




“ 散步促进我的思想。我的身体必须不断运动,脑筋才会开动起来。 —— 卢梭”

1、前言
为什么需要使用分布式系统?做个大型项目的基本上都接触过分布式文件系统,我给大家举例子说清楚我们为什么需要使用分布式文件系统。
平时我们的文件如何存储呢?存在什么地方呢?据我真实接触过的项目,相信很多同学也接触过类似的项目,大概分以下几种情况来存储文件。
方案一:把文件存储到数据库的 blob 字段里面
方案二:把文件存储到项目的某个目录下,也就是 Tomcat 下面
方案三:把文件存储到服务器的非 Tomcat 目录下,然后再通过 Tomcat、Nginx 做文件映射
方案四:文件上传到 Ftp,再然后通过 Tomcat、Nginx 做文件映射,当然这种模式相比前三种来说,还是可以接受的
这四种模式我相信很多人都接触过,甚至当初自己就是这么干的,如果你还是停留在这四种模式上,那么希望本章内容对你能有一定的帮助。那么分析一下,以上四种模式的所存在的弊端到底是什么,为什么不提倡这么做。
方案一:存储数据库的弊端
把文件存储到数据库将是灾难性的,严重占用数据库的存储空间,数据库很容易就会爆满;
影响数据库的查询性能,试想一如果 100 个人同时下载 10g 的文件,也就是从数据库读取文件,将是什么样的后果;
同时数据库的备份和还原都非常的麻烦,浪费很长的时间;
无法横向扩展容量,数据库满了,则再也无法上传文件了。
方案二:存储把文件存储到项目的某个目录下的弊端
容易丢失文件,项目重新部署,很容易就丢失文件
无法支持集群
无法横向扩展容量,如果服务器磁盘满了,则再也无法上传文件了
方案三:把文件存储到服务器的非 Tomcat 目录下的弊端
无法支持集群
无法横向扩展容量,如果服务器磁盘满了,则再也无法上传文件了
方案四:文件上传到 Ftp 的弊端
这种模式支持集群,但是还是有弊端
无法横向扩展容量,如果服务器磁盘满了,则再也无法上传文件了
不支持高级特性,比如:副本冗余,负载均衡等;
这里,重点讲解一下无法支持集群的大概意思,具体如下图所示: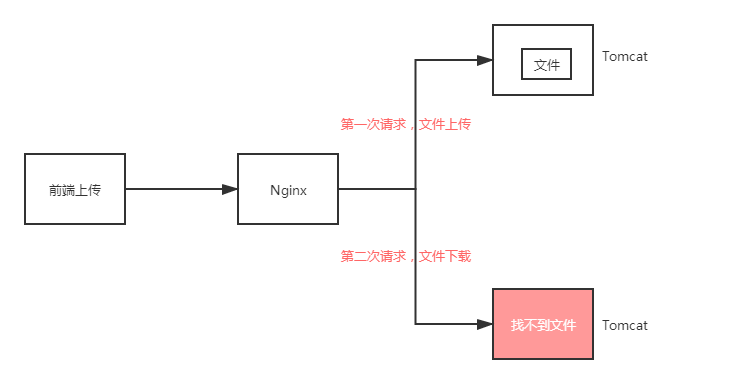
通过上面的架构图,大家应该能理解不使用分布式文件系统所存在的缺陷了,因此我们很有必要学习和使用分布式文件系统。它的好处很明显,给大家总结一下。
第一:动态扩展服务器的容量,不需要一台特别牛逼的超级计算机,可以由若干普通服务器组成一个集群即可。
第二:分布式文件系统支持冗余备份,或者叫副本冗余;就是把一份文件在不同服务器都备份一份,好处如下:
容灾:如果其中一台服务器宕机了,其他节点还能正常对外提供服务,不至于整个集群瘫痪。
负载:一个文件在不同的服务器都有备份,那么当用户下载这份文件时,可以从不同的服务器进行下载。
那么,市面上主流的分布式文件系统到底有哪些呢?
