




在如今的数据驱动时代,我们越来越依赖于通过“预测”优化生活和决策。早上出门前,我们会查看天气预报来决定是否带伞;到了饭点,我们会根据预计送达时间选择合适的外卖……
同样地,在城市出行中,行程时间预测已成为网约车系统中的关键一环。对于乘客而言,这一时间会直接影响通勤选择;对于平台而言,这关乎整个系统的资源配置。一旦预测失准,就会导致资源调度混乱、订单流失和成本上升。
因此,如何提升“预计到达时间”的准确性和预测效率,是每一个出行平台必须面对的核心课题。
为了应对这一挑战,滴滴、Uber 这类头部出行平台已经构建起了自己的 ETA(Estimate Travel Time) 预测模型,借助强大的算法团队和数据基础,持续优化预测能力。但对于大多数中小平台而言,缺乏高效建模工具与实时计算能力,一直是模型难以落地的一大阻碍。
一、为什么说来容易,做起来难?
行程时间预测的本质是一个回归问题,看上去并不复杂。可一旦置于真实的业务环境,情况就远比想象中复杂得多。
每天的通勤高峰、临时交通管制、天气变化、节假日效应等因素,都有可能对行程时间产生显著影响,为预测模型带来诸多挑战。而且,出行订单的数据体量庞大,还涵盖上下车经纬度、时间戳、乘客人数等多个维度。这就意味着模型构建不仅需要精确的算法,还需要系统具备高效的数据处理能力。
目前,平台普遍采用“数据库 + Python + XGBoost”的组合进行建模与预测。尽管这一方案在工具层面已相对成熟,但在实际操作中,用户往往需要先将数据存入数据库,再导出到 Python 环境进行格式转换、建模与训练。这样的流程在大数据场景下存在明显弊端,例如数据迁移成本高、容易触发内存瓶颈、模型训练效率低下等,难以满足业务对实时性与稳定性的高要求。
二、直接打通“数据存储-预测结果”全链路?
那么,是否存在一款工具,能够覆盖数据存储、格式转换、建模训练等全流程操作,真正打通从原始数据到预测结果的完整链路呢?
答案是肯定的。
作为一款基于高性能时序数据库、支持复杂分析与流处理的实时计算平台,DolphinDB 不仅能够高效存储和查询结构化与半结构化数据,也在库内实现了 Tensor 格式并内置 XGBoost 插件,用户无需离开数据库环境就能直接完成数据转换、模型加载和预测。
此外,DolphinDB 还提供多种计算函数,帮助用户快速实现数据处理。例如,提供空值处理函数用于判断空值,配合 sum() 等聚合函数快速完成整表数据的查询;提供条件运算符简化 if-else 语句;提供多个日期函数用于提取时间、日期数据的不同特征……
以下是使用 DolphinDB 进行行程时间预测的流程图:
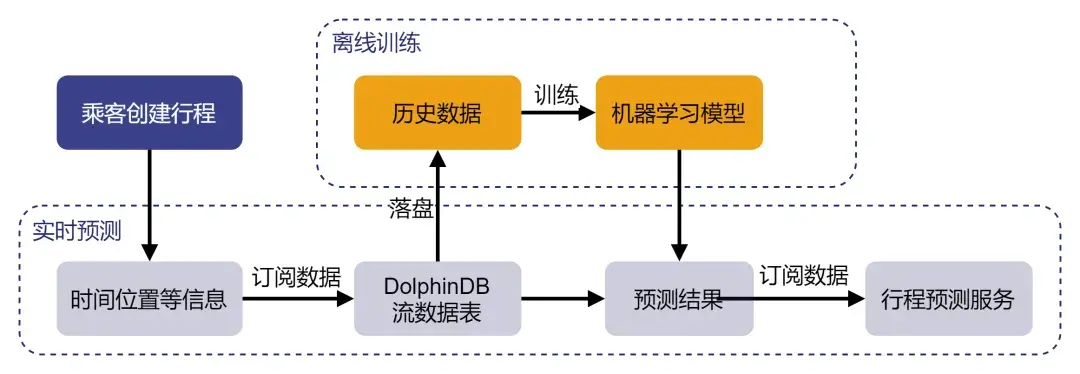
接下来,我们就通过一个实例,展示如何使用 DolphinDB 进行模型构建、模型训练和模型评价,并附上与 Python Scikit-Learn 库、XGBoost 在同一环境下进行模型训练和预测的性能对比结果。
由于篇幅有限,实时预测环节将在后续文章中介绍。
三、DolphinDB 建模实战
本例中,我们采用 Kaggle 提供的来自纽约出租车委员会的数据集。该数据集分为训练数据集和测试数据集,训练数据集共包含 1458644 条数据,测试数据集共包含 625134 条数据;训练数据集共包含以下 11 列信息。
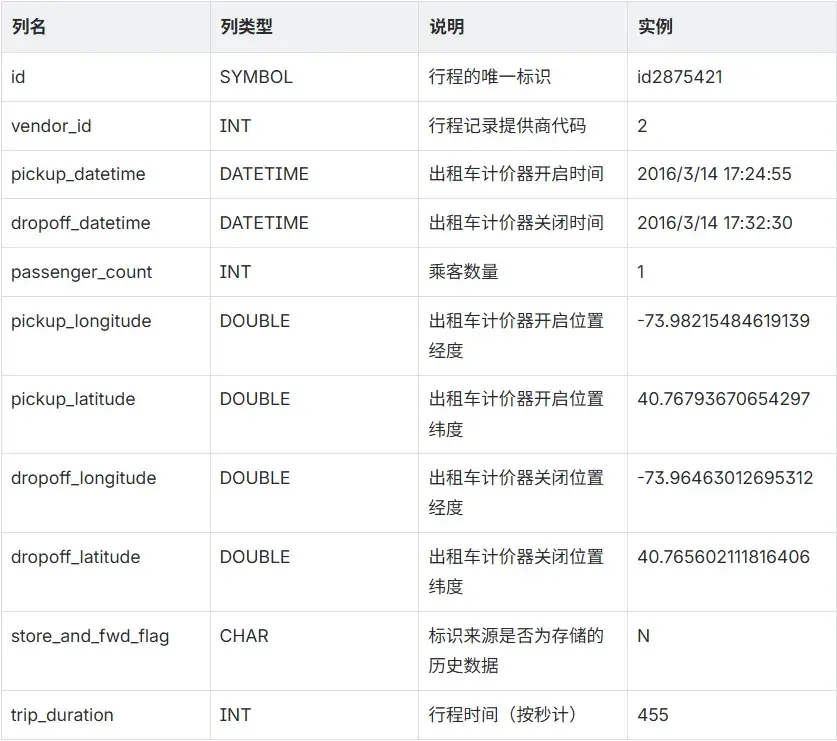
行程时间预测的目标列为上表中 trip_duration 列,即 dropoff_datetime 与 pickup_datetime 之差。测试数据集用于预测,所以列信息不包括 dropoff_datetime 及 trip_duration 列,测试数据集中行程标识、位置等列属性同上表。
SYMBOL 类型是 DolphinDB 中一种特殊的字符串类型,在系统内部的存储结构为一个编码字典;DATETIME 类型是包含日期和时刻的时间类型。
训练方法参考获奖者 Beluga 的模型,使用 DolphinDB 对原始数据进行数据预处理,完成位置信息主成分分析(PCA, Principal Component Analysis)、位置信息聚类(KMeans)、新特征构建等工作,并使用 DolphinDB XGBoost 插件完成模型训练及行程时间预测。
1. 数据导入与存储
DolphinDB 支持 loadText 方法读取 csv 等数据存储文件到内存表,用户可以使用 schema 函数获取表的特征信息:
train = loadText("./taxidata/train.csv")
train.schema().colDefs
select count(*) from train
select top 5 * from train将数据加载到内存表后,可以将训练数据与测试数据导入 DolphinDB 数据库中,便于后续数据的读取与模型的训练。
数据导入分布式数据库的操作详见:https://docs.dolphindb.cn/zh/db_distr_comp/db_oper/data_import_method.html
2. 数据预处理
在模型训练过程中,首先需要检查数据集是否包含空值,本训练数据集与测试数据集均不包含空值。若存在缺失值,还需要进行删除、插补等操作。其次,需要检查数据集数据类型,将字符型数据、日期时间型数据转化为数值型数据。
