




今天接到开发同事反馈,使用CDC同步一张一千六百多万的MySQL大表数据到doris,结果发现数据缺失了10多万。。。
doris咱也是小白啊,不过遇到问题,咱也不慌,首先AI一下:
==============以下是AI答复=====================
将 MySQL 中的一张大表快速导入到 Doris,需要根据数据量、实时性要求、资源情况选择合适的方案。以下是一些主流且高效的导入方法,按推荐程度排序:
### 1. **使用 Doris 的 `Broker Load` (推荐用于初次全量迁移)**
这是处理大表**初次全量迁移**最推荐的方式,支持断点续传、原子性、错误容忍,并且对 MySQL 和 Doris 都是无侵入的。
**原理:** Doris BE 节点通过 Broker 进程访问外部存储(如 HDFS, S3, 或通过 MySQL ODBC/JDBC 的中间文件)读取数据并导入。
**步骤:**
1. **将 MySQL 数据导出为中间文件:**
* 使用 `mysqldump` 或 `SELECT INTO OUTFILE` 将大表数据导出为 CSV 或 Parquet 文件。
* **`mysqldump` 示例:**
```bash
mysqldump -h[mysql_host] -u[user] -p[password] [database] [table] --fields-terminated-by=',' --fields-escaped-by='\\' --fields-optionally-enclosed-by='"' --lines-terminated-by='\n' --no-create-info --complete-insert --skip-extended-insert > /path/to/data.csv
```
* **`SELECT INTO OUTFILE` 示例 (需要 MySQL 有写入权限):**
```sql
SELECT * FROM your_table
INTO OUTFILE '/tmp/mysql_data.csv'
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n';
```
* **关键:** 确保导出的字段分隔符、行分隔符、转义符与后续 Doris 建表语句和 Load 语句中的定义一致。
2. **将文件上传到 Doris BE 可访问的存储:**
* 将生成的 CSV/Parquet 文件上传到 HDFS、S3 或 NFS 等共享存储。
* 或者,如果 Broker 支持 JDBC/ODBC,可以配置直接读取 MySQL (较少用,性能可能不如先导出文件)。
3. **在 Doris 中创建对应的表:**
* 根据 MySQL 表结构在 Doris 中创建表。注意 Doris 的数据类型映射、分区(Partition)、分桶(Bucket)策略。合理的分桶数对性能至关重要。
* **示例:**
```sql
CREATE TABLE doris_table (
id BIGINT,
name VARCHAR(64),
create_time DATETIME
)
ENGINE=OLAP
DUPLICATE KEY(id)
PARTITION BY RANGE(create_time) (
PARTITION p202501 VALUES LESS THAN ("2025-02-01"),
PARTITION p202502 VALUES LESS THAN ("2025-03-01")
-- ... 根据时间范围划分
)
DISTRIBUTED BY HASH(id) BUCKETS 10 -- 根据数据量和查询模式调整 BUCKETS 数
PROPERTIES("replication_num" = "1");
```
4. **提交 Broker Load 任务:**
* 使用 `LOAD LABEL` 命令提交一个 Broker Load 作业。
* **示例 (导入 HDFS 上的 CSV):**
```sql
LOAD LABEL example_db.label1
(
DATA INFILE("hdfs://your-namenode:port/path/to/mysql_data.csv")
INTO TABLE doris_table
COLUMNS TERMINATED BY ","
(id, name, create_time)
)
WITH BROKER 'broker_name'
(
"username"="hdfs_user",
"password"="hdfs_password"
)
PROPERTIES
(
"timeout" = "3600",
"max_filter_ratio" = "0.1"
);
```
* **参数说明:**
* `LABEL`: 作业唯一标识,用于幂等性。
* `DATA INFILE`: 指定数据文件路径。
* `COLUMNS TERMINATED BY`: 指定分隔符。
* `WITH BROKER`: 指定 Broker 名称和连接信息。
* `PROPERTIES`: 设置超时时间、允许的错误行比例等。
5. **监控和管理 Load 作业:**
* 使用 `SHOW LOAD WHERE LABEL = "label1";` 查看作业状态(`PENDING`, `LOADING`, `FINISHED`, `CANCELLED`)。
* `Broker Load` 支持自动重试和错误处理。
**优点:** 异步执行,不阻塞 Doris 查询;支持大文件、断点续传;原子性;错误容忍度高。
**缺点:** 需要额外的中间存储;需要先将数据从 MySQL 导出。
### 2. **使用 `Stream Load` (适合流式或分批导入)**
如果数据可以分批导出,或者有实时写入的需求,`Stream Load` 是一个高效的选择。
**原理:** 客户端(如 curl, Java 程序)将数据通过 HTTP 协议直接推送到 Doris FE,由 FE 协调 BE 完成导入。
**步骤:**
1. **分批导出 MySQL 数据:**
* 使用 `LIMIT` 和 `OFFSET` 或基于主键/时间戳分页查询,将大表数据分成多个较小的批次。
* 将每批查询结果格式化为 CSV 或 JSON。
* **示例 (分页查询):**
```sql
-- 批次 1
SELECT * FROM your_table ORDER BY id LIMIT 1000000 OFFSET 0;
-- 批次 2
SELECT * FROM your_table ORDER BY id LIMIT 1000000 OFFSET 1000000;
-- ...
```
2. **使用 `curl` 或程序发起 Stream Load:**
* **`curl` 示例:**
```bash
# 假设数据在 stdin 或文件中
curl --location-trusted -u user:passwd -T /path/to/batch_data.csv -H "label:stream_load_label_1" -H "column_separator:," http://doris_fe_host:http_port/api/your_db/doris_table/_stream_load
```
* **参数说明:**
* `-u`: Doris 用户名密码。
* `-T`: 指定数据文件。
* `-H "label"`: 作业标签,保证幂等。
* `-H "column_separator"`: 指定列分隔符。
* URL: `http://<fe_host>:<http_port>/api/<db>/<table>/_stream_load`
3. **编写脚本自动化:**
* 编写 Shell/Python 脚本,循环执行分页查询、数据导出、发起 `Stream Load` 请求。
**优点:** 吞吐量高;实现相对简单;可以结合程序灵活控制。
**缺点:** 需要客户端程序或脚本管理;需要处理分页逻辑;如果单次导入数据量过大,可能影响 Doris 性能。
### 3. **使用 `INSERT INTO ... SELECT FROM MySQL` (最简单,但性能有限)**
Doris 支持直接从 MySQL 外部表查询数据并插入。
**步骤:**
1. **在 Doris 中创建 MySQL 外部表:**
```sql
CREATE EXTERNAL TABLE mysql_external_table
(
id BIGINT,
name VARCHAR(64),
create_time DATETIME
)
ENGINE=MYSQL
PROPERTIES
(
"host" = "mysql_host",
"port" = "3306",
"user" = "mysql_user",
"password" = "mysql_password",
"database" = "your_database",
"table" = "your_table"
);
```
2. **执行 `INSERT INTO SELECT`:**
```sql
INSERT INTO doris_table SELECT * FROM mysql_external_table;
```
