




“ 人要有毅力,否则将一事无成。——居里夫人”

1、业务需求
主要实现文件全文检索功能,看起来功能虽然简单,但是需要满足以下要求:
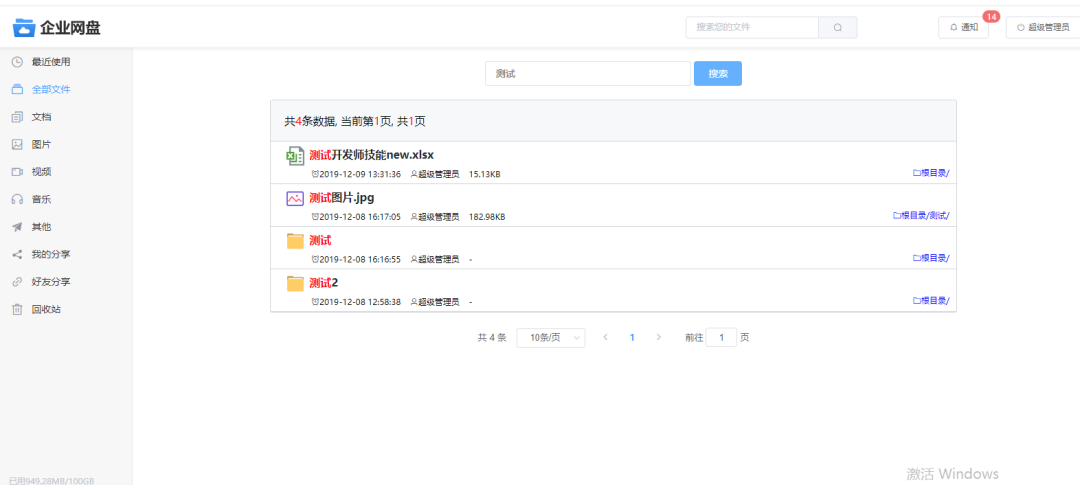
第一:搜索关键字高亮显示,不光是搜索关键字高亮,含有其中的部分关键字也需要高亮显示。
第二:模糊匹配,比如:搜索
张三你好
,那么可以匹配含有张三
的记录;也匹配含有你好
的记录;第三:最核心的是性能问题,支持海量数据的高性能搜索
项目效果图如下:
2、功能的设计
其实,全文检索这个没啥好说的,做个稍微大点的项目可能都会接触过这方面的需求,用过类似的框架。或许很多同学做搜索功能还是习惯于传统的 sql 语句搜索,虽然也能实现模糊搜索,但是大型项目中这种模式的弊端就会显示出来。
第一:like 查询,则索引失效。什么是索引查询?就好比一本新华词典的目录,我们查询某个汉字的时候,首先去目录查询到其所在页数,然后再去具体页数查询即可,这样的效率是很快。如果是 like 查询,它就会去把整本新华词典从第一页开始翻到最后一页,一一匹配把所有符合要求的记录查询出来,这种模式的查询性能非常的低。
第二:like 查询基本上都是拼接字符串的,很容易出现sql漏洞攻击问题。
第三:MySQL 压力过大,我们都知道,MySQL 的压力往往都是读的压力比写的压力要大,因此需要做 MySQL 的读写分离。如果在海量数据、高并发情况下,使用 like 查询,则 MySQL 根本吃不消。
因此,我们一般都是采用全文检索方面的 Nosql 数据库去代替传统 sql 查询。常见的框架主要有 Solr 和 ElasticSearch 这两个开源框架,它们底层都是基于 Lucene 来实现的。
使用全文检索框架的优势如下:
全文检索框架能很好的解决 like 性能很低的问题,它使用
倒排索引
思想快速提升搜索性能支持高亮显示,提高用户体验
独立的文档库,彻底解耦 MySQL 数据库,把搜索压力从 MySQL 转移到了全文检索库
有成熟的集群解决方案,支持海量数据的分片存储
下面,我们简单对比一下 Solr 和 ElasticSearch 两款开源框架。
单纯的对数据进行搜索的时候,Solr 比 ElasticSearch 更加的快
当实时建立索引的时候,Solr 会产生 IO 堵塞,查询性能较差,ElasticSearch 具有明显的性能优势
随着数据量的增大,Solr 的搜索效率会变的更低,而 ElasticSearch 却没有明显变化
Solr 的架构不适合实时搜索的应用
Solr 在传统的搜索应用中表现好于 ElasticSearch,但在处理实时搜索应用时效率明显低于 ElasticSearch(所以ES适合做日志搜索和大数据的实时搜索)
Solr 支持更多格式的数据,比如 JSON、XML、CSV,而 ElasticSearch 仅支持json文件格式
应用场景:Solr 适合做单纯的搜索功能;ES 一般是大数据领域的实时搜索,它常见用于 ELK 日志分析系统。
其实光从使用角度来说,我觉得两款都差不多,但是 ElasticSearch 在 Linux 上安装的话,容易遇到坑,没有 Solr 安装相对简单。以下是 ElasticSearch 在 Linux下安装时常见的坑:
常见坑1,不支持 root 账号启动,如果你用 root 账号启动会发现报错
常见坑2,你启动的时候会发现报
vm.max_map_count常见坑3,你启动的时候会发现报
process is too low
3、Solr的快速入门
3.1、Solr的安装
先来了解 Solr 的目录结构
solr-5.5.5
|-- bin
| |-- solr //启动文件
|-- server
| |-- solr //存放solrcore,类似MySQL服务
| | |-- solrcore //solrcore,类似MySQL的具体实例
| | | |-- conf //存放配置文件(核心)
| | | |-- data //存放数据
| | | |-- core.properties
基本概念普及
Solr 相当于我们的 MySQL 服务
solrcore(4.x版本叫Collection)相当于 MySQL 的数据库(比如:netdisk网盘数据库),不同的业务创建不同的 solrcore
Solr 也需要像 MySQL 那样创建表字段(下面讲),它是 JSON 格式存储数据的
Solr 的安装详细步骤如下:
#1.上传安装包
solr-5.5.5.zip
#2.文件解压(或者windows解压好了,再上传)
yum -y unzip
zip solr-5.5.5.zip
#3.启动
cd solr-5.5.5/bin
./solr start
#4.创建solrcore
./solr create -c disk
#5.集成中文分词器
把ik-analyzer-solr5-5.x.jar放到solr-5.5.5/server/solr-webapp/webapp/WEB-INF/lib
#6.配置solrcore
cd solor-5.5.5/server/solr/disk/conf
vim managed-schema #加入以下内容
#7.重启
./solr stop -all #先停止
./solr start #再重启
在 managed-schema 配置业务字段(类似数据库字段),以下字段是网盘项目所需要的字段:
<!--IK分词器-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
<!--字段--->
<field name="filename" type="text_ik" indexed="true" stored="true"/>
<field name="pid" type="string" indexed="true" stored="true"/>