考虑到该数据测试集评价指标为均方根对数误差,最大行程时间接近 1000 小时,所以我们对行程时间取对数作为预测值,使用均方根误差(RMSE)指标进行评价。
sum(isNull(train)) // 0,不含空值
trainData[`store_and_fwd_flag_int] = iif(trainData[`store_and_fwd_flag] == 'N', int(0), int(1)) // 将字符N/Y转化为0/1值
trainData[`pickup_date] = date(trainData[`pickup_datetime]) // 日期
trainData[`pickup_weekday] = weekday(trainData[`pickup_datetime]) // 星期*
trainData[`pickup_hour] = hour(trainData[`pickup_datetime]) // 小时
trainData[`log_trip_duration] = log(double(trainData[`trip_duration]) + 1)// 对行程时间取对数,log(trip_duration+1)
select max(trip_duration / 3600) from trainData // 训练集上最大行程时间为979h3. 位置信息主成分分析(PCA)
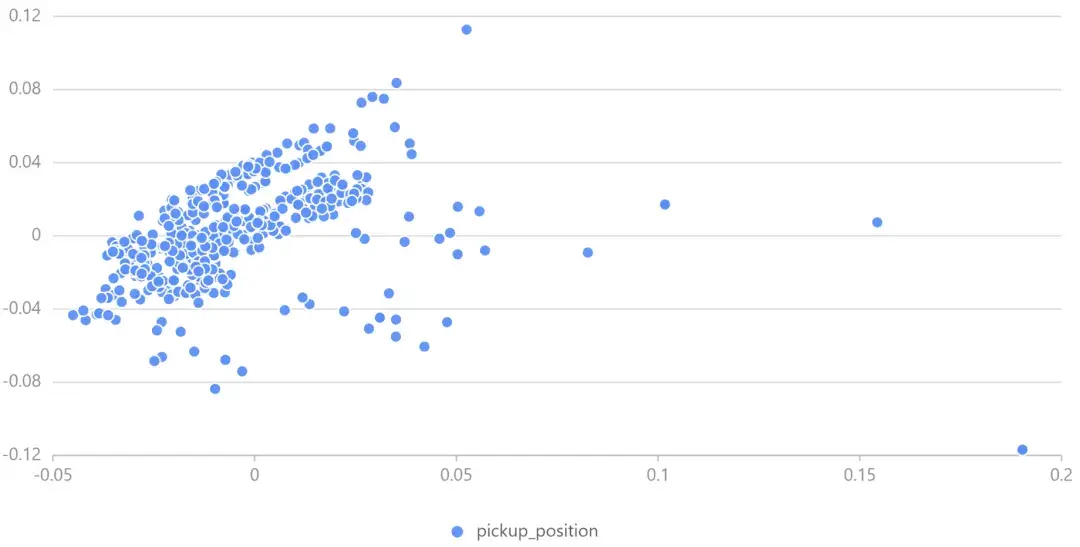
原始数据中的纬度经度信息集中在 40.70 °N 至 40.80 °N、73.94 °W 至 74.02 °W 之间,数据间位置特征差异不够显著,所以我们使用 PCA 来转换经度和纬度坐标,便于 XGBoost 决策树的拆分。
DolphinDB pca 函数说明:https://docs.dolphindb.cn/zh/funcs/p/pca.html
我们取若干数据绘制经度-纬度散点图观察 PCA 结果:
4. 位置信息聚类(KMeans)
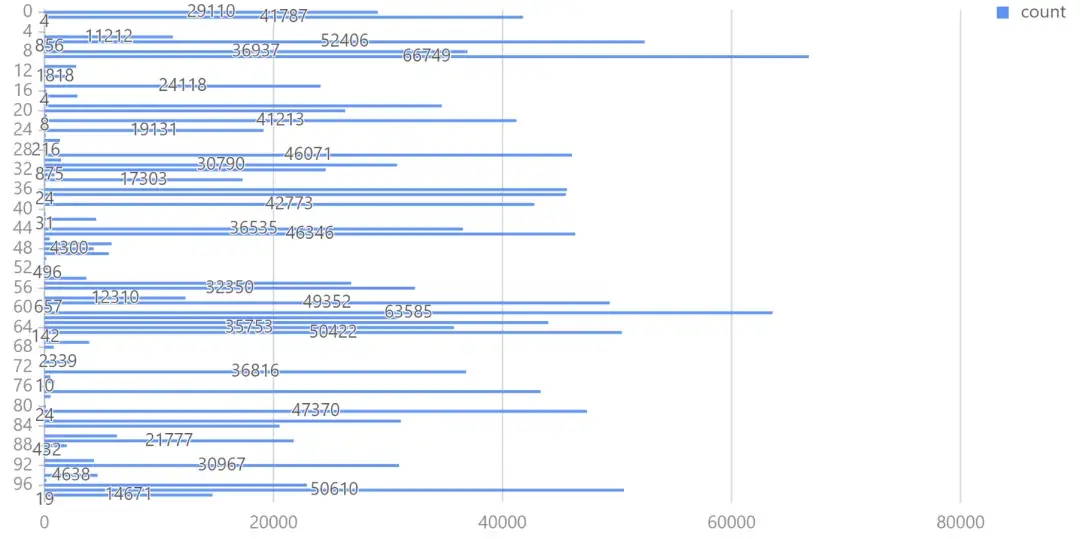
原始位置数据规模庞大,很难挖掘出数据间的共同特征,所以我们可以通过 KMeans 将经纬度相近的数据点归入同一簇,更好地归纳组内数据特征。本例中,我们将聚类数设为 100,质心最大迭代次数为 100,选择 KMeans++ 算法生成模型。
DolphinDB kmeans 可选参数及含义详见:https://docs.dolphindb.cn/zh/funcs/k/kmeans.html