常见的应用级别(不是系统级别)的文件系统有:GFS、HDFS、Lustre 、Ceph 、GridFS 、mogileFS、TFS、FastDFS、NFS、MFS。但是目前比较常用的主要是阿里开源的 FastDFS、Hadoop 生态里的 HDFS,FastDFS 主要应用电商行业比较多,用于存储商品的图片;HDFS 主要运用大数据领域比较多。
FastDFS和HDFS的简单对比:
| 类型 | FastDFS | HDFS |
|---|---|---|
| 开发语言 | c语言 | Java语言 |
| 切块 | 不支持 | 支持 |
| 文件大小 | 500M以内 | 不限制 |
| 领域 | 一般用于电商领域 | 一般用于大数据领域 |
| 社区及API | 完善的API,国内用户量比较大 | 完善的API,用户群体比较大 |
| 性能 | 读写速度比较快 | 读写速度比较慢 |
既然FastDFS和 HDFS 都是主流,那么我们应该如何选择呢,带大家从以下几个方面来做选择。
第一:FastDFS 不支持切块,大于 500M 的文件则读写性能比较差,但是 500M 以下性能非常的高。
第二:HDFS 支持切块,无法高效的对大量小文件进行存储,原因是占用 NameNode 大量的内存来存储文件的目录和块信息,小文件存储的寻址时间会超过读取时间;不支持并发写入,一个文件只能有一个写,不允许多个线程同时写。
那么由此,可知,如果想要速度快则选择 FastDFS,如果想上传大文件则选择 HDFS。由于我们的网盘是进行切块上传和切块存储的,单个切块不大(标准是5M),因此选择 FastDFS 是非常的合适的。
2、FastDFS的原理分析
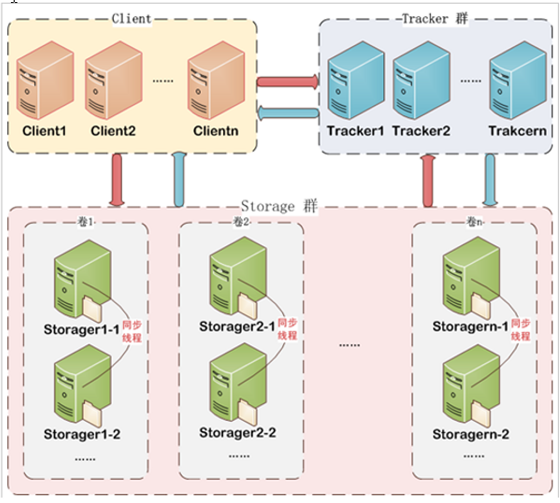
FastDFS的架构图
FastDFS流程图
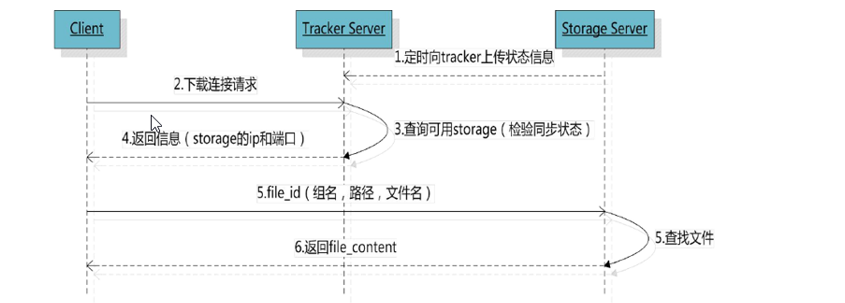
根据上面两张图,我们可以清晰的知道 FastDFS 主要有两个部分组成,分别是 Tracker Server 和 Storage Server,其中 Tracker Server 是追踪服务,也就是管理节点,专门管理文件的存储的地址信息的,同时它会和 Storage Server 保持心跳;Storage Server 是存储服务,真实的存储文件的数据。
文件上传流程剖析:
第一步,客户端先去 Tracker Server 获取上传的服务器信息,Tracker Server 会根据那个 Storage 节点的文件数量比较少,哪个 Storage 比较空闲等,返回具体的 Storage Server 的服务器 IP 和 Port 信息给客户端。
第二步,客户端再连接具体的 Storage Server 上传文件
文件下载流程剖析:
第一步,根据文件的信息去 Tracker Server 查询文件存储的服务器信息,Tracker Server 会查询文件所在服务器,由于文件会存在副本,因此通过负载策略把 Storage Server 的服务器 IP 和 Port 信息返回给客户端。
第二步,客户端再连接具体的Storage Server下载文件
通过上传、下载两个流程的分析,大家对 Storage Server 和 Tracker Server 的作用应该都能理解了吧。
3、FastDFS的安装
FastDFS 的安装步骤还是比较繁琐的,它主要包括五个部分的安装,依赖的基础环境、libfastcommon、FastDFS 的 tracker 和 storage、fastdfs-nginx-module(非必须)的安装。
3.1、基础环境
yum install make cmake gcc gcc-c++
