




导读
在开源之夏 2025,李萧同学成功中选【为 NebulaGraph Exchange 实现插件化数据源】。他的项目申请书清晰且全面,与 mentor 沟通积极,虽然是第一次为开源项目实现 feature,但最终仅用了两周的时间顺利完成开发任务并合入。本期我们邀请李萧同学分享他在 NebulaGraph 社区的开源之旅,也为对开源项目感兴趣但迷茫的小伙伴们提供一些参考~

个人主页:
https://melodylx666.github.io/lx-bigdata/
为 NebulaGraph Exchange 实现插件化数据源,使 NebulaGraph Exchange 支持导入自定义数据源数据。
PR:
https://github.com/vesoft-inc/nebula-exchange/pull/209
文档:
https://docs.nebula-graph.com.cn/3.8.0/import-export/nebula-exchange/use-exchange/ex-ug-import-from-custom/
参与开源之夏 2025,在 NebulaGraph 社区做贡献,对我个⼈⽽⾔收获很多,我想将⼀些通⽤的开发思路分享出来,和⼤家⼀起交流进步。本⽂的核⼼内容主要分为择项原因、开发经验、项目收获三个部分。
一、择项原因
为什么选择 NebulaGraph 技术社区以及【为 NebulaGraph Exchange 增加插件化数据源】这⼀项⽬呢?
1. 对⽣态增强这⼀类型的项⽬感兴趣
很多⼈都⼗分向往数据库的开发,⽽传统的数据库内核开发对开发者要求很⾼,并且竞争激烈。于是我认为可以从其他⻆度切⼊:⼀个完整的数据库产品,内核研发并不是全部。⽣态增强(⽐如数据库导⼊导出)⼯具,对于开发者来说相对容易上⼿,⽽用户也往往更加⻘睐⼯具丰富的数据库产品。
上述思路不只可以⽤在开源之夏,在⽇常的实习求职⽅向上也可以借鉴。
2. 技术栈匹配
NebulaGraph Exchange 是⼀个完全由 Scala 编写的 Spark Application,⽽ Spark ⼜是我⽐较熟悉的计算引擎。所以从技术上来说开发的卡点会⽐较少。
3. 社区支持
因为本地开发环境的限制,想要完整跑通⼀个⼤数据类的项⽬是并不容易的。⽽ NebulaGraph Exchange 的社区资料⼗分完善,和导师的沟通交流也⼗分顺畅,使得我可以快速上⼿项⽬并验证想法。
二、开发经验
开发经验部分,我将其分为【需求理解】以及【功能开发】两个核⼼阶段,这也是上⼿所有项⽬的必经之路。
1. 需求理解
对需求的理解程度直接决定了后续开发的质量。看到需求描述,我们需要清楚对于开发者和用户来说,当前的痛点是什么。这部分值得多花⼀些时间来考虑清楚。可以⾃⼰总结完毕之后,和导师交流,后续的设计与开发就围绕确定下来的核⼼痛点展开。
