




如果给梧桐数据库插上向量的翅膀
引子:AI时代的数据库缺什么?
在过去的几十年里,数据库技术的发展几乎伴随了整个信息化浪潮。从最早的行式存储关系型数据库,到后来为数据仓库而生的列式存储,再到云原生架构下的分布式分析型数据库——梧桐数据库正是这一发展脉络中的最新成果之一。它的核心优势在于:高扩展性、高并发处理能力,以及对复杂数据分析场景的良好支持。
然而,时代的风向正在发生变化。随着深度学习和大模型的兴起,数据的形态已经不再局限于传统的结构化表格。越来越多的业务场景涉及到 非结构化数据:文本、图像、语音、视频……甚至是传感器产生的时间序列数据。问题随之而来:
- 传统 SQL 查询擅长处理结构化数据,但在语义检索、相似度计算方面显得笨拙。
- 用户希望问一句“过去三个月关于新能源车的客户反馈”,数据库却只能返回精准匹配的字符串,而无法理解“新能源车”与“电动车”之间的语义关联。
- 企业正在尝试把大模型(如 ChatGPT、通义千问、DeepSeek 等)应用到业务中,可是这些模型背后的关键引擎——向量数据库,还没有很好地融入企业现有的数据库体系。
用一句比喻来说:
梧桐数据库如今是一架“性能出色的喷气飞机”,但面对 AI 时代的天空,它还缺少一对能够翱翔更高的“翅膀”。而这对翅膀,正是 向量支持。
数据形态的演变
我们不妨先看看数据形态的变化:
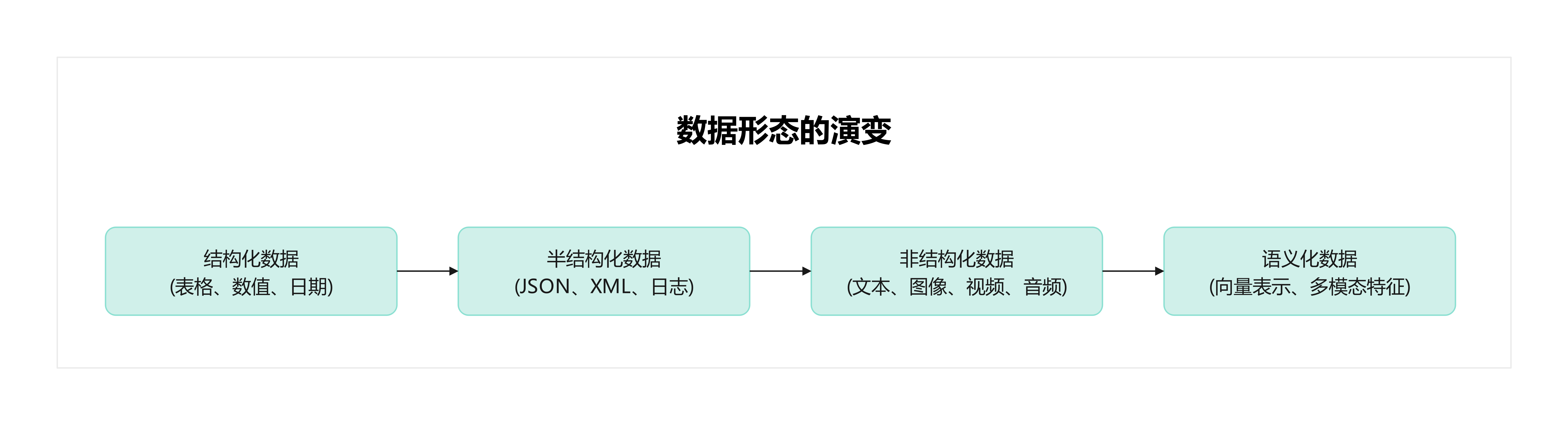
在这个演变过程中,传统关系型数据库在 A 阶段无可替代;Hadoop、Spark 等大数据体系在 B 阶段大放异彩;而到了 C 和 D 阶段,新的需求正在催生 向量数据库。
一个具体的例子
假设我们在梧桐数据库里存放了大量的客户反馈文本。如果用传统 SQL 来做检索,语句可能是这样的:
-- 查找包含“新能源车”的反馈
SELECT feedback_id, content
FROM customer_feedback
WHERE content LIKE '%新能源车%';
这当然能找到结果,但它无法识别“新能源车”和“电动车”、“EV”之间的语义相似性。
而如果有了向量支持,查询就能升级为:
-- 用向量相似度来查找与“新能源车”语义相近的反馈
-- embedding <-> query_vec 表示计算向量的余弦相似度或欧式距离
SELECT feedback_id, content
FROM customer_feedback
ORDER BY embedding <-> '[0.21, 0.45, -0.12, ...]' -- 这里是“新能源车”的向量表示
LIMIT 10;
这时候,数据库就不再只是“精确匹配的工具”,而是能理解语义、发现相似性的“智能引擎”。
梧桐数据库的基础能力
要谈“插上向量支持的翅膀”,首先得看看梧桐数据库本身的基础有多扎实。毕竟,只有底座足够稳固,才能承载新的能力。
