





本文字数:12937;估计阅读时间:33 分钟
作者:ClickHouse Team

Meetup活动
ClickHouse 北京第三届 Meetup 讲师招募中,欢迎讲师在文末扫码报名!

又到了每月版本发布的时间!
发布概要
本次ClickHouse 25.6 发布包含 27 项新功能 🌸 26 项性能优化 🍦 以及 98 个缺陷修复 🐞。
本次更新中,我们要特别欢迎所有参与 25.7 版本开发的新贡献者!ClickHouse 社区的不断壮大令人深受感动,我们始终感谢每一位推动 ClickHouse 走向更广泛应用的贡献者。

Alon Tal、Andrey Volkov、Damian Maslanka、Diskein、Dominic Tran、Fgrtue、H0uston、HumanUser、Ilya fanyShu、Joshie、Mishmish Dev、Mithun P、Oleg Doronin、Paul Lamb、Rafael Roquetto、Ronald Wind、Shiv、Shivji Kumar Jha、Surya Kant Ranjan、Ville Ojamo、Vlad Buyval、Xander Garbett、Yanghong Zhong、ddavid、e-mhui、f2quantum、jemmix、kirillgarbar、lan、wh201906、xander、yahoNanJing、yangjiang、yangzhong、思维
由 Anton Popov 开发
ClickHouse 现在支持 可大规模执行的标准 SQL UPDATE 语句,由全新的轻量级 patch-part 机制驱动。与传统需要重写整列数据的变更操作不同,这种方式只会写入很小的补丁部分(patch parts),能够即时生效,并且对查询性能几乎没有影响。
工作原理
补丁部分继承了 专用引擎(https://clickhouse.com/blog/updates-in-clickhouse-1-purpose-built-engines)(如 ReplacingMergeTree)背后的相同原理,但以完全通用的方式,通过 标准 SQL(https://www.w3schools.com/sql/sql_update.asp) 暴露给用户:
UPDATE ordersSET discount = 0.2WHERE quantity >= 40;
插入操作非常快速(https://clickhouse.com/blog/updates-in-clickhouse-1-purpose-built-engines#inserts-are-so-fast-we-turned-updates-into-inserts)。
合并是持续进行的(https://clickhouse.com/blog/updates-in-clickhouse-1-purpose-built-engines#merges-are-fast-thanks-to-sorted-parts)。
数据部分是不可变且有序的(https://clickhouse.com/blog/updates-in-clickhouse-1-purpose-built-engines#inserts-create-sorted-and-immutable-parts)。
因此,ClickHouse 不会去定位并直接修改行,而是插入一个紧凑的补丁部分,用于在合并过程中修补数据部分,仅应用更改过的数据。
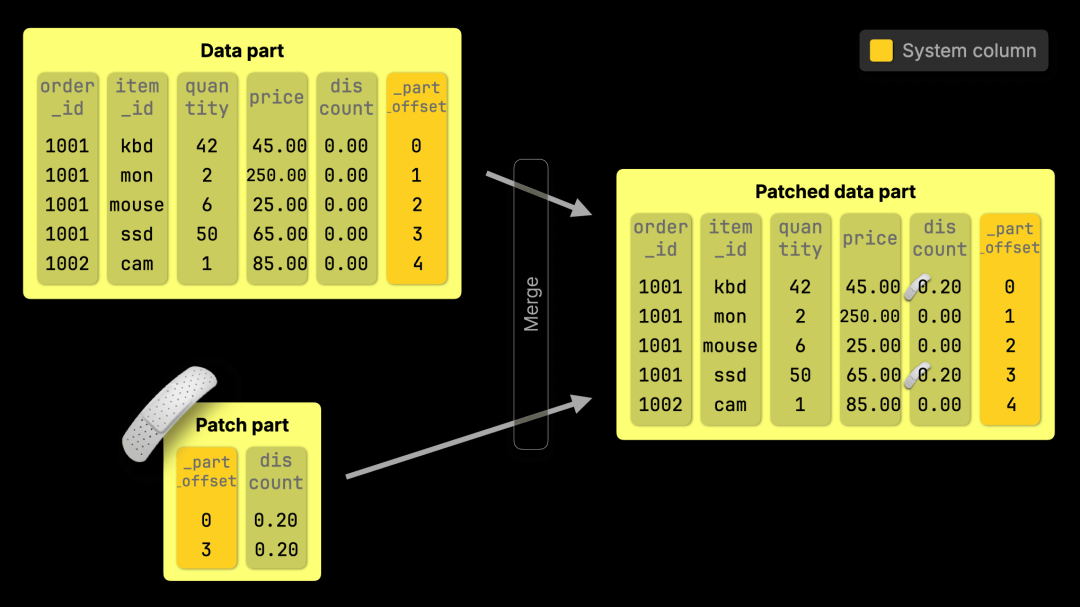
合并任务原本就在后台运行,现在我们让它在几乎零额外开销的情况下多做一步:应用补丁部分,在合并数据时高效更新基础数据。
更新可以即时反映出来,尚未合并的补丁部分会被匹配,并且会在每个 数据流(https://clickhouse.com/docs/optimize/query-parallelism#distributing-work-across-processing-lanes) 的各个数据范围内独立应用,以精确且有针对性的方式确保更新正确执行,同时不影响并行处理。
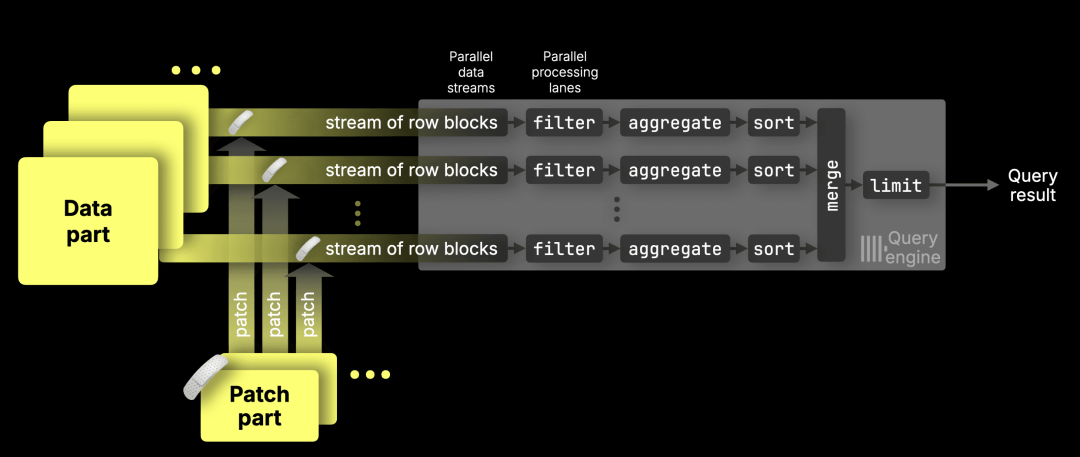
