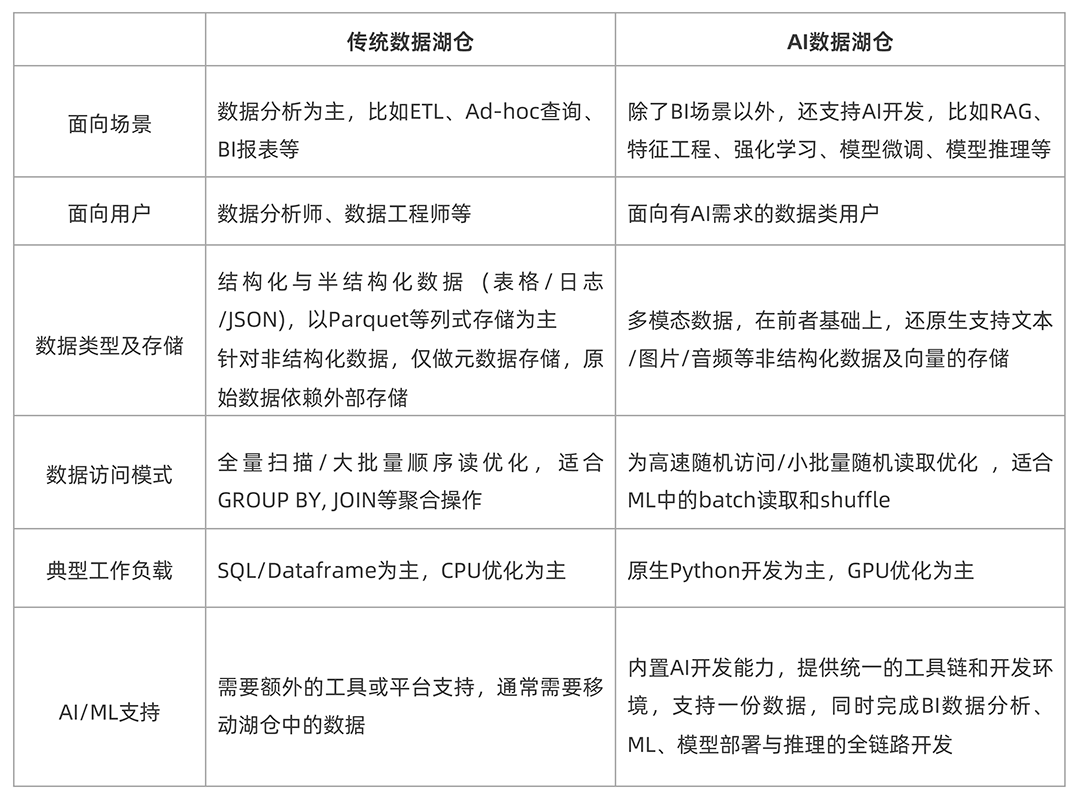
ADB Ray + Lance:构建从数据到模型的AI流水线
ADB存储层通过引入AI原生的Lance数据格式,并结合上层托管的ADB Ray和ADB Spark计算引擎,将多模数据ETL与ML一体化,更高效地构建和优化AI流水线。
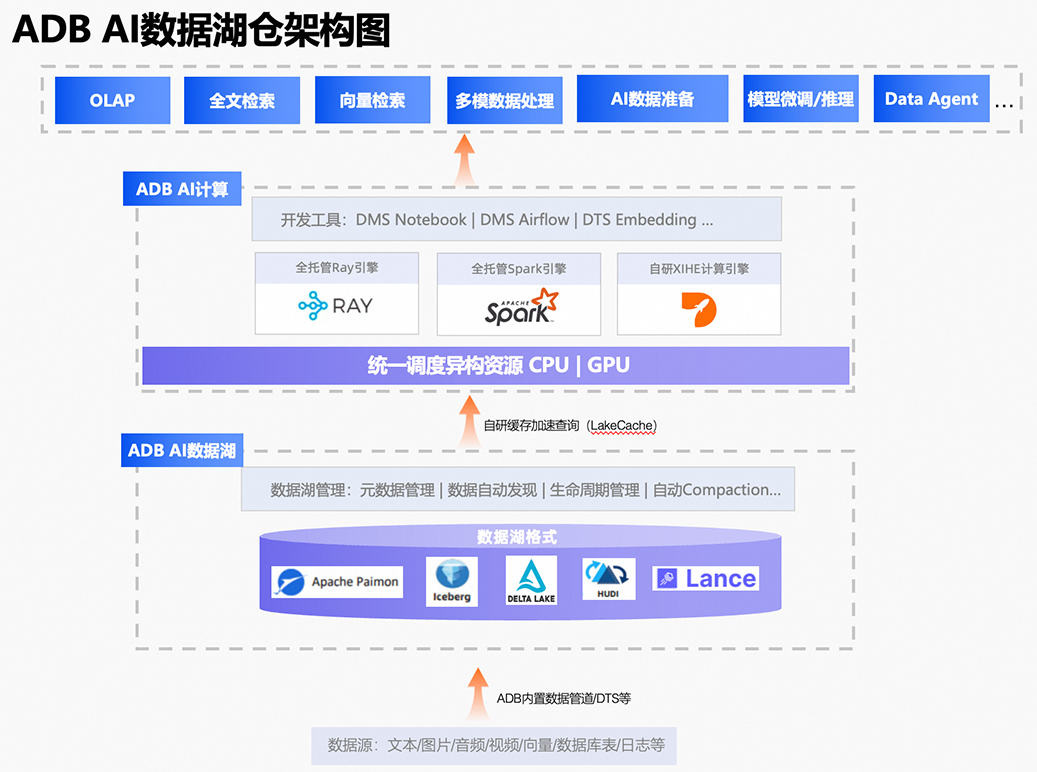
Data+AI Zero ETL:ADB湖存储通过APS(ADB Pipeline Service,ADB内置管道服务),自动感知增量数据文件,比如针对新增视频文件可自动完成截帧,并调用百炼或外部服务完成截帧图片的描述生成和图文向量构建。用户也可自定义算子开发;同时内置数据格式转换服务,可将已有图片/文本/音视频等多模数据一键转为Lance格式等,无需手动编写复杂的ETL逻辑,快速构建AI数据处理管道。 ADB Ray/Spark+Lance深度融合:借助Lance数据格式,打破以Python为核心的AI开发(Ray)与以SQL为核心的数据工程(Spark)之间的壁垒,数据工程师可以用Spark进行大规模的ETL和特征工程,将AI就绪的数据写入Lance;AI科学家可以用Ray,通过零拷贝的方式直接在同一份数据上进行后续的ML和向量检索等。 未来可期,迈向零运维多模数据湖:延续前面所讲的数据湖底座能力,ADB也正在构建基于Lance的文件入湖、元数据服务和自动化Compation等,让多模数据易发现、易管理和易使用。
实践应用介绍
