




字符串类型是数据库中最常用的数据类型之一,在 PostgreSQL 数据库中,字符串类型的选择看似简单,却暗藏玄机。不少开发者在设计表结构时,会下意识地选择char(n)类型存储固定长度的字符串,认为它比varchar或text更高效。但实际情况恰恰相反,在PostgreSQL中,char类型往往是数据库的 “空间杀手” 和 “性能杀手”。
PostgreSQL中的字符串数据类型
我们先来了解一下PostgreSQL中的字符串类型,PostgreSQL中支持的字符串类型如下表:
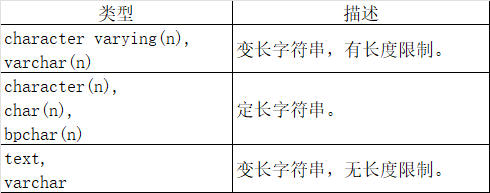
关于PostgreSQL中的字符串类型,我总结出了以下的知识点:
varchar(n)是character varying(n)的别名,char(n)和bpchar(n)则是character(n)的别名,其中n是正整数,代表声明这两种数据类型可以存储长度不超过n个字符的字符串。
如果将长度大于n的字符串插入这两种数据类型的列中,如果末尾超过长度的字符都是空格,则多余的字符会被截断,否则将插入失败。
testdb=# CREATE TABLE t1 (col_char char(5),testdb-# col_varchar varchar(5));CREATE TABLEtestdb=# INSERT INTO t1 VALUES ('12345 ','12345 ');INSERT 0 1testdb=# INSERT INTO t1 VALUES ('1234 ','1234 ');INSERT 0 1testdb=# SELECT col_char,testdb-# octet_length(col_char) as length_char,testdb-# col_varchar,testdb-# octet_length(col_varchar) as length_varchartestdb-# FROM t1;col_char | length_char | col_varchar | length_varchar----------+--------------+-------------+--------------12345 | 5 | 12345 | 51234 | 5 | 1234 | 5(2 rows)testdb=# INSERT INTO t1 VALUES ('123456','123456');ERROR: value too long for type character(5)
如果将长度小于n的字符串插入varchar(n)类型的字段时,数据库中会存储实际长度的字符串;将长度小于n的字符串插入char(n)类型的字段时,数据库将存储长度为n的字符串,字符串的末尾会补充空格。
testdb=# INSERT INTO t1 VALUES ('123','123');INSERT 0 1testdb=# SELECT col_char,testdb-# octet_length(col_char) as length_char,testdb-# col_varchar,testdb-# octet_length(col_varchar) as length_varchartestdb-# FROM t1;col_char | length_char | col_varchar | length_varchar----------+--------------+-------------+--------------12345 | 5 | 12345 | 51234 | 5 | 1234 | 5123 | 5 | 123 | 3(3 rows)
如果varchar类型未声明长度,则等同于没有长度限制;char类型未声明长度,则等同于char(1)。
testdb=# CREATE TABLE t2 (col_char char,col_varchar varchar);CREATE TABLEtestdb=# \d+ t2Table "public.t2"Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description-------------+-------------------+-----------+----------+---------+----------+-------------+--------------+-------------col_char | character(1) | | | | extended | | |col_varchar | character varying | | | | extended | | |Access method: heap
text类型是PostgreSQL的原生字符串数据类型,可以认为其等同于不声明长度的varchar类型。
在对char类型的字符串比较时,会自动截断字符串末尾空格;在对varchar和text的字符串比较时,会严格判断整个字符串。
testdb=# select 'abc '::char(5) = 'abc';?column?----------t(1 row)testdb=# select 'abc '::varchar(5) = 'abc';?column?----------f(1 row)testdb=# select 'abc '::text = 'abc';?column?----------f(1 row)testdb=# select 'abc '::varchar(3) = 'abc';?column?----------t(1 row)
PostgreSQL中字符串类型允许存储的字符串长度约为1GB。
PostgreSQL中认为不超过126 bytes的字符串是短字符串,超过126 bytes的字符串为长字符串。存储一个短字符串需要1 byte的额外存储空间,存储一个长字符串需要4 byte的额外存储空间,但存储长字符串时,数据库会将其自动压缩。
testdb=# CREATE TABLE t3(col varchar);CREATE TABLEtestdb=# INSERT INTO t3 VALUES ('a');INSERT 0 1testdb=# INSERT INTO t3 SELECT repeat('a', 128);INSERT 0 1testdb=# SELECT length(col),pg_column_size(col) FROM t3;length | pg_column_size--------+----------------1 | 2128 | 132(2 rows)
为什么char可能成为“空间杀手”
由于char类型“存储固定长度字符串”和“自动填充空格”的特性,不当的使用char类型时,可能会大量浪费存储空间。
以下就是一个使用char数据类型不当的例子,这个例子中,val字段使用char类型时,数据表和索引占用的存储空间远远超过了val字段使用varchar类型:
testdb=# CREATE TABLE test1 (id int PRIMARY KEY,val varchar(100));CREATE TABLEtestdb=# CREATE TABLE test2 (id int PRIMARY KEY,val char(100));CREATE TABLEtestdb=# INSERT INTO test1 SELECT id, id::text FROM generate_series(1,500000) id;INSERT 0 500000testdb=# INSERT INTO test2 SELECT id, id::text FROM generate_series(1,500000) id;INSERT 0 500000testdb=# SELECT octet_length(val) FROM test1 WHERE id=1;octet_length--------------1(1 row)testdb=# SELECT octet_length(val) FROM test2 WHERE id=1;octet_length--------------100(1 row)testdb=# CREATE INDEX idx_test1_val ON test1(val);CREATE INDEXtestdb=# CREATE INDEX idx_test2_val ON test2(val);CREATE INDEXtestdb=# SELECT pg_size_pretty(pg_table_size('test1')) AS table_size,testdb-# pg_size_pretty(pg_indexes_size('test1')) AS index_size;table_size | index_size------------+------------21 MB | 11 MB(1 row)testdb=# SELECT pg_size_pretty(pg_table_size('test2')) AS table_size,testdb-# pg_size_pretty(pg_indexes_size('test2')) AS index_size;table_size | index_size------------+------------67 MB | 63 MB(1 row)
为什么char可能会成为“性能杀手”
不当使用char数据类型,对性能的影响在以下方面:
使用char类型时,单行记录所占空间可能变大,会导致一个数据页中能容纳的记录数减少,查询时就需要读取更多的数据页,间接增大了磁盘的I/O压力。
在对char类型的字段创建索引时,索引中存储的是包含填充空格的完整字符串。这不仅增加了索引占用的存储空间,还会降低索引的查询效率,因为索引树需要处理更长的字符串,查找和比对的速度自然变慢。
PostgreSQL在对char类型的字符串进行比较时,会先自动截断末尾的空格,再进行比较,“截断”操作也是额外的开销。
另外,在生产中,我们可能还会遇到一些小马虎,他们将两个表需要关联的列,分别创建为varchar类型和char类型。这就导致了查询时,会发生了隐式转换,导致本应使用索引扫描的查询使用了全表扫描,导致SQL效率低下。
我们继续使用刚才的test1表和test2表来举例:
第一个例子,我们使用test1表(val字段为varchar类型)自己和自己关联,可以看到下面的执行计划中触发了优化器的“常量传递”特性,虽然过滤条件是t1.val='1',但是执行计划中t2使用索引扫描,其条件也是t2.val='1'。
testdb=# EXPLAIN SELECT * FROM test1 t1, test1 t2 WHERE t1.val=t2.val AND t1.val='1';QUERY PLAN-------------------------------------------------------------------------------------Nested Loop (cost=0.84..5.69 rows=1 width=20)-> Index Scan using idx_test1_val on test1 t1 (cost=0.42..2.84 rows=1 width=10)Index Cond: ((val)::text = '1'::text)-> Index Scan using idx_test1_val on test1 t2 (cost=0.42..2.84 rows=1 width=10)Index Cond: ((val)::text = '1'::text)(5 rows)
第二个例子,test1表和test2表通过不同数据类型的val字段来进行关联,过滤条件是varchar类型的t1.val,这里就没有触发优化器的“常量传递”特性,t2虽然使用了索引扫描,但其过滤条件为t2.val=t1.val,该执行计划的cost是5.81略高于上一个例子的5.69。
testdb=# EXPLAIN SELECT * FROM test1 t1, test2 t2 WHERE t1.val=t2.val AND t1.val='1';QUERY PLAN--------------------------------------------------------------------------------------Nested Loop (cost=0.97..5.81 rows=1 width=115)-> Index Scan using idx_test1_val on test1 t1 (cost=0.42..2.84 rows=1 width=10)Index Cond: ((val)::text = '1'::text)-> Index Scan using idx_test2_val on test2 t2 (cost=0.55..2.96 rows=1 width=105)Index Cond: (val = (t1.val)::bpchar)(5 rows)
第三个例子,test1表和test2表通过不同数据类型的val字段来进行关联,过滤条件是char类型的t2.val,这里可以看到t1表无法使用索引,而采用了全表扫描,cost远高于前两个例子。
testdb=# EXPLAIN SELECT * FROM test1 t1, test2 t2 WHERE t1.val=t2.val AND t2.val='1';QUERY PLAN--------------------------------------------------------------------------------------Nested Loop (cost=0.55..8954.98 rows=1 width=115)-> Seq Scan on test1 t1 (cost=0.00..8952.00 rows=1 width=10)Filter: ((val)::bpchar = '1'::bpchar)-> Index Scan using idx_test2_val on test2 t2 (cost=0.55..2.96 rows=1 width=105)Index Cond: (val = '1'::bpchar)(5 rows)
总结
在PostgreSQL中,建议不使用char类型来存储字符串,如果需要限制存储字符串的长度,可以使用varchar(n),如果存储的字符串不限制长度,那么使用varchar或者text均可。
附:在PostgreSQL官方手册中,也明确指出了虽然char(n)在其他数据库中可能具有一些性能优势,但在PostgreSQL中,char(n)通常性能都不如varchar(n)或者text。

官方手册链接:
https://www.postgresql.org/docs/current/datatype-character.html