**优点:** 操作极其简单,无需中间步骤。
**缺点:**
* **性能差:** Doris FE 会发起对 MySQL 的查询,数据通过 FE 传输,对于大表非常慢,容易成为瓶颈。
* **资源消耗:** 大量数据经过 FE,可能影响 FE 稳定性。
* **不适用于超大表:** 仅适用于数据量较小的场景。
### 4. **使用数据集成工具 (如 Flink CDC, DataX)**
对于需要**持续同步**或更复杂 ETL 场景,使用专业工具是更好的选择。
* **Flink CDC + Doris Connector:**
* 实时捕获 MySQL 的 Binlog 变更,实时写入 Doris。
* 适合需要近实时同步的场景。
* 可以先做一次全量同步,再开启增量同步。
* **DataX:**
* 阿里开源的离线数据同步工具。
* 提供 `mysqlreader` 和 `doriswriter` 插件。
* 配置 JSON 任务即可完成同步,支持并发读取 MySQL 分片。
* 适合离线批量迁移。
### **关键优化建议**
1. **Doris 表设计:**
* **分桶 (Buckets):** 根据数据量和查询模式设置合适的分桶数(通常建议 10-100 个)。避免数据倾斜。
* **分区 (Partition):** 对大表按时间等维度分区,便于管理、查询和删除历史数据。
* **数据模型:** 选择合适的数据模型 (`DUPLICATE KEY`, `AGGREGATE KEY`, `UNIQUE KEY`)。
* **索引:** 合理使用前缀索引、Bloom Filter 等。
2. **导入参数调优:**
* **`Broker Load` / `Stream Load`:** 调整 `max_filter_ratio` (允许的错误行比例), `timeout`, `max_batch_rows`/`max_batch_size` (影响内存和性能)。
* **并发:** 对于 `Stream Load` 或 `DataX`,可以开启多个并发任务导入不同分片的数据。
3. **资源保障:**
* 确保 Doris BE 节点有足够的内存、CPU 和磁盘 IO。
* 确保网络带宽充足,特别是数据传输路径(MySQL -> 中间存储 -> Doris 或 客户端 -> Doris)。
4. **数据一致性:**
* 使用 `Broker Load` 的 Label 机制保证幂等性。
* 导入完成后进行数据量校验。
### **总结**
* **初次全量迁移大表:** 首选 **`Broker Load`** (先将数据导出到 HDFS/S3 再导入)。
* **分批或流式导入:** 使用 **`Stream Load`** (配合分页查询脚本)。
* **简单小表或测试:** 可尝试 `INSERT INTO SELECT`。
* **持续同步或复杂 ETL:** 使用 **Flink CDC** 或 **DataX**。
选择哪种方式取决于你的具体需求(一次性迁移 vs 持续同步)、数据量大小、基础设施(是否有 HDFS/S3)以及对实时性的要求。对于“快速”导入大表,`Broker Load` 通常是性能和稳定性最佳的平衡点。
==============以上是AI答复=====================
以上水一波,AI讲了一大堆,咱就是使用了方案4 Flink CDC 遇到问题了呀。至于方案1,咱也没有HDFS、S3 或 NFS 等共享存储呀,而方案2,还需要写脚本啥的。。。
还是回归简单一点的方法吧:
我先在doris搞一张临时表玩玩,试试水先:
CREATE TABLE eqm_pv_over_station_record_tmp like eqm_pv_over_station_record
我用下面的mysqldump命令,导出了一份前100万的记录看看效果先:
mysqldump --set-gtid-purged=OFF --skip-opt --single-transaction -h 172.**.**.3 -P 3306 -uroot -p solar_mes eqm_pv_over_station_record --where="id>=1 AND id<=1000000" > /tmp/backup_eqm_pv_over_station_record_2025.08.20.sql
#在远程服务器192.168.*.***上操作:
useradd -m mysql #创建用户和用户文件夹
passwd mysql # 修改用户密码
输入密码******
su - mysql #切换用户
mkdir gfmes #创建目标文件夹
exit #回到root用户bash