<field name="filemd5" type="string" indexed="true" stored="true"/>
<field name="filesize" type="string" indexed="true" stored="true"/>
<field name="typecode" type="string" indexed="true" stored="true"/>
<field name="filesuffix" type="string" indexed="true" stored="true"/>
<field name="fileicon" type="string" indexed="true" stored="true"/>
<field name="filetype" type="string" indexed="true" stored="true"/>
<field name="createuserid" type="string" indexed="true" stored="true"/>
<field name="createusername" type="string" indexed="true" stored="true"/>
<field name="createtime" type="string" indexed="true" stored="true"/>
<field name="pname" type="string" indexed="true" stored="true"/>
xml文件剖析
Solr 在该配置里面内置了好多类型(string,long,datetime等等)(自己在配置文件里面慢慢找即可)
Solr 在该配置里面内置了 id 这个 field,所以不用配置了(自己在配置文件里面慢慢找即可)
type 的讲解
long、string 等基本类型是不被分词的,text_* 开头的字段才会被分词。分词是指什么意思呢?回忆上面讲的倒排索引,就是 Solr 在
新增数据
和查询数据
,都会对数据进行分词新增数据,把记录往
Solr库
存储,同时对text_*
类型的字段进行切分,并且把切分的词组存储到索引库查询数据,会对查询关键字进行切分,并且把切分的词组分别去
索引库
查询,然后再去Solr库
查询,最后组装查询结果indexed的讲解
indexed=“true” 表示该字段可以作为搜索字段
indexed=“false” 表示该字段不可以作为搜索字段,即使你在代码里面指定作为查询条件也没有用
stored的讲解
stored=“true” 表示搜索返回数据时,该字段被返回
stored=“false” 表示搜索返回数据时,该字段不会被返回,即使Solr库中存在该字段(类似:select id,name from table_name)
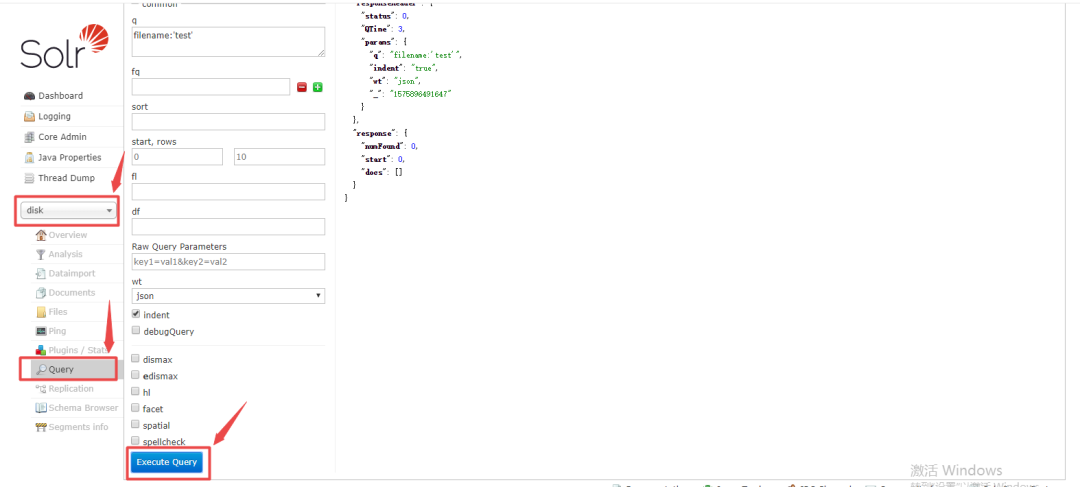
安装并启动完成之后,可以访问Solr的后台系统
http://ip:8983/solr
3.2、Solr的核心API
第一步:导入坐标
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-solr</artifactId>
</dependency>
第二步:配置文件
#disk是solrcore的名称
spring.data.solr.host=http://192.168.1.8:8983/solr/disk
第三步:新增
@Autowired
private SolrClient solrClient;
public void add(FileSearchBean bean) {
try{
SolrInputDocument document=new SolrInputDocument();
//注意:这里的字段和managed-schema配置的一致
document.addField("id",bean.getId());
document.addField("filename",bean.getFilename());
document.addField("pid",bean.getPid());
document.addField("pname", bean.getPname());
document.addField("filemd5",bean.getFilemd5());
document.addField("fileicon",bean.getFileicon());
document.addField("typecode",bean.getTypecode());
document.addField("filesuffix",bean.getFilesuffix());
document.addField("filesize",bean.getFilesize());
document.addField("filetype",bean.getFiletype());
document.addField("createuserid",bean.getCreateuserid());
document.addField("createusername",bean.getCreateusername());
document.addField("createtime",bean.getCreatetime());
solrClient.add(document);
solrClient.commit();
}catch(Exception e){
throw new RuntimeException(e.getMessage());
}
}
第四步:删除
@Autowired
private SolrClient solrClient;
public void delete(String id) {
try{
solrClient.deleteById(id);