这让声明式更新在我们的基准测试中最高可比以往快 1,000 倍(https://clickhouse.com/blog/updates-in-clickhouse-3-benchmarks#time-until-bulk-updates-are-visible-to-queries),并且在合并前对查询的影响几乎可以忽略。
无论是更新一行还是一百万行,现在都能做到快速、高效,并且完全是声明式的。
DELETE 是 轻量级 羽量级
对于使用 标准 SQL 语法(https://www.w3schools.com/sql/sql_delete.asp) 的 DELETE 操作,例如:
DELETE FROM orders WHERE order_id = 1001 AND item_id = 'mouse';
ClickHouse 只需创建一个补丁部分,将被删除行的 _row_exists 设置为 0。然后,这些行会在下一次后台合并时被移除。
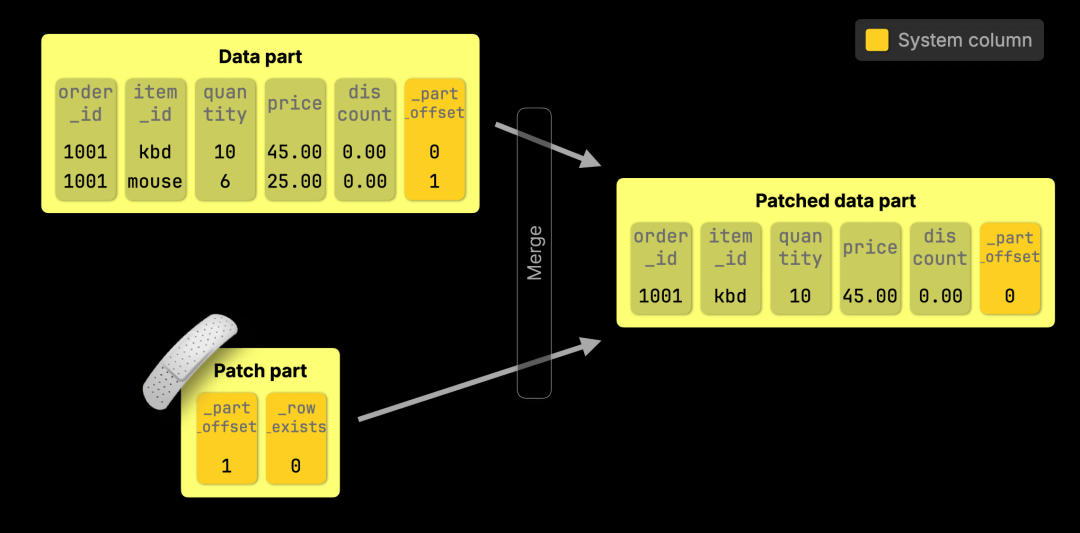
快速 UPDATE 的内部机制
想更深入地了解?可以阅读我们关于 ClickHouse 快速 UPDATE 的三篇博客系列:
第 1 篇:专用引擎(https://clickhouse.com/blog/updates-in-clickhouse-1-purpose-built-engines)
介绍 ClickHouse 如何利用基于插入的引擎(ReplacingMergeTree、CollapsingMergeTree、CoalescingMergeTree)来规避缓慢的行级更新。
第 2 篇:声明式 SQL 风格 UPDATE(https://staging.clickhouse.com/blog/updates-in-clickhouse-2-sql-style-updates)
探讨我们如何通过补丁部分将标准 UPDATE 语法引入 ClickHouse,并将额外开销降至最低。
第 3 篇:基准测试(https://clickhouse.com/blog/updates-in-clickhouse-3-benchmarks)
展示实际的性能效果。我们对包括声明式 UPDATE 在内的多种方式进行了基准测试,最高实现了 1,000 倍的性能提升。
由 Kaushik Iska 贡献
ClickHouse 客户端和 clickhouse-local (https://clickhouse.com/docs/operations/utilities/clickhouse-local) 现已支持 AI 生成 SQL(https://clickhouse.com/docs/use-cases/AI/ai-powered-sql-generation)。只需在命令前加上 ?? 前缀即可启用,如果在环境变量中设置了 OPENAPI_API_KEY 或 ANTHROPIC_API_KEY,系统会提示你是否使用该密钥。
例如,我们可以先连接到 ClickHouse SQL Playground:
./clickhouse client -mn--host sql-clickhouse.clickhouse.com--secure--user demo --password ''
接着请求获取 2025 年 7 月最受欢迎的代码仓库:
?? what was the most popular github repository in July 2025?;
系统会确认是否使用 API key:
AI SQL generation will use openai API key from environment variable.Do you want to continue? [y/N] y
随后便会开始执行,并在生成过程中输出推理信息:
• Starting AI SQL generation with schema discovery...─────────────────────────────────────────────────🧠 thinking..[INFO] Text generation successful - model: gpt-4o, response_id: chatcmpl-BxBDkKy9sNi1Bw8E26UC8RXNBMrPT🔧 Calling: list_databases [call_IXv...]✓ list_databases completed└─ Found 37 databases: - amazon - bluesky - country - covid - default - dns - en...