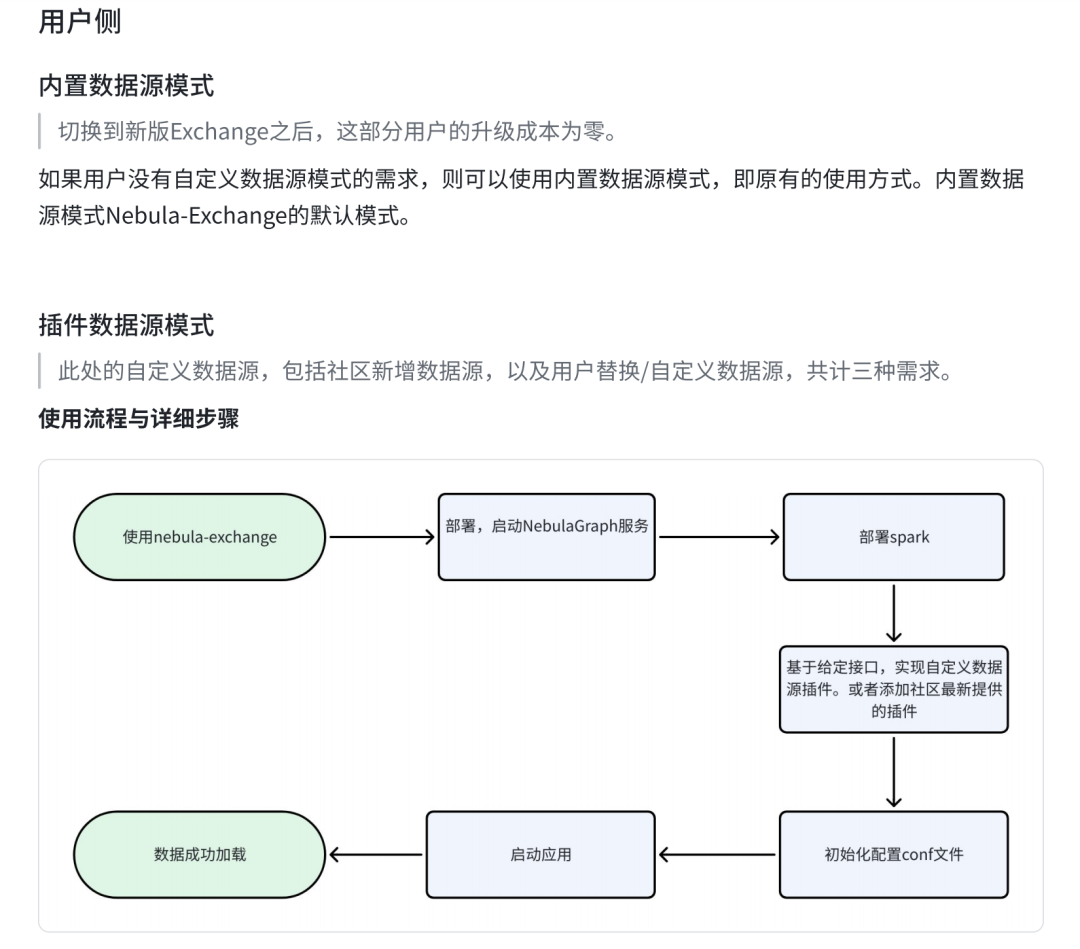
针对【为 NebulaGraph Exchange 实现数据源插件化】任务⽽⾔,可以发现原有的痛点如下:
对于开发侧,每增加或者修改⼀种新的数据源,都要对原有代码进⾏改动并重新发版,数据源维护成本较⾼。
对于用户侧,⽆法添加⾃定义数据源,以及修改现存数据源设计。
我个⼈的最初想法其实是将所有的数据源全部去除,统⼀使⽤插件 jar 包⽅式维护。⽽在和导师沟通之后,明确了可以将数据源划分为存量数据源和增量数据源,分别使⽤不同的数据源管理模式,这样在开发侧可以做到最⼩改动,⽽用户侧可以低成本升级。

(节选自李萧同学的项目申请书)
2. 功能开发
在开发任何功能的时候,都需要从以下三个⻆度来思考问题:
正确性:既要保证新增功能能够正确运⾏,⼜要保证不能影响原有功能。
⾼效性:在正确性基础之,上优化功能细节,提⾼运⾏效率。
易⽤性:在正确性基础之上,保证用户可以低成本上⼿。
这⼏点看上去像是“正确的废话”,但是在开发过程对于这⼏点的关注是不可或缺的。下⾯我会结合本次任务来具体说明。
正确性
最简单的⽅式就是通过“最⼩改动”的⽅式来添加新功能,也就是在需求理解部分提到的,将数据源进⾏类型划分,专注于⾃定义类型的数据源的引⼊即可。同时,由于 NebulaGraph Exchange 涉及到不同版本的 Scala & Spark,实现的时候就需要关注使⽤的语法是否在不同版本都可以通过编译和单元测试。
⾼效性
其实插件化数据源加载在本质上不会成为系统的性能瓶颈,因为它只是在 Tag/EdgeType 粒度上做的类加载,不过依旧需要明确插件的加载时机以及实现⽅式(是Scala object 还是 Java class)。
易⽤性
这点是⼗分关键的。为了让启动命令改动最⼩,在代码实现时抛弃了添加额外命令⾏参数,在内部实现了数据源模式的⾃动切换。同时,插件的形式,从开始繁杂的插件实例管理,到最后统⼀修改为了配置驱动的插件单例对象,用户对于插件实现的⾃由度更⾼。最后也输出了⼀份易于上⼿的用户⽂档,便于使⽤此功能。
三、项⽬收获
本次开源之夏的开发,令我印象最深的就是对于需求的充分理解永远需要排在⾸位。现在可供参考的优秀开源代码越来越多,⽽ AI Coding ⼯具也越来越强,代码开发变得越来越便捷。对于开发者来说,只有不断提升对需求的理解能⼒,才能让这些开发⼯具更好地为⾃⼰所⽤,提升⾃⼰的开发效率。
最后,感谢安祺导师,以及 NebulaGraph 社区运营⼩姐姐。在开发过程中,她们给了我很⼤帮助,让我在开源之夏的体验直接拉满~
星云仔有话说
每年开源之夏都有数百个开发项目,作为开源小白,如何选择适合自己的开源项目呢?
