





本文字数:8666;估计阅读时间:22 分钟
作者:Lionel Palacin
Meetup活动
ClickHouse 北京第三届 Meetup 火热报名中,详见文末海报!
实时 Tick(Tick)数据应用是实时分析的一个经典场景。类似于在 Web 应用中追踪用户行为或监控 IoT 设备产生的指标,这类系统需要对高频事件流进行低延迟的数据摄取、存储和查询。
在金融市场中,最大的不同在于其对时效性的极高要求。哪怕只有几秒钟的延迟,也可能让一次本可盈利的交易变成亏损。每一笔交易和每一次报价(quote)更新都会产生新的 Tick,而这些 Tick 在多个交易标的(symbol)中每秒可能高达数千条。
ClickHouse 非常适合这种类型的工作负载。它能够应对高频插入、基于时间范围的查询以及超低延迟的查询需求。即使针对每个交易标的存储数十亿行数据,内置的压缩能力也能有效降低存储成本。借助物化视图(Materialized View),可以在写入时对数据进行预聚合或重排,从而无需引入额外的处理层,就能显著优化查询性能。
本文将介绍如何使用 Polygon.io [https://polygon.io/] 获取市场数据,并利用 ClickHouse 实时存储和查询 Tick。后端将采用 NodeJS,前端使用 React 实现实时可视化。让我们一起深入探索吧。

在正式开始之前,先明确报价(quote)和交易(trade)的含义会更容易理解。报价指市场参与者当前愿意买入或卖出某只证券的价格,具体包括最高买入报价(即有人愿意支付的最高价)以及最低卖出报价(即有人愿意出售的最低价)。这些价格会随着新的订单进入或撤出市场而持续变化。

