




指标、目标与协议
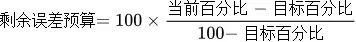
SLO指标选择
原则一 选择能够标识一个主体是否稳定的指标,如果不是这个主体本身的指标,或者不能标识主体稳定性的,就要排除在外。 原则二 针对有用户界面的业务系统,优先选择与用户体验强相关或用户可以明显感知的指标。
数据任务跑失败了,但是无法自动恢复,这时就要人工介入恢复;或者超时了,也需要人工介入,来中断任务、重启拉起来跑等等。
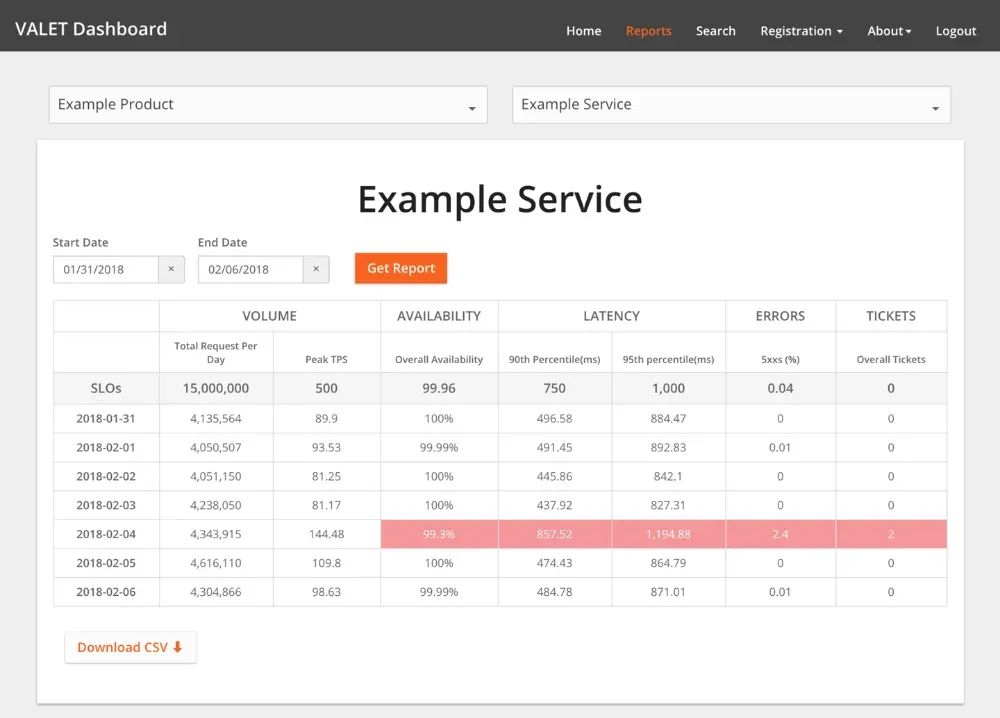
SLO计算
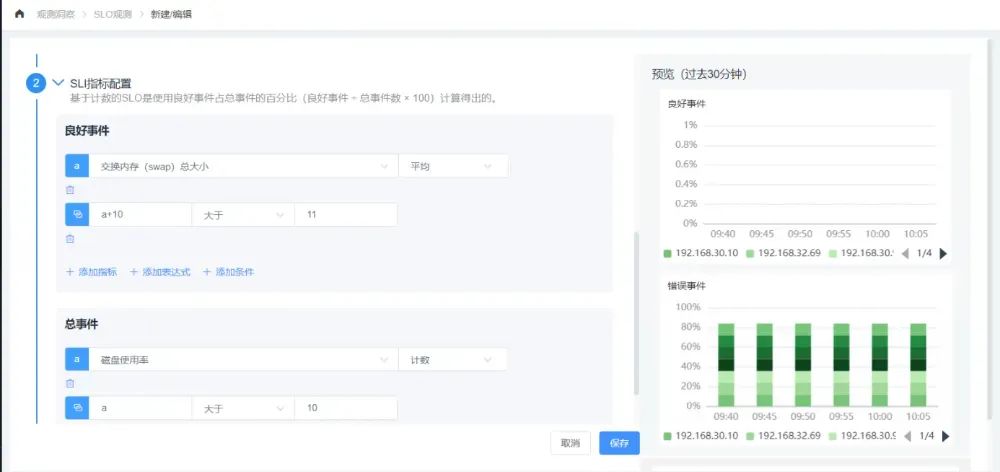
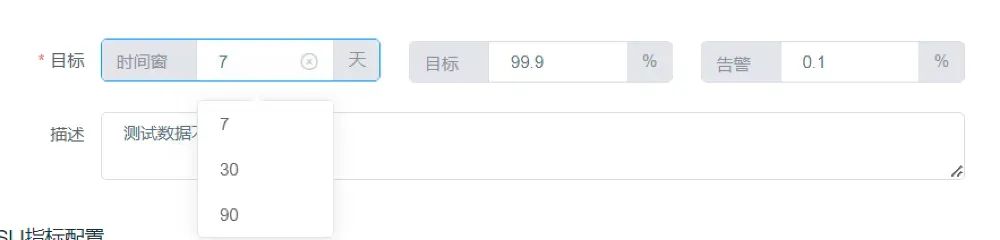
<前缀>_sli_good_events(良好事件数) 根据SLI指标配置的良好事件数的计算公式得出最终的值。 <前缀>_sli_total_events(总事件数) 根据SLI指标配置中的总事件数的计算公式得出最终的值。 <前缀>_sli_current_rate(当前百分比) 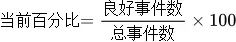
<前缀>_sli_error_budget_rate(错误预算)【不生成指标】 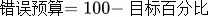
<前缀>_sli_error_budget_left(剩余错误预算) 