WuTongDB 的定位是 云原生分析型数据库,它的核心价值在于:既能支撑高并发 OLTP(联机事务处理),又能应对大规模 OLAP(联机分析处理)。这让它不仅能处理日常的业务数据,还能承担企业级的数据仓库与分析任务。
下面,我们从几个关键方面来看看它的“内功”。
多样化的存储格式
梧桐数据库的存储层设计非常灵活,它支持四种主要的存储格式:
- ROW:传统的行存储,适合实时读写。
- ORC:高效的列存储,擅长大规模分析场景。
- Hudi:支持增量数据,特别适合实时数据摄取与更新。
- MagmaAP:新一代行列混合存储,既有事务支持,也有索引能力。
简单来说,不同的格式各有优点:
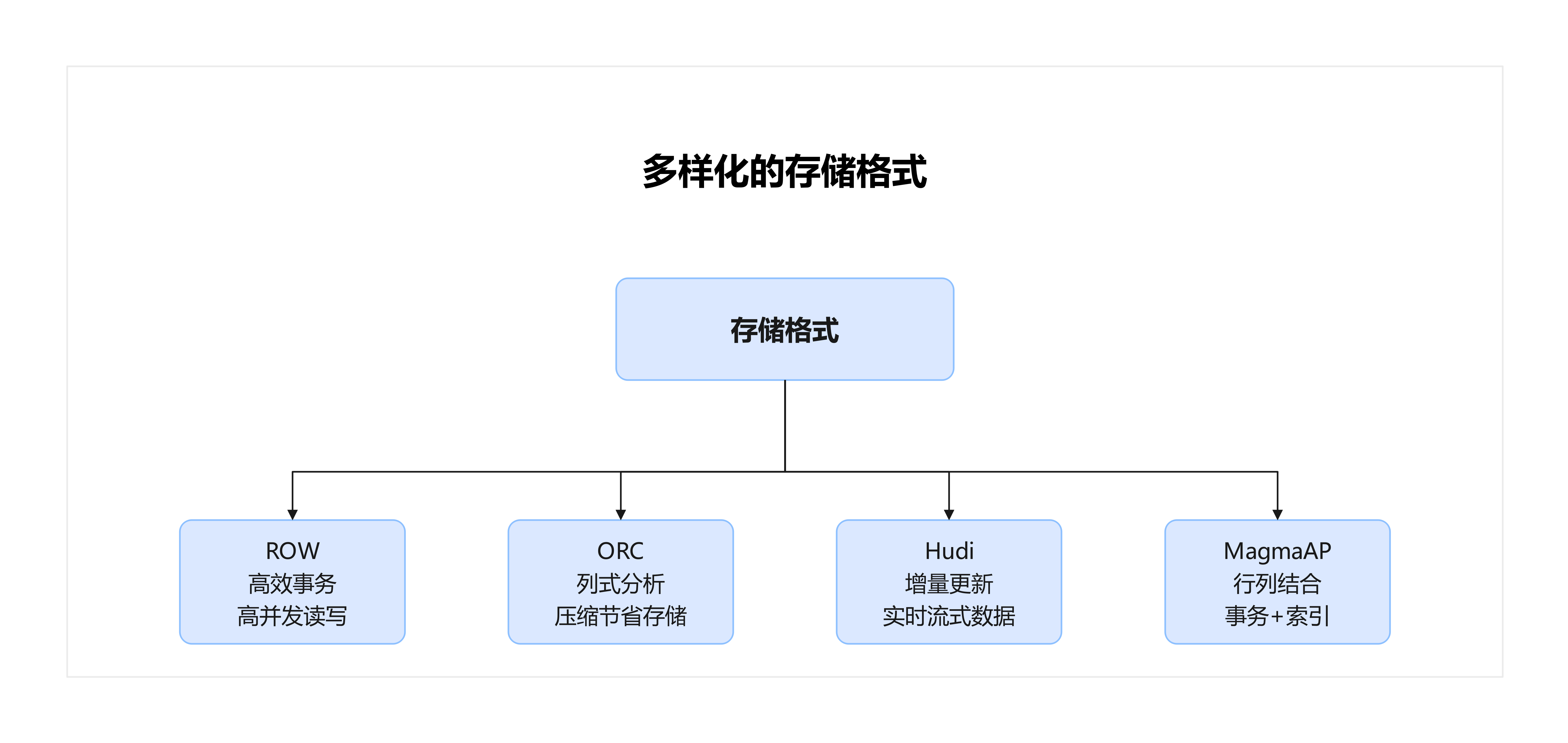
可以看到,梧桐数据库的存储体系就像“积木”,企业可以根据业务需要选择最合适的存储模式。
分布式执行与弹性扩展
WuTongDB 采用 Master + Segment 的分布式架构:
- Master:负责全局元数据管理和调度。
- Segment:负责数据存储和计算任务。
这种架构的好处是 可横向扩展。当数据量变大或者并发压力增高时,可以通过增加 Segment 节点来提升性能。
同时,WuTongDB 内置了 资源管理器,能够在不同任务之间动态分配资源,实现混合负载下的弹性调度。
灵活的数据分布策略
数据在集群里如何分布,直接关系到查询效率。WuTongDB 提供了两种主要的分布方式:
- Random 分布:随机分布到各个节点,扩容时无需重新分布,适合灵活扩展。
- Hash 分布:按照某个字段的哈希值分布,查询时可以避免数据重分布,性能更优。
举个例子:如果要创建一张按 user_id 哈希分布的表,可以这样写:
-- 创建一个哈希分布的用户表
-- 数据会根据 user_id 的哈希值分布到多个节点
CREATE TABLE users (
user_id bigint,
name text,
email text
)
DISTRIBUTED BY (user_id);
而如果不指定分布方式,系统默认会用 Random:
-- 创建一个随机分布的订单表
-- 扩容时不需要重分布数据
CREATE TABLE orders (
order_id bigint,
user_id bigint,
amount decimal(10,2),
created_at timestamp
)
DISTRIBUTED RANDOMLY;
这种灵活性让 WuTongDB 在面对不同业务场景时都能找到最优解。
丰富的数据类型
与传统数据库相比,梧桐数据库在数据类型上更接近 PostgreSQL 的生态:
- 基本类型:整数、浮点、字符、日期/时间。
- 扩展类型:JSON/JSONB、数组、范围、几何、网络地址等。
