




“ 当你做成功一件事,千万不要等待着享受荣誉,应该再做那些需要的事。—— 巴斯德”

1. 业务需求
需要实现文件下载功能,但是不仅限于传统的文件下载,还需要满足以下特性的下载:
由于文件是切块进行存储的,如何下载的时候变成一个完整的文件?
不仅可以下载单个文件,还要支持多个文件 / 夹下载,比如:同时勾选多个文件下载、勾选多个文件夹下载等等
要保证超大文件的下载不会导致内存溢出
本节内容主要是设计和实现满足以上三点需求的下载功能
效果图如下所示
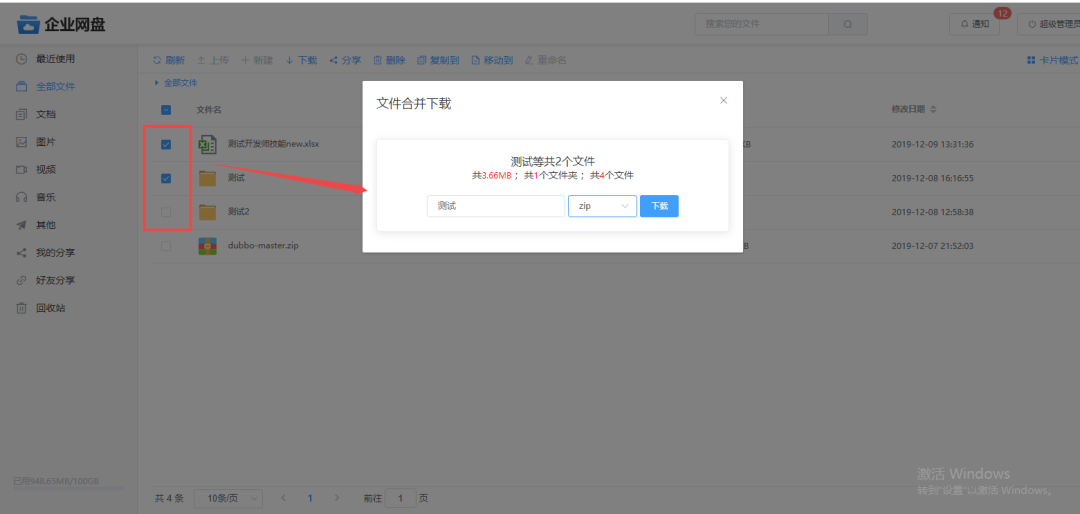
2. 功能设计
2.1 基本知识了解
首先,我们都知道如果传统的下载实现方式,如果是超大文件的下载肯定是会内存溢出的,所以我们才需要进行下载功能的改进。
知识 1:简单了解文件下载的原理
要想了解文件下载的原理,我们得先来了解 Http 协议,Http 协议是我们用的最多的一种协议,也是做 Java Web 开发使用的协议,但是 Java 的 Servlet 的底层帮我们做了封装,不需要手工的解析 Http 协议,因此我们很少去了解其原理。Http 协议其实就是一种规则,客户端按照这种规则去编码数据,通过网络传输到服务端,服务端再按这种规则去解码数据。如果了解过 Netty 的同学应该比较清楚,基于 Netty 通讯框架,我们可以自定义自己的协议(私有协议),而 Http 它是一种公有协议。
下载的时候,Java 后台需要做两个操作
把文件的字节流(byte [])放到响应体里面;
在响应头告诉浏览器用什么方式打开文件,浏览器收到协议之后,按标准去解码协议,然后做出处理。
其实,浏览器自己也会有一套默认的规则,比如:你在浏览器直接访问某个文件,如果是图片、pdf 等它自己会在页面打开,如果是 doc 等它则会提示下载。原因是:服务器通过 MIME 告知响应内容类型,而浏览器则通过 MIME 类型来确定如何处理文档。
静态文件下载示例:
//1.静态文件的位置
project
src/main/java
src/main/resources
static
test.doc
//2.在浏览器直接访问静态文件,进行文件下载
http://192.168.1.8:8080/project-name/test.doc
//3.下载原因说明
1)Tomcat自动帮我们读取该文件,并且通过输出流给写回浏览器
2)因为'doc'=>'application/msword',所以该类型浏览器自动下载
知识 2:网络 IO 和 磁盘 IO 的了解
其实无论 网络 IO 和 磁盘 IO,你只需要把它当做一条河流,河流它必然有源头和流向,其实 IO 也是一样。当读取文件流的时候,是读取本地磁盘的文件呢?还是读取客户端传递过来的文件呢?当写文件的时候,是写到本地磁盘呢?还是通过网络写到客户端呢?
