





数字化浪潮席卷之下,传统的关系型数据库在面对海量复杂数据时,开始显得力不从心——它们擅长处理规整的表格,却在描绘实体间千丝万缕的联系时频频“卡顿”。
图数据库,用“图”点边数据结构来建模。能够在犯罪网络溯源、铁路运输调度、金融风控、供应链管理等众多场景中,凭借高效的图算法挖掘隐藏在数据背后的深层价值,将数据快速串联起来,让复杂关系一目了然。
如何充分发挥图数据库的潜力呢?合理的“图建模”至关重要。 良好的图模型不仅能够提高数据的可读性和可维护性,还能极大地优化查询性能,从而为业务决策、预测分析提供强有力的支持。
本文将以公安业务场景为例,利用蜀天梦图完全自主研发的分布式原生图数据库管理系统——GDMBASE,通过对比关系型数据库的建模方式,为大家介绍图数据库的建模思路。
大型商超中,货架上物品不是随意摆放的,而是按物品的用途来进行归类整理。对于海量异构的数据,我们也需要对其进行抽象与归类,设计数据结构,这就是数据建模。
关系型数据库最常用的数据建模方法是E-R图(实体-关系模型),其本质上是一种图的方法。建模设计步骤大致如下:
1.确定实体与关系
2.设计主键与外键
3.使用规范化规则(即一、二、三范式)
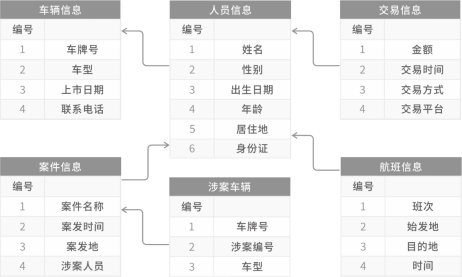
公安案件通常会涉及到人、地、事、物等相关信息,将案件、人、车辆、交易、航班抽象为五类实体。每个实体都有其相关的附加属性,比如人的姓名、性别、年龄等。实体间各有关系,例如人“拥有”车辆,车辆“涉及”案件。
数据建模的过程并非一帆风顺。规范化的模型,在面向业务和用户时,也会因冗余等各种问题来反规范化。从数据中心的架构图,到E-R图,再到规范化和反规范化的数据库建模,为了适应关系模型,在搭建模型的初始阶段便要做出诸多尝试与改变。这些改变使得概念模型和数据的真实存储之间产生了无法逾越的鸿沟,导致系统的演化远远落后于业务的发展。
区别于关系型数据库通过表、行和列来表示数据,图数据库建模通过节点、边和属性来表示数据间的关系,其核心在于“关系”二字。
节点代表实体,边代表关系,属性代表实体或关系的附加信息。此外,要用到标签来对节点分类,相当于关系型数据库中的表。通常,同一类型的顶点/边遵循统一的属性模型约束,并冠以统一的标签进行划分,若干点/边标签组合,构成一个完整的图模型。
1.理解业务
明确业务需求,结合图数据库的特性将业务需求转化为图模型。
围绕公安业务中人员信息的多维度、全方位管理与分析应用,通过信息整合,将分散在不同公安业务系统中的人员、社会关系、行为轨迹数据进行集中汇聚。例如,通过数据挖掘和数据分析手段,发现犯罪嫌疑人与其他人员之间存在密切的经济往来或频繁的通讯联系,进而判断他们可能存在的协同犯罪关系或其他关联。
2.识别实体和关系
识别实体和关系建模环节中最重要的部分,是将业务模型转换为数学模型的关键。具体设计内容包括:
1、应该建立哪些类型的节点。
2、顶点之间需要建立何种类型的边。
3、同一业务场景下,可以根据需求将个别关系灵活设计为节点或边。
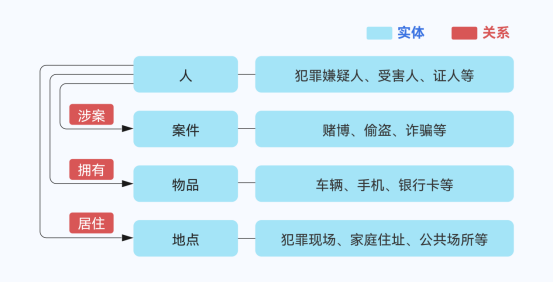
图 | 公安案件常见的实体与关系
3.定义节点、边属性
一般来说,需要用来进行检索和可视化展示的,都需要作为属性。每个节点和边都可以有多个属性进行具体描述。
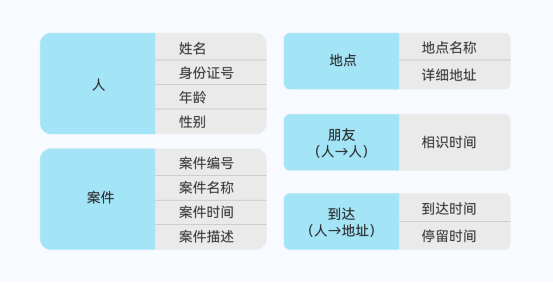
图 | 公安案件常见的属性
4.图模型建立
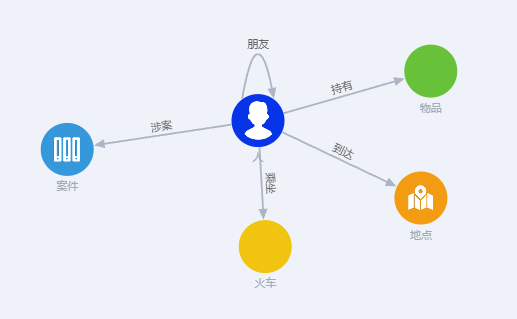
公安案件人员关系间的图模型
通常围绕人员信息的多维度关系开展建模。
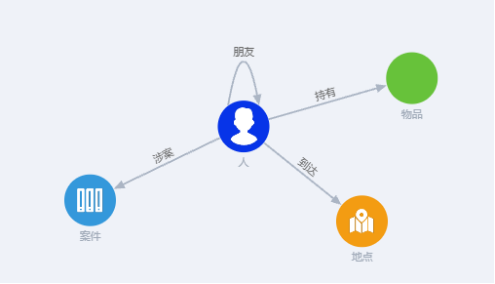
通过分析人员与案件、地点、物品之间的关系,挖掘潜在的情报线索,如发现频繁出现在特定地点且与特定物品相关的人员,可能存在可疑行为。
图模型调整
