




❝开头还是介绍一下群,如果感兴趣PolarDB ,MongoDB ,MySQL ,PostgreSQL ,Redis, OceanBase, Sql Server等有问题,有需求都可以加群群内有各大数据库行业大咖,可以解决你的问题。加群请联系 liuaustin3 ,(共3300人左右 1 + 2 + 3 + 4 +5 + 6 + 7 + 8 +9)(1 2 3 4 5 6 7群均已爆满,开8群近400 9群 200+,开10群PolarDB专业学习群100+)
在我听到这个信息后,我实际上有点蒙。DuckDB不是应该归PostgreSQL所有吗?MySQL融合了DuckDB,我没听说甲骨文有这个产品呀?
等我看完整个事情,我才明白原来是阿里云 RDS MySQL的产品。Why,How,When,What!!!
1 Why:为什么,MySQL融合了DuckDB,怎么想的,PG怎么办?
2 How: 怎么做的,他们怎么做到的?
3 When: 什么时候,是有产品了,还是在吹牛的阶段?
4 What: 这个词真的是What ! 感叹词,惊叹词,还是有点发蒙 的意思?
诚然,最近一段时间MySQL发展的不好,吐槽他,退MySQL的比比皆是,都是往PG群里面扎的。可为什么阿里云弄出了MySQL+DuckDB的东西,不过咱们有人往他们公司一打听,你猜怎么着,我来揭秘一个大瓜。
这个大瓜就是,阿里云RDS团队纠集了一帮MySQL大神,有我前一段文章写的宋利兵宋老师,还有甲骨文颁发了“刺头”称号的陈老师,还有前一段DISS甲骨文MySQL不测试就上线的那个老师,另外小道消息,里面还有几个神秘的扫地僧。他们看不惯MySQL的没落,要在中国建立一个MySQL神秘的复兴组织,MySQL星星帮。
MySQL各种小的优化不断,这次搞出了MySQL+DuckDB的超级蘑菇云,誓死要拯救MySQL的颓势。他们的口号是,MySQL兴盛,星星帮人人有责,他们要在中国凭着一己之力,让MySQL再火起来。
其实我对这个让MySQL火起来的想法存在质疑,不过MySQL星星帮里面大咖的实力不容小视,先看看这次的新产品如何,再看看MySQL有没有可能在火起来。
1 MySQL最大的问题就是不能和MSSQL,ORACLE,PostgreSQL一样进行OLAP的一些轻量级的,多表的数据分析的工作。
2 DuckDB是目前热度最高的分析型数据库,他具有列式和向量化的能力,并且还是开源的产品,谁都可以用,都可以集成。
那么到底MySQL能不能兴盛,在此一举了,如果真的如他们所说MySQL+DUCKDB,那别的数据库还真的掂量掂量了。
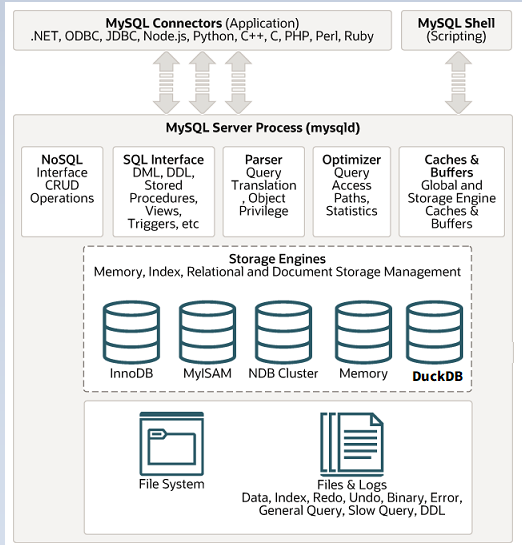
但这里我也有一些担心
1 MySQL+DuckDB 对于MySQL的使用者有什么影响,如兼容性,语法差异
2 MySQL+DuckDB 如果我有大事务那么数据的一致性有没有问题
3 有没有基于数据字段的类型的不一致,有数据计算后的精确性的问题等等
所以必须进行一个使用和测试,测试中我们需要说明产品的类型,产品购买需要选择高可用系列,产品类型要选择标准版,方可开启MySQL混合引擎的大阵。
购买一个符合规格的MySQL RDS后,我们打开界面,找到duckdb分析引擎,进行开通。
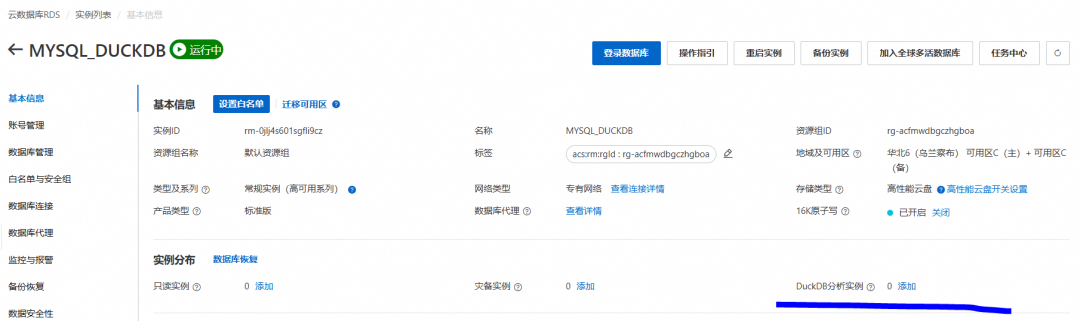
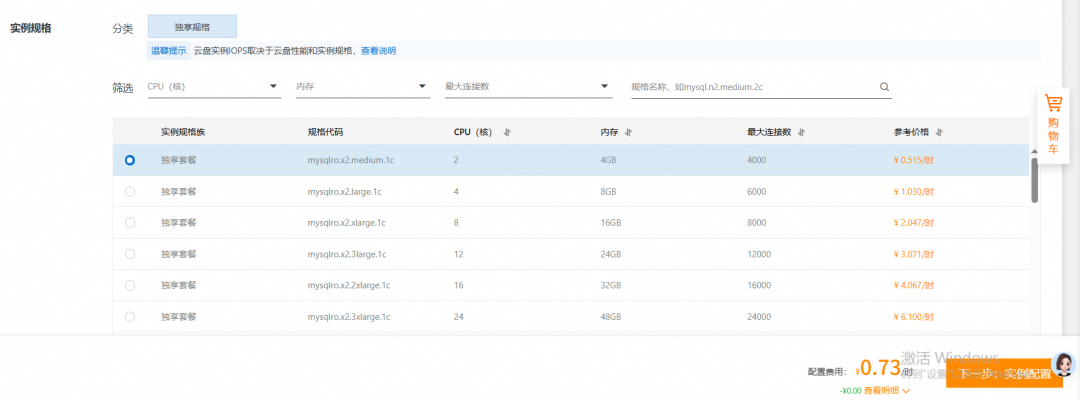
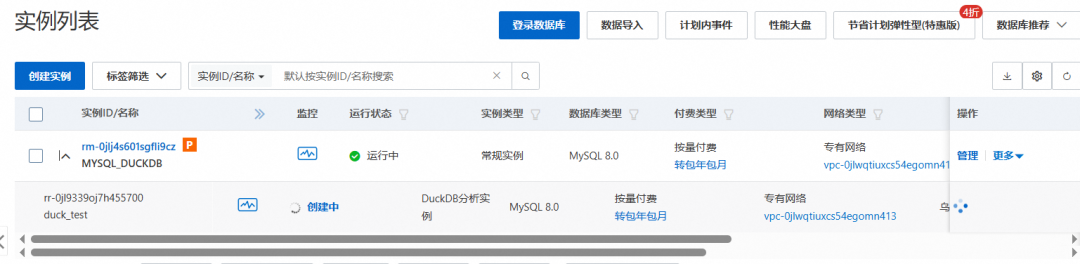
这里相当于在建立MySQL RDS后,在产生一个通过Binlog数据复制的 DuckDB,作为这个MySQL RDS的附属。这里DuckDB 和 MySQL 二者是独立的,各自有独立的链接地址。