- 多样化存储:支持 XML、UUID、枚举类型。
比如,存储 JSON 数据:
-- 创建一个 JSONB 类型的反馈表
-- 适合存储半结构化的用户反馈
CREATE TABLE feedback (
id serial primary key,
user_id bigint,
content jsonb,
created_at timestamp default now()
);
这为后续引入“向量类型”打下了很好的基础。
与外部生态的互通
WuTongDB 不是“孤岛”,它支持外部表机制,可以与 HDFS、Hive、HTTP、gpfdist 等外部系统打通。
例如,通过 HDFS 外部表导入数据:
-- 定义一个 ORC 格式的 HDFS 外部表
CREATE EXTERNAL TABLE sales_ext (
order_id bigint,
user_id bigint,
amount decimal(10,2)
)
LOCATION ('hdfs://namenode:8020/data/sales')
FORMAT 'orc';
这样一来,企业在数据湖、数仓、流处理系统里已有的数据,都可以无缝接入 WuTongDB,进一步进行分析和建模。
为什么是向量?为什么是现在?
向量的本质
简单来说,向量是一组高维的浮点数,它可以用来表示文本、图像、语音等复杂数据的“语义特征”。
例如:
- 一句话经过大模型处理,可以得到一个 768 维或 1536 维的向量。
- 一张图片可以被转换成几千维的向量,每一维代表一种抽象的语义特征。
- 不同对象之间的 相似度 就是通过计算它们的向量距离来衡量的(常见方法有欧式距离、余弦相似度)。
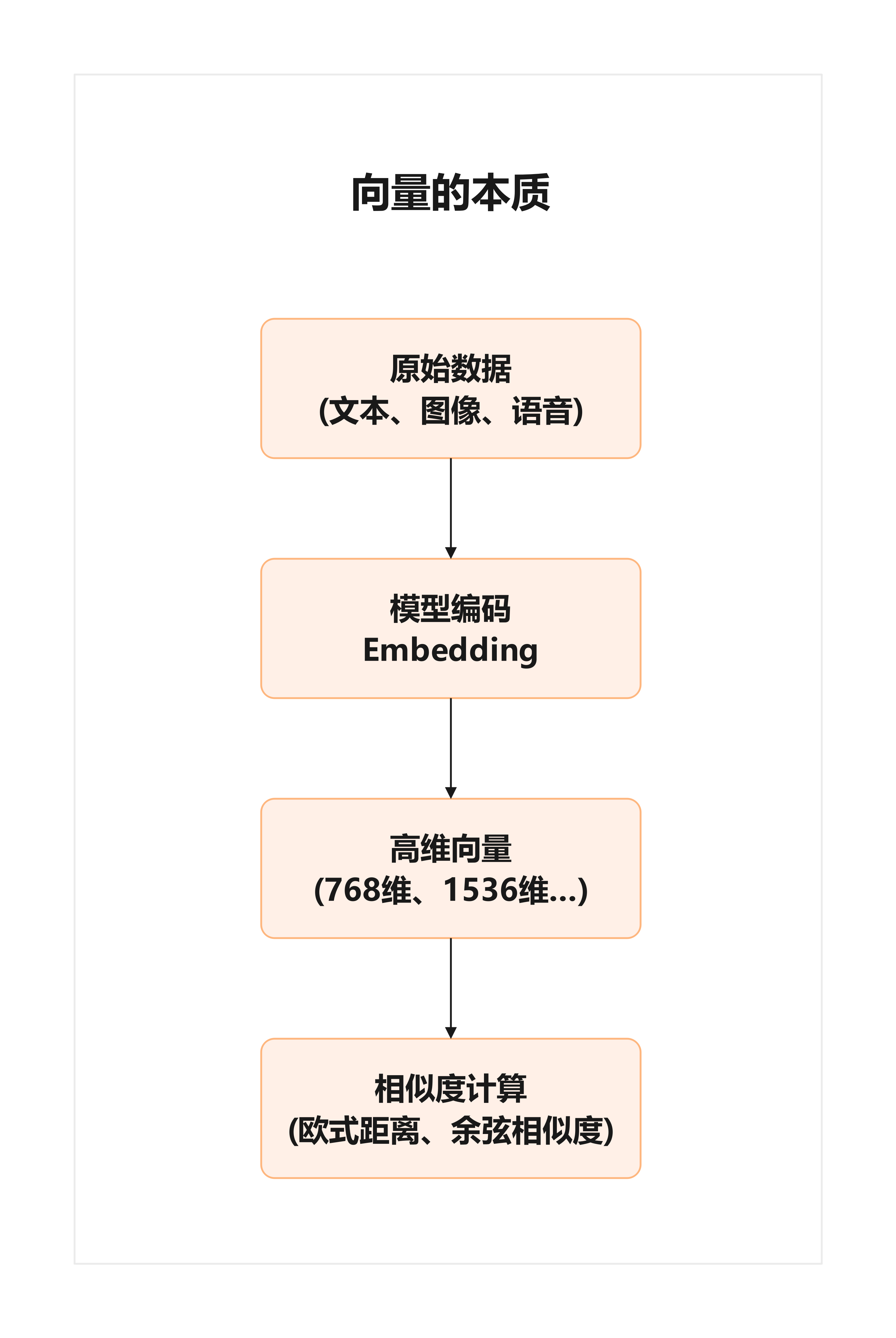
这种表示方式让计算机不再只是“看见字符串”,而是“理解语义空间中的位置”。
向量检索的关键能力
引入向量后,数据库需要具备三项新的核心能力:
- 向量存储
- 提供
vector[N]类型,支持存储高维浮点数数组。 - 能够压缩或稀疏化,节省存储空间。
- 提供
- 向量索引
- 建立高效的 近似最近邻索引(ANN),常见算法包括:
- HNSW(基于图的检索)
- IVF(分区倒排索引)
- PQ(乘积量化压缩)
- 建立高效的 近似最近邻索引(ANN),常见算法包括:
- 向量检索语法
- 在 SQL 中引入相似度查询的表达式,例如:
-- 用余弦相似度查找最相近的前10条记录
-- <-> 表示相似度计算运算符
SELECT doc_id, content
FROM documents
ORDER BY embedding <-> '[0.12, -0.34, 0.98, ...]' -- 查询向量
LIMIT 10;
这样,数据库就能支持“语义检索”,而不仅仅是关键字搜索。
为什么是现在?
