SQL语句中2个表进行Join操作,该2张表的关联列有一个为分布表的hash分布列或都不是hash分布列,并且关联方式为非等值关联,则GCluster将单表过滤条件过滤后结果集小的表拉成复制表的方式在各节点复制较小的表,然后再进行两表local join。举例说明:
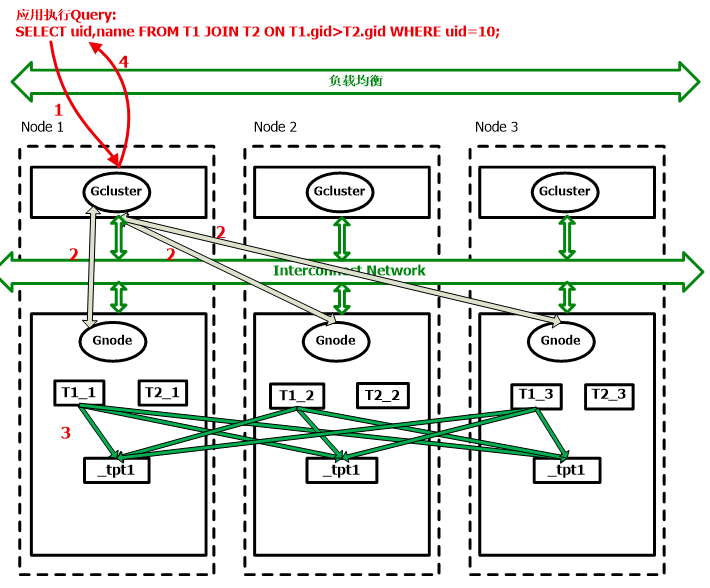
应用进行查询,查询语句为:SELECT uid,name FROM T1 JOIN T2 ON T1.gid>T2.gid WHERE uid=10;
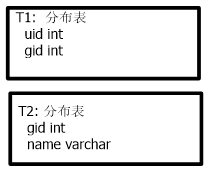
在数据库中的表结构为:
该查询在GBase 8a MPP Cluster执行步骤如下:
1、该查询通过GBase 8a MPP Cluster的接口层进行负载均衡后发送给Node1节点上的GCluster组件。
2、Node1节点上的GCluster组件接收到该SQL后,进行语法解析,GCluster组件判断出T1,T2表关联列没有hash分布列,并且不是等值关联,故GCluster组件需要把该SQL语句进行内部优化处理,处理过程如下:
1) GCluster根据T1,T2 表各自的单表条件进行评估结果集的大小, 把结果集较小的表(T1)的在各个节点上根据T1的表结构产生一个中间结果表_tpt1。表结构示意图如下:

2) GCluster通知各个节点中的GNode把T1单表条件过滤后的结果数据传输给3个节点的_tpt1表。
3) _tpt1表数据构建完毕后,GCluster生成GNode执行的SQL语句,发送给Node1,Node2,Node3的GNode组件的SQL语句如下:
Node1:
SELECT uid,name FROM _tpt1 JOIN T2_1 ON _tpt1.gid> T2_1.gid WHERE uid=10;
Node2:
SELECT uid,name FROM _tpt1 JOIN T2_2 ON _tpt1.gid>T2_2.gid WHERE uid=10;
Node3:
SELECT uid,name FROM _tpt1 JOIN T2_3 ON _tpt1.gid> T2_3.gid WHERE uid=10;
3、Node1,Node2,Node3节点上的GNode接收到SQL后,进行执行该查询。
4、 Node1,Node2,Node3节点上的GNode把查询结果返回给Node1节点的GCluster,由它负责把结果返回给应用。
查询计划示意如下: