




温故而知新,分享也是温习。
linux硬盘检测健康状态检查
服务器硬盘是SATA的,使用下面的命令来确认硬盘是否打开了SMART支持
smartctl -i /dev/sda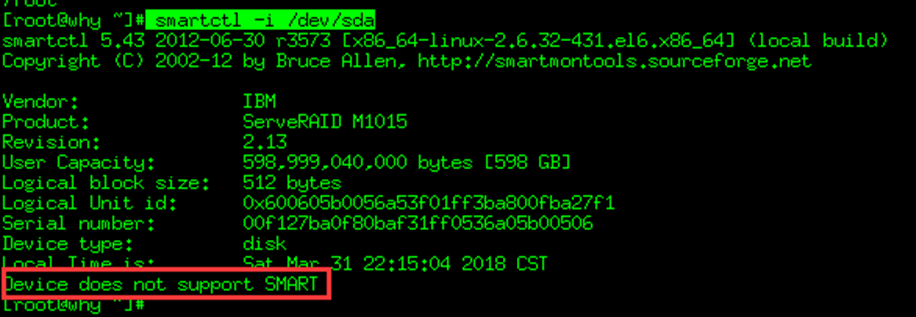
在这里,如果看到SMART support is: Disabled或者 Device does not support SMART,则表示SMART未启用
如果我们需要执行如下命令,启动SMART:
代码如下:
smartctl –smart=on –offlineauto=on –saveauto=on /dev/sda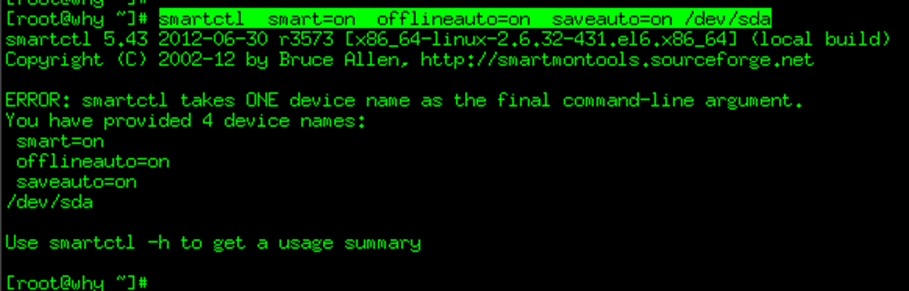
查看sda硬盘当前的健康状态使用如下命令
smartctl -H /dev/sda

在 Linux 系统下检查硬盘健康状态,主要依赖于 SMART 技术,并结合一些其他工具来检查磁盘错误。以下是详细的方法和步骤。
核心方法:使用 SMART 工具
SMART(Self-Monitoring, Analysis and
Reporting Technology)是现代硬盘和固态硬盘都支持的一种自我监测、分析和报告技术。它是判断硬盘健康状况的首要和最直接的方法。
1. 安装 SMART 工具包
在大多数 Linux 发行版上,工具包名为 smartmontools。
- Debian/Ubuntu:
sudo apt update && sudo apt install smartmontools- RHEL/CentOS/Fedora:
sudo yum install smartmontools # 旧版 RHEL/CentOS
sudo dnf install smartmontools # Fedora / RHEL 8+2. 识别磁盘设备名
首先,你需要知道要检查的硬盘的设备名(如 /dev/sda, /dev/nvme0n1)。
使用 lsblk或 fdisk命令:
lsblk
# 或者
sudo fdisk -l输出示例:
NAME
MAJ:MIN RM SIZE RO TYPE
MOUNTPOINT
sda
8:0 0 931.5G 0 disk
├─sda1
8:1 0 512M
0 part /boot/efi
└─sda2
8:2 0 931G
0 part /
nvme0n1
259:0 0 476.9G 0 disk
├─nvme0n1p1 259:1 0
512M 0 part /boot
└─nvme0n1p2 259:2 0 476.4G
0 part /
这里有两块盘:一块 SATA 硬盘 (sda) 和一块 NVMe 固态硬盘 (nvme0n1)。
重要提示:NVMe 盘和 SATA/SCSI 盘的设备名和 SMART 命令参数不同。
针对 SATA /
SAS / SCSI 硬盘(例如 /dev/sda)
3. 查看 SMART 基本信息(整体健康状态)
使用 smartctl -H命令可以快速查看硬盘的“通过/失败”健康状态。
sudo smartctl -H /dev/sda输出示例:
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test
result: PASSED
PASSED 表示健康,FAILED 表示硬盘即将出现故障,应立即备份数据。
4. 查看详细的 SMART 属性数据
smartctl -A命令会显示详细的属性表,这是诊断问题的关键。
sudo smartctl -A /dev/sda输出示例(部分重要属性):
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED
WHEN_FAILED RAW_VALUE
5
Reallocated_Sector_Ct 0x0033
100 100 010
Pre-fail Always -
0
9
Power_On_Hours 0x0032 092
092 000 Old_age Always
- 6523
187 Reported_Uncorrect 0x0032
100 100 000 Old_age
