





在信息爆炸的时代,如何把分散、杂乱的数据转化为清晰、有序的知识结构?知识图谱作为人工智能的“认知底座”,正逐步成为政企智能化转型的核心基础设施,应用到越来越多的关键场景。但构建一张真正“可用”的知识图谱并不容易,常面临以下挑战:
多源异构数据混杂:数据库、Excel、PDF、WebAPI等,难以统一映射多源数据。
关系抽取的规则依赖严重:传统方法依赖人工规则模板抽取实体关系,维护成本高、业务扩展性差。
深度查询困境:关系型数据库查询路径有限,无法支撑多跳推理与复杂图计算。
关系挖掘效率低下:靠人工编规则、写脚本,难以适配复杂的业务语义。
破局关键:图数据库+知识图谱
基于图数据库的知识图谱技术栈突破性实现:
√ 多源数据智能映射
√ 动态关系发现
√ 深度推理能力
本文结合蜀天梦图旗下两款自主研发产品——GDMBASE图数据库与知识图谱平台,拆解一个从0到1的图谱构建路径。
一、知识图谱是什么
简单来说,知识图谱就是一种揭示实体之间关系的语义网络,可以把它想象成一张巨大的蜘蛛网,每个节点都是一个实体,比如人、事物、概念等,而节点之间的连线则代表着实体之间的各种关系。一句话概括:把“数据孤岛”连成“智能网络”。
二、知识图谱能做什么
我们可以把知识图谱比作是“数据关系智能分析师”,它的核心能力是让“数据之间产生联系”,能在由成千上万个点和线组成的复杂关系网络里,快速进行深度分析、推导结论。随着人工智能的技术发展与应用,知识图谱作为关键技术之一,已经被广泛应用于诸多领域,如智能搜索、智能推荐、智能问答、风险控制等,并且可以同时与大模型结合进行互相补充。