绘制条形图观察聚类后的数据分布:
5. 新特征构建
原始数据仅提供了经度和纬度位置信息,我们可以在此基础上增加位置特征,如地球表面两经纬度点之间距离、两经纬度点之间的 Manhattan 距离、两个经纬度之间的方位信息等。
DolphinDB 支持用户自定义函数,通过独立的代码模块完成特定的计算任务。而对于不同类别(聚类、时间)内的特征,可使用 groupby 方法在每个分组中计算需要的特征(如平均值)。groupby 接收三个参数,根据第三个参数指定的列进行分组,取第一个参数为计算函数,计算第二个参数对应列的特征,并返回行数与分组数相等的表。用户可通过表连接操作将该组合特征合并入特征数据。
本例使用 fj(full join) 将特征表与 groupby 表合并,fj() 指定第三个参数为连接列,将前两个参数所传入的表合并。代码如下:
// 两经纬度点距离、两个经纬度之间的 Manhattan 距离、两个经纬度之间的方位信息
trainData['distance_haversine'] = haversine_array(trainData['pickup_latitude'], trainData['pickup_longitude'], trainData['dropoff_latitude'], trainData['dropoff_longitude'])
trainData['distance_dummy_manhattan'] = dummy_manhattan_distance(trainData['pickup_latitude'], trainData['pickup_longitude'], trainData['dropoff_latitude'], trainData['dropoff_longitude'])
trainData['direction'] = bearing_array(trainData['pickup_latitude'], trainData['pickup_longitude'], trainData['dropoff_latitude'], trainData['dropoff_longitude'])
// 按时间、聚类等信息处理速度、行程时间,产生新特征
for(gby_col in ['pickup_hour', 'pickup_date', 'pickup_week_hour', 'pickup_cluster', 'dropoff_cluster']) {
for(gby_para in ['avg_speed_h', 'avg_speed_m', 'log_trip_duration']) {
