





小米通过将 Apache Doris(数据库)与 Apache Paimon(数据湖)深度融合,不仅解决了数据湖分析的性能瓶颈,更实现了 “1+1>2” 的协同效应。在这些实践下,小米在湖仓数据分析场景下获得了可观的业务收益。本文预览目录如下:
引言:现代数据架构中的 “割裂困境”
数据库与数据湖的互补之力
Apache Doris & Paimon 在小米的实践与挑战
总结与展望
作者|王龙,小米高级开发工程师
引言:现代数据架构中的 “割裂困境”
Apache Paimon 作为数据湖,核心优势体现在存储层:其开放格式(兼容 Spark、Flink、Trino 等多引擎)、基于对象存储(S3、HDFS)的 PB 级弹性扩展能力,以及对事务、Schema 演进的原生支持,使其成为海量异构数据的“统一存储基座”,兼顾低成本与兼容性。 Apache Doris 作为分析型数据库,核心优势体现在计算层:分布式并行引擎、向量化执行框架、以及针对复杂聚合场景的算子优化,使其能提供毫秒至秒级的低延迟查询响应,成为数据价值挖掘的“高效计算引擎”。
数据湖格式(如 Paimon)为适配多引擎读写与大规模存储场景,在设计上以通用性为优先,虽能满足跨引擎兼容需求,但在高频查询、复杂计算场景下,其通用格式的解析效率、IO 开销难以进一步优化; 而数据库(如 Doris)则拥有专为查询性能设计的 高效内部存储格式——例如基于列存的分层存储结构、自适应编码压缩算法(如字典编码、RLE 压缩)、原生索引(如前缀索引、 bloom filter)等,这些格式通过深度耦合计算引擎的执行逻辑,可最大限度减少数据扫描量与 IO 消耗,实现亚秒级查询响应。
海量冷数据、全量历史数据以 Paimon 格式存储于数据湖,保持低成本与多引擎兼容性; 高频访问的热数据、需复杂聚合的核心指标,则通过 Doris 的物化视图、本地缓存等机制,转换为 Doris 高效内部格式存储,借助其原生存储与计算的协同优化,实现极致查询性能。