这里我们做一个测试,来看看复杂的SQL在MySQL和DuckDB之间运行的差距。
下面我们把表和灌入数据的脚本展示在下方 方便大家也可以进行类似的测试。
DROP TABLE IF EXISTS orders;
DROP TABLE IF EXISTS products;
DROP TABLE IF EXISTS users;
CREATE TABLE users (
user_id BIGINT AUTO_INCREMENT PRIMARY KEY,
user_name VARCHAR(100),
email VARCHAR(200),
country VARCHAR(50),
create_time DATETIME DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE products (
product_id BIGINT AUTO_INCREMENT PRIMARY KEY,
product_name VARCHAR(200),
category VARCHAR(50),
price DECIMAL(10,2),
create_time DATETIME DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE orders (
order_id BIGINT AUTO_INCREMENT PRIMARY KEY,
user_id BIGINT,
product_id BIGINT,
quantity INT,
order_date DATETIME DEFAULT CURRENT_TIMESTAMP,
status VARCHAR(20)
);
DELIMITER $$
CREATE PROCEDURE load_test_data()
BEGIN
DECLARE i INT DEFAULT 0;
-- 插入 users (10万)
SET i = 1;
WHILE i <= 100000 DO
INSERT INTO users (user_name, email, country)
VALUES (
CONCAT('user_', i),
CONCAT('user_', i, '@test.com'),
ELT(FLOOR(1 + RAND()*5), 'China','USA','UK','Germany','India')
);
SET i = i + 1;
END WHILE;
-- 插入 products (1万)
SET i = 1;
WHILE i <= 10000 DO
INSERT INTO products (product_name, category, price)
VALUES (
CONCAT('product_', i),
ELT(FLOOR(1 + RAND()*5), 'Electronics','Clothes','Food','Books','Sports'),
ROUND(RAND()*1000, 2)
);
SET i = i + 1;
END WHILE;
-- 插入 orders (100万)
SET i = 1;
WHILE i <= 1000000 DO
INSERT INTO orders (user_id, product_id, quantity, order_date, status)
VALUES (
FLOOR(1 + RAND()*100000), -- 有效 user_id
FLOOR(1 + RAND()*10000), -- 有效 product_id
FLOOR(1 + RAND()*5 + 1), -- 数量 1~5
NOW() - INTERVAL FLOOR(RAND()*365) DAY,
ELT(FLOOR(1 + RAND()*3), 'PAID','SHIPPED','CANCELLED')
);
SET i = i + 1;
END WHILE;
END $$
DELIMITER ;
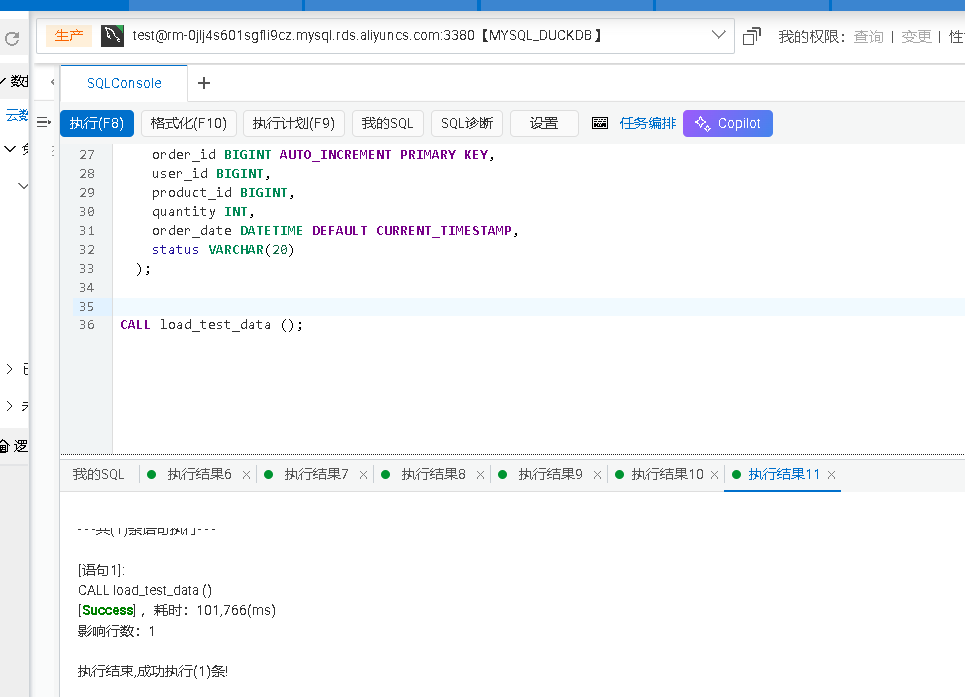
CALL load_test_data();
把以上脚本在MySQL上运行即可,数据会通过Binlog 直接复制到DuckDB中。
然后我们链接到MySQL 和 DuckDB,来运行同样的SQL看看之间的差距。
目标:统计最近 90 天各国家、各品类的销售额/订单数/客单价,并计算在国家内的 排名 与 贡献占比。
特点:WITH CTE、三表 JOIN、窗口函数 RANK()、分区内占比、条件过滤。
WITH o90 AS (
SELECT
o.order_id,
o.user_id,
o.product_id,
o.quantity,
o.order_date,
o.status
FROM orders o
WHERE o.status = 'PAID'
AND o.order_date >= NOW() - INTERVAL 90 DAY
),
base AS (
SELECT
u.country,
p.category,
o.order_id,
(o.quantity * p.price) AS amount
FROM o90 o
JOIN users u ON u.user_id = o.user_id
JOIN products p ON p.product_id = o.product_id
),
agg AS (
SELECT
country,
category,
COUNT(DISTINCT order_id) AS order_cnt,
SUM(amount) AS revenue,
AVG(amount) AS avg_order_value
FROM base
GROUP BY country, category
)
SELECT
a.country,
a.category,
a.order_cnt,
ROUND(a.revenue, 2) AS revenue,
ROUND(a.avg_order_value, 2) AS avg_order_value,
RANK() OVER (PARTITION BY a.country ORDER BY a.revenue DESC) AS rev_rank_in_country,
ROUND(
a.revenue NULLIF(SUM(a.revenue) OVER (PARTITION BY a.country), 0) * 100, 2
) AS revenue_share_in_country_pct
FROM agg a
ORDER BY a.country, rev_rank_in_country, a.revenue DESC;
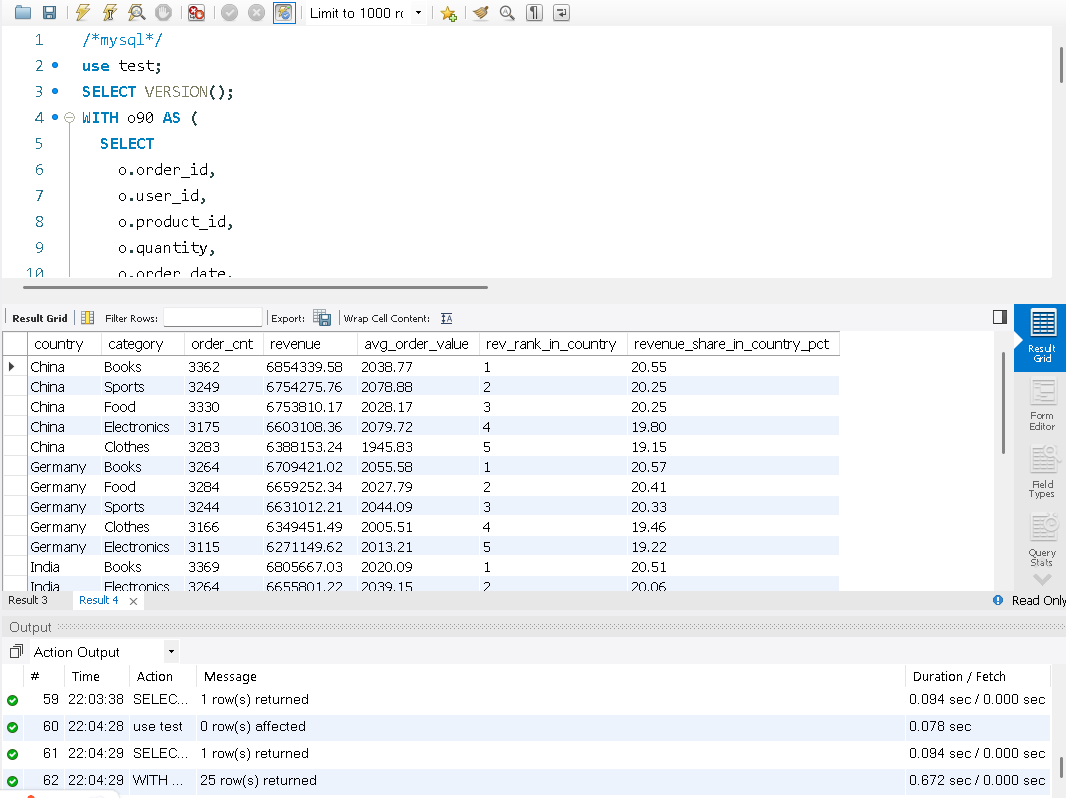
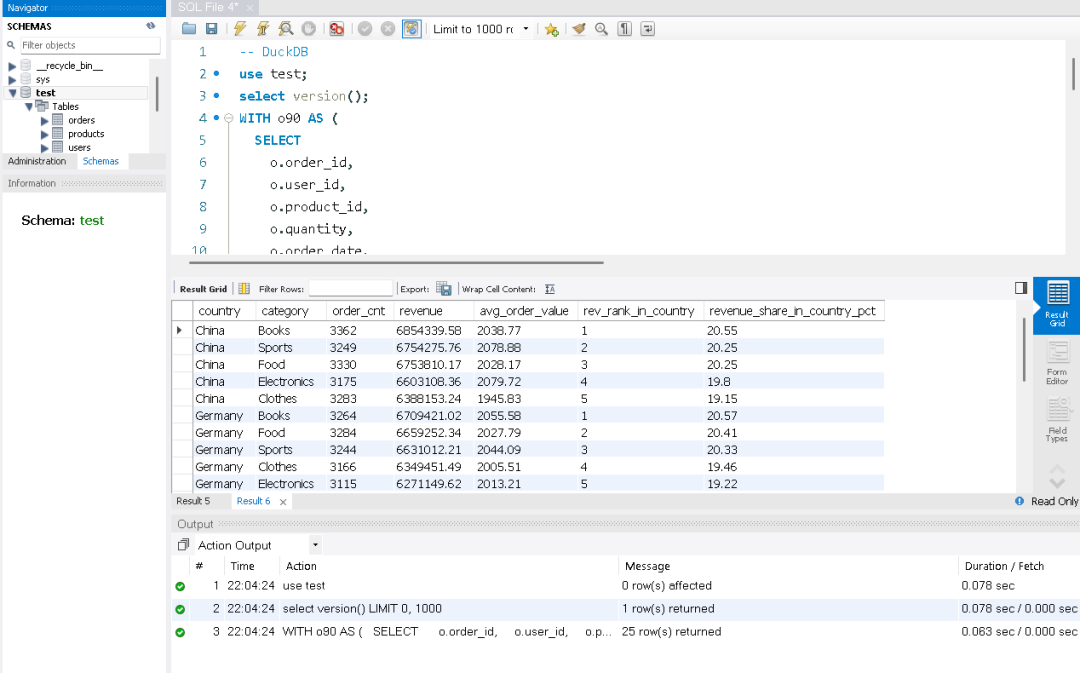
在测试中虽然DuckDB比MySQL要快10倍,但MySQL的查询速度也在1秒内,下面我们在来一个更复杂和数据量较大的语句。
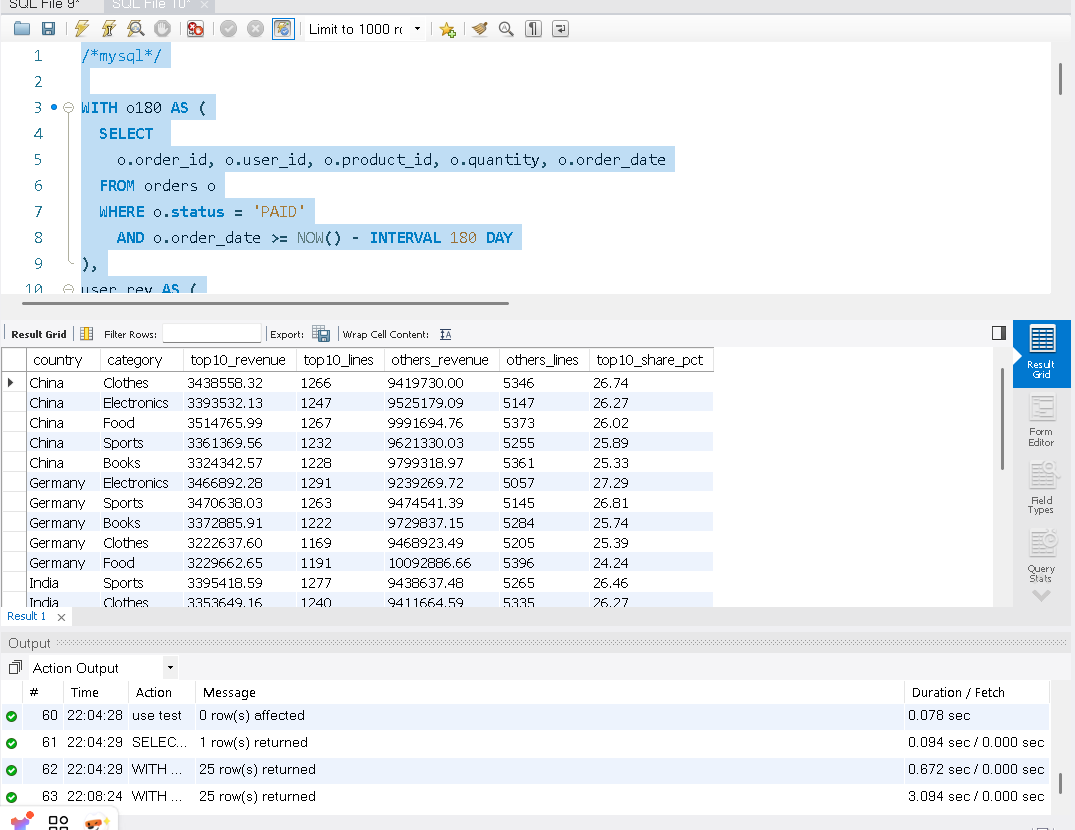
目标:先在每个国家内按 用户近 180 天总消费 做十分位分层(NTILE(10)),把 Top10% 作为高价值用户,与“其余用户”对比,按 国家 × 品类 汇总对比贡献。
