




某移动地市分公司数据集市国产化改造
[TOC]
业务背景
某省移动作为某省内用户规模最大的电信运营商,服务超过xxx万用户,核心营业系统数据量已超过xxTB,单库日SQL请求量达xx亿次,日订单量超xxxx万笔;原有集中式数据库无法分库分表,单机算力不足,导致业务高峰期性能下降架构,同时面临容量瓶颈、高并发处理能力不足等问题,难以支撑业务连续性要求。
首先,为了响应国家“信创”战略,降低对国外数据库的依赖,避免技术“卡脖子”风险。同时,国外数据库的许可费用和维护成本极高,国产化替换可显著节省开支,通过替换国产数据库,可以节省大量的应用开发成本和许可费用。
因此,中国移动集团层面推动省级业务支撑系统国产化,并结合国产数据库的兼容性优势,减少开发人员学习成本。通过以某省公司作为试点,探索可复用的国产化路径,为全国推广积累经验。
场景描述
地市数据集市系统作为区域数据中枢已稳健运行逾十载,目前系统存储容量达xxxTB规模,日间数据吞吐量维持xxTB量级。系统承载的核心业务模块包含xxxx余个数据下发单元,日均执行超万项数据汇总任务,当前调度任务池规模突破xxxx+节点。在业务数据量呈现指数级增长的态势下,系统运行效能面临严峻挑战:核心数据下发时效性指标为89%,关键任务最长执行周期突破12小时,传统数据库架构在弹性扩展能力、本地化支持响应及安全可控性等维度逐渐显现瓶颈制约。
基于国家信息技术应用创新战略指引,为贯彻落实关键核心技术攻关工程部署要求,亟需构建安全可信的国产化技术体系。经充分技术论证,拟采用国产磐维分布式数据库实施架构升级,该方案具备以下战略价值:其一,通过自主研发的分布式架构实现存储计算弹性扩展,有效应对业务规模持续扩张;其二,依托原生安全防护体系保障核心数据资产安全;其三,遵循国产化替代技术路线,实现数据库核心技术自主可控。此次架构升级将同步优化数据处理流程,重构任务调度机制,全面提升系统运行效率与业务连续性保障能力。
建设方案
网络拓扑图
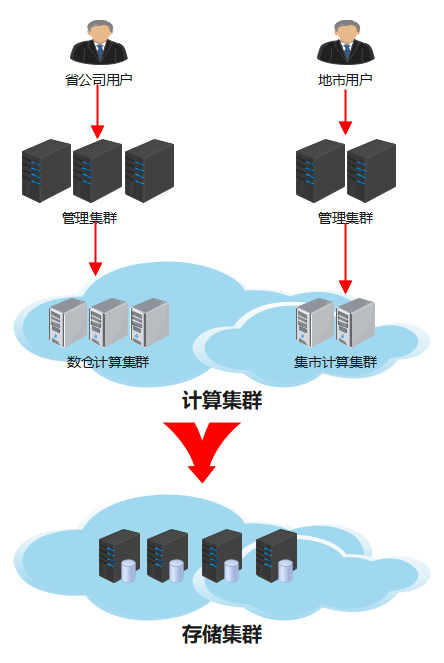
系统功能架构
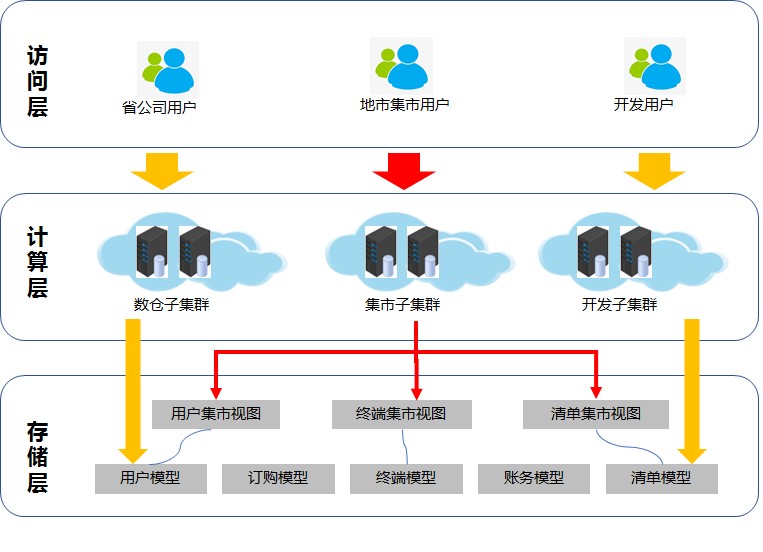
功能建设
数据开发
某公司系统依托先进的数据治理框架,通过智能数据管道实现多源异构系统的全量数据汇聚。原始数据经分层分级处理后,以范式化方式存储于经分系统数据仓库。在数据预处理阶段,采用调度引擎对原始数据集进行深度分析与智能清洗,通过标准化重构与语义化转换,形成高价值密度业务指标。数据开发人员基于前瞻性业务洞察,结合多维度建模技术,对结构化数据集进行定制化开发,最终输出满足战略决策支持、运营效能评估及客户行为分析等多元场景需求的多维可视化分析报表与动态数据看板。
同时,某公司还肩负着赋能地市分公司成长的重任。部分价值较高的数据,可通过省公司提供的数据下传程序进行数据传输,精准同步至地市分公司数据库。地市分公司的开发人员拿到数据后,根据各地市分公司的实际业务需求,深度挖掘数据潜力,展开二次开发。
省公司数据开发团队将依据地市分公司提交的数据表需求清单,在磐维数据库平台中规范构建对应物理表结构。为强化数据资产安全管理,遵循标准化数据治理规范,技术团队将实施三层防护机制:首先建立基础表结构并配置完整性约束,随后通过视图层实现数据安全隔离,最终基于精细化权限管理策略完成访问控制体系搭建。
在视图架构设计环节,技术团队将严格对照地市机构提供的业务数据目录,分阶段实施视图创建工作:第一阶段完成逻辑视图层的框架搭建,第二阶段按业务单元逐项创建标准化视图对象。所有视图对象均采用与实际业务表完全一致的命名规范,确保业务映射的准确性和可维护性。地市分公司开发人员可通过4A统一安全管控平台认证接入,在授权范围内进行合规的数据开发作业。
数据订阅
地市分公司数据开发团队在执行日常报表开发任务时,偶遇数据源完整性不足的情形。此时需通过4A统一认证系统登录大数据分析平台,继而访问数据超市界面。在该界面的数据申请服务模块中,数据开发人员可依据缺失数据表字段特征及数据更新周期要求,按照平台既定的数据服务申请规范,在标准化模板中完善元数据描述及业务需求说明,完成填写后提交流程后即可触发自动化数据订阅服务机制。
数据下发
数据管理中心对多渠道汇入经营分析系统的原始数据,实施全链路数据治理工程,包括但不限于数据清洗、加工转换、标准化处理等核心环节,最终形成全域业务明细数据资产库。依托各地市业务管理单元定期反馈的个性化数据需求矩阵,省级数据工程团队首先完成维度建模与配置管理,构建全域统一的数据下发维度控制体系。继而基于全省地市业务特性和技术架构特征,研发智能化数据分发引擎系统。该核心组件通过多层质量验证后,自动解析下发维度配置中心的信息指令,按照预设的数据安全传输协议,将定制化数据精准投递至各地市分公司的专属数据存储节点。
报表刷新
地市分公司开发团队依托敏捷BI开发框架,构建本地化数据服务矩阵。数据源采用混合架构模式:一方面基于地市级数据资源池进行本地化数据治理与增值加工实现业务指标建模;另一方面通过安全数据网关对接国产磐维数据库,完成多模态数据实时同步与标准化映射。开发人员基于可视化工作台对异构数据集进行智能关联,通过分布式任务调度平台实现报表参数化配置,最终输出支持多终端自适应的交互式分析看板。系统内置增量更新机制,结合业务事件驱动与定时批处理双模式,保障数据展示层的分钟级和小时级刷新效能,同时通过数据血缘追溯体系实现全链路质量管控。
生命周期管理
某移动系统侧数据的生命周期管理针对的是数据仓库中的业务数据。这些业务数据可以划分为四个存储级别:在线级别、近线级别、归档级别和销毁级别。其中在线、近线和归档级别的数据可以存储在不同存储介质中。在线级别数据存储在高速存储设备上,近线级别数据存储在低速存储设备上,而归档级别数据可以存储在磁带或磁带库上。
- 在线级别:
一般指6个月内的业务数据;具体业务数据的在线周期可以根据该数据的重要度指数,月访问频率分析来决定;通常针对汇总数据的在线周期可以更长; - 近线级别:
在本级别中的数据,一般具有相对较长的存在时间,一般指6个月至18个月的业务数据;通常针对汇总数据的在线周期可以更长; - 归档级别:
处于本级别的数据库,可以认为是在近期不太可能被经常查询访问到的数据,往往指18个月以上的业务数据; - 销毁级别:
指数年(例如>10年)以后的数据,数据不再可能被访问到,从而不再需要保存。
各地市分公司可以根据数据的访问频率、重要性程度、月访问频率分析和技术要求章节中数据存储周期要求等来确定不同业务数据的存储级别。
隐私化保护
在数据管理与运用的流程中,地市分公司所涉及的数据依据实际访问情形,有着泾渭分明的两类划分:一类是包含敏感字段的数据表,像手机号、身份证号、家庭住址、客户名称以及短信内容等这类高度敏感信息所在的表;另一类则是完全未涵盖敏感字段的数据表。
对于前者,即存有敏感信息的数据表,借助磐维数据库提供的专业 PostgreSQL Anonymizer 模式,实施极为严格且精细的数据访问权限控制。每一个敏感字段都如同被置于重重安保之下,从根源上杜绝数据泄露风险,严守信息安全底线。
而后者,也就是那些被明确判定为维表的、未含敏感字段的数据表,地市分公司的工作人员拥有全量查看权限。这既保障了日常工作能够高效流畅地开展,又因无需经过繁琐的隐私化脱敏处理流程,让数据的即时可用性大幅提升,为分公司业务的快速推进注入强劲动力。
数据安全访问
地市分公司日常运营所需的数据,依其实际存储类型,大致可划分为两类:一类为包含地市编码的数据表,另一类则是未涵盖地市编码的数据表。针对含有地市编码的数据表,我们依托磐维数据库所提供的 PostgreSQL Anonymizer 技术手段,精准实施数据访问权限管控,确保数据流通的安全性与合规性。而对于那些未带有地市编码的数据表,从数据架构层面来讲,可将其归类为维表。鉴于此类维表的特性与应用场景需求,地市分公司的工作人员有权进行全量查看,无需施加额外的安全访问限制,以此保障业务流程的高效顺畅推进,满足一线工作的实际数据需求。
建设成效
- 技术架构优化:
消除传统集中式架构对云原生、算力网络等技术架构持续演进的不利影响,为后续新技术的应用和业务拓展打下良好基础,使系统更具扩展性和灵活性,能够更好地适应未来业务发展变化。 - 运维效率提高:
数据库运维效率显著提升,运维人员投入减少。磐维数据库架构和管理方式让运维工作更加便捷高效,也能更及时地处理系统出现的各类问题,保障业务稳定运行。 - 成本降低:
在数据库软件许可成本上,单台 x86 主机的 license 费用大幅下降。同时,通过采用性价比高的本地存储代替昂贵集中存储,硬件成本也得到控制。 - 自主可控与安全性增强:
实现关键基础软件自主可控,减少对国外产品依赖,降低潜在风险。在数据安全性上更有保障,进一步确保数据不丢失、不出错,满足存储和访问的高安全要求。