交易(trade)则是买方和卖方实际达成的成交行为。当有人接受当前的买入或卖出价格时,就会匹配成交,形成一个订单,并记录成交价格、交易数量和成交时间。

Tick 数据通常分成两个流:一个是报价更新流,另一个是交易执行流。这两种数据都对理解市场行为非常关键,但它们在分析和策略制定中的作用有所不同。
现在我们已经清楚要摄取的数据类型,接下来来看看如何获取这些数据。首先需要选择并注册一个股票市场 API,目前市面上有不少可选方案,我们在这个演示项目中使用了 Polygon.io。它的付费套餐提供无限次调用 API 的权限、实时数据访问能力以及对 WebSockets 的支持。
WebSockets 对于流式传输市场数据来说至关重要,它可以避免传统轮询 REST API 时产生的延迟和额外开销。相比每次请求都重新建立连接并可能在两次请求间错过 Tick,WebSockets 可以维持一个持续的连接,在数据一旦可用时就立即推送过来,这对于对毫秒级延迟要求极高的高频市场数据来说尤其关键。
使用 Polygon.io API 开始摄取数据的过程相当简单,只需要连接到 stocks 端点,使用你的 Polygon API key 完成身份验证,然后就可以开始处理数据消息。
下面提供一个使用 NodeJS 编写的示例代码片段。
this.authMsg = JSON.stringify({action: "auth",params: process.env.POLYGON_API_KEY,});this.ws = new WebSocket("wss://socket.polygon.io/stocks");this.ws.on("open", () => {console.log("WebSocket connected");this.isConnected = true;this.reconnectAttempts = 0;this.lastMessageTime = Date.now();this.connectionStartTime = Date.now();this.statusMessage = "Connected - Authenticating...";this.logConnectionEvent("connected");this.ws.send(this.authMsg);});this.ws.on("message", (data) => {if (!this.isPaused) {this.handleMessage(data);}});
在 ClickHouse 中对 Tick(Tick)数据建模
由于 Tick 数据只包含两种事件类型:交易(trade)和报价(quote),每种事件都有少量以数字类型为主的字段,因此建模相对比较简单。下面是为它们分别创建两个独立表的 DDL。
CREATE TABLE quotes(`sym` LowCardinality(String),`bx` UInt8,`bp` Float64,`bs` UInt64,`ax` UInt8,`ap` Float64,`as` UInt64,`c` UInt8,`i` Array(UInt8),`t` UInt64,`q` UInt64,`z` Enum8('NYSE' = 1, 'AMEX' = 2, 'Nasdaq' = 3),`inserted_at` UInt64 DEFAULT toUnixTimestamp64Milli(now64()))ORDER BY (sym, t - (t % 60000));CREATE TABLE trades(`sym` LowCardinality(String),`i` String,`x` UInt8,`p` Float64,`s` UInt64,`c` Array(UInt8),`t` UInt64,`q` UInt64,`z` Enum8('NYSE' = 1, 'AMEX' = 2, 'Nasdaq' = 3),`trfi` UInt64,`trft` UInt64,`inserted_at` UInt64 DEFAULT toUnixTimestamp64Milli(now64()))ORDER BY (sym, t - (t % 60000));
数据量增长会非常快。
举例来说,仅仅跟踪纳斯达克的交易每天就可能产生大约 5000 万条记录。为数据表选择一个高效的排序键对性能至关重要。在这里,我们首先按 symbol(股票代码)排序,把相同 symbol 的事件聚集在一起。在每个 symbol 的分组里,行按 t - (t % 60000) 排序,也就是按 1 分钟的时间桶分组。这种方式在我们的可视化场景中很适用,因为我们需要按 symbol 聚合数据生成图表。按分钟分组能提升时间范围过滤和聚合的效率。
数据写入策略
对于这类应用,可以设计多种数据摄取管道,比如借助 Kafka 等消息队列。但为了把延迟控制在最小,通常保持架构简单是最优解,也就是在可行的情况下,直接从 WebSocket 连接把数据推送到 ClickHouse。
完成这些配置后,下一步就是选择合适的写入方式。ClickHouse 同时支持同步和异步插入。
采用同步方式时,数据会在客户端先进行批处理再发送。批处理的大小需要在内存占用、延迟和系统负载之间取得平衡。大批量能减少插入次数并提高吞吐,但会增加内存占用并延后单条记录的入库。小批量可以降低内存压力,但可能因产生过多小数据块而给 ClickHouse 带来更大压力。
采用异步方式时,数据会持续流向 ClickHouse,并在 ClickHouse 端自动完成批处理。接收的记录会先写入内存缓冲区,然后根据可配置的阈值批量刷新到磁盘。如果客户端无法方便地做批处理,比如数据来源是多个小客户端,这种方式就非常合适。
