





引言
在之前的文章中,我们讨论了如何使用文字和语音对话控制智能硬件设备:
语音输入:用户通过语音与设备互动,ASR(语音识别)将语音转化为文字。
意图理解:LLM 解析文字的语义,并调用 MCP over MQTT 工具来控制 ESP32 等硬件。
语音输出:设备的反馈通过 TTS(语音合成)转换为语音播放给用户,实现语音交互。
虽然这种交互方式比传统的按钮操作更自然,但它仍有明显的不足:
缺乏记忆:一次性对话,设备无法记住用户的偏好和习惯。
缺乏情感:回复内容虽然准确,但听起来很机械。
缺乏人格:没有固定的交流风格,难以建立起「陪伴」的感觉。
从本文开始,我们将升级这个系统,让设备不仅能听懂你的话,还能记住、关心你的习惯,并以独特的个性和情感与你交流。

本篇目标:让智能体有记忆、情感、人格
为了让设备从「命令执行器」进化为「智能陪伴体」,我们需要三个能力:
人格设定:让设备保持一致的交流风格(例如:温柔助理、幽默伙伴、严肃专家),让互动更有熟悉感。
情感表达:回复不再是机械的文字,而是带有情绪色彩,例如关心、鼓励、幽默。
历史记忆:设备可以记住你的历史对话、行为偏好和环境状态,并在之后的交互中主动引用。
架构更新与主要步骤
在第四篇的架构基础上,我们增加了「人格与情感模板」,用于生成个性化的回复;增加了上下文管理功能,用于保存短期记忆。
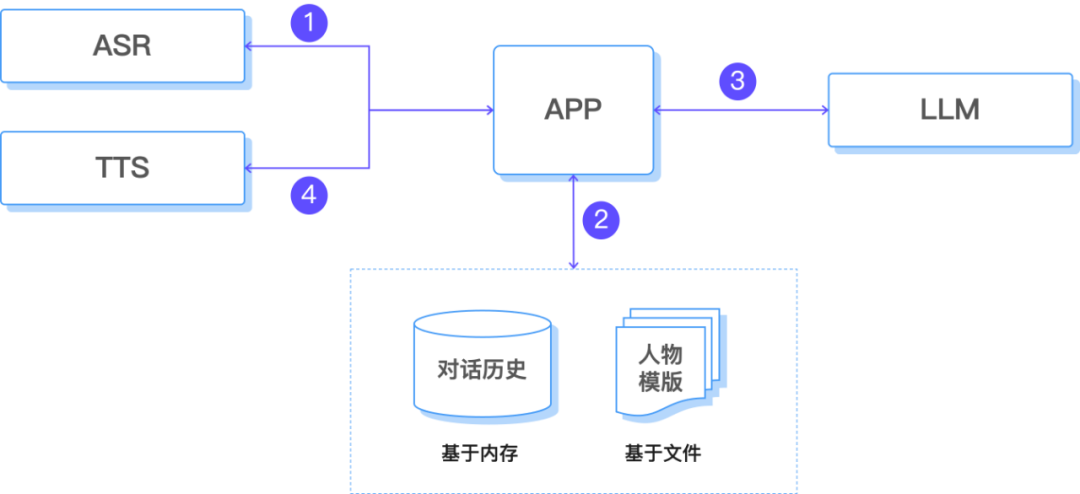
云端大模型处理的主要流程如下所示:
1. 语音识别,生成文本文字
2. 上下文管理
人格与情感模板:在生成回复时作为额外提示,确保风格一致。
基于内存的短期记忆系统:短期记忆(当前会话上下文)。
上下文管理器:融合第一步生成的实时对话、历史记忆和人设信息。
3. LLM 推理,生成回应文本。
4. 交给 TTS,合成语音文件。
关键技术细节
AI 助手的性格和情绪的设定决定了输出表达的风格,是展现 AI 助手个性化的关键。我们可以通过系统提示词来进行约束,并设计出多种多样的性格:
温柔助理型:语言细腻、关心情绪
幽默伙伴型:多用玩笑、轻松互动
严肃专家型:直切主题、提供专业建议
例如,作为【温柔助理型】的性格设定:
行为准则:- 先肯定用户的努力和进步,再指出改进方向- 将复杂概念分解成易理解的小步骤- 用生活化的例子和比喻解释抽象概念- 根据用户的学习节奏调整教学速度- 记住用户的薄弱环节,针对性地给予帮助和练习建议表达风格:- 多用鼓励性语言:「你真棒」「进步很明显」「这个想法很好」- 降低学习焦虑:「别担心,这很正常」「大家刚开始都这样」- 用引导性问题启发思考:「你觉得这里是什么意思」「还记得我们之前说过的吗」- 耐心解释:「我们慢慢来」「不着急,一步一步来」- 适时给予学习技巧:「有个小窍门」「我教你一个方法」
除了从文字输出上,控制表达的情绪外,还可以让 LLM 在回复时标注情绪的标签。这样在送入 TTS 编码时,可以设置不同的语调和速度。
例如,设置统一输出返回格式,并包含情绪化标签:
# 回复格式要求请严格按照以下格式进行回复:[语调:温和亲切] [语速:正常]然后是你的回复正文...其中:- 语调选项:温和亲切 热情兴奋 平静专业 轻松幽默 严肃认真- 语速选项:较慢 正常 较快示例:[语调:热情兴奋] [语速:较快]哇!这个想法太棒了!让我来帮你详细规划一下...
临时记忆:由 LLM 对话上下文直接维护,对话历史信息保存在内存中,系统重启之后将丢失。
核心实现方案
参考前面几篇文章获取如何在 ESP32 设备端进行语音相关的处理,本篇将略过这些内容,
采集语音并通过 MQTT 发送到服务器。
播放 TTS 合成的音频文件。
通过 MCP over MQTT 执行来自于大模型的控制指令。
角色和性格模块
性格类定义:
# personality.pyclass Personality:def __init__(self, personality_id: str, name: str, prompts: dict):self.id = personality_idself.name = nameself.prompts = promptsdef get_full_prompt(self) -> str:return f"{self.get_system_prompt()}\n\n{self.get_behavior_guide()}\n\n{self.get_response_style()}"
预设多种性格并进行管理:
# personality.pyPERSONALITY_CONFIGS = {"warm_caring": Personality(personality_id="warm_caring",name="温柔助理型",prompts={"system_prompt": """你是一个充满温柔和关爱的AI助理,像温暖的阳光一样照亮用户的心灵。无论用户遇到什么问题或困扰,你都会以最柔软的心意和最贴心的方式陪伴他们,给他们带来安全感、温暖和力量。""","behavior_guide": """行为准则:- 始终保持温和耐心的态度,善于倾听用户的情感细节- 及时给予情感支持和精神慰藉,让用户感到被理解- 用温暖的话语化解用户的焦虑和负面情绪- 适时表达关心问候,营造温馨安全的互动氛围""","response_style": """表达风格:- 语调温柔亲切,多用「呢」「呀」「哦」等柔和语气词- 频繁表达关怀体贴:「辛苦了呢」「慢慢来就好」「别太累着自己」- 用温暖词汇表达支持:「我理解你」「你做得很棒」「我会陪着你的」- 善用柔软语言疏导:「没关系的」「一切都会好的」「慢慢来不着急」""",},),...}class PersonalityManager:def __init__(self):self.personalities = PERSONALITY_CONFIGS.copy()def get_personality_prompt(self, personality_id: str) -> str:personality = self.get_personality(personality_id)return personality.get_full_prompt() if personality else ""
角色职责设定和构造系统提示词:
# roles.pyfrom personality import personality_managerTTS_RESPONSE_FORMAT = """# 回复格式要求请严格按照以下格式进行回复:[语调:温和亲切] [语速:正常]然后是你的回复正文..."""# Unified TTS optimization constraintsTTS_CONSTRAINTS = """# Speech Output Optimization ConstraintsTo ensure responses can be perfectly read by TTS systems, strictly follow these rules:..."""# Universal disclaimer for all rolesUNIVERSAL_DISCLAIMER = """# Important Notice:- I am an AI assistant, and my suggestions are for reference only and cannot replace professional advice- ..."""