gby = groupby(avg, trainData[gby_para], trainData[gby_col])
gby.rename!(`avg_ + gby_para, gby_para + '_gby_' + gby_col)
trainData = fj(trainData, gby, gby_col)
testData = fj(testData, gby, gby_col)
}
trainData.dropColumns!(`gby + gby_col)
}6. 模型训练(XGBoost)
完成数据处理和特征构建后,我们使用 DolphinDB 内置的 XGBoost 插件进行机器学习。为评价模型训练效果,将训练数据集划分为训练集和验证集,随机选取 80% 的数据作为训练集训练模型,使用 20% 的数据作为验证集输出预测结果,使用均方根误差指标计算验证集的预测值与真实值的偏差。
绘制预测值-真实值散点图,定性分析模型预测效果:
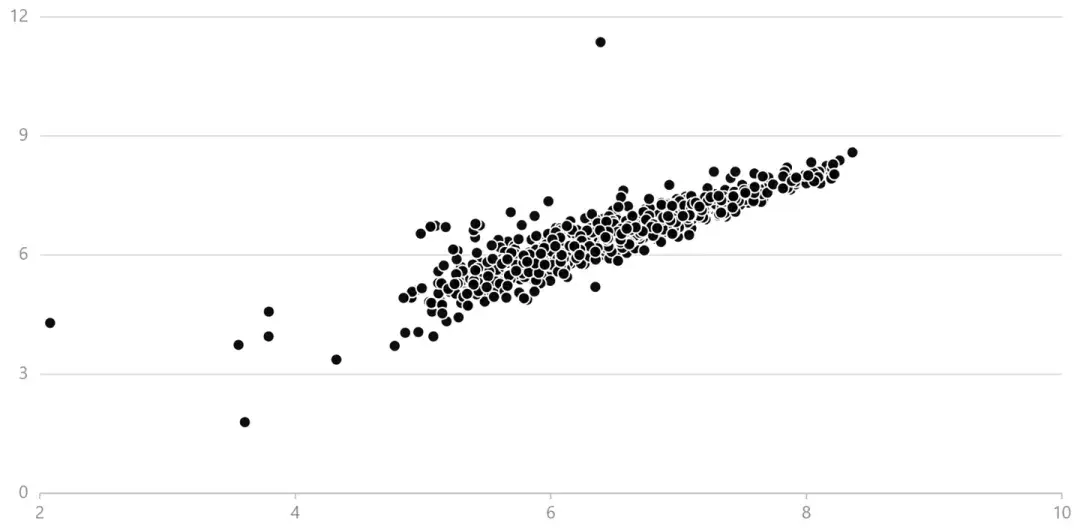
7. 模型评价&性能对比
本例使用了三种机器学习方法:使用 PCA 对位置信息进行处理,转换数据的经纬度特征;使用 KMeans++ 对出租车上下客位置进行聚类,将纽约市区划分为 100 个区域进行分析;使用 XGBoost 对数据集特征进行训练。在验证集上模型均方根误差为 0.390,效果较好。
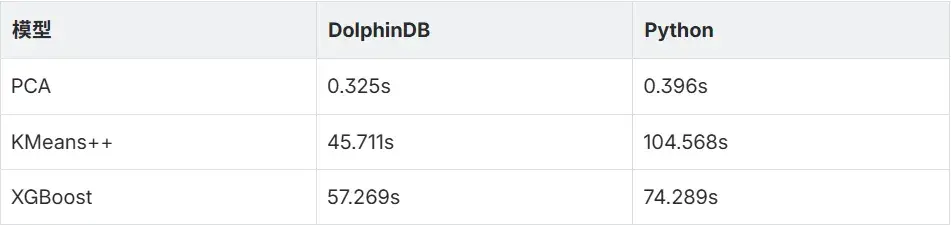
我们在相同环境下使用 DolphinDB 和 Python 对同一数据集进行训练,PCA、KMeans++、XGBoost 训练耗时如下表所示:
训练模型在验证集上的误差如下表所示:

结果显示,两者准确率差异不大,而 DolphinDB 在性能表现上则全面领先于 Python。
以上就是使用 DolphinDB 进行网约车行程时间预测的建模流程——从数据加载、清洗、特征构建,到模型训练与评估,全程在同一平台完成,省去数据迁移成本,大幅提效。如需获取本例中使用的代码文件,请添加小助手微信(dolphindb1)。
当然,精准的离线建模只是第一步,能够将预测能力延伸到实时业务场景中才是落地的关键。由于篇幅限制,我们将在后续文章中详细展示如何利用 DolphinDB 处理实时订单流数据,基于已训练的模型实时预测,并结合 Grafana 构建可视化监控面板,让行程时间预测真正服务于乘客体验和平台运营。
如果您对智能出行、实时计算或 DolphinDB 的更多物联网应用感兴趣,欢迎关注我们,第一时间了解最新动态与技术干货!