读取 IO 示例:
//读取磁盘IO
@Test
public void readFileIO() throws Exception{
FileInputStream is=new FileInputStream("E:/测试IO.txt"); //从磁盘获取IO
byte[] bytes=new byte[is.available()];
is.read(bytes);
String str=new String(bytes,"GBK");
System.out.println("输出结果:"+str);
}
//输出结果:大家好,我是本地IO
//读取网络IO
public static void main(String[] args) throws IOException{
ServerSocket server=new ServerSocket(8080);
Socket client=server.accept();
InputStream is=client.getInputStream(); //从网络获取IO
byte[] bytes=new byte[is.available()];
is.read(bytes);
String msg=new String(bytes,"UTF-8");
System.out.println("输出结果:"+msg);
}
//浏览器输入:http://127.0.0.1:8080查看输出结果
写出 IO 示例:
//写到磁盘IO
@Test
public void readFileIO() throws Exception{
FileInputStream is=new FileInputStream("E:/测试IO.txt");
byte[] bytes=new byte[is.available()];
is.read(bytes);
//输出到磁盘
OutputStream out=new FileOutputStream("E:/测试IO2.txt"); //输出到磁盘IO
out.write(bytes);
}
//写到网络IO
public static void main(String[] args) throws IOException{
ServerSocket server=new ServerSocket(8080);
Socket client=server.accept();
InputStream is=client.getInputStream();
byte[] bytes=new byte[is.available()];
is.read(bytes);
String msg=new String(bytes,"UTF-8");
System.out.println("输出:"+msg);
OutputStream out=client.getOutputStream(); //输出到网络当中
out.write("你好".getBytes());
}
通过上面案例解说,目的就是让大家知道,其实文件下载就是普通的文件流输出,跟我们平时做磁盘 IO 输出没啥区别,只不过它是网络 IO 而已。除此之外,我们还需要了解一下 Http 协议,因为把文件流输出到网络当中,我们还要通过协议告诉浏览器使用什么方式打开,仅此而已。
通过以上两个小知识点,我相信大家应该能对我们本节的需求有一定的思路。
2.2 流程分析
通过上面的了解,我们知道了文件下载是怎么回事,但是我们的需求是要比普通的文件下载要复杂的,那么复杂在哪里呢?
第一:我们的文件是切块,而不是完整的文件,那么如何下载的时候变成完整的文件?
第二:如何同时下载多个文件呢?采用什么方式下载?
问题 1:如何让切块最后变成完整文件进行下载呢?说说我的想法
方案一:服务端合并完整文件
思路:服务器端把切块按序号由小到大进行排序,并且按顺序输出到服务器临时目录(自动合并一个完整文件),然后再把该文件返回浏览器。
缺点:但是这种模式的缺点非常的明显,如果合并之后的文件非常的大,那么将导致内存溢出。
方案二:客户端合并完整文件
思路:服务器端把切块按序号由小到大进行排序,并且输出到网络当中,所有的切块输出共用一个输出流,浏览器自动合并。
优点:把文件的合并交由客户端进行处理,减轻了服务端的压力
举例说明:如果这里感觉有点抽象的话,举个比较形象的例子:
OutputStream out=client.getOutputStream();
当做是新修一条单向铁路,每个切块是火车的具体车厢,一辆完整的火车由很多车厢组成。只不过是现在把车厢拆开独立开往目的地,等所有的车厢都达到终点,则把铁路拆除,此时终点站的车厢依然是排成一列完整的火车。但是如果每个切块独立创建一个OutputStream out=client.getOutputStream();
,那么就好比每个车厢独立一条铁路,最后终点站就无法组成一辆完整的火车了,而是并排的车厢。
示例代码如下所示:
//第一步:根据md5获取切块信息集合(按切块排序)
List<String> urls=filePreviewService.getChunksByFilemd5(filemd5);
//第二步:获取输出流(分别是两种模式的IO)
//OutputStream out=new FileOutoutStream("E:/name.txt");//磁盘IO
OutputStream out=response.getOutoutStream();//网络IO
//第三步:遍历集合
for(String url:urls){
//1.根据路径去文件系统获取切块的字节流
byte[] bytes=filePreviewService.getBytesByUrl(url);
//2.输出字节流
out.write(bytes);
}
//第四步:关闭输出流
out.close();
问题 2:同一个下载请求如何同时下载多个文件呢?