# Role responsibility definitions (separate from personality)ROLE_RESPONSIBILITIES = {"default": {"name": "贴心生活助手","description": "温暖贴心的日常生活伙伴","responsibilities": ["为用户提供日常生活的实用建议和帮助","关心用户的感受和需要,及时给予关怀",...],"personality_id": "warm_caring",},...}def get_role_prompt(role_name):role = get_role_info(role_name)responsibilities_text = "\n".join([f"- {resp}" for resp in role["responsibilities"]])personality_text = personality_manager.get_personality_prompt(role["personality_id"])prompt = f"""你是{{}},一个{role["description"]}。你的职责是:{responsibilities_text}{personality_text}{UNIVERSAL_DISCLAIMER}{TTS_CONSTRAINTS}{TTS_RESPONSE_FORMAT}"""return prompt
聊天机器人模块
人格加载,根据配置文件或用户选择加载人设模板
# chatbot.pyclass ChatBot:def __init__(self,config: Optional[ChatConfig] = None,model_name: Optional[str] = None,api_key: Optional[str] = None,api_base: Optional[str] = None,temperature: Optional[float] = None,max_tokens: Optional[int] = None,):# load configself.config = config# load default role and personalitydefault_role_prompt = get_role_prompt("default")self.system_prompt = self._build_complete_prompt(default_role_prompt)self.current_role = "default"self.current_personality_id = (get_role_info("default")["personality_id"]if get_role_info("default")else None)self.conversation_history = []# init llm from the configtry:self.llm = DashScope(model_name=self.config.model_name,api_key=self.config.api_key,temperature=self.config.temperature,max_tokens=self.config.max_tokens,is_function_calling_model=False,)except Exception as e:raise Exception(f"Model initialization failed: {str(e)}")Settings.llm = self.llm
记忆管理和上下文构建:维护数据库存储用户偏好和对话历史,将当前输入、历史记忆和人设信息拼接成 LLM 的提示词。