🔧 Calling: list_databases [call_IXv...]🧠 thinking...✓ list_databases completed└─ Found 37 databases: - amazon - bluesky - country - covid - default - dns - en...🧠 thinking..[INFO] Text generation successful - model: gpt-4o, response_id: chatcmpl-BxBDmOwzsHgBNHtOiT8tEIhjJoMXV🔧 Calling: list_tables_in_database [call_pRq...]└─ Args: {"database":"github"}🧠 thinking...✓ list_tables_in_database completed└─ Found 19 tables in database 'github': - actors_per_repo - actors_per_repo_mv ...🔧 Calling: list_tables_in_database [call_pRq...]└─ Args: {"database":"github"}✓ list_tables_in_database completed└─ Found 19 tables in database 'github': - actors_per_repo - actors_per_repo_mv ...🧠 thinking...[INFO] Text generation successful - model: gpt-4o, response_id: chatcmpl-BxBDo0qbEkfvzTl6vgrA49fgjVVfo🔧 Calling: get_schema_for_table [call_NKK...]└─ Args: {"database":"github","table":"repo_events_per_day"}🧠 thinking✓ get_schema_for_table completed└─ Schema for github.repo_events_per_day: CREATE TABLE github.repo_events_per_da...🔧 Calling: get_schema_for_table [call_NKK...]└─ Args: {"database":"github","table":"repo_events_per_day"}✓ get_schema_for_table completed└─ Schema for github.repo_events_per_day: CREATE TABLE github.repo_events_per_da...🧠 thinking.[INFO] Text generation successful - model: gpt-4o, response_id: chatcmpl-BxBDpMp0HpRmFZK2VBZG5y6sWMCsF─────────────────────────────────────────────────• ✨ SQL query generated successfully!
以下是它生成的查询:
SELECTrepo_name,sum(count) AS total_eventsFROM github.repo_events_per_dayWHERE (created_at >= '2025-07-01') AND (created_at <= '2025-07-31')GROUP BY repo_nameORDER BY total_events DESCLIMIT 1;
┌─repo_name───────────────────┬─total_events─┐│ freefastconnect/fastconnect │ 333215 │└─────────────────────────────┴──────────────┘
如果我来写,还会按事件类型进行过滤,仅保留 `WatchEvent`,但这个结果已经是一个不错的起点。欢迎试用,并与我们分享你的体验!