有人可能会问:向量检索并不是一个全新的概念,为什么到今天才被如此重视?
答案在于 AI 大模型的爆发:
- 大模型的广泛应用,使得 生成向量(embedding) 的门槛极大降低。
- 企业在构建智能应用(RAG、智能客服、推荐引擎)时,几乎都需要 向量数据库 来做语义检索。
- 传统数据库与向量数据库割裂,企业数据孤岛问题进一步加剧。
所以,今天的痛点是:
- 业务数据 在梧桐数据库里,
- 语义检索数据 在 Milvus、Pinecone 等独立向量库里,
- 数据流转成本高,而且 一致性难保证。
这就导致了一个尴尬的局面:企业不得不维护两套系统,既要保证事务型/分析型数据库的稳定,又要兼顾向量库的实时性。
典型应用场景
为了更直观地理解向量的价值,我们不妨看几个实际的业务场景:
- 企业知识库问答(RAG)
用户问:“公司去年的新能源车销售情况如何?”
→ 系统先把问题转成向量 → 在知识库向量索引里找到最相关的文档 → 再结合 SQL 分析结果 → 给出回答。 - 推荐系统
用户浏览了几篇关于 AI 的文章,系统要推荐更多相关文章。
→ 把文章转化为向量 → 相似度检索 → 找到最相关的内容。 - 金融风控
一笔交易的特征向量与历史正常交易不太一样 → 触发风控模型。 - 多模态应用
图片、语音、文本的 embedding 融合到同一个数据库里,实现跨模态检索。
如果梧桐数据库拥有向量支持,会怎样?
新的数据类型:向量字段
第一步,自然是引入新的数据类型,例如 vector[N]。
这样,开发者就能在表结构里直接定义向量列,而不是再依赖外部系统存储 embedding。
-- 创建一个带向量字段的文档表
-- embedding 用来存储文本的语义向量
CREATE TABLE documents (
doc_id bigint primary key,
title text,
content text,
embedding vector(768) -- 768维的向量表示
);
这种方式的意义在于:数据与语义特征存储在一起,不用在业务逻辑层做额外拼接。
新的索引与检索能力
有了向量字段,就需要新的索引机制来加速查询。
常见的 ANN(近似最近邻)索引算法,比如 HNSW、IVF、PQ,都可以被集成到梧桐数据库的索引系统中。
建索引的语句可能是这样的:
-- 为向量字段创建 HNSW 索引
CREATE INDEX idx_documents_embedding
ON documents
USING hnsw (embedding);
检索时,SQL 可以直接调用相似度运算符 <->:
-- 查找与查询向量最相似的前10个文档
-- <-> 表示计算向量相似度(如余弦相似度)
SELECT doc_id, title, content
FROM documents
ORDER BY embedding <-> '[0.12, 0.34, -0.56, ...]'