其实浏览器是无法一次请求下载多个文件的,大家应该都是知道,浏览器下载的时候,会弹出一个确认框让你选择保存到本地那个目录,并且指定名称,因此是无法多个的。那么是否可以多个文件共用一个输出流呢?如果共用的话,那么这些文件最终被合并成一个独立文件了。下面说说我的思路是什么样的。
方案一:压缩下载
思路:在服务器端把文件分别按照对应的切块合并成独立的文件;再把这些独立的文件最终压缩成一个完整的压缩包;客户下载压缩包之后,解压之后自然保留完整的目录结构。但是注意的是,如果最终合并的压缩包很大,则将会导致内存溢出。
优点:是 b/s 架构下目前很好的思路了,如果谁有更好的方案可以留言讨论
缺点:
浏览器其实也是一个 c/s 架构的客户端,但是不像自定义 c/s 客户端那样可控制。
如何多个文件压缩之后还是很大,那么不适合这种模式
方案二:c/s 客户端下载
思路:使用 Java Swing(当然也可以使用 c++、c#)开发客户端桌面程序,下载多个文件时,客户端分别发起多次来获取文件字节流,然后保存到客户端本地
优点:无论是客户端还是服务端的压力都很小,性能很高
缺点:对应没有接触过 c/s 架构的同学来说技术难点稍微高一点
最后的方案,下载之前判断下载的文件大小,如果大于我们设置的阈值,则提示使用 c/s 版本的网盘客户端进行下载;如果小于阈值则压缩成一个独立的包进行下载。
分析到这里,相信大家应该都能理解了吧,我们这里重点介绍的是压缩包下载模式
,c/s 架构则不讲解。
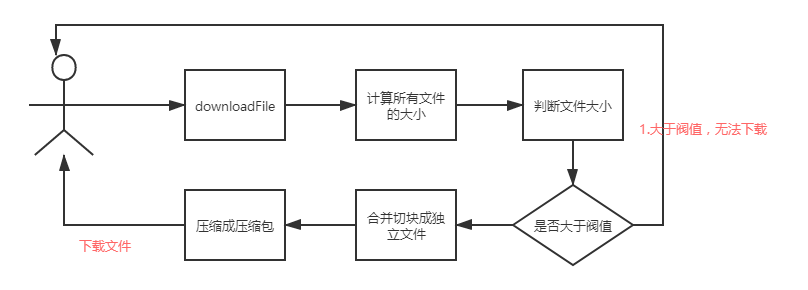
上面的图是压缩包模式下载的完整流程图,但是如果一个方法实现完整个流程,则将会非常的复杂,甚至请求超时,因此需要拆分成以下几个步骤。
第一次请求:计算文件的总大小和判断是否超过阈值
第二次请求:合并切块、压缩文件;并且把压缩包的完整下载路径给返回客户端
第三次请求:根据压缩包的下载路径,发起下载请求
3. 小结
本节内容主要讲解 Http 协议的大概原理、磁盘 IO 和网络 IO、以及文件下载的核心思路,希望大概能够掌握。
纸上得来终觉浅,绝知此事要coding...