WITH o180 AS (
SELECT
o.order_id, o.user_id, o.product_id, o.quantity, o.order_date
FROM orders o
WHERE o.status = 'PAID'
AND o.order_date >= NOW() - INTERVAL 180 DAY
),
user_rev AS (
-- 每位用户在 180 天内的总消费(用于分层)
SELECT
u.user_id,
u.country,
SUM(o.quantity * p.price) AS user_revenue_180d
FROM o180 o
JOIN users u ON u.user_id = o.user_id
JOIN products p ON p.product_id = o.product_id
GROUP BY u.user_id, u.country
),
user_seg AS (
-- 在各国家内按用户总消费分十分位,1=最高
SELECT
user_id,
country,
user_revenue_180d,
NTILE(10) OVER (PARTITION BY country ORDER BY user_revenue_180d DESC) AS decile_in_country
FROM user_rev
),
base AS (
-- 还原到订单明细,打上用户的分层标签
SELECT
us.country,
us.decile_in_country,
p.category,
(o.quantity * p.price) AS amount
FROM o180 o
JOIN user_seg us ON us.user_id = o.user_id
JOIN products p ON p.product_id = o.product_id
)
SELECT
country,
category,
-- 高价值用户(Top10%,decile=1)
ROUND(SUM(CASE WHEN decile_in_country = 1 THEN amount END), 2) AS top10_revenue,
COUNT(CASE WHEN decile_in_country = 1 THEN 1 END) AS top10_lines,
-- 其余用户
ROUND(SUM(CASE WHEN decile_in_country <> 1 THEN amount END), 2) AS others_revenue,
COUNT(CASE WHEN decile_in_country <> 1 THEN 1 END) AS others_lines,
-- Top10% 在该国家×品类中的贡献占比
ROUND(
SUM(CASE WHEN decile_in_country = 1 THEN amount END)
NULLIF(SUM(amount), 0) * 100, 2
) AS top10_share_pct
FROM base
GROUP BY country, category
ORDER BY country, top10_share_pct DESC, category;
我们在看结果DuckDB 运行这条语句需要0.125秒,而MySQL需要3.094秒。
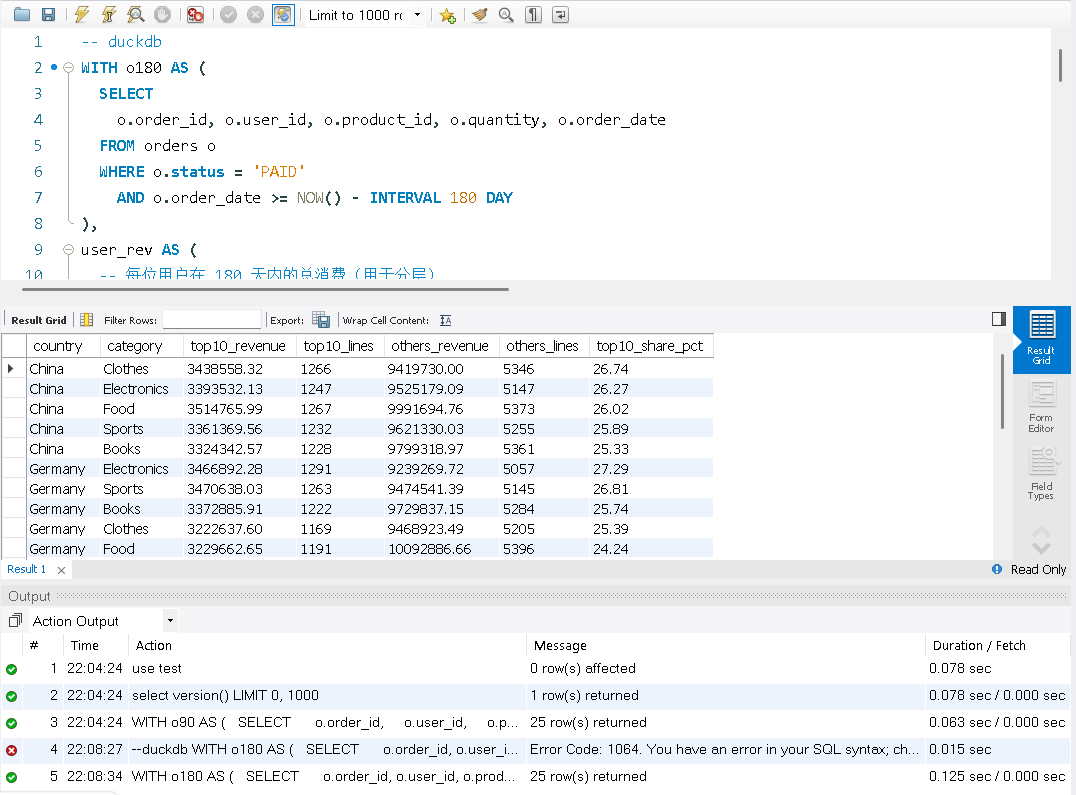
MySQL
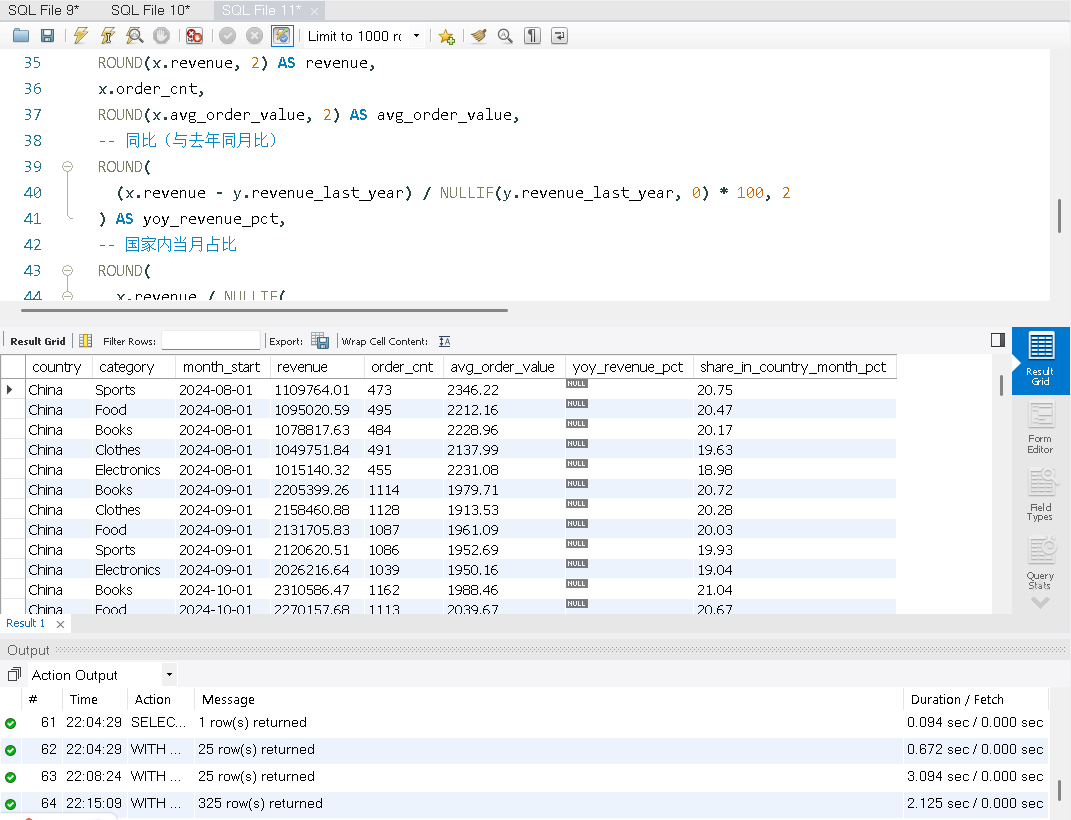