由 Amos Bird 贡献
本次发布对 count() 聚合进行了针对性优化,降低了内存和 CPU 占用,使此类查询执行速度进一步提升。
ClickHouse 的并行聚合
ClickHouse 在执行此类查询时,本就采用高度并行的方式:利用所有可用 CPU 核心,将任务分配到多个处理通道,并将硬件性能发挥到接近极限。
其典型工作流程如下:
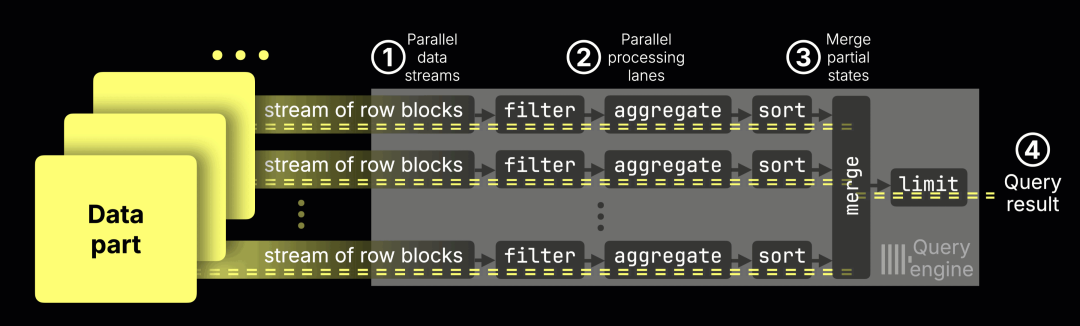
① 数据流入
数据以块为单位被持续导入引擎。
② 并行处理
每个 CPU 核心处理互不重叠的数据范围,独立执行过滤、聚合和排序。
③ 合并部分结果生成 ④ 最终结果
每个通道会生成部分聚合状态(例如 avg() 的总和与计数),这些中间结果会被合并为最终输出。
下面我们聚焦于流水线中的一个阶段:聚合。在这一阶段,每个 CPU 核心会针对其负责的数据范围累积部分结果(如总和和计数),随后再与其他核心的结果合并,生成最终答案。
为什么需要部分聚合状态 (Partial Aggregation States)
部分聚合状态使高度并行的处理模型成为可能,它让每个 CPU 核心可以独立处理,同时确保最终结果的正确性。
要理解其必要性,可以看一个计算各城镇房产平均价格(https://clickhouse.com/docs/getting-started/example-datasets/uk-price-paid)的例子:
SELECTtown,avg(price) AS avg_priceFROM uk_price_paidGROUP BY town;
假设我们使用两个 CPU 核心来计算伦敦的平均价格:
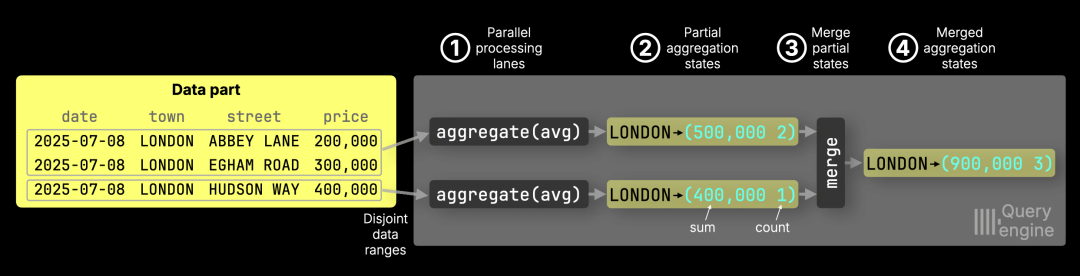
① 并行处理与 ② 部分聚合状态
通道 1 处理两行伦敦数据 → sum = 500,000,count = 2
通道 2 处理一行伦敦数据 → sum = 400,000,count = 1
③ 合并生成 ④ 最终状态
最终 avg = (500,000 + 400,000) (2 + 1) = 300,000
必须合并总和与计数,而不能直接合并中间平均值,否则会产生错误:
(250,000 + 400,000) 2 = 325,000 ← 错误
GROUP BY 聚合的内部机制
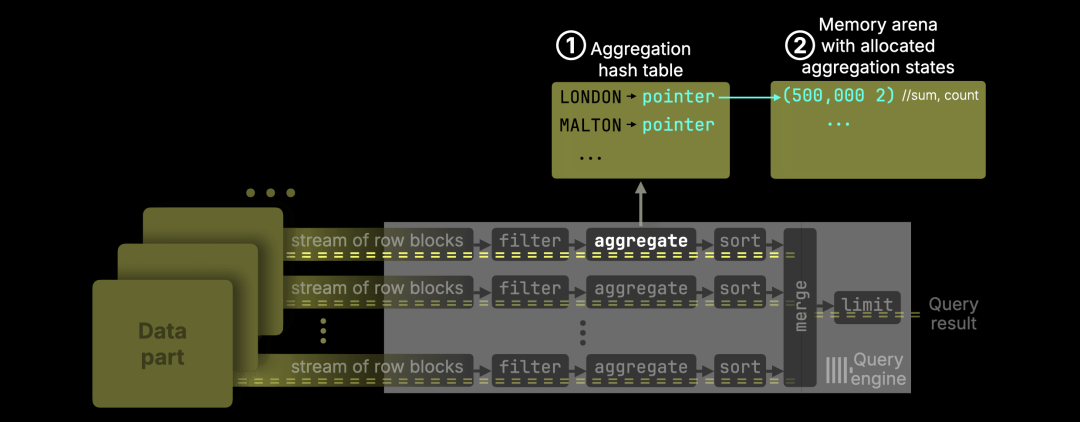
进一步深入到聚合阶段的内部工作,可以看到每个处理通道会维护自己的哈希表,并独立构建聚合状态。
GROUP BY 查询在每个通道内独立执行,采用哈希聚合算法:每个通道维护一个哈希表(https://clickhouse.com/blog/hash-tables-in-clickhouse-and-zero-cost-abstractions),其中每个键(如城镇名)指向一个聚合状态。
在我们的例子中,当处理通道读取到 LONDON 时:
如果该键在 ① 哈希表中不存在,则创建新条目,并在 ② 全局内存区域分配一个聚合状态,同时将该状态的指针存入哈希表。
如果该键已存在,则通过指针查找并更新全局内存区域中对应的聚合状态。
count() 优化
接下来看看这个版本在 count() 聚合上的改进。