<前缀>_sli_burn_rate(燃烧率) 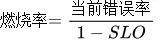
<前缀>_sli_error_budget_time (错误预算时间) 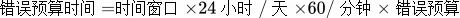
汇总间隔 每一分钟汇总一次。 汇总范围 集群中的全部任务。 度量频率 每10秒一次。 包含哪些请求 从黑盒监控任务发来的 HTTP GET请求。 数据如何获取 通过监控系统获取服务器端信息得到。 数据访问延迟 从收到请求到最后一个字节被发出。
SLO燃烧率
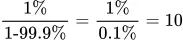
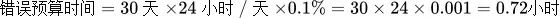
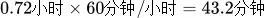
SLO展示
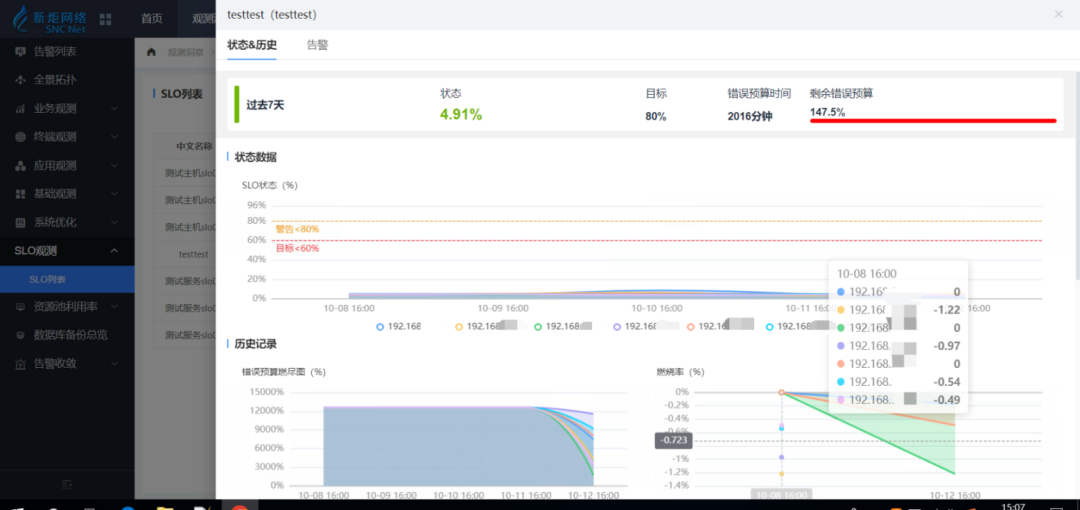
防止预期的停机时间(例如计划维护)耗尽您的错误预算; 忽略非工作时间,在这些时间里,你不需要遵守你的 SLO; 确保部署导致的临时问题不会对 SLO 产生负面影响。
本文作者:邸仁杰(上海新炬中北团队)
本文来源:“IT那活儿”公众号

文章转载自IT那活儿,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