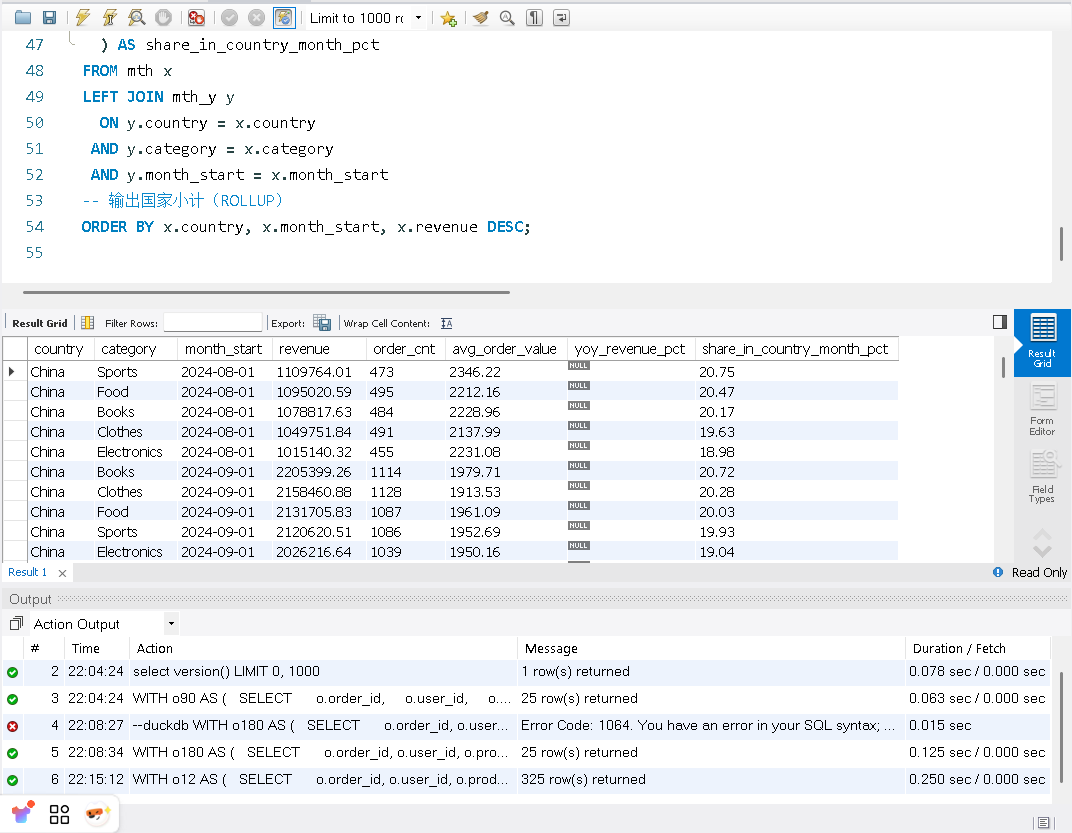
目标:构建 国家 × 品类 × 月 的月度指标(收入、订单数、客单价),计算 同比 YoY,并给出 国家内占比。最后使用 WITH ROLLUP 输出 国家小计。
WITH o12 AS (
SELECT
o.order_id, o.user_id, o.product_id, o.quantity, o.order_date
FROM orders o
WHERE o.status = 'PAID'
AND o.order_date >= DATE_FORMAT(DATE_SUB(CURDATE(), INTERVAL 12 MONTH), '%Y-%m-01')
),
mth AS (
-- 基础月度聚合:国家 × 品类 × 月
SELECT
u.country,
p.category,
DATE_FORMAT(o.order_date, '%Y-%m-01') AS month_start,
COUNT(DISTINCT o.order_id) AS order_cnt,
SUM(o.quantity * p.price) AS revenue,
AVG(o.quantity * p.price) AS avg_order_value
FROM o12 o
JOIN users u ON u.user_id = o.user_id
JOIN products p ON p.product_id = o.product_id
GROUP BY u.country, p.category, DATE_FORMAT(o.order_date, '%Y-%m-01')
),
mth_y AS (
-- 为计算同比,准备去年的同月指标
SELECT
country,
category,
DATE_FORMAT(DATE_ADD(STR_TO_DATE(month_start, '%Y-%m-%d'), INTERVAL 12 MONTH), '%Y-%m-01') AS month_start, -- 映射到“今年同月”
revenue AS revenue_last_year
FROM mth
)
SELECT
x.country,
x.category,
x.month_start,
ROUND(x.revenue, 2) AS revenue,
x.order_cnt,
ROUND(x.avg_order_value, 2) AS avg_order_value,
-- 同比(与去年同月比)
ROUND(
(x.revenue - y.revenue_last_year) NULLIF(y.revenue_last_year, 0) * 100, 2
) AS yoy_revenue_pct,
-- 国家内当月占比
ROUND(
x.revenue NULLIF(
SUM(x.revenue) OVER (PARTITION BY x.country, x.month_start), 0
) * 100, 2
) AS share_in_country_month_pct
FROM mth x
LEFT JOIN mth_y y
ON y.country = x.country
AND y.category = x.category
AND y.month_start = x.month_start
-- 输出国家小计(ROLLUP)
ORDER BY x.country, x.month_start, x.revenue DESC;
这次MySQL使用2.125秒完成了查询,DuckDB使用了0.250完成了查询。
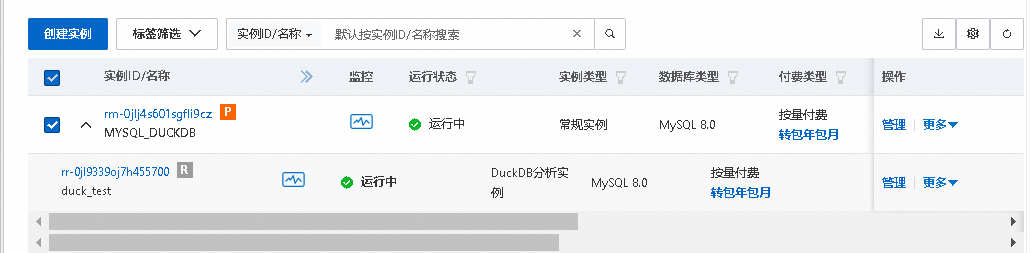