LIMIT 10;
这样,SQL 不仅能做传统的“WHERE 条件筛选”,还能做“语义空间里的最近邻搜索”。
与分布式架构结合
向量检索在单机环境下已经很成熟,但企业的数据规模往往是 亿级、甚至百亿级 的。
梧桐数据库的优势正好在于 分布式架构,一旦与向量检索结合,就能形成“并行相似度搜索”的能力。
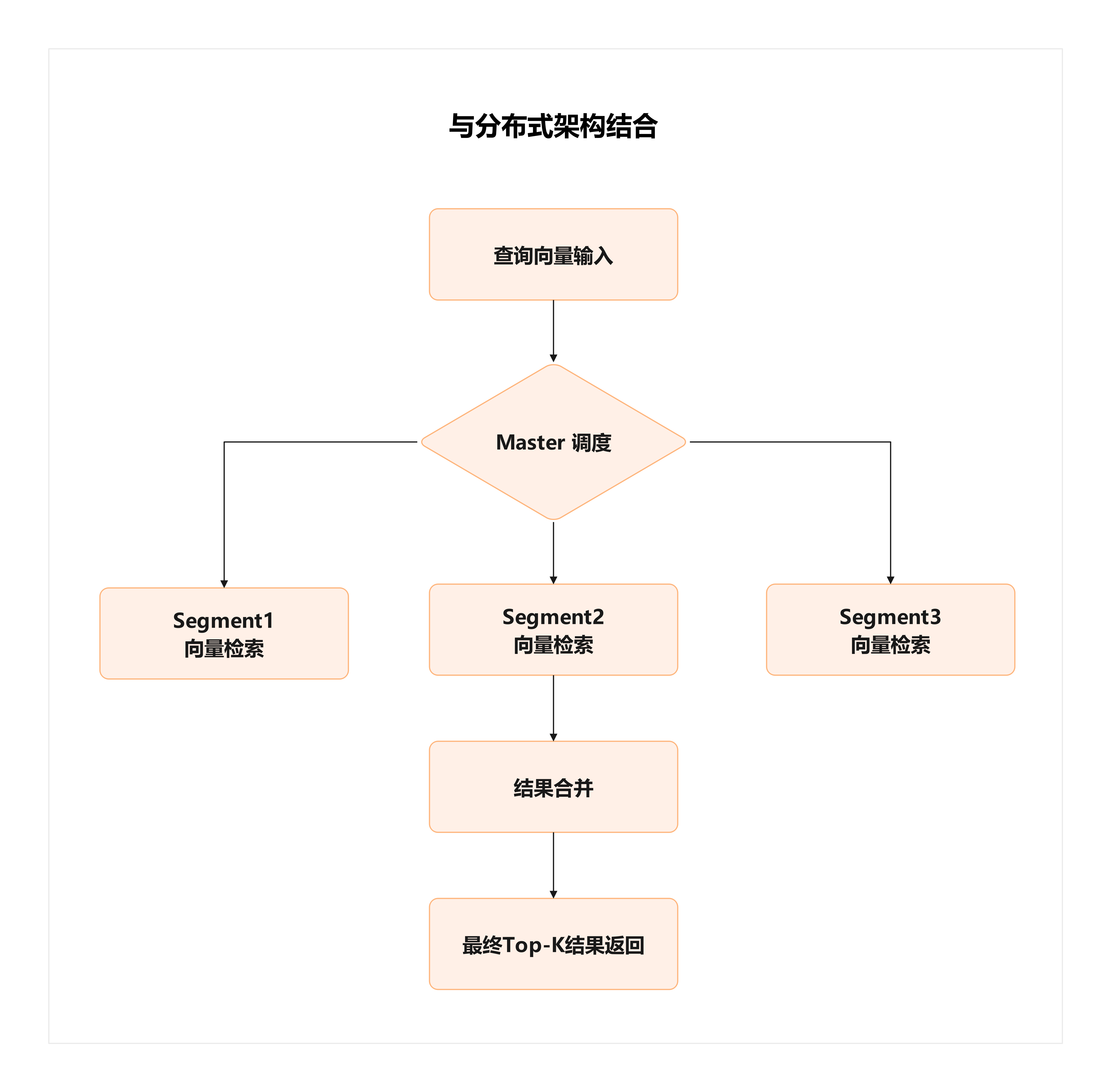
这种架构下,WuTongDB 就能在大规模向量检索场景中保持高性能,而不是被单机瓶颈卡住。
与生态系统的无缝融合
如果梧桐数据库支持向量类型,它就能直接与 大模型接口(如 OpenAI、通义千问、DeepSeek)结合:
- 数据导入时:先调用模型生成 embedding → 存入 WuTongDB 向量字段。
- 查询时:把用户输入转成向量 → 用 SQL 相似度查询。
这意味着,企业可以直接在梧桐数据库上实现 RAG(检索增强生成) 流程:
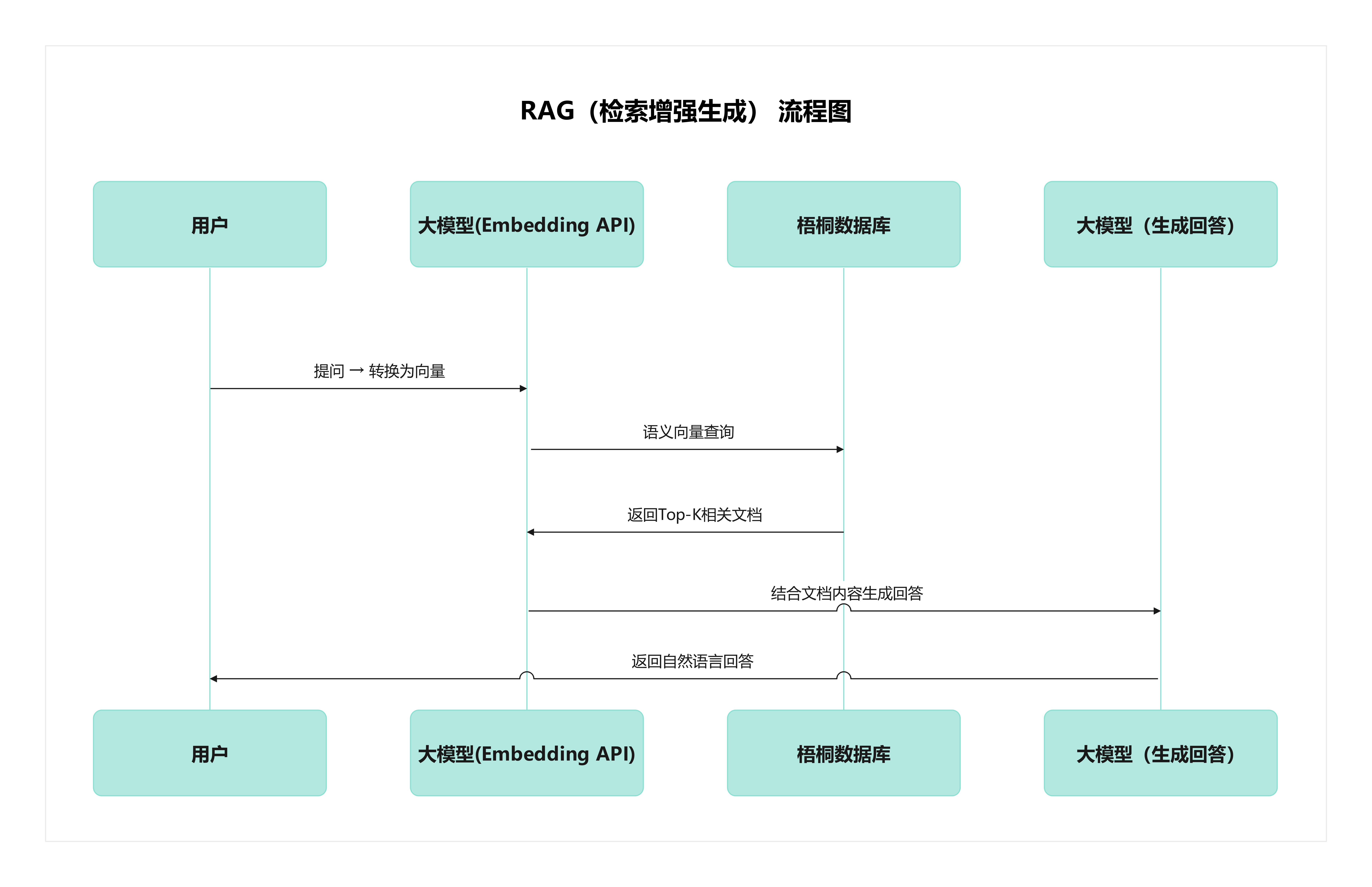
换句话说,梧桐数据库不仅是“数据仓库”,还能变成“知识中枢”。
新的应用场景
有了向量支持,梧桐数据库将拓展出许多全新的应用场景:
- 智能知识库问答
企业内部资料 → 转换为向量存入 WuTongDB → 实现内部版 ChatGPT。 - 个性化推荐系统
用户行为数据(Hudi 实时流) + 向量检索 → 实时推荐内容。 - 金融风控
交易向量特征库 + 向量相似度计算 → 异常检测与反欺诈。 - 多模态数据管理
图片、语音、文本向量统一存储 → 实现跨模态检索。
挑战与对策
存储与空间开销
挑战