通过元信息对 Paimon 数据进行分区、分桶裁剪和谓词下推,优化查询效率。 支持 Paimon Deletion Vector 读取,利用向量化 C++ 引擎加速 Paimon 更新数据的读取。 支持 Paimon 数据的本地文件缓存,充分利用本地高速磁盘提升热点数据的查询效率。 支持 Paimon 时间旅行、增量数据读取、Branch/Tag 数据读取,方便用户进行 Paimon 数据的多版本管理。 支持基于 Paimon 的物化视图,包括分区级别的增量物化视图构建,以及本文后续将要介绍的基于快照级别的增量构建,同时支持强一致的物化视图透明改写能力,将湖和仓的能力深度结合。 支持 Paimon Rest Catalog(DLF),方便云上用户接入 Paimon 生态,实现统一元数据管理。
多维度分析:支持高并发、低延迟的多维聚合分析(如用户行为、设备状态、运营监控等)。 多源接入:需要打通 Flink、Spark、Flink CDC 等流批框架的输入,覆盖离线、实时全链路数据处理场景。 统一数据访问:支持跨引擎、多格式的数据消费需求(如 Doris、Paimon、Iceberg 等)。 降低平台复杂度:减少技术栈分裂,统一数据建模与管控,提升数据平台运维效率。
存储多源异构,数据重复堆叠: 为满足不同业务对数据的不同时效性需求,需要按照分钟、小时、天级别的时效性要求,将数据存储在不同的数据系统中(Iceberg、Paimon、Druid、Doris),导致数据冗余、不一致等问题。 湖仓割裂,缺乏统一接口: 需要同时使用不同的引擎进行数据查询,(如 Presto、Druid、Doris、Spark 等)。各系统有独立的数据建模、运维和权限控制逻辑,平台治理成本高,入口不统一,使用方式不统一。
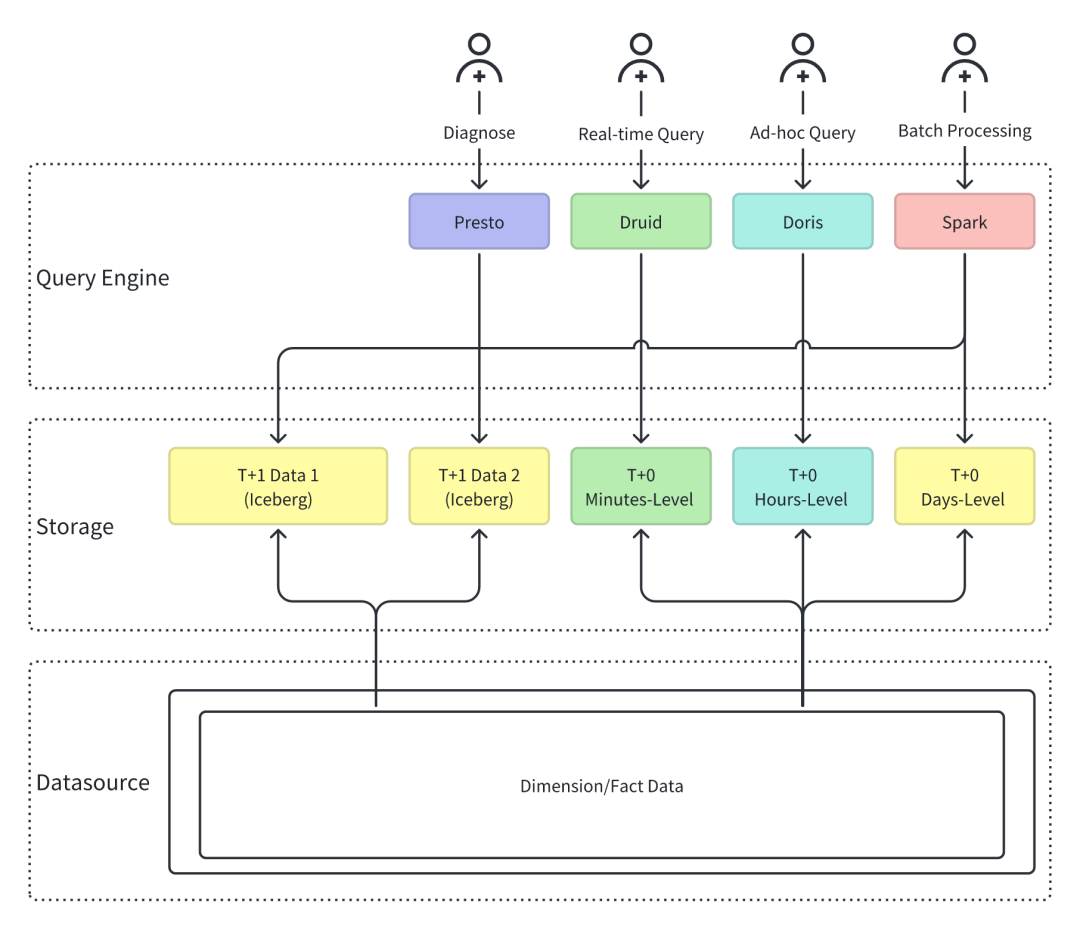
统一计算引擎:Apache Doris + Spark 采用 Doris + Spark 的计算引擎组合。Doris 负责实时数据和交互式数据分析,以及高并发查询场景。Spark 负责离线批处理场景。 统一数据湖存储:Apache Paimon 以 Apache Paimon 作为统一数据存储格式。Paimon 的设计非常适合流、批数据一体化存储。实现批流一体、湖仓一体的数据管理。