3.2、libfastcommon
#1.下载:
wget https://github.com/happyfish100/libfastcommon/archive/V1.0.7.tar.gz
#2.解压:
tar -zxvf V1.0.7.tar.gz
#3.进入:
cd libfastcommon-1.0.7
#4.编译:
./make.sh
#5.安装:
./make.sh install
#6.拷贝文件
cp /usr/lib64/libfastcommon.so /usr/lib
#原因:libfastcommon安装好之后自动将库文件拷贝至/usr/lib64下,由于FastDFS程序引用/usr/lib目录,所以需要将/usr/lib64下的库文件拷贝至/usr/lib下
3.3、FastDFS-Tracker
1、Tracker的安装
#1.新建目录
mkdir -p /usr/local/java/fastdfs/trackerdata
#2.解压
wget https://github.com/happyfish100/fastdfs/archive/V5.05.tar.gz
tar -zxvf V5.05.tar.gz -C /usr/local/java/fastdfs
#3.进入目录
cd /usr/local/java/fastdfs/fastdfs-5.05
#4.编译
./make.sh
#5.安装
./make.sh install
#6.安装自动生成/etc/fdfs目录,需要把文件拷贝到里面
cd /usr/local/java/fastdfs/fastdfs-5.05/conf
cp * /etc/fdfs
#7.进入目录
cd /etc/fdfs
#8.配置tracker.conf
vim /etc/fdfs/tracker.conf
base_path=/usr/local/java/fastdfs/trackerdata #软件运行产生的日志和数据
2、Tracker的配置
#进入目录
cd /etc/init.d
#创建文件夹
mkdir /usr/local/fdfs
#拷贝文件
cd /usr/local/java/fastdfs/fastdfs-5.05
cp stop.sh restart.sh /usr/local/fdfs/
#编辑(核心,一共7个地方需要修改)
vim fdfs_trackerd
PRG=/usr/bin/fdfs_trackerd #改成/usr/bin
stop.sh和restart.sh的路径
3、Tracker的启动
#启动(初次成功启动,会在/usr/local/java/fastdfs/trackerdata目录下创建data、logs两个目录)
/etc/init.d/fdfs_trackerd start
#状态:
ps -ef | grep fdfs
#停止:
/etc/init.d/fdfs_trackerd stop
3.4、FastDFS-Storage
提示:tracker和storage可以在安装在同一台机器上,也可以安装在不同机器上;这里主要是讲解分别安装在不同的机器上面。
1、Storage的安装
#1.新建目录
mkdir -p /usr/local/java/fastdfs/storedata
#2.解压
wget https://github.com/happyfish100/fastdfs/archive/V5.05.tar.gz
tar -zxvf V5.05.tar.gz -C /usr/local/java/fastdfs
#3.进入目录