使用场景也非常的明显,将MySQL作为主库,通过MySQL binlog将数据复制到封装成MySQL的DuckDB中,然后将难搞报表SQL 都指向从节点即可。
测试到最后,我深深的感受到阿里云RDS MySQL团队的MySQL大神们对MySQL的“爱”,搞出了弥补MySQL短板的Super MySQL RDS产品,让MySQL再次兴盛。
附带当前产品的兼容性
MySQL + DuckDB 兼容性总结
1. 数据类型支持情况
完全兼容 BOOLEAN TINYINT、SMALLINT、INT/INTEGER、BIGINT FLOAT、DOUBLE CHAR/VARCHAR(UTF8 系列) TEXT 系列(TINYTEXT、TEXT、MEDIUMTEXT、LONGTEXT) JSON、SET、ENUM BINARY/VARBINARY、BIT BLOB 系列(TINYBLOB、BLOB、MEDIUMBLOB、LONGBLOB) YEAR、TIMESTAMP 部分兼容 DECIMAL(m,d):当 m <= 38 完全兼容;m > 38 转为 DOUBLE(有精度损失) TIME DATE DATETIME:DuckDB 支持范围更窄,超出范围数据可能导致查询结果不一致 不兼容 空间数据类型(GEOMETRY、POINT、LINESTRING、POLYGON 等)
2. SQL 语法限制
不支持 #
注释不支持字符集转换( CONVERT()
/CAST()
改字符集)不支持在同一 SQL 混用显式 JOIN 与隐式 JOIN 部分时间间隔单位不支持(如 YEAR_MONTH
)别名必须用 AS
或反引号,不能用'alias'
/"alias"不支持等值非标量子查询 (col1, col2) = (SELECT …)不支持显式类型转换为 BINARY(num)
、SIGNED
、UNSIGNED不支持列修饰符 BINARY colname复杂运算需加括号避免解析错误(如 1 != (-1)
)
3. 类型与比较规则
类型转换更严格,部分 MySQL 隐式转换会报错 字符串类型仅布尔类型时 ,仅 '1'
、'0'
、'yes'
、'no'
、'true'
、'false'
可转换浮点比较在边界值可能有差异 整数溢出会报错(MySQL 会截断或转大类型) 字符串类型转日期类型时,格式不合法会直接报错
4. 函数支持与限制
4.1 聚合函数
支持:AVG、COUNT、SUM、MIN、MAX、STD 系列、VAR 系列 限制: BIT_AND
/BIT_OR
/BIT_XOR
不支持字符串、DECIMAL、日期类型不支持:JSON_ARRAYAGG、JSON_OBJECTAGG 等部分 JSON 聚合
4.2 数值函数
大部分支持 不支持:ATAN(y, x)、ATAN2、CONV、CRC32、TRUNCATE
4.3 字符串函数
严格区分二进制与普通字符串 部分函数不支持:CHAR、ELT、MATCH、REGEXP 系列、SOUNDEX
4.4 日期函数
大部分支持,但日期输入必须显式 CAST 不支持:TIME()、TIMEDIFF()、TIMESTAMP()
4.5 JSON 函数
基础 JSON 操作支持(JSON_EXTRACT、JSON_OBJECT、JSON_ARRAY 等) 高级 JSON 操作不支持(JSON_SET、JSON_REMOVE、JSON_SEARCH 等)
5. 其他限制
不支持 视图查询(View) UTF8MB4_0900_xx 系列部分符号排序与 MySQL 不同 IN
向量子查询对 NULL 处理可能不一致运算和比较更严格,需注意括号与显式类型转换