先“大海捞针”:1️⃣兴趣2️⃣技术栈3️⃣难度,兴趣永远是最好的老师,技术栈决定你是否有完成一个项目的基础能力,难度就不多说了~结合这三点,在开源之夏搜索关键字,至少能找到 3 个符合你条件的项目。
再“择优录取”:1️⃣完成这个项目能带给我什么?(从开发过程中我将得到哪些成长?对我以后想从事的 xx 岗位有帮助吗?)2️⃣这个项目所在社区是否活跃?这个社区的背景如何?3️⃣我当前的能力和时间,选择哪个项目能够出色的完成?结合这三点,再挑选一个最适合自己的项目。
跳出开源之夏,高校开发者如何选择第一个开源项目呢? NebulaGraph PMC Sherman 曾给出两点建议:一是与兴趣匹配,开源项目意味着技术的快速迭代与变革创新,开发者往往面临纷繁复杂的疑难问题,而兴趣是挑战困难的第一动力;二是与知识能力匹配,这不仅能提高学习和贡献的效率,还能在实践中稳步提升技能,逐步迈向更复杂的项目挑战。
最后,祝大家都能拥抱开源,享受开源~
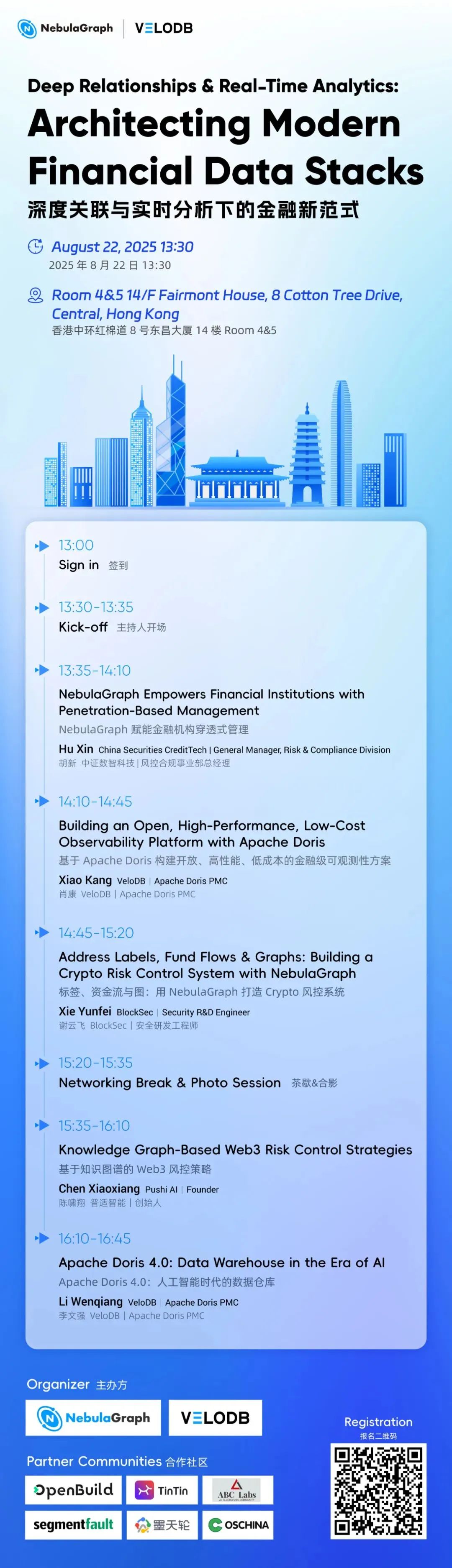
香港 nMeetUp 报名中🔥
✦
如果你觉得 NebulaGraph 能帮到你,或者你只是单纯支持开源精神,可以在 GitHub 上为 NebulaGraph 点个 Star!每一个 Star 都是对我们的支持和鼓励✨
https://github.com/vesoft-inc/nebula
✦
✦

扫码添加
可爱星云
技术交流
资料分享
NebulaGraph 用户案例
✦
风控场景:携程|Airwallex|众安保险|中国移动|Akulaku|邦盛科技|360数科|BOSS直聘|金蝶征信|快手|青藤云安全
平台建设:博睿数据|携程|众安科技|微信|OPPO|vivo|美团|百度爱番番|携程金融|普适智能|BIGO
✦
✦