solrClient.commit();
}catch(Exception e){
throw new RuntimeException(e.getMessage());
}
}
第五步:搜索
@Autowired
private SolrClient solrClient;
public Page<FileSearchBean> search(String filename,String userid, Integer page, Integer limit) {
Page<FileSearchBean> pageInfo=new Page<FileSearchBean>();
try{
//创建一个SolrQuery对象
SolrQuery query = new SolrQuery();
//条件
if(StringUtils.isEmpty(filename)){
query.setQuery("pid:0");
query.setFilterQueries("createuserid:"+userid+"");
}else{
query.setQuery("filename:"+filename+"");
query.setFilterQueries("createuserid:"+userid+"");
}
//分页
page=page==null?1:page;
limit=limit==null?10:limit;
int first=(page-1)*limit;
query.setStart(first);
query.setRows(limit);
//排序
query.setSort("createtime", SolrQuery.ORDER.desc);
//高亮
query.setHighlight(true);
query.addHighlightField("filename");
query.setHighlightSimplePre("<span style=\"color:red;\">");
query.setHighlightSimplePost("</span>");
//查询结果
QueryResponse response =solrClient.query(query);
//取查询结果
SolrDocumentList solrDocumentList = response.getResults();
//取查询结果总记录数
long count=solrDocumentList.getNumFound();
long pageCount=(count%limit==0)?(count/limit):(count/limit+1);
List<FileSearchBean> rows=getRows(solrDocumentList, response);
pageInfo.setPage(page);
pageInfo.setLimit(limit);
pageInfo.setRows(rows);
pageInfo.setTotalElements(count);
pageInfo.setTotalPage(pageCount);
pageInfo.setCode(0);
pageInfo.setMsg("查询成功");
return pageInfo;
}catch(Exception e){
pageInfo.setCode(1);
pageInfo.setMsg("查询失败");
}
return pageInfo;
}
public List<FileSearchBean> getRows(SolrDocumentList list,QueryResponse res){
List<FileSearchBean> rows=new ArrayList<FileSearchBean>();
Map<String, Map<String, List<String>>> highlighting = res.getHighlighting();
for (SolrDocument doc : list) {
String id=doc.get("id").toString();
String pid=doc.get("pid").toString();
String pname=doc.get("pname").toString();
String filemd5=doc.get("filemd5").toString();
String fileicon=doc.get("fileicon").toString();
String typecode=doc.get("typecode").toString();
String filesuffix=doc.get("filesuffix").toString();
String filesize=doc.get("filesize").toString();
String filetype=doc.get("filetype").toString();
String createuserid=doc.get("createuserid").toString();
String createusername=doc.get("createusername").toString();
String createtime=doc.get("createtime").toString();
//取高亮显示
List<String> list = highlighting.get(id).get("filename");
String title = "";
if (list != null && list.size() >0) {
title = list.get(0);
} else {
title = (String) solrDocument.get("filename");
}