微软动手了,联合OpenAI + Azure 云争夺AI服务市场
“当复杂的SQL不再需要特别的优化”,邪修研究PolarDB for PG 列式索引加速复杂SQL运行
“合体吧兄弟们!”——从浪浪山小妖怪看OceanBase国产芯片优化《OceanBase “重如尘埃”之歌》
未知黑客通过SQL SERVER 窃取企业SAP核心数据,影响企业运营
那个MySQL大事务比你稳定,主从延迟低,为什么? Look my eyes! 因为宋利兵宋老师
非“厂商广告”的PolarDB课程:用户共创的新式学习范本--7位同学获奖PolarDB学习之星
说我PG Freezing Boom 讲的一般的那个同学,专帖给你,看看这次可满意
这个 PostgreSQL 让我有资本找老板要 鸡腿 鸭腿 !!
OceanBase Hybrid search 能力测试,平换MySQL的好选择
HyBrid Search 实现价值落地,从真实企业的需求角度分析 !不只谈技术!
OceanBase 光速快递 OB Cloud “MySQL” 给我,Thanks a lot
从“小偷”开始,不会从“强盗”结束 -- IvorySQL 2025 PostgreSQL 生态大会
被骂后的文字--技术人不脱离思维困局,终局是个 “死” ? ! ......
个群2025上半年总结,OB、PolarDB, DBdoctor、爱可生、pigsty、osyun、工作岗位等
从MySQL不行了,到乙方DBA 给狗,狗都不干? 我干呀!
SQL SERVER 2025发布了, China幸亏有信创!
MongoDB 麻烦专业点,不懂可以问,别这么用行吗 ! --TTL
PostgreSQL 新版本就一定好--由培训现象让我做的实验
删除数据“八扇屏” 之 锦门英豪 --我去-BigData!
写了3750万字的我,在2000字的OB白皮书上了一课--记 《OceanBase 社区版在泛互场景的应用案例研究》
疯狂老DBA 和 年轻“网红” 程序员 --火星撞地球-- 谁也不是怂货
和架构师沟通那种“一坨”的系统,推荐只能是OceanBase,Why ?
跟我学OceanBase4.0 --阅读白皮书 (OB分布式优化哪里了提高了速度)
跟我学OceanBase4.0 --阅读白皮书 (4.0优化的核心点是什么)
跟我学OceanBase4.0 --阅读白皮书 (0.5-4.0的架构与之前架构特点)
跟我学OceanBase4.0 --阅读白皮书 (旧的概念害死人呀,更新知识和理念)
MongoDB 相关文章
MongoDB “升级项目” 大型连续剧(4)-- 与开发和架构沟通与扫尾
MongoDB “升级项目” 大型连续剧(3)-- 自动校对代码与注意事项
MongoDB “升级项目” 大型连续剧(2)-- 到底谁是"der"
MongoDB “升级项目” 大型连续剧(1)-- 可“生”可不升
MongoDB 大俗大雅,上来问分片真三俗 -- 4 分什么分
MongoDB 大俗大雅,高端知识讲“庸俗” --3 奇葩数据更新方法
MongoDB 大俗大雅,高端的知识讲“通俗” -- 2 嵌套和引用
MongoDB 大俗大雅,高端的知识讲“低俗” -- 1 什么叫多模
MongoDB 合作考试报销活动 贴附属,MongoDB基础知识速通
MongoDB 使用网上妙招,直接DOWN机---清理表碎片导致的灾祸 (送书活动结束)
MongoDB 2023年度纽约 MongoDB 年度大会话题 -- MongoDB 数据模式与建模
免费PolarDB云原生课程,听课“争”礼品,重塑云上知识,提高专业能力
“PostgreSQL” 高性能主从强一致读写分离,我行,你没戏!
