




项目概述
Apache Gravitino是一个高性能、分布式且联邦式的元数据湖。它直接管理不同来源、不同类型和不同地区的元数据,还为用户提供对数据和人工智能资产的统一元数据访问方式。
Gravitino提供多项特性:支持分布式架构,作为多区域数据的单一事实来源;为用户和引擎提供统一的数据+人工智能资产管理;集中式安全管理,对不同来源进行统一的安全管控;内置数据管理、数据访问管理功能。
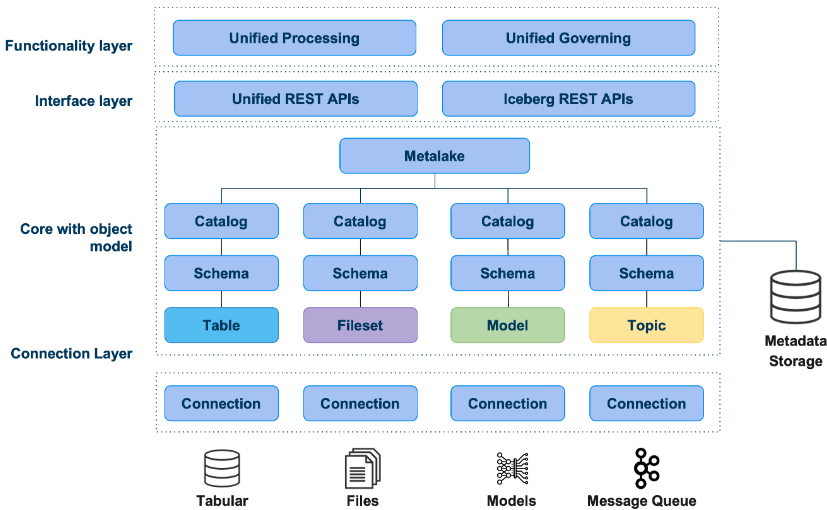
Gravitino使用元数据湖metalake作为数据的顶级容器,提供三级命名空间组织数据:目录(catalog)、模式/数据库(schemas/databases)和表/视图(tables/views)。
专业术语
Metalake:元数据的容器/租户。通常一个团队拥有一个元湖,用于管理其中的所有元数据。Catalog:来自特定元数据源的元数据集合,每个目录都有一个相关的连接器。Schema:用于对元数据集合进行分组的第二级命名空间,关系型元数据源,模式可指代数据库/模式。在文件集和模型目录中,模式也可指代逻辑命名空间。Table:在支持关系型元数据源的目录中,表是对象层级结构中的最低级别。可以在目录中特定的模式下创建表。Fileset:文件集元数据对象指代文件系统中的一组文件和目录。文件集元数据对象用于管理文件的逻辑元数据。Model:模型元数据对象表示支持模型管理的特定目录中的元数据。Topic:主题元数据对象表示支持消息队列系统(如Kafka)主题管理特定目录的元数据。
文章发布于微信公众号:大数据从业者,其它均为转载,原创不易,欢迎您点赞关注推荐转发,谢谢!
源码编译
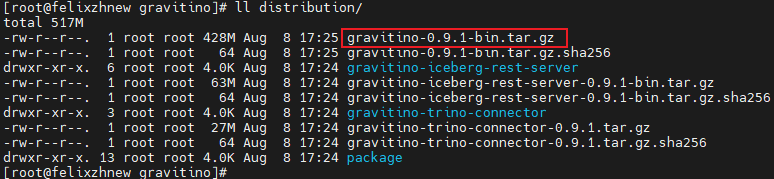
Gradle 8.12.1openjdk version "17.0.2"git clone -b v0.9.1https://github.com/apache/gravitino.gitgradle clean assembleDistribution -x test
安装部署
cp mysql-connector-java-8.0.13.jar gravitino-0.9.1-bin/libs/
mysql> create database gravitino;mysql> use gravitino;mysql> source /home/myHadoopCluster/gravitino-0.9.1-bin/scripts/mysql/schema-0.9.0-mysql.sql
vim conf/gravitino.conf

mkdir -p home/myHadoopCluster/gravitino-0.9.1-bin/logs./bin/gravitino.sh start
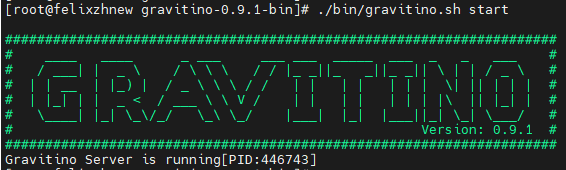
http://felixzh:8090/ui/metalakes
Catalog类型
Catalog类型分为四类:Relational、Fileset、Messaging、Model如图:
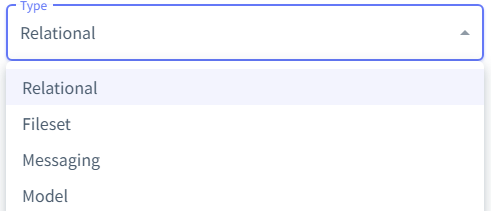
每类catalog类型支持具体情况如下所示:
Relational(8类) | Iceberg、Hive、MySQL、PostgreSQL、 Doris、Paimon、Hudi、OceanBase |
Fileset(1类) | Hadoop(s3、gcs、oss、adls) |
Messaging(1类) | Kafka |
Model(1类) | Model |
Apache Gravitino提供了将Apache Hive用作元数据管理目录的功能,通过Thrift协议访问 Hive元存储服务(HMS)。尽管官方说Hive目录使用Hive2元存储客户端,可以与Hive3元存储服务兼容。实际测试发现对接Hive3.1.3版本时候,需要调整3.1.3版本Jar,如下:
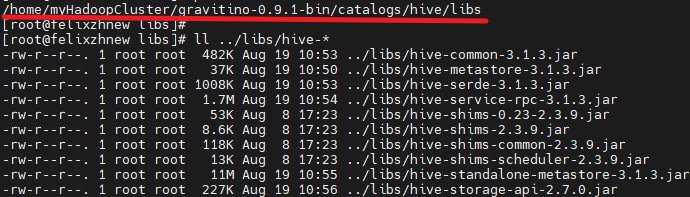
重启Gravitino服务:
./bin/gravitino.sh restart
通过UI界面化CREATE METALAKE、CREATE CATALOG,选择Hive,最小化配置HMS地址即可(支持Kerberos):
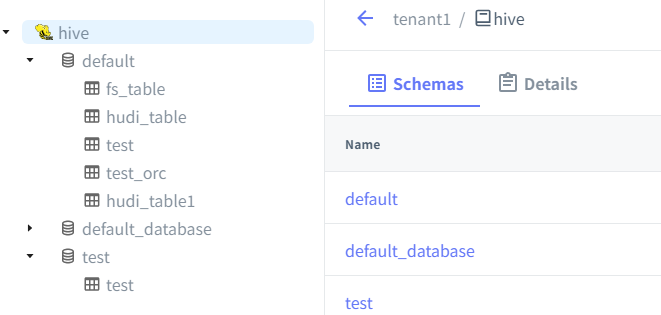
一旦成功连接HMS,可以对SCHEMA、TABLE进行各种DDL操作(create/delete等)!