- 向量通常是高维浮点数(如 768 维、1536 维),单条数据就可能占用数 KB。
- 一旦数据量上亿条,存储成本将呈指数级上升。
- 与传统列存储相比,向量存储缺乏天然的压缩优势。
对策
- 引入 稀疏存储 和 量化技术(如 PQ、OPQ),在不明显损失精度的前提下减少存储开销。
- 支持 冷热分层存储:常用向量存放在 SSD 上,历史向量迁移到磁盘/HDFS。
- 对接外部存储(对象存储、数据湖),避免数据库本体成为“存储黑洞”。
向量索引的复杂性
挑战
- 向量检索的核心在于 ANN(近似最近邻索引)。
- 不同算法适合不同场景:
- HNSW → 高精度、高性能,但内存占用大。
- IVF → 适合大规模数据,但召回率可能下降。
- PQ → 存储节省,但计算复杂。
- 如何在 WuTongDB 的 SQL 框架下优雅地引入这些索引,是一大难题。
对策
- 借鉴 PostgreSQL 的
pgvector扩展,先引入vector[N]类型和基本的<->运算符。 - 提供 插件化索引机制:用户可按需选择 HNSW、IVF、PQ 等索引类型。
- 在优化器层面,增加索引选择策略:在不同查询条件下,自动选择合适的索引。
-- 用户可以按需选择索引类型
CREATE INDEX idx_doc_embed_hnsw
ON documents USING hnsw (embedding);
CREATE INDEX idx_doc_embed_ivf
ON documents USING ivf (embedding) WITH (nlist=100);
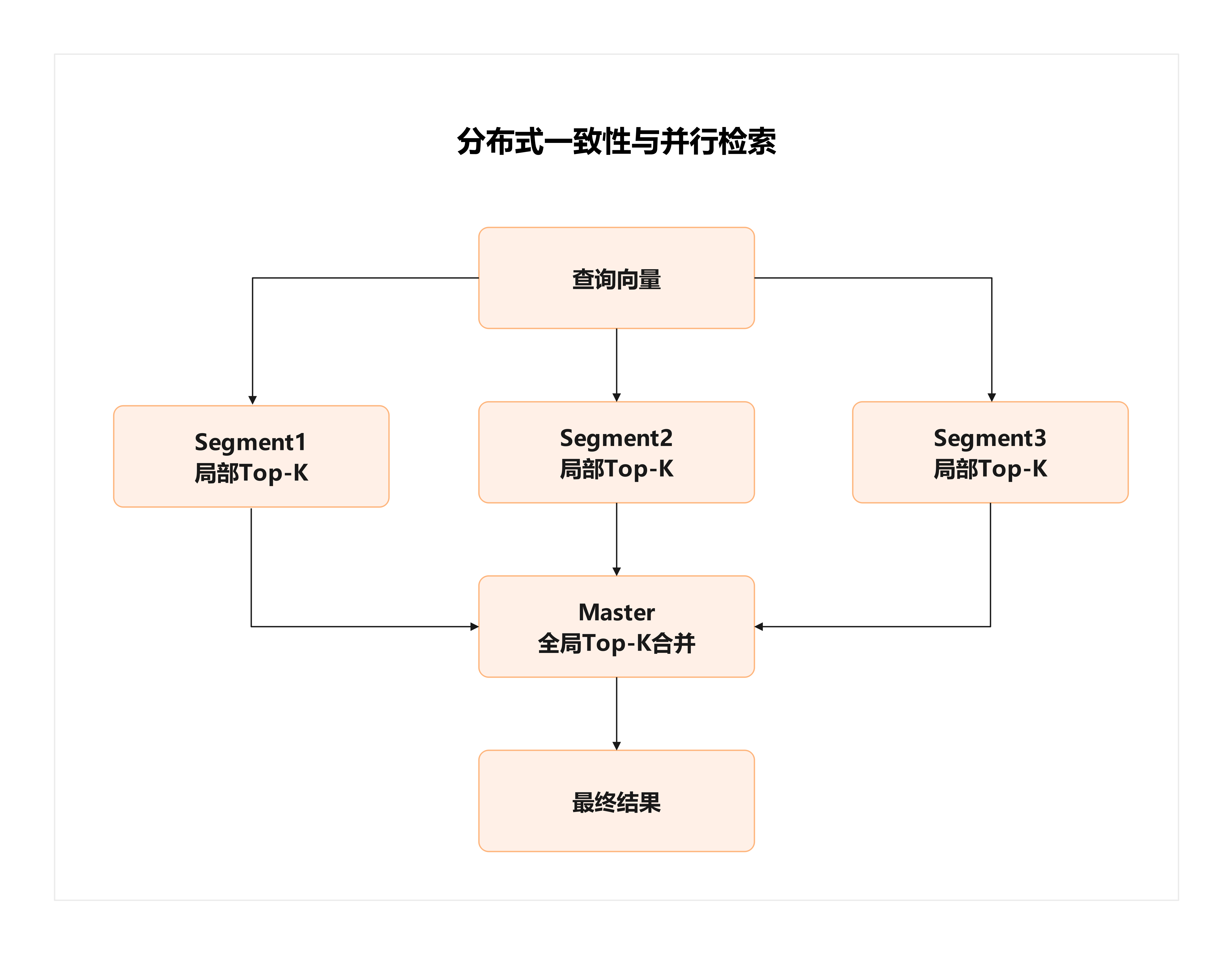