POLARDB 添加字段 “卡” 住---这锅Polar不背
PolarDB 版本差异分析--外人不知道的秘密(谁是绵羊,谁是怪兽)
PolarDB 答题拿-- 飞刀总的书、同款卫衣、T恤,来自杭州的Package(活动结束了)
PolarDB for MySQL 三大核心之一POLARFS 今天扒开它--- 嘛是火
PostgreSQL 无服务 Neon and Aurora 新技术下的新经济模式 (翻译)
“PostgreSQL” 高性能主从强一致读写分离,我行,你没戏!
全世界都在“搞” PostgreSQL ,从Oracle 得到一个“馊主意”开始
PostgreSQL 加索引系统OOM 怨我了--- 不怨你怨谁
PostgreSQL “我怎么就连个数据库都不会建?” --- 你还真不会!
PostgreSQL 稳定性平台 PG中文社区大会--杭州来去匆匆
PostgreSQL 分组查询可以不进行全表扫描吗?速度提高上千倍?
POSTGRESQL --Austindatabaes 历年文章整理
PostgreSQL 查询语句开发写不好是必然,不是PG的锅
MySQL相关文章
微软动手了,联合OpenAI + Azure 云争夺AI服务市场
“当复杂的SQL不再需要特别的优化”,邪修研究PolarDB for PG 列式索引加速复杂SQL运行
“合体吧兄弟们!”——从浪浪山小妖怪看OceanBase国产芯片优化《OceanBase “重如尘埃”之歌》
未知黑客通过SQL SERVER 窃取企业SAP核心数据,影响企业运营
那个MySQL大事务比你稳定,主从延迟低,为什么? Look my eyes! 因为宋利兵宋老师
非“厂商广告”的PolarDB课程:用户共创的新式学习范本--7位同学获奖PolarDB学习之星
说我PG Freezing Boom 讲的一般的那个同学,专帖给你,看看这次可满意
这个 PostgreSQL 让我有资本找老板要 鸡腿 鸭腿 !!
OceanBase Hybrid search 能力测试,平换MySQL的好选择
HyBrid Search 实现价值落地,从真实企业的需求角度分析 !不只谈技术!
OceanBase 光速快递 OB Cloud “MySQL” 给我,Thanks a lot
从“小偷”开始,不会从“强盗”结束 -- IvorySQL 2025 PostgreSQL 生态大会
被骂后的文字--技术人不脱离思维困局,终局是个 “死” ? ! ......
个群2025上半年总结,OB、PolarDB, DBdoctor、爱可生、pigsty、osyun、工作岗位等
从MySQL不行了,到乙方DBA 给狗,狗都不干? 我干呀!
SQL SERVER 2025发布了, China幸亏有信创!
MongoDB 麻烦专业点,不懂可以问,别这么用行吗 ! --TTL
PostgreSQL 新版本就一定好--由培训现象让我做的实验
删除数据“八扇屏” 之 锦门英豪 --我去-BigData!
写了3750万字的我,在2000字的OB白皮书上了一课--记 《OceanBase 社区版在泛互场景的应用案例研究》
疯狂老DBA 和 年轻“网红” 程序员 --火星撞地球-- 谁也不是怂货
和架构师沟通那种“一坨”的系统,推荐只能是OceanBase,Why ?
跟我学OceanBase4.0 --阅读白皮书 (OB分布式优化哪里了提高了速度)
跟我学OceanBase4.0 --阅读白皮书 (4.0优化的核心点是什么)
跟我学OceanBase4.0 --阅读白皮书 (0.5-4.0的架构与之前架构特点)
跟我学OceanBase4.0 --阅读白皮书 (旧的概念害死人呀,更新知识和理念)
MongoDB 相关文章
MongoDB “升级项目” 大型连续剧(4)-- 与开发和架构沟通与扫尾
MongoDB “升级项目” 大型连续剧(3)-- 自动校对代码与注意事项
MongoDB “升级项目” 大型连续剧(2)-- 到底谁是"der"
MongoDB “升级项目” 大型连续剧(1)-- 可“生”可不升
MongoDB 大俗大雅,上来问分片真三俗 -- 4 分什么分
MongoDB 大俗大雅,高端知识讲“庸俗” --3 奇葩数据更新方法
MongoDB 大俗大雅,高端的知识讲“通俗” -- 2 嵌套和引用
MongoDB 大俗大雅,高端的知识讲“低俗” -- 1 什么叫多模
MongoDB 合作考试报销活动 贴附属,MongoDB基础知识速通
MongoDB 使用网上妙招,直接DOWN机---清理表碎片导致的灾祸 (送书活动结束)
MongoDB 2023年度纽约 MongoDB 年度大会话题 -- MongoDB 数据模式与建模
免费PolarDB云原生课程,听课“争”礼品,重塑云上知识,提高专业能力
“PostgreSQL” 高性能主从强一致读写分离,我行,你没戏!
POLARDB 添加字段 “卡” 住---这锅Polar不背
PolarDB 版本差异分析--外人不知道的秘密(谁是绵羊,谁是怪兽)
PolarDB 答题拿-- 飞刀总的书、同款卫衣、T恤,来自杭州的Package(活动结束了)
PolarDB for MySQL 三大核心之一POLARFS 今天扒开它--- 嘛是火
PostgreSQL 无服务 Neon and Aurora 新技术下的新经济模式 (翻译)
“PostgreSQL” 高性能主从强一致读写分离,我行,你没戏!
全世界都在“搞” PostgreSQL ,从Oracle 得到一个“馊主意”开始
PostgreSQL 加索引系统OOM 怨我了--- 不怨你怨谁
PostgreSQL “我怎么就连个数据库都不会建?” --- 你还真不会!
PostgreSQL 稳定性平台 PG中文社区大会--杭州来去匆匆
PostgreSQL 分组查询可以不进行全表扫描吗?速度提高上千倍?
POSTGRESQL --Austindatabaes 历年文章整理
PostgreSQL 查询语句开发写不好是必然,不是PG的锅
MySQL相关文章