FileSearchBean row=new FileSearchBean();
row.setId(id);
row.setFilename(title);
row.setPid(pid);
row.setPname(pname);
row.setFilemd5(filemd5);
row.setFileicon(fileicon);
row.setTypecode(typecode);
row.setFilesuffix(filesuffix);
row.setFilesize(filesize);
row.setFiletype(filetype);
row.setCreateuserid(createuserid);
row.setCreateusername(createusername);
row.setCreatetime(createtime);
rows.add(row);
}
return rows;
}
4、功能的实现
需求:网盘系统集成 Solr 中间件来做搜索功能,具体实现如下所示:
第一步:首先在对应工程新建具体的类文件
netdisk-web-perpc
|-- com.micro.controller
| |-- FileController.java //Controller类
netdisk-service-api
|-- com.micro.disk.service
| |-- SearchService.java //接口类
|-- com.micro.disk.bean
| |-- SearchBean.java
| |-- PageInfo.java
netdisk-service-provider
|-- com.micro.service.impl
| |-- SearchServiceImpl.java //接口实现类
utils-filesearch
|-- com.micro.search.service
| |-- FileSearchService //接口
|-- com.micro.search.service.impl
| |-- FileSearchSolrServiceImpl.java //Solr实现类
| |-- FileSearchEsServiceImpl.java //ES实现类
|-- com.micro.search.config
| |-- SearchContext.java //策略类
|-- com.micro.search.bean
| |-- FileSearchBean.java //实体类
项目结构核心分析:
为什么把文件搜索独立一个工程呢?
可以重复使用,全文搜索这种是比较常用的功能,很多系统都会用的到的,那么我们尽量封装起来,哪个项目用到直接导入 jar 就能使用,而不是单纯的封装工具类。
为什么需要使用策略模式呢?
问题:如果万一哪天领导说要换成 ElasticSearch 框架,那么就会大改代码
解决:①定义一个接口,多个实现类;②根据一定的策略选择调用不同的实现类
第二步:集成(坐标)
在 netdisk-service-provider 工程的 pom.xml 导入坐标
<dependency>
<groupId>com.micro</groupId>
<artifactId>utils-filesearch</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
第三步:策略类的实现
思考:使用策略模式去调用底层的全文检索框架,那么如何实现策略模式呢?
@Component
public class SearchContext{
@Autowire
private SpringContentUtils springContentUtils;
@NacosValue("${searchtype}")
private String searchtype; //核心
//新增
public String add(FileSearchBean bean){
//核心,根据searchtype去Spring容器查询具体实现类
Object obj=springContentUtils.getBean(searchtype);
if(obj!=null){
FileSearchService fileSearchService=(FileSearchService)obj;
fileSearchService.add(bean);
}
}
//删除
public String delete(String id){
//核心,根据searchtype去Spring容器查询具体实现类
Object obj=springContentUtils.getBean(searchtype);
if(obj!=null){
FileSearchService fileSearchService=(FileSearchService)obj;
fileSearchService.delete(id);
}
}
//其他接口省略了
}
把搜索类型的标识放到 Nacos 配置中心,这样的话我们切换底层,只需要在 Nacos 后台修改,项目都不用启动,非常的灵活。
这个策略模式和之前
FastDFS章节
、分布式锁章节
的原理是一样的
第四步:业务调用
@Component
public class SearchServiceImpl implements SearchService{
@Autowire
private SearchContext searchContext;
public void add(FileSearchBean bean){
searchContext.add(bean);
}
}
5、小结
本节内容主要讲解了传统 sql 查询的弊端;全文检索框架的好处以及 Solr 和 ES 的大概对比;Solr 的安装及使用;如何使用策略模式封装搜索组件。
纸上得来终觉浅,绝知此事要coding...