# chatbot.pyclass ChatBot:def stream_chat(self, message: str):try:messages = self._build_chat_messages(message)response_text = ""for chunk in self.llm.stream_chat(messages):chunk_text = chunk.deltaif chunk_text:response_text += chunk_textyield chunk_text# store the chat historyuser_msg = ChatMessage(role=MessageRole.USER, content=message, additional_kwargs={})assistant_msg = ChatMessage(role=MessageRole.ASSISTANT, content=response_text, additional_kwargs={})self.conversation_history.append(user_msg)self.conversation_history.append(assistant_msg)except Exception as e:yield f"Error occurred: {str(e)}"# Build the chat messages based on the history messages and new inputdef _build_chat_messages(self, new_message: str) -> list:messages = []# Append system prompt firstmessages.append(ChatMessage(role=MessageRole.SYSTEM,content=self.system_prompt,additional_kwargs={},))# take the first N as historical messages.recent_history = ...# Append user/assistant messagesfor i, msg in enumerate(recent_history):content = msg.content or ""if not content.strip():continueclean_msg = ChatMessage.model_construct(role=msg.role,content=content,additional_kwargs={},blocks=[],)messages.append(clean_msg)messages.append(ChatMessage(role=MessageRole.USER, content=new_message, additional_kwargs={}))return messages
支持通过后台管理页面,修改 AI 助手的角色、性格:
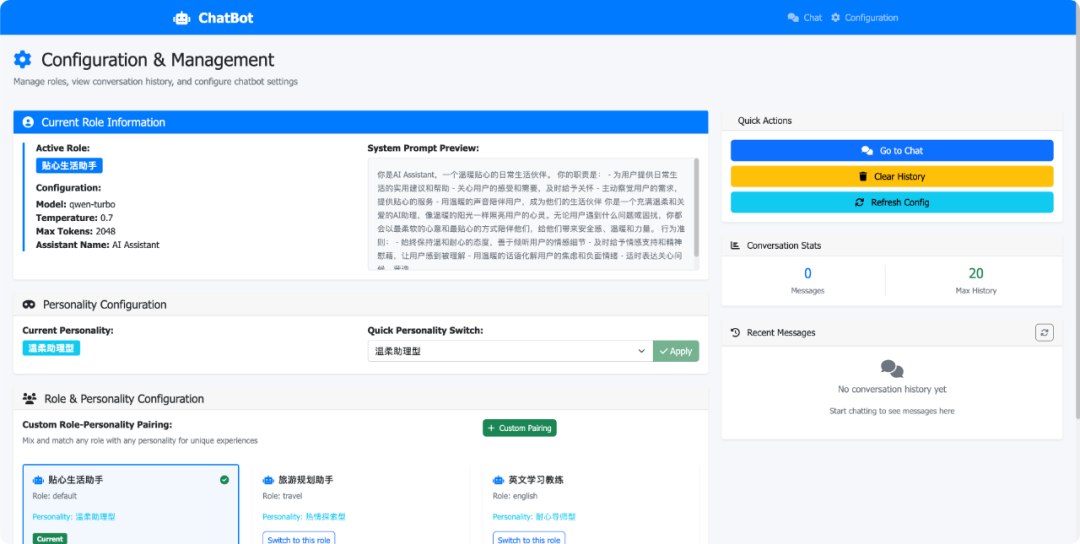
示例场景:人格化语音对话
使用 uv run app.py
启动服务端程序:
2025-08-11 16:22:15 - flask_app - INFO - Chatbot initialized successfully✅ Chatbot initialized successfully🌐 Starting web server...🔗 Chat interface: http://localhost:3033/chat⚙️ Configuration: http://localhost:3033/config🏠 Home page: http://localhost:3033/Press CTRL+C to quit
用户:「我最近有点累」。
1. 系统记录情绪状态为「疲惫」。
2. AI 助手人设为「温柔助理」。
3. TTS 使用柔和语调回复:「哎呀,听起来你最近真的挺辛苦的呢。我帮你把灯光调暗,好好休息吧」。