在我们的示例中,同步写入是更优的方案。因为只有一个客户端通过 WebSocket API 推送数据,所以可以在客户端做批处理,以便更好地控制系统性能和资源利用。
下面给出一个 NodeJS 的示例代码片段,用于写入 ClickHouse。
handleMessage(data) {try {const trades = payload.filter((row) => row.ev === "T").map(({ ev, ...fields }) => fields);const quotes = payload.filter((row) => row.ev === "Q").map(({ ev, ...fields }) => fields);this.addToBatch(trades, "trades");this.addToBatch(quotes, "quotes");} catch (error) {console.error("Error handling message:", error);console.error("Message data:", data.toString().substring(0, 200));}addToBatch(rows, type) {if (rows.length === 0) return;const batch = type === "trades" ? this.tradesBatch : this.quotesBatch;batch.push(...rows);if (batch.length >= this.maxBatchSize) {this.flushBatch(type);}}flushBatch(type) {const batch = type === "trades" ? this.tradesBatch : this.quotesBatch;if (batch.length === 0) return;const dataToInsert = [...batch];if (type === "trades") {this.tradesBatch = [];} else {this.quotesBatch = [];}await this.client.insert({table: table,values: data,format: "JSONEachRow",});}
实时市场数据可视化
当数据写入 ClickHouse 后,搭建可视化层就相对容易了。真正的难点在于如何编写合适的 SQL 查询。下面我们来介绍如何实现,并重点解析支持两个核心可视化所需的查询。第一个可视化是一个实时更新的表格,用于持续展示某只股票的最新交易数据。
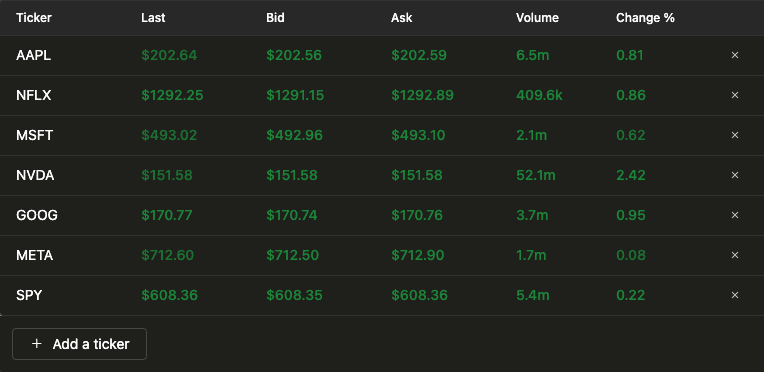
构建这个可视化只需要一个查询,借助 ClickHouse 强大的 SQL 查询语言以及自定义函数,就可以对数据完成格式化处理。
WITH{syms: Array(String)} as symbols,toDate(now('America/New_York')) AS curr_day,trades_info AS(SELECTsym,argMax(p, t) AS last_price,round(((last_price - argMinIf(p, t, fromUnixTimestamp64Milli(t, 'America/New_York') >= curr_day)) argMinIf(p, t, fromUnixTimestamp64Milli(t, 'America/New_York') >= curr_day)) * 100, 2) AS change_pct,sum(s) AS total_volume,max(t) AS latest_tFROM tradesWHERE (toDate(fromUnixTimestamp64Milli(t, 'America/New_York')) = curr_day) AND (sym IN (symbols))GROUP BY symORDER BY sym ASC),quotes_info AS(SELECTsym,argMax(bp, t) AS bid,argMax(ap, t) AS ask,max(t) AS latest_tFROM quotesWHERE (toDate(fromUnixTimestamp64Milli(t, 'America/New_York')) = curr_day) AND (sym IN (symbols))GROUP BY symORDER BY sym ASC)SELECTt.sym AS ticker,t.last_price AS last,q.bid AS bid,q.ask AS ask,t.change_pct AS change,t.total_volume AS volumeFROM trades_info AS tLEFT JOIN quotes_info AS q ON t.sym = q.sym;
下面来拆解一下这个查询的具体作用。
首先,它定义了两个变量:symbols,用于存储需要分析的股票代码列表,以及 curr_day,用于获取纽约时区的当前日期。
这个查询会拉取交易数据,包括:
last_price:使用 argMax(p, t) 获取最新时间戳上的成交价
change_pct:当日相对于开盘价的百分比变化
total_volume:当日总成交量
同时也会获取报价(quote)数据:
bid:使用 argMax(bp, t) 获取最新的买入价
ask:使用 argMax(ap, t) 获取最新的卖出价
最后,将交易数据和报价数据进行合并(join),得到最终的输出结果。