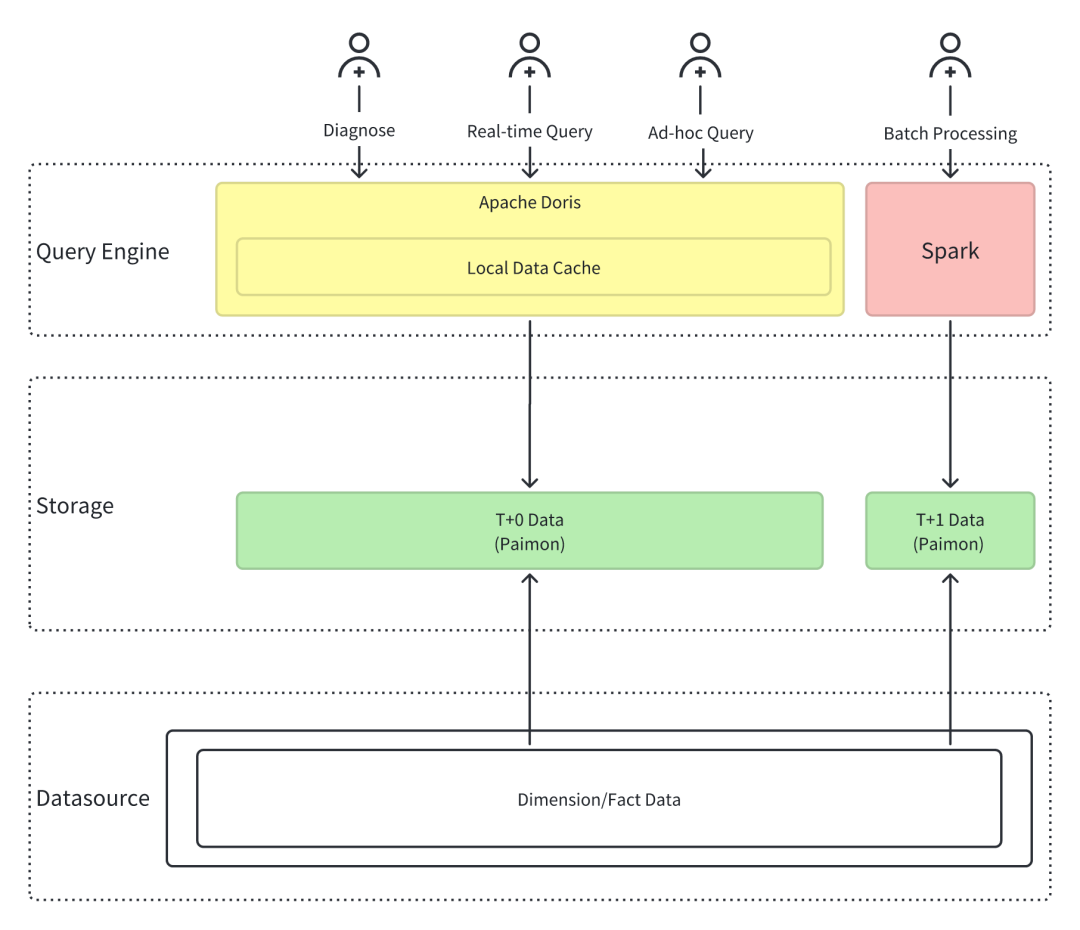
计算引擎:Presto、Druid、Doris、Spark -> Doris、Spark 存储格式:Iceberg、Paimon、Doris、Druid -> Doris、Paimon
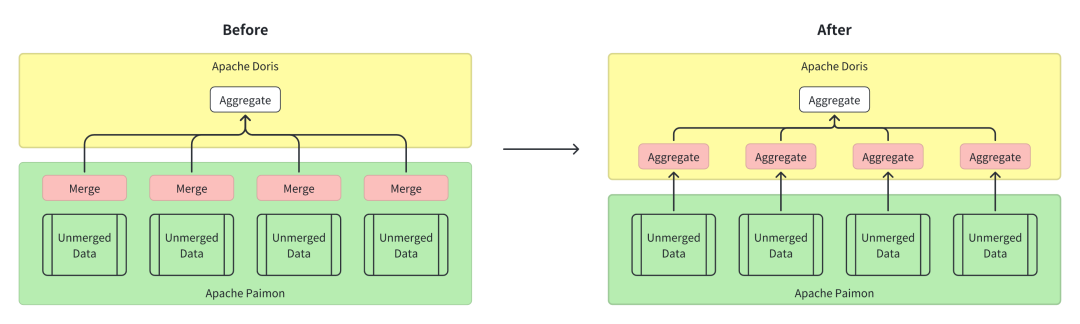
聚合性能不足:Doris 在读取 Paimon 的 Merge-on-Read 表时,受限于 Paimon SDK(Java)单线程处理多文件的排序与合并,在高并发场景下完全无法满足业务对 “秒级响应” 的需求。 物化视图更新代价高昂:分区级增量更新机制粒度在某些场景下可以满足用户的增量更新需求。但对于非分区表,或者单分区数据量较大的表,依然有较高的更新成本。 HDFS 读取延迟不稳定:HDFS 多副本读取时,默认 60 秒的超时阈值和网络抖动,导致查询延迟波动极大,业务方难以依赖数据结果快速做出决策。
放弃 JNI 调用 Paimon Java SDK 的方式,改用 Doris 原生 Parquet Reader 直接读取 Paimon 数据文件; 借助 Doris 的 Hash 算子实现分布式聚合(无需排序步骤),充分发挥 C++ 引擎的性能优势。
SELECT * FROM paimon_table@incr('startSnapshotId'='0', 'endSnapshotId'='5')
CREATE TABLE paimon_aggregate_table (
dt bigint,
k1 bigint
k2 string,
v1 int,
v2 double
)
USING paimon
PARTITIONED BY (dt)
TBLPROPERTIES (
'bucket' = '2',
'bucket-key' = 'k1,k2',
'fields.v1.aggregate-function' = 'sum',