分布式一致性与并行检索
挑战
- 向量检索的瓶颈往往在“Top-K 合并”。
- 在分布式场景下,每个节点都返回局部 Top-K,如何快速合并成全局 Top-K?
- 节点扩容或缩容时,如何保证索引数据的重分布不影响查询性能?
对策
- 引入 分布式 ANN 合并算法(如基于归并的多路合并、近似候选池)。
- 结合梧桐数据库已有的 Hash/Random 分布策略,为向量列设计专用分布方案。
- 对索引支持 增量重建,避免全量重建造成长时间停机。
查询优化与 SQL 兼容性
挑战
- 现有 SQL 优化器主要面向传统算子(Join、Group By、Filter),对向量检索不够友好。
- 如何在 SQL 里同时写条件筛选 + 向量相似度查询?
- 如何在 Explain Analyze 里直观显示向量索引的执行计划?
对策
- 扩展 SQL 语法,使其支持混合查询:
-- 示例:同时按语义相似度和时间过滤
SELECT doc_id, content
FROM documents
WHERE created_at > '2024-01-01'
ORDER BY embedding <-> '[0.12, 0.98, -0.45, ...]'
LIMIT 5;
- 在优化器中增加 算子融合,例如:
- 先做时间过滤,再进行向量检索。
- 避免全量扫描,提高效率。
- 在 Explain Plan 中展示 向量索引使用情况,方便调优。
生态与兼容性
挑战
- 当前市场上已有专门的向量数据库(Milvus、Weaviate、Pinecone 等)。
- 企业可能会问:为什么要用梧桐数据库自带的向量支持,而不是接入这些成熟产品?