chown mysql:mysql /home/mysql/gfmes或者chmod 755 /gfmes #授权文件夹
#在待拷贝文件的服务器172.**.**.3上操作:
scp /tmp/backup_eqm_pv_over_station_record_2025.08.20.sql mysql@192.168.*.***:/home/mysql/gfmes #执行远程拷贝
遇到问题:
root@master02:/tmp# scp /tmp/backup_eqm_pv_over_station_record_2025.08.20.sql mysql@192.168.*.***:/home/mysql/gfmes
ssh: connect to host 192.168.*.*** port 22: Connection timed out
lost connection
端口探测一下:
nc -w 2 -z 192.168.*.*** 22 && echo "Port 22 is open"
原因:
192.168.*.*** port 22: 端口开放了,但服务器172.**.**.3无访问该端口权限,估计是本地服务器和总部之间的网络防火墙限制了
解决方案:
改用ftp下载到本地,再上传到192.168.*.***
随后,我用以下命令导入doris
mysql -h192.168.*.*** -uroot -P9030 -p solar_mes < /home/mysql/gfmes/backup_eqm_pv_over_station_record_2025.08.20.sql --default-character-set=utf8mb4
输入密码
然后发现居然报错了(连续报错过程就略过不说了,直接看修复命令):
#修改表名
sed -i 's/`eqm_pv_over_station_record`/`eqm_pv_over_station_record_tmp`/g' /home/mysql/gfmes/backup_eqm_pv_over_station_record_2025.08.20.sql
#删除建表语句
sed -i '19,61d' /home/mysql/gfmes/backup_eqm_pv_over_station_record_2025.08.20.sql
#加上指定字段,没这个貌似还插入不了doris
sed -i 's/`eqm_pv_over_station_record_tmp`/`eqm_pv_over_station_record_tmp` (`id`, `factory_code`, `factory_name`,......) /g' /home/mysql/gfmes/backup_eqm_pv_over_station_record_2025.08.20.sql
搞完这一切重新来一遍导入命令:
然后就是等待。。。。等待。。。kao,怎么这么慢~!sql脚本直接导入。。。真好用~。~,下次还是别用了~~!
换个思路吧,直接用Navicat好了:
数据传输、数据同步~~~尝试了一下,失败,根本用不了~!
导出为csv,再导入。。。各种报错~!
导出为json,再导入。。。也行不通~!
要不导出为EXCEL看看?
还真行,先查询个10万,再导出查询结果。嗯不错,还挺快~!然后使用导入向导导入到doris。是不是挺完美?
1千6百万,你得执行个160次啊,想想就可怕~!
要不然,换个思路,先查出缺失的数据,再补进去?说干就干:
测试环境建两个只有id的表test和test2
先查询个100万的id,再导出查询结果,然后导入测试环境这两张表。
接着使用select group_concat(id) from test where id not in(select id from test2)找出差异的id。
再使用where in(ids) 查出缺失的数据,导入doris。
第100万貌似没毛病,还挺快的~!窃喜中。。。
第200万,纳尼,差异id 2.7万,group_concat居然截断了。没事没事,小问题。我用EXCEL来组装id呗:

好用的很~!
不过这还是有点点磨人,没办法了,先这样吧,后面发现CDC同步异常,大概率是有删除的脏数据,binlog里面还记录着的原因。所以换了一个终极思路:在MySQL里面新建一张新表:
create table eqm_pv_over_station_record_new like eqm_pv_over_station_record;
然后使用存储过程分批次插入数据,也就10分钟就搞定了
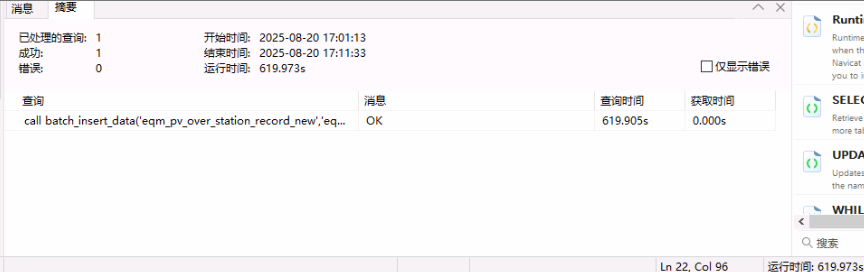
用上新表后问题是否解决,请看后续开发的反馈,今天还没给我结果,明天再问问,估计是搞定了,~。~