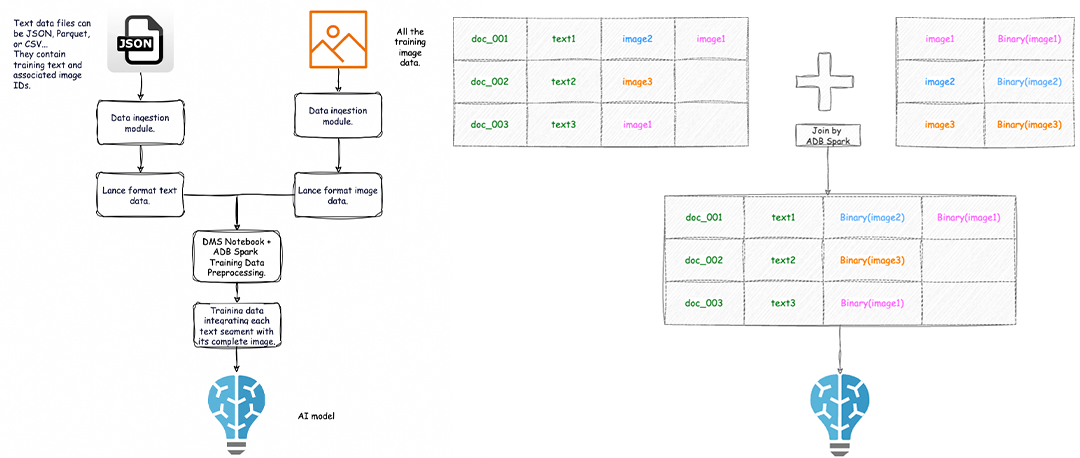
解决了传统图文分离存储方案中的数据完整性和一致性问题,图片与元数据存储在同一文件中,方便管理。 高效读取。传统方案是在表中存储图片url,访问数据时需额外的IO去读取图片数据。Lance的多模存储可以一次性把元数据和图片同时读取出来,减少IO操作和路径查找时间,尤其适合批量处理大量图片+数据的场景(如机器学习数据集)。在客户场景测试中,与采用Parquet对比,处理性能提升2-4倍。
▶︎ 图片打标及微调
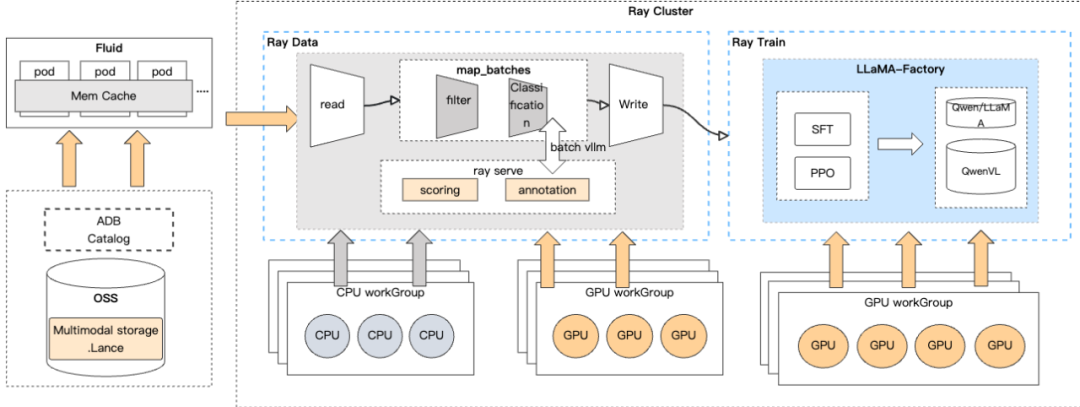
利用Lance零成本schema演进特性,实现高效加列,无需重写数据文件,新增小文件即可;在客户场景测试中,与采用Parquet对比,性能提升3倍+。 通过ADB Ray工具链,一站式完成数据处理、打标和微调。

相比传统调度的异构资源使用和开销,ADB Ray不同阶段CPU和GPU任务可以并行执行,执行时间无等待,资源空闲小,最大化处理吞吐。结合基于画像的CPU和GPU异构资源精细化调度,可将GPU利用率提升至90%+。 任务调度吞吐可达400+ task/s , 随着资源增加,吞吐线性增长。
了解更多
📃 了解更多产品信息,欢迎点击文末「阅读原文」查看详情
💬 欢迎钉钉搜索群号 23128105 or 扫码加入钉群进行交流



点击阅读原文了解 AnalyticDB Ray 详情

文章转载自阿里云瑶池数据库,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