对于这样的查询:
SELECTtown,count() AS countFROM uk_price_paidGROUP BY town;
……ClickHouse 现在会完全跳过内存分配区域(memory arena)。
由于 count() 是可加函数(https://en.wikipedia.org/wiki/Additive_function),在跨通道合并部分结果时,不需要维护复杂的聚合状态。它只需存储一个 64 位整数(计数值),在 64 位系统中,这个大小与指针相当甚至更小,因此 ClickHouse 可以:
将计数值直接存储在哈希表单元中
省去在内存分配区域申请空间
省去指针寻址的过程
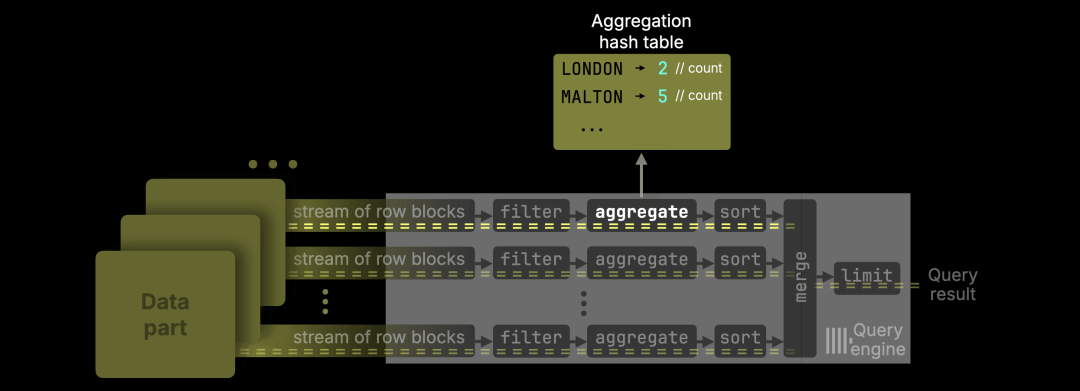
这样就避免了内存分配和指针访问的开销,降低了 CPU 与内存使用。
在我们的测试中,count() 聚合的执行速度相比之前提升了 20–30%,同时显著减少了内存占用和 CPU 消耗。
为什么重要
Count 聚合是最常用的操作之一:从仪表盘上统计最活跃的用户或下载量最高的软件包(https://clickhouse.com/blog/clickhouse_vs_elasticsearch_mechanics_of_count_aggregations#count-aggregations-in-clickhouse-and-elasticsearch),到告警系统中监控异常事件频率。无论是分析、可观测性还是搜索,几乎所有系统都依赖高效的 count 查询。因此,即使是微小的优化,也能带来巨大的影响。
真实环境测试结果
我们使用一个典型的 Web 分析查询来演示这一优化:该查询通过 count() 聚合返回最活跃的 10 位用户。
SELECT UserID, count()FROM hitsGROUP BY UserIDORDER BY count() DESCLIMIT 10;
(你可以通过创建(https://github.com/ClickHouse/ClickBench/blob/83d5a48f7a29703064e27a44f1cb918d9f53ff43/clickhouse/create.sql)表并加载(https://github.com/ClickHouse/ClickBench/blob/83d5a48f7a29703064e27a44f1cb918d9f53ff43/clickhouse/benchmark.sh#L36)数据自行运行)
测试环境为 AWS m6i.8xlarge EC2 实例(32 核 CPU,128 GB 内存),存储使用 gp3 EBS 卷(16k IOPS,最大吞吐量 1000 MiB/s)。
我们在 ClickHouse 25.6 上运行该查询 3 次,并展示由 clickhouse-client 返回的运行时统计数据:
10 rows in set. Elapsed: 0.447 sec. Processed 100.00 million rows, 799.98 MB (223.49 million rows/s., 1.79 GB/s.)Peak memory usage: 2.50 GiB.10 rows in set. Elapsed: 0.391 sec. Processed 100.00 million rows, 799.98 MB (255.79 million rows/s., 2.05 GB/s.)Peak memory usage: 2.52 GiB.10 rows in set. Elapsed: 0.383 sec. Processed 100.00 million rows, 799.98 MB (261.21 million rows/s., 2.09 GB/s.)Peak memory usage: 2.51 GiB.
接着,我们在 ClickHouse 25.7 上同样运行了该查询 3 次:
10 rows in set. Elapsed: 0.305 sec. Processed 100.00 million rows, 799.98 MB (327.54 million rows/s., 2.62 GB/s.)Peak memory usage: 2.00 GiB.10 rows in set. Elapsed: 0.265 sec. Processed 100.00 million rows, 799.98 MB (377.43 million rows/s., 3.02 GB/s.)Peak memory usage: 1.96 GiB.10 rows in set. Elapsed: 0.237 sec. Processed 100.00 million rows, 799.98 MB (422.34 million rows/s., 3.38 GB/s.)Peak memory usage: 1.96 GiB.
以下是运行结果分析:
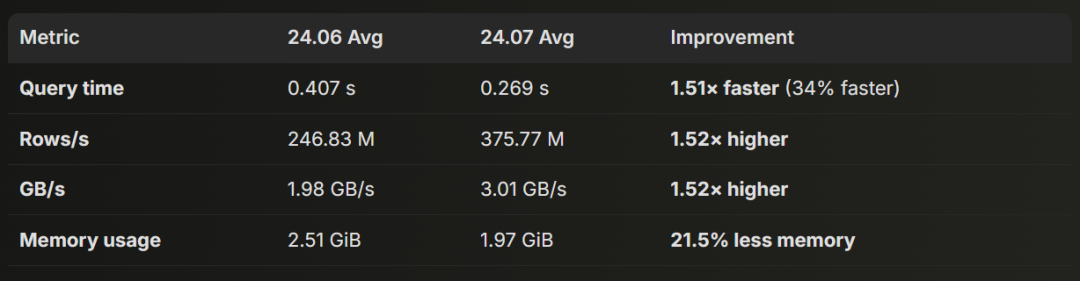
ClickHouse 24.06
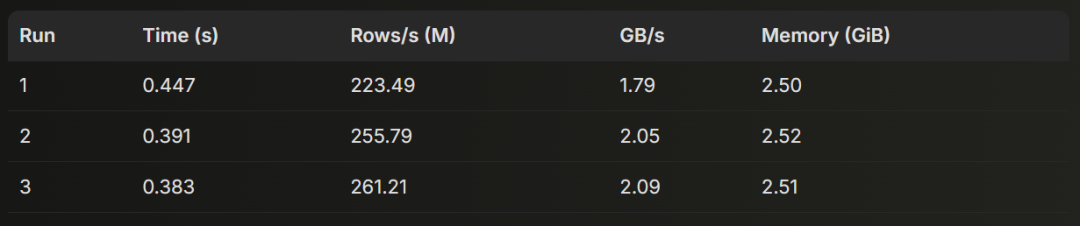
平均值:
执行时间:0.407 秒
行处理速度:246.83 M 行/秒
吞吐率:1.98 GB/秒
内存占用:2.51 GiB
ClickHouse 24.07
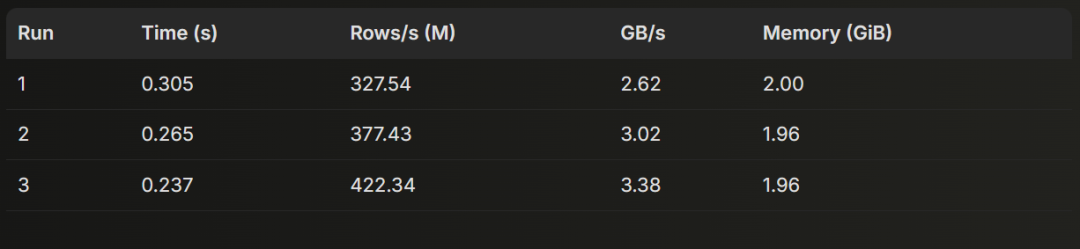
平均值:
执行时间:0.269 秒
行处理速度:375.77 M 行/秒
吞吐率:3.01 GB/秒
内存占用:1.97 GiB
24.06 与 24.07 的性能改进
由 Nikita Taranov 贡献
过去几个月里,提升 JOIN 性能一直是我们的重点工作。默认的 JOIN 策略——并行哈希连接(parallel hash join)(https://clickhouse.com/blog/clickhouse-fully-supports-joins-hash-joins-part2#parallel-hash-join)——在多个版本中持续获得优化:
ClickHouse 24.7 改进了哈希表的分配效率(https://clickhouse.com/blog/clickhouse-release-24-07#faster-parallel-hash-join)。
ClickHouse 24.12 引入了自动 JOIN 重排序(https://clickhouse.com/blog/clickhouse-release-24-12#automatic-join-reordering),可智能选择构建阶段的最优表。
ClickHouse 25.1 与 25.2 分别进行了更底层的性能优化,加快了 JOIN 的探测阶段(https://clickhouse.com/blog/clickhouse-release-25-01#faster-parallel-hash-join),并消除了构建阶段的线程争用(https://clickhouse.com/blog/clickhouse-release-25-02#faster-parallel-hash-join)。
在并行化、查询规划和算法效率上的这些持续改进,使 JOIN 性能稳步提升。ClickHouse 25.7 延续了这一趋势,新增了四项针对哈希连接的底层性能优化:
1. 单列键 JOIN 提速
移除了单列键 JOIN 中的内部循环及多余的空值检查,减少了 CPU 指令执行量,从而加快了执行速度。
在 PR(https://github.com/ClickHouse/ClickHouse/pull/82308) 的测试截图中,柱状图展示了新旧版本的性能对比,整体平均提速约 1.37 倍。

2. 多 OR 条件 JOIN 提速
将上述单列键优化扩展到了 ON 子句中包含多个 OR 条件的 JOIN。这类 JOIN 现在同样受益于底层性能提升,执行效率显著提高。
在 PR(https://github.com/ClickHouse/ClickHouse/pull/83041) 的性能测试截图中可以看到,带有 OR 条件的 JOIN 查询最高提速可达 1.5 倍,这得益于指令开销的减少以及更高效的 JOIN 循环执行。

3. 降低 JOIN 处理的 CPU 开销
优化了 JOIN 跟踪过程,去掉了重复的哈希计算,减少了冗余操作并提升了吞吐量。
根据 PR(https://github.com/ClickHouse/ClickHouse/pull/83043) 的性能测试截图,对于输入数据量较大的两条 JOIN 查询,优化后运行速度提升了 1.5~1.8 倍。此优化尤其针对高匹配基数的 JOIN,过去在这种情况下,重复的哈希计算会消耗大量 CPU 资源。


4. 降低 JOIN 结果的内存占用
在确定匹配数量后,系统会精确分配结果缓冲区大小,避免了过度分配,从而减少内存占用并提升性能。这对于宽行数据(列重复或包含填充列)尤其有效,例如 JOIN ... USING 查询或带合成列的结果集。
PR(https://github.com/ClickHouse/ClickHouse/pull/83304) 的性能测试结果显示,对于宽结果行的 JOIN 查询,优化后执行速度提升了 1.3~1.4 倍。此前,这类查询常常为连接结果过度分配内存,而该优化有效解决了这一问题。


优化仍在进行中。JOIN 性能依旧是我们的核心优化目标,未来版本中我们将继续改进并行哈希连接以及其他 JOIN 策略。
即将推出:我们正在准备一篇技术深度解析,全面介绍过去几个月 JOIN 性能改进的细节,包括基准测试数据和实际应用案例。敬请关注!