'fields.v2.aggregate-function' = 'max',
'merge-engine' = 'aggregation',
'primary-key' = 'dt,k1,k2'
);
2、在 Doris 中创建对应的物化视图
CREATE MATERIALIZEDVIEW paimon_aggregate_table_mv
BUILDDEFERRED
REFRESH INCREMENTAL
PARTITIONBY (dt)
DISTRIBUTEDBY RANDOM BUCKETS 2
AS
SELECT dt, k1, SUM(a1) AS a1
FROM paimon_aggregate_table
GROUPBY dt, k1;
);
Doris 的异步物化视图框架会在后台定时执行如下语句:
INSERT INTO paimon_aggregate_table_mv
SELECT dt, k1, SUM(a1) AS a1
paimon_aggregate_table@INCR('startSnapshotId'='1', 'endSnapshotId'='2')
GROUP BY dt, k1;
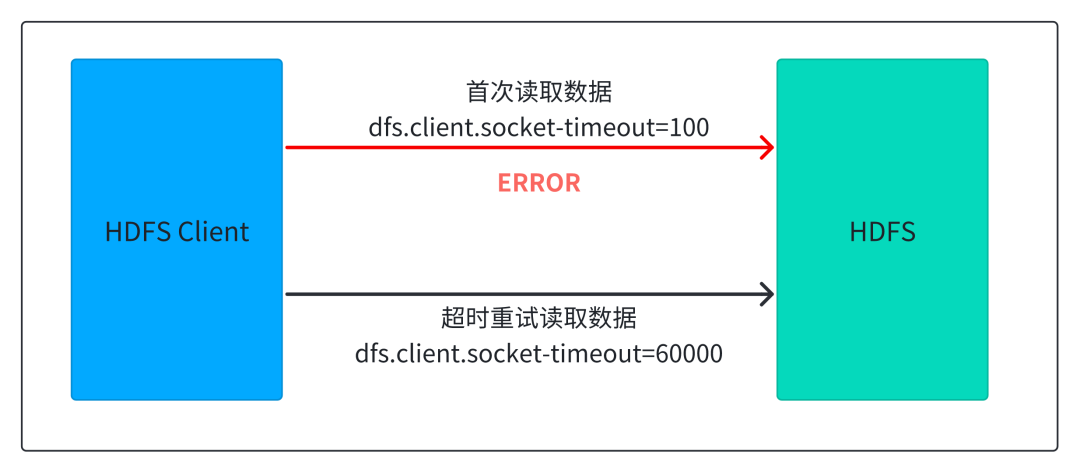
HDFS 快速超时与重试
dfs.client.socket-timeout控制,默认是 60 秒。这导致首次读取的超时时间过长,在 HDFS 抖动或负载较高的情况下,会导致查询延迟显著增加。我们通过将该阈值降低到 100 毫秒,让读取情况进行快速的超时重试,显著降低了查询长尾,P99 性能提升 1 倍,总体性能提升 10%。
Doris 数据缓存

查询平均延迟从 60 秒降至 10 秒,性能提升 6 倍; 高并发场景下(5 并发提高至 80 并发),查询延迟降低 25% 到 300%; 整体查询并发能力达到 Presto 的 5 倍,有效减少了计算资源。
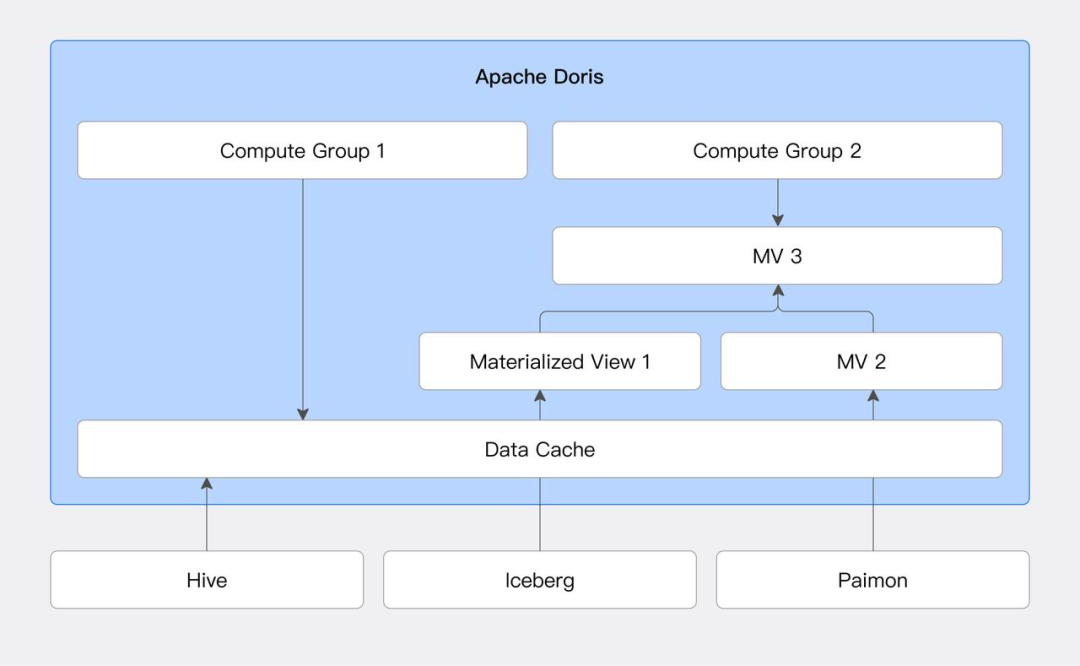