因业务的变化对数据模型的调整也是可能发生的。例如上述图模型中还需要对人的火车出行情况进行分析,在图数据库可直接复用上述模型并新增火车顶点与乘坐关系。
前面提到关系型数据库最常用的数据建模方法是E-R图,其最终落地都是一张张独立的表,表与表之间的关联关系并不直接,需要通过主外键才能够关联起来,既不直观也缺少灵活性,还牺牲了查询的性能和深度分析的能力。反观图数据库,在设计上、使用上都高度重视关系,关系直接传输到数据库里面,建模时,更加符合E-R模型。
1.点、边的确定
节点通常代表可以在没有其它实体的情况下独立存在的实体或对象。例如,人、地点、物品、组织等。边表示两个节点之间的关联或互动,并且可能携带额外的信息(权重、时间戳等),例如,友谊、所有权、访问、交易等。
2.边的方向
边的方向有单向和双向之分。例如在社交网络中,如果用户A、B之间互相关注,则是“双向边”性质的节点关系,那么方向可以是A指向B,也可以是B指向A。在图数据库GDMBASE中,只要两个节点存在关系即可进行节点间的探索,边的方向不会引发数据查询的问题,若存储方向不同的两条边会造成一定的数据冗余,同时增加数据的存储。
3.属性与节点的区分
定义顶点和属性的过程是一个平衡艺术和技术的任务。需要结合业务逻辑、查询模式和技术实现的考量,做出最有利于应用需求的选择。可以从理解数据表的业务含义入手,多数情况下符合我们业务理解的建模方式,是把整张表设为顶点,然后把里面的字段设为属性。属性通常依附于节点,无法独立存在。
4.超级节点问题的规避
超级节点问题是指某些顶点拥有异常大量的边,这可能导致查询性能下降、内存消耗过大以及系统复杂度增加。超级节点的存在对图数据库的效率和可扩展性构成了挑战,因为它们会导致数据倾斜,使得与这些节点相关的操作变得非常耗时。
我们可以考虑通过如下方式解决超级顶点问题:
引入中间节点
将超级节点分解为多个较小的顶点,通过增加一些中间节点和边来重新构建图结构,分散超级节点的连接关系。例如人与酒店的入住关系,若按月进行统计,则酒店节点很容易形成超级顶点,这种情况下可以将酒店按日期分出酒店分点,由酒店分点再指向酒店总点。
分解超级节点
对同一标签下的点按某种方式进行分类,将单一标签的点转化为多类型标签的点,也可以达到引入中间顶点来分散超级节点连接关系的效果。例如以药品查询为例,所有的医疗用药都可以归类为药品标签下,通过将药品按治疗领域分类为心血管系统用药、神经系统用药、内分泌系统用药等标签类型,完成对药品标签分解的动作。
边多标签化
与分解超级节点类似,通过对同一标签下的边按某种方式进行归类,细分为多个特定类型的边,这样可以减少每种类型边的数量,从而缓解超级顶点的压力。例如在银行转账流水业务场景中,如果将所有的转账关系都归类到转账标签下,该标签数据会十分巨大,若按转账金额对转账标签进行分类,如一万以下为小额转账、一万到十万为较大额度转账、十万以上为大额转账。
存储优化
在物理资源充沛的情况下,可以考虑使用分布式图数据库增加存储节点,将超级节点的数据分散存储在多个节点上。使得超级节点的相关数据分布在不同的物理节点上,从而避免单个节点存储过多与超级节点相关的数据,提高存储的可扩展性和读写性能。
图建模能够直观地展示复杂的数据关联,相较于传统的关系型数据库,更适合处理需要频繁查询和分析海量关系的数据场景。在实际应用中,需要结合业务需求和技术方案综合考量,创建出既高效又易于维护的图模型,才能充分发挥图数据库在发掘数据关系潜在价值的强大优势。
蜀天梦图数据库管理系统GDMBASE采用领先的分布式原生图数据库设计理念,提供高性能、高可用、高扩展性,支持海量图数据存储和计算的需求,提供标准的图查询语言,提供丰富的图计算能力,拥有多种工具组件、可视化运维管理平台。多年来,在金融、交通、公检法等多个领域累积了丰富的经验。蜀天梦图愿携GDMBASE赋能各行各业智能化升级,助力用户洞察复杂数据关系,驱动高效决策。
撰文 | 武
校对 | 莉 佳