cd /usr/local/java/fastdfs/fastdfs-5.05
#4.编译
./make.sh
#5.安装
./make.sh install
#6.安装自动生成/etc/fdfs目录,需要把文件拷贝到里面
cd /usr/local/java/fastdfs/fastdfs-5.05/conf
cp * /etc/fdfs
#7.进入目录
cd /etc/fdfs
#8.配置storage.conf
vim /etc/fdfs/storage.conf
base_path=/usr/local/java/fastdfs/trackerdata #软件运行产生的日志和数据
store_path0=/usr/local/java/fastdfs/storedata #文件真实存储目录
tracker_server=192.168.1.8:22122 #IP是Tracker的IP
2、Storage的配置
#进入目录
cd /etc/init.d
#创建文件夹
mkdir /usr/local/fdfs
#拷贝文件
cd /usr/local/java/fastdfs/fastdfs-5.05
cp stop.sh restart.sh /usr/local/fdfs/
#编辑(核心,一共7个地方需要修改)
vim fdfs_storaged
PRG=/usr/bin/fdfs_storaged #改成/usr/bin
stop.sh和restart.sh的路径
3、Storage的启动
#启动:
/etc/init.d/fdfs_storaged start
#状态:
ps -ef | grep fdfs
#停止:
/etc/init.d/fdfs_storaged stop
4、FastDFS核心讲解
1、端口说明
Tracker 的端口,22122
Storage 需要连接 Tracker,保持心跳,方便 Tracker 管理 Storage
2、文件真实位置
store_path0=/usr/local/java/fastdfs/storedata #文件真实存储目录
Storage Server 安装好的时候,默认会生成很多的文件夹,自己可以进入目录查看
3、组的概念(核心)
FastDFS 对 Storage 进行分组,组名称相同,则存储的文件相同;组名称不同,则存储的文件不同。这句话可能光从字面意思理解会比较难理解,下面具体讲解。
/etc/fdfs/tracker.conf 里面的核心配置,具体如下:
store_lookup=2 #0轮询、1指定group、2剩余最多的group
store_group=group2 #如果store_lookup=1的时候,指定
store_server=0 #指定服务器(一个group里面有多个server)
store_lookup,表示文件上传时,tracker 寻址具体 group 的策略
store_group,指定组名,如果 store_lookup=1 时生效
特殊业务场景使用,比如实现不同区域的用户上传的文件保存到其对应区域的服务器
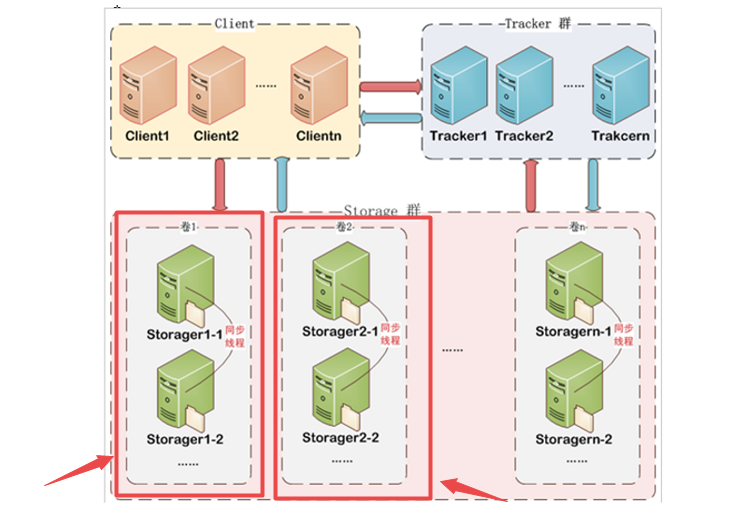
参考下面的架构图分析:
第一:每个红色框是一个组,FastDFS 集群可以有很多的组
第二:每个组里面会有很多的 Storage Server 存储节点,同一个组下面的 Storage 之间会做文件同步,目的就是对文件生成副本,可以进行容错、负载等等。
第三:不同的组存储的文件不一样,如果集群容量满了,可以通过扩展一个组来进行集群容量的扩展
总结,分析到这里,大家应该都理解 FastDFS 集群的含义了吧
思考:通过上面的分析,那么FastDFS扩展集群有几种类型呢?