Always - 0
194 Temperature_Celsius 0x0022
064 055 000
Old_age Always -
36 (Min/Max 20/45)
197 Current_Pending_Sector 0x0012
100 100 000
Old_age Always -
0
198 Offline_Uncorrectable 0x0010
100 100 000
Old_age Offline -
0
199 UDMA_CRC_Error_Count 0x003e
200 200 000
Old_age Always -
0
需要重点关注的关键属性:
- Reallocated_Sector_Ct(重新分配扇区计数): RAW_VALUE 不为 0 表示硬盘已有坏道,并用备用扇区替换了。数值持续增长是坏兆头。
- Current_Pending_Sector(当前待处理扇区数): RAW_VALUE 不为 0 表示有扇区读写失败,正在等待决定是重新分配还是修复。这是严重警告!
- Offline_Uncorrectable(无法校正的扇区数): 无法修复的坏道数量。
- UDMA_CRC_Error_Count: 通常与数据线或接口连接问题有关,不一定是硬盘本身故障,但值得检查线缆。
5. 运行 SMART 测试
你可以手动发起测试,更主动地检测问题。
- 短测试(通常几分钟完成):
sudo smartctl -t short /dev/sda- 长测试(全面检查,可能需数小时,不要中断):
sudo smartctl -t long /dev/sda- 查看测试结果:
sudo smartctl -l selftest /dev/sda
针对 NVMe 固态硬盘(例如 /dev/nvme0n1)
NVMe 的命令语法不同,但逻辑相似。
查看健康信息
sudo smartctl -H /dev/nvme0n1查看详细信息(更易读)
重点关注输出中的 SMART/Health
Information 部分:
- percentage_used: 寿命损耗百分比,越高说明磨损越严重。
- critical_warning: 任何非 0 值都表示严重问题。
- media_errors, num_err_log_entries: 错误计数,越高越不好。
- temperature: 温度信息。
运行测试
# 发起设备自检
sudo smartctl -t device self-test /dev/nvme0n1
# 查看测试日志
sudo smartctl -l selftest /dev/nvme0n1
其他辅助检查方法
1. 查看内核日志
使用 dmesg命令查看内核环缓冲区日志,经常能发现硬盘报告的 I/O 错误。
dmesg | grep -i sda # 将 sda 替换为你的设备名
dmesg | grep -i error如果看到大量关于磁盘的 I/O 错误报告,说明硬盘可能存在问题。
2. 使用 badblocks命令(谨慎使用!)
此命令用于扫描磁盘坏道,但它是一个写测试,会对数据造成风险,强烈建议在新盘上使用,或确保已有完整备份。
只读模式扫描(相对安全):
sudo badblocks -v -s /dev/sda > bad-blocks.txt完成后,可以将坏道信息通知文件系统(如 ext4):
sudo e2fsck -l bad-blocks.txt /dev/sda1操作总结与建议
- 1.定期检查: 使用 sudo smartctl -H /dev/你的磁盘定期检查健康状态,可以设置为每月一次的 cron 任务。
- 2.关注变化: 详细属性 (smartctl -A) 中的 RAW_VALUE 值是否在持续增长比其绝对值更重要。
- 3.听声音: 机械硬盘如果发出异常的“咔嗒”声(click of death),通常是物理故障的征兆,应立即备份。
- 4.性能监控: 如果系统变得异常卡顿,I/O 等待时间 (wa) 很高(可用 top或 iostat查看),也可能是磁盘故障的前兆。
- 5.备份是关键: 任何磁盘健康检查工具都不能 100% 预测故障。唯一能保护数据的方法就是定期备份!