第二个可视化是一个蜡烛图(candlestick)图表,用来展示某只股票在一定时间范围内的价格变化趋势和成交量。
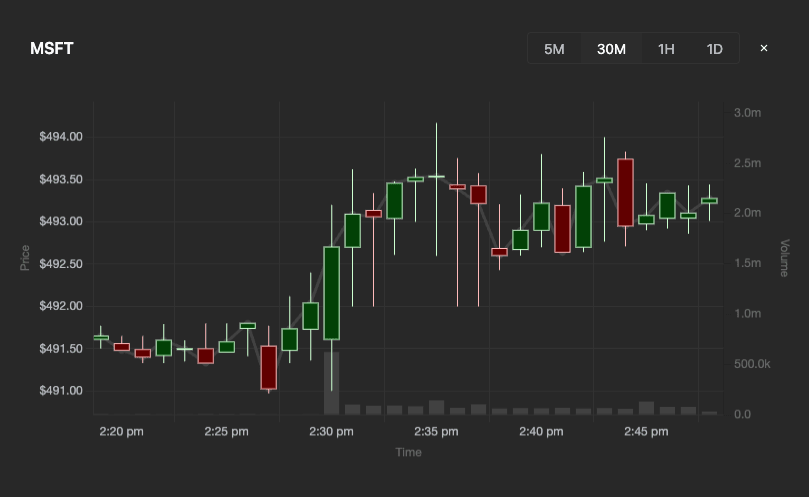
接下来看一下驱动该可视化的 SQL 查询。
SELECTtoUnixTimestamp64Milli(toDateTime64(toStartOfInterval(fromUnixTimestamp64Milli(t), interval 2 minute), 3)) as x,argMin(p, t) as o,max(p) as h,min(p) as l,argMax(p, t) as c,sum(s) as vFROM tradesWHERE x > toUnixTimestamp64Milli(now64() - interval 1 hour) AND sym = {sym: String}GROUP BY xORDER BY x ASC;
这个查询逻辑相对更简单,只需要在指定的时间窗口内计算交易量以及最高价、最低价。
在展示查询结果时,我们使用 click-ui 组件来渲染表格,使用 Chart.js 组件绘制蜡烛图可视化。
在生产环境中处理高频市场数据,光有一个快速的数据库远远不够。以下这些实用技巧和经验可以帮助你的系统在数据规模不断增长时,依然保持良好的性能和可靠性。
扩展数据摄取
当需要处理大量 symbol 的 Tick(Tick)级数据时,系统的持续吞吐量很容易达到每秒数万条记录。
要应对这种情况,可以考虑以下做法:
在客户端使用批处理,并根据系统的内存和延迟限制合理地选择插入批次的大小。 启用压缩功能:压缩后的插入数据会更小,能减少网络带宽消耗并加快传输速度。 监控 ClickHouse 中创建的数据分片(parts),防止出现过度合并的问题。虽然本文中重点讨论异步插入,但分片管理的思路同样适用于同步摄取。你还可以通过高级的可观测性(observability)仪表盘监控分片数量。 Polygon.io 也提供了一些高并发数据消费的性能优化建议。
监控摄取延迟
正如前面所提到,对于金融场景来说,越新的数据就越有价值,因此持续监控显得尤为重要。
你可以非常方便地计算并跟踪事件时间戳(Tick 发生的时间)与摄取时间戳(写入 ClickHouse 的时间)之间的时间差,这个“摄取延迟(ingest delay)”对于及时发现反压(backpressure)或性能瓶颈至关重要。
SELECTsym,count() AS trade_count,argMax(inserted_at, t) - argMax(t, t) AS ingest_latencyFROM tradesGROUP BY symORDER BY trade_count DESCLIMIT 100;
将这个指标可视化到仪表盘上,可以帮助你尽早识别潜在的性能下降。
利用物化视图(Materialized View)
如果想在数据到达时就完成预聚合,物化视图是非常好的选择。它能优化基于时间区间的聚合查询模式。比如对于金融数据,每隔 1 分钟计算一次 OHLCV(Open,High,Low,Close,Volume)指标。通过在写入时就完成聚合,你可以极大缩短查询响应时间,而不用每次都重新计算。
你需要先创建一个目标表(destination table),用来存放 1 分钟的 OHLCV 聚合结果。这个表会从物化视图接收数据输出,并提供结构化访问的能力。
-- Create destination tableCREATE TABLE trades_1min_ohlcv(`sym` LowCardinality(String),`z` Enum8('NYSE' = 1, 'AMEX' = 2, 'Nasdaq' = 3),`minute_bucket_ms` UInt64,`open_price_state` AggregateFunction(argMin, Float64, UInt64),`high_price_state` AggregateFunction(max, Float64),`low_price_state` AggregateFunction(min, Float64),`close_price_state` AggregateFunction(argMax, Float64, UInt64),`volume_state` AggregateFunction(sum, UInt64),`trade_count_state` AggregateFunction(count))ENGINE = SummingMergeTreeORDER BY (sym, minute_bucket_ms);
接下来就可以创建物化视图。
-- Create viewCREATE MATERIALIZED VIEW trades_1min_ohlcv_mv TO trades_1min_ohlcvAS SELECTsym,z,intDiv(t, 60000) * 60000 AS minute_bucket_ms,argMinState(p, t) AS open_price_state,maxState(p) AS high_price_state,minState(p) AS low_price_state,argMaxState(p, t) AS close_price_state,sumState(s) AS volume_state,countState() AS trade_count_stateFROM tradesGROUP BYsym,z,minute_bucket_ms;
当交易数据被插入 trades 表时,物化视图会自动进行处理,并更新目标表中对应的 1 分钟数据桶。
需要查看数据时,只要执行一条查询即可。
-- Query the tableSELECTsym,z,minute_bucket_ms,fromUnixTimestamp64Milli(minute_bucket_ms) as minute_timestamp,argMinMerge(open_price_state) AS open_price,maxMerge(high_price_state) AS high_price,minMerge(low_price_state) AS low_price,argMaxMerge(close_price_state) AS close_price,sumMerge(volume_state) AS volume,countMerge(trade_count_state) AS trade_countFROM trades_1min_ohlcvGROUP BY sym, z, minute_bucket_msORDER BY sym, z, minute_bucket_ms;
本文介绍了如何使用 Polygon.io 获取市场行情数据,并通过 ClickHouse 实现高速的写入和查询,构建一个实时 Tick 数据的应用。涵盖了如何流式传输并建模 Tick 数据、如何保证摄取性能,以及如何构建高效的查询和可视化能力。
在这个 Github 仓库中[https://github.com/ClickHouse/examples/tree/main/stock-data-demo],你可以找到一个结合 React 构建前端可视化层的完整示例。虽然这个示例相对简单,但相同的原理依然适用于搭建一个具备规模化生产能力的系统。

好消息:ClickHouse Beijing User Group第 3 届 Meetup 火热报名中,将于2025年09月20日在北京海淀永泰福朋喜来登酒店(北京市海淀区远大路25号1座)举行,扫码免费报名

/END/
试用阿里云 ClickHouse企业版
轻松节省30%云资源成本?阿里云数据库ClickHouse 云原生架构全新升级,首次购买ClickHouse企业版计算和存储资源组合,首月消费不超过99.58元(包含最大16CCU+450G OSS用量)了解详情:https://t.aliyun.com/Kz5Z0q9G


征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