对策
- 强调 一体化优势:数据和向量在一个库里,避免跨系统数据同步。
- 提供 标准 API(兼容 pgvector 或 OpenAI embedding 接口)。
- 支持与 外部向量库互通:既能独立完成任务,也能协同外部库。
梧桐数据库的二次飞跃
一体化的智能数据库
如果梧桐数据库能够成功集成向量支持,它将成为一种真正的一体化数据库:
- 传统分析型任务 → 继续发挥行列混合存储和分布式执行的优势。
- AI 语义检索任务 → 借助向量索引和相似度查询,实现智能搜索。
- 融合场景 → 在同一条 SQL 里混合条件过滤与语义检索,让业务逻辑与智能分析天然融合。
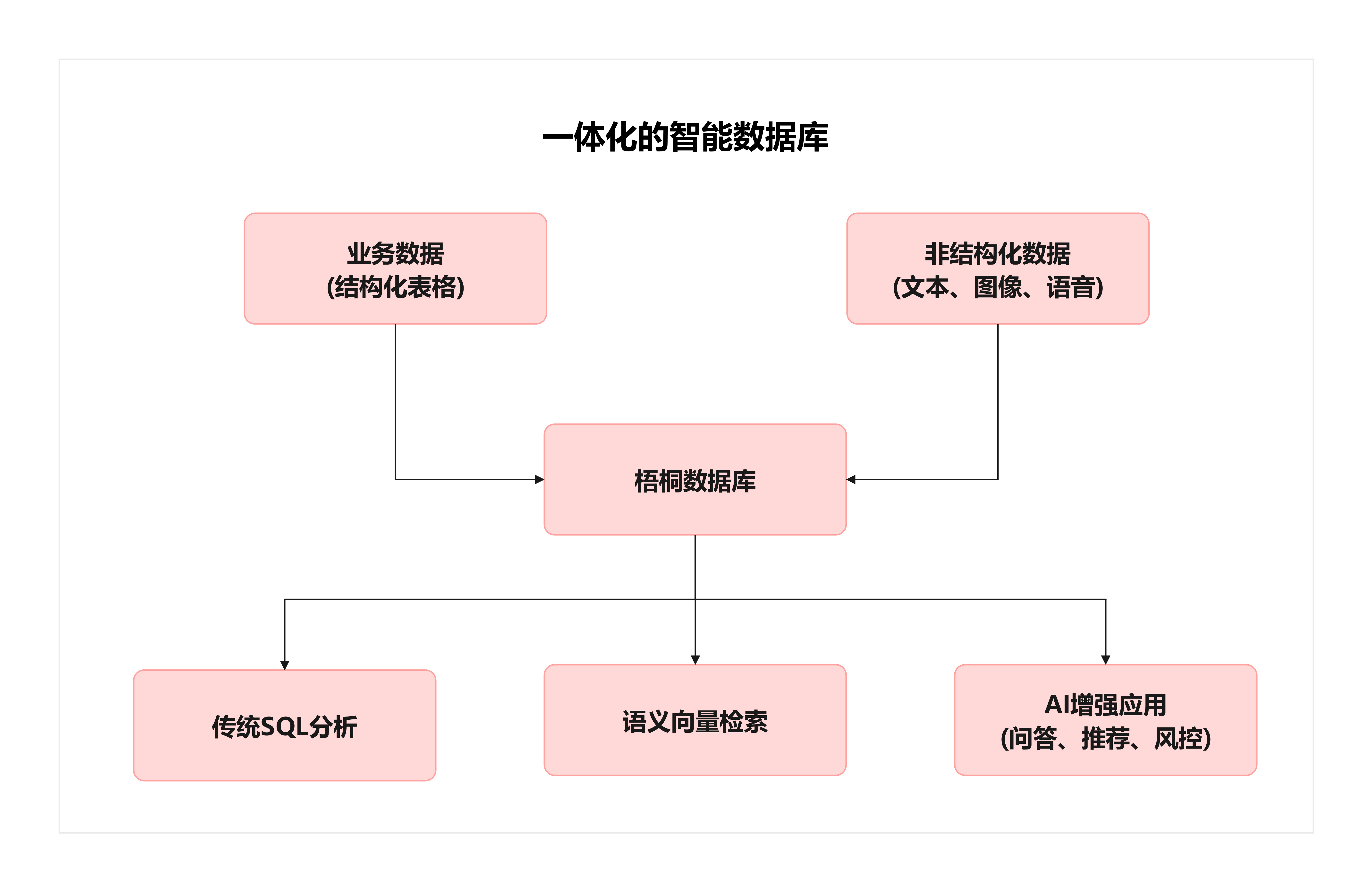
这种“一库多能”的形态,将极大降低企业的技术成本和系统复杂度。
与大模型的深度结合
向量是大模型和数据库之间的桥梁。
有了这层桥梁,梧桐数据库就能更紧密地嵌入 AI 应用的核心环节:
- RAG(检索增强生成):在 WuTongDB 中存储知识库向量,直接为大模型提供上下文。
- Agent 系统:智能体可以直接通过 SQL + 向量查询与数据库交互,而不是额外维护一个向量库。
- 多模态 AI:语音、图像、文本的 embedding 统一进入 WuTongDB,实现跨模态融合应用。
换句话说,未来的梧桐数据库可能不再只是“支撑分析”,而是“驱动智能”。 其实,“支撑分析”与“驱动智能”本来就很像一体互相支撑的二兄弟一样。
产业价值与竞争格局
目前,全球范围内的数据库厂商都在探索“AI 原生数据库”的方向。
- 国外:Snowflake、Databricks 都在强化向量能力。
- 国内:阿里、腾讯、华为的数据库产品,也纷纷开始支持向量扩展。
在这个背景下,梧桐数据库如果能抓住机会,不仅能巩固在 云原生分析型数据库 赛道的地位,还可能在 AI 数据库 的新战场占据一席之地。
未来愿景
试想这样一个场景:
- 企业的数据统一存放在梧桐数据库里。
- 无论是 SQL 报表查询,还是 AI 问答检索,都在同一套数据库体系里完成。
- 开发者写的不是“传统 SQL”或“向量 API”,而是融合了语义查询的“新一代 SQL”。
在这个未来,梧桐数据库不再只是“支撑业务的引擎”,而是企业数字化与智能化的 大脑。