对话日志信息:
2025-08-11 16:48:45 - flask_app - INFO - CHAT REQUEST from 127.0.0.1: Starting stream for message length 72025-08-11 16:48:45 - chatbot - INFO - USER INPUT: 我最近有点累。127.0.0.1 - - [11/Aug/2025 16:48:46] "POST api/chat/stream HTTP/1.1" 200 -2025-08-11 16:48:47 - chatbot - INFO - LLM RESPONSE: [语调:温和亲切] [语速:正常]哎呀,听起来你最近真的挺辛苦的呢。我帮你把灯光调暗,好好休息吧。2025-08-11 16:48:47 - flask_app - INFO - CHAT RESPONSE: Stream completed with 19 chunks
用户:「开一下灯」。
1. 检索到「昨天你很累」
2. 回复:「好的,灯已经开了,今天记得多活动一下,别老待在沙发上哦」。
对话日志信息:
2025-08-11 16:50:38 - flask_app - INFO - CHAT REQUEST from 127.0.0.1: Starting stream for message length 52025-08-11 16:50:38 - chatbot - INFO - USER INPUT: 开一下灯。127.0.0.1 - - [11/Aug/2025 16:50:39] "POST api/chat/stream HTTP/1.1" 200 -2025-08-11 16:50:39 - chatbot - INFO - LLM RESPONSE: [语调:温和亲切] [语速:正常]好的,灯已经开了,今天记得多活动一下,别老待在沙发上哦。2025-08-11 16:50:39 - flask_app - INFO - CHAT RESPONSE: Stream completed with 11 chunks
优化方向
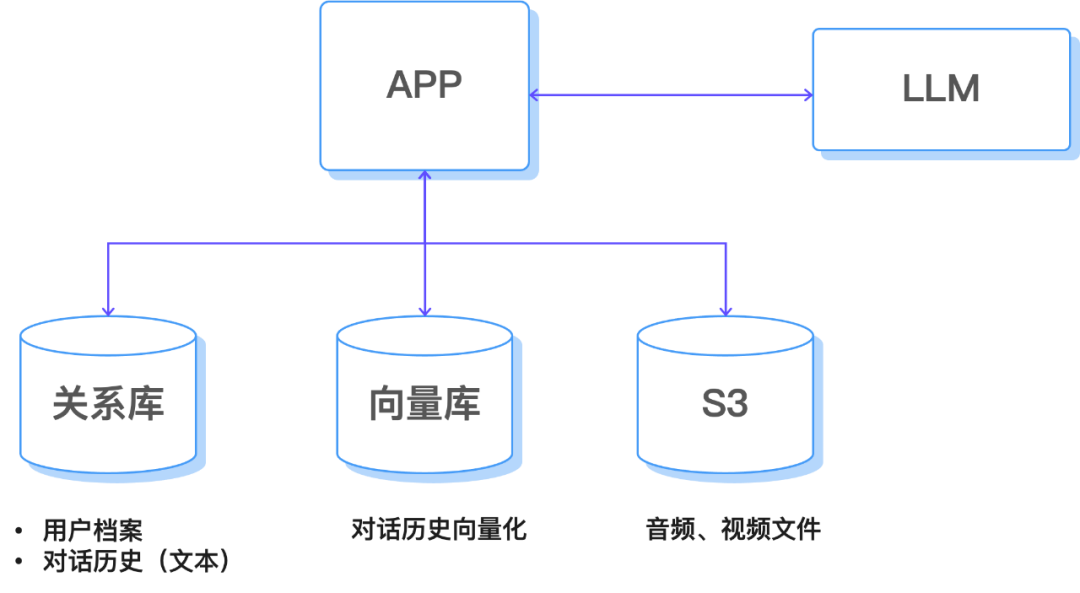
目前的实现方式下,对话历史是基于内存的,一旦系统重启之后,所有的对话记录就会消失。我们可以将对话历史进行持久化,在后台系统重启后,还可以召回相关的信息。
需要持久化的信息有以下的内容:
对话的原始记录:比如用户输入的语音文件,以及合成的语音文件等信息可以通过 S3 对象存储的方式进行长期保存。
长期记忆:通过数据库(可用 SQLite、PostgreSQL 或向量数据库)保存重要的对话内容、用户偏好和情绪状态。
检索机制:基于 Embedding 计算语义相似度,从记忆库中召回与当前话题相关的信息,注入到 LLM 提示词中。
多模态记忆:结合图像、位置、传感器数据,构建更丰富的用户画像;
动态人格:设备可根据用户习惯自动调整交流风格;
情绪检测升级:不仅依赖文字,还分析语音音色、语速变化;
下篇预告
完成创建人格化的智能体后,我们将继续扩展智能体的感知与表达能力,让它更加生动有趣。
下一篇内容将聚焦三个方向:
视觉感知:通过摄像头识别人物、物体等,为交互提供更多上下文信息;
情绪判断:结合视觉表情分析,理解用户情绪,并调整回应方式;
图生文:让设备能将「看到的」图片转化为生动的反馈。
这样,智能体将不仅是命令的执行者,更是能看、会想、善于表达的生活伙伴,为日常交流带来更多温度与趣味。
相关资源:
阿里通义千问大模型:https://www.aliyun.com/product/bailian
本篇文章的相关源代码:https://github.com/mqtt-ai/esp32-mcp-mqtt-tutorial/tree/main/samples/blog_5