由 Konstantin Vedernikov 贡献
在 ClickHouse 25.5 中,ClickHouse 新增了对 Parquet 文件中 Geo 类型的读取支持(https://clickhouse.com/blog/clickhouse-release-25-05#geo-types-in-parquet)。当时,这些 Parquet 的 Geo 类型会被映射为 ClickHouse 中的其他类型,例如元组(tuple)或列表(list)。
从 25.7 开始,ClickHouse 可以将所有 采用 WKB 编码的 Geo 类型(https://libgeos.org/specifications/wkb/#geometry-types) 直接读取为对应的 ClickHouse Geo 类型。
下面的示例演示了其工作方式:我们首先执行一个查询,将每种 ClickHouse Geo 类型写入到一个 Parquet 文件中。
SELECT (10, 10)::Point as point,[(0, 0), (10, 0), (10, 10), (0, 10)]::LineString AS lineString,[[(0, 0), (10, 0), (10, 10), (0, 10)],[(1, 1), (2, 2)]]::MultiLineString AS multiLineString,[[(20, 20), (50, 20), (20, 50)], [(30, 30), (50, 50), (50, 30)]]::Polygon AS polygon,[ [[(0, 0), (10, 0), (10, 10), (0, 10)]],[[(20, 20), (50, 20), (50, 50), (20, 50)],[(30, 30), (50, 50), (50, 30)]]]::MultiPolygon AS multiPolygon,[(0, 0), (10, 0), (10, 10), (0, 10)]::Ring AS ringINTO OUTFILE 'geo.parquet' TRUNCATE;
随后,将该 Parquet 文件重新读入:
DESCRIBE file('geo.parquet');
┌─name────────────┬─type────────────────────────┐│ point │ Point ││ lineString │ LineString ││ multiLineString │ MultiLineString ││ polygon │ Polygon ││ multiPolygon │ MultiPolygon ││ ring │ Array(Tuple( ↴││ │↳ `1` Nullable(Float64), ↴││ │↳ `2` Nullable(Float64))) │└─────────────────┴─────────────────────────────┘
除了 Ring 之外,所有类型都按其 Geo 类型正确读回。在 Parquet 中,Geo 类型通常采用 WKB 编码(https://libgeos.org/specifications/wkb/#geometry-types),而 WKB 编码并不支持 Ring 类型。
由 Paul Lamb 贡献
本次版本引入了两个用于检测多边形是否相交的新函数:polygonIntersectsCartesian 和 polygonIntersectsSpherical。
polygonIntersectsCartesian 基于笛卡尔(平面)几何进行计算,而 polygonIntersectsSpherical 则基于球面几何进行判断。
例如,使用 polygonIntersectsSpherical 可以检测覆盖伦敦市中心部分区域的两个多边形是否相交。
select polygonsIntersectSpherical([[[(-0.140, 51.500), (-0.140, 51.510), (-0.120, 51.510), (-0.120, 51.500), (-0.140, 51.500)]]],[[[(-0.135, 51.505), (-0.135, 51.515), (-0.115, 51.515), (-0.115, 51.505), (-0.135, 51.505)]]]);
┌─polygonsInte⋯51.505)]]])─┐│ 1 │└──────────────────────────┘
而 polygonIntersectsCartesian 的示例则使用了两个位于球场两侧的足球运动员的假想坐标。
select polygonsIntersectCartesian([[[(0.0, 0.0), (0.0, 64.0), (45.0, 64.0), (45.0, 0.0), (0.0, 0.0)]]],[[[(55.0, 0.0), (55.0, 64.0), (100.0, 64.0), (100.0, 0.0), (55.0, 0.0)]]]);
┌─polygonsInte⋯51.505)]]])─┐│ 1 │└──────────────────────────┘
由 Artem Brustovetskii Diskein 贡献
本次版本在安全方面也带来了一些增强功能。
首先,现在可以通过参数化查询动态创建用户,使用户配置更加灵活。
SET param_username = 'test123';CREATE USER {username:Identifier};
例如,可以使用变量化的用户名进行程序化用户创建,从而提升用户管理工作流的自动化能力。
此外,还支持为外部数据源单独配置 READ 和 WRITE 授权。此前,外部数据访问依赖较为宽泛的权限控制。
GRANT S3 ON *.* TO user
在 25.7 中,你可以在配置文件中启用新的读/写授权功能:
# config.d/read_write_grants.yamlaccess_control_improvements:enable_read_write_grants: true
然后可以像这样授予权限:
GRANT READ, WRITE ON S3 TO user;

我们正为北京活动招募讲师,如果你有独特的技术见解、实践经验或 ClickHouse 使用故事,非常欢迎你加入我们,成为这次活动的讲师,与大家分享你的经验。

/END/
试用阿里云 ClickHouse企业版
轻松节省30%云资源成本?阿里云数据库ClickHouse 云原生架构全新升级,首次购买ClickHouse企业版计算和存储资源组合,首月消费不超过99.58元(包含最大16CCU+450G OSS用量)了解详情:https://t.aliyun.com/Kz5Z0q9G


征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