使用 Doris 全流量替换 Presto 集群实现降本增效。 进一步加强针对 Paimon、Iceberg 湖格式增量物化视图的能力。 Doris 湖仓架构容器化以满足更灵活的部署方式。 基于 Doris 的 Compute Group 虚拟计算组能力实现多业务间的资源隔离,提高资源利用率,降低维护成本。

- END -
更多标杆企业信赖
智慧金融与政企:东北证券|国金证券|国信证券|杭银消金|河北幸福消费金融|汇添富基金|金融壹账通|陆金所控股|霖梓控股|拉卡拉|平安人寿|奇富科技|同程数科|通联支付|无锡锡商银行|星云零售信贷|星火保|银联商务|易生支付|招商信诺人寿|招联金融|中信银行信用卡中心|360 数科|360 企业安全浏览器
互联网与文娱:菜鸟|抖音集团|斗鱼|叮咚买菜|浩瀚深度|京东|工商信息查询平台|货拉拉|快手|荔枝微课|票务平台|墨迹天气|MiniMax|奇安信|趣丸科技|顺丰科技|腾讯音乐|天眼查|网易|网易游戏|网易严选|网易云信|网易云音乐|小米|小鹅通|迅雷|约苗|字节跳动|知乎|360 商业化
企业服务与新经济:宝尊科技|Cisco|橙联|度言|观测云|慧策|快成物流|领健|领创|灵犀科技|名创优品|Moka BI|美联物业|钱大妈|拈花云科|森马 |思必驰|顺丰科技|上海家化 | 物易云通|云积互动|有赞|雨润集团|纵腾集团|中通快递
先进智造与电信:爱玛|长安汽车|极越汽车|金风科技|科大讯飞|Lifewit|哪吒科技|四川航空|上海通用五菱|三星电子|蜀海供应链|特步|天翼云|雅迪|中国联通

作为基于 Apache Doris 的商业化公司,飞轮科技秉承着 “开源技术创新”和“实时数仓服务”双轮驱动的战略,在投入资源大力参与 Apache Doris 社区研发和推广的同时,基于 Apache Doris 内核打造了聚焦于企业大数据实时分析需求的企业级产品 SelectDB ,面向新一代需求打造世界领先的实时分析能力。自 2022 年成立以来,获得 IDG 资本、红杉中国、襄禾资本等顶级 VC 的近 10 亿元融资,创下了近年来开源基础软件领域的新纪录。