案例2:Kafka Catalog
Kafka目录是一种消息目录,它提供了管理Apache Kafka主题元数据的能力。一个Kafka目录对应一个Kafka集群。通过UI界面化选择CREATE METALAKE(可选)、CREATE CATALOG,Messaging->Apache Kafka,最小化配置bootstrap.servers即可:
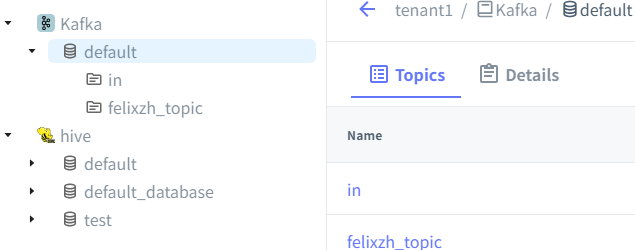
一旦成功连接Kafka,可以对Kafka Topic进行DDL操作,如创建、删除、修改配置等!
案例3:Hadoop Catalog
Hadoop目录是一种文件集目录,它使用Hadoop兼容文件系统(HCFS)来管理文件集的存储位置。目前,支持本地文件系统和 HDFS。Gravitino通过Hadoop目录支持S3、GCS、OSS和Azure Blob Storage。通过UI界面化选择CREATE METALAKE(可选)、CREATE CATALOG,Fileset->ApacheHadoop,最小化配置location即可:
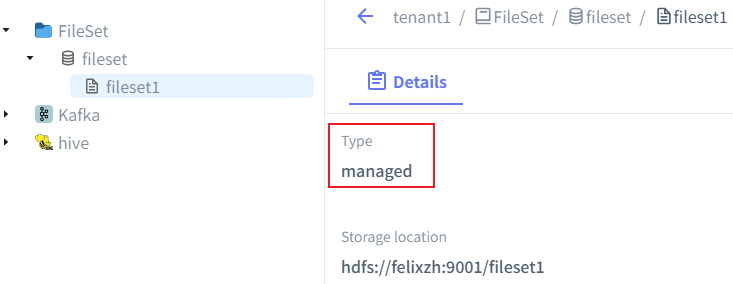
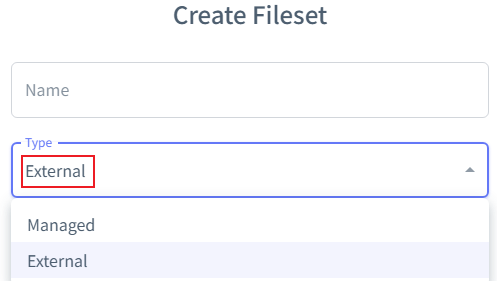
注意:如果managed类型,删除Fileset的时候,Storage location目录会联动删除!目录即上图的:hdfs://felixzh:9001/fileset1。如果不想联动删除目录,创建Fileset时候可以使用另外一种类型External,如图所示:
案例4:Model Catalog
模型目录提供统一的接口,以集中方式管理机器学习模型的元数据。它遵循典型的 Gravitino 三级命名空间(目录、模式和模型)来管理机器学习模型的元数据。此外,它还支持为每个模型管理版本。模型管理的核心概念是管理模型的路径(URI)。模型元数据并非对模型存储路径进行物理上的单独管理,而是定义了模型名称与存储路径之间的映射关系。同时,借助模型元数据的可扩展属性支持,用户可以为模型元数据定义更详细的信息,而不仅仅是存储路径。通过UI界面化选择CREATE METALAKE(可选)、CREATE CATALOG,最小化配置Model URL即可:
总结
Gravitino是一款面向大数据与AI场景的高性能分布式元数据湖解决方案,核心价值在于通过统一的元数据管理层,解决跨区域、多源异构数据的治理难题。成为数据湖3.0时代的关键基础设施。文章发布于微信公众号:大数据从业者,其它均为转载,原创不易,欢迎您点赞关注推荐转发,谢谢!