**解答:**会有两种模式
给某个组新增 Storage 节点,做副本备份
扩展一个组,扩展集群整体总容量
5、FastDFS快速入门
第一步:配置 Maven 坐标
<dependency>
<groupId>com.luhuiguo</groupId>
<artifactId>fastdfs-spring-boot-starter</artifactId>
<version>0.2.0</version>
</dependency>
第二步:配置 application.properties
#tracker地址
fdfs.tracker-list=192.168.1.8:22122
#连接超时时间
fdfs.connect-timeout=10000
#上传超时时间
fdfs.so-timeout=3000
第三步:上传代码
@Autowired
private FastFileStorageClient storageClient;
@Override
public String upload(String group,byte[] bytes, String fileName) {
String fileExtName = FilenameUtils.getExtension(fileName);
StorePath sp=storageClient.uploadFile(group, bytes, fileExtName);
return sp.getFullPath();
}
第四步:下载代码
@Autowired
private FastFileStorageClient storageClient;
@Override
public byte[] download(String group,String path) {
byte[] bytes=storageClient.downloadFile(group,path);
return bytes;
}
第五步:删除代码
@Autowired
private FastFileStorageClient storageClient;
@Override
public void delete(String path) {
storageClient.deleteFile(path);
}
6、网盘系统集成
第一步:首先在对应工程新建具体的类文件
utils-filestore (文件存储组件工程)
|-- com.micro.store.service
| |-- StoreService.java (定义一个接口)
|-- com.micro.store.service.impl
| |-- StoreServiceFastDFS.java (实现类)
| |-- StoreServiceHDFS.java (实现类)
|-- com.micro.store.context
| |-- StoreContext.java (策略类)
项目结构核心分析:
我们不能写死说只用 FastDFS 作为我们的分布式文件存储,如果万一哪天领导说要换成 HDFS、换成 TFS 呢?所以我们需要使用策略模式去把它做灵活了,底层怎么切换,都不会影响到我们上层业务。
那么,我们为什么把文件存储独立一个工程呢?为什么不在 Service 工程里面编写代码呢?文件存储这种是比较常用的功能,很多系统都会用的到的,那么我们尽量封装起来,哪个项目用到直接导入 jar 就能使用,而不是单纯的封装工具类。
第二步:集成(坐标)
在 netdisk-service-provider 工程的 pom.xml 导入坐标
<dependency>
<groupId>com.micro</groupId>
<artifactId>utils-filestore</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
第三步:策略模式的实现
思考:使用策略模式去调用底层的分布式文件系统,那么如何实现策略模式呢?
@Component
public class StoreContext{
@Autowire
private SpringContentUtils springContentUtils;
@NacosValue("${uploadtype}")
private String uploadtype; //核心
//上传
public String upload(String group,byte[] bytes,String fileName){
//核心,根据uploadtype去Spring容器查询具体实现类
Object obj=springContentUtils.getBean(uploadtype);
if(obj!=null){
StoreService storeService=(StoreService)obj;
storeService.upload(group,bytes,fileName);
}
}
//其他接口省略了
}
把
上传类型
的标识放到 Nacos 配置中心,这样的话我们切换底层,只需要在 Nacos 后台修改,项目都不用启动,非常的灵活。
第四步:策略类的调用
@Component
public class FileServiceImpl implements FileService{
@Autowire
private StoreContext storeContext;
public void upload(String group,byte[] bytes,String fileName){
storeContext.upload(group,bytes,fileName);
}
}
7、小结
本章节内容还是比较核心的,主要讲解了不用分布式文件系统所存在的缺点(重点理解)、主流分布式文件系统的比较、FastDFS 的原理、安装、使用、以及最后使用策略模式集成 FastDFS;大家尽量按照我上面的步骤搭建一遍 FastDFS,相对来说 FastDFS 的安装会比其他软安装复杂很多;
纸上得来终觉浅,绝知此事要coding...