三、知识图谱怎么构建
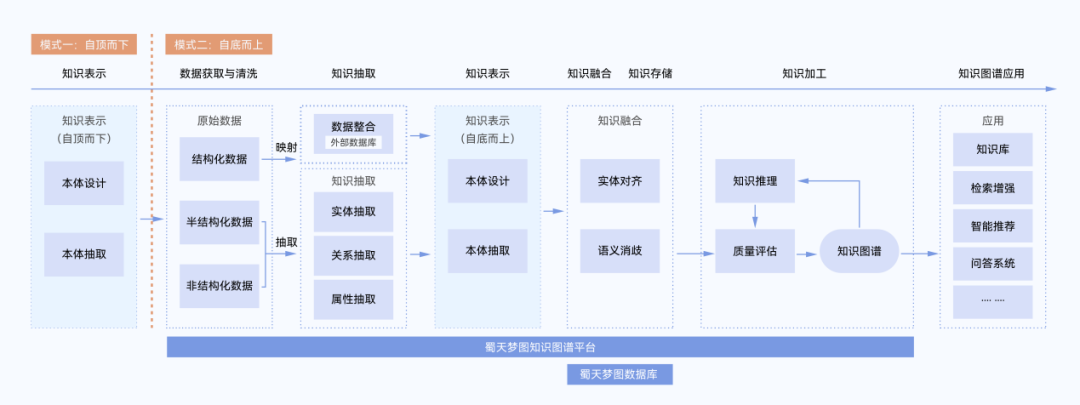
图1- 知识图谱具体构建流程
知识图谱通过建模→清洗→抽取→融合→存储→加工→应用流程,形成从原始数据到结构化知识,最终支持语义推理与智能服务的完整链路。构建流程具体概括为7个阶段:
阶段一:知识表示与建模
需求定义与场景,明确目标和领域
知识表示与建模就像盖房子之前先画图纸,我们先确定要建什么样的知识图谱?图谱的用途是什么?明确具体的目标和领域后再进行本体的设计。
1.本体设计模式
自顶向下:先设计本体,再填充实例。适用:领域知识体系成熟。
自底向上:从当前数据中归纳模式。适用:探索性项目。
以风控与合规的知识图谱的本体为例,则适用于自顶而下的本体设计方式:
(1)领域建模:以金融为例
核心实体:企业、股东、高管、金融机构、担保物、交易记录、行政处罚等。
核心关系:持股关系、担保关系、关联交易、实际控制人、任职关系等。
风险标签:高风险行业(如P2P)、失信被执行人、监管处罚记录等。
(2)本体的构成:
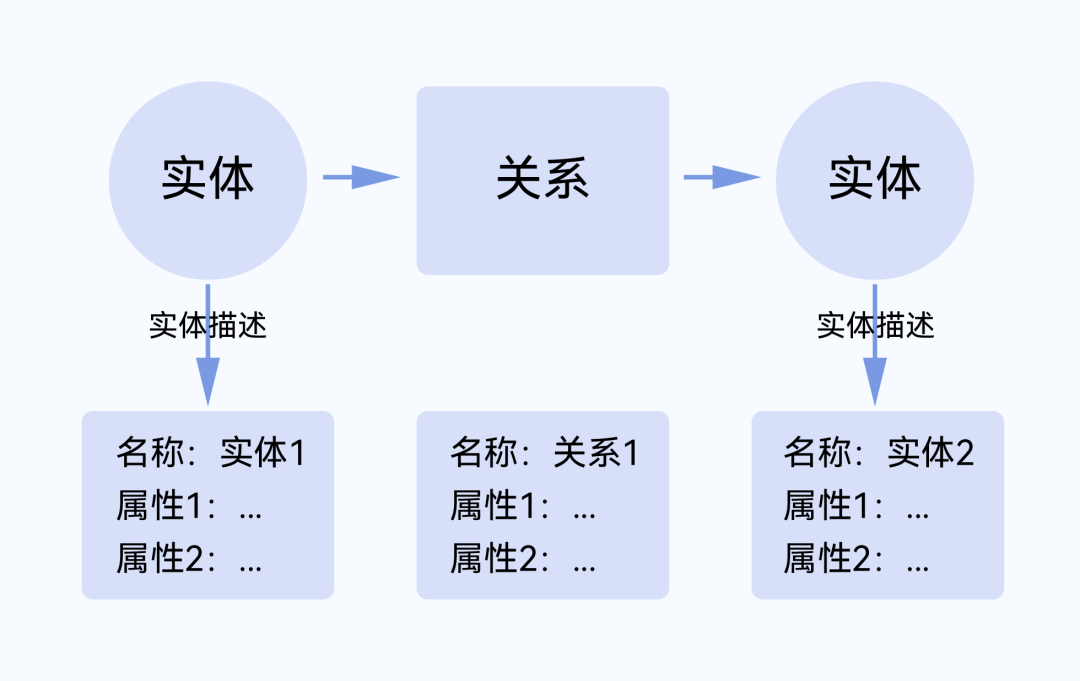
图2-本体设计
使用工具:知识图谱平台-本体管理
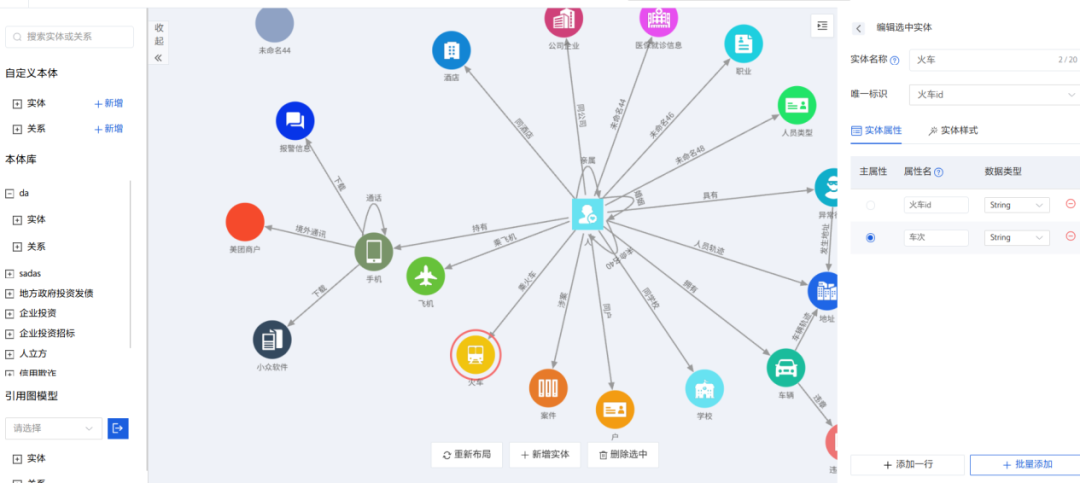
图3-本体模型结果预览界面
阶段二:数据获取与清洗
收集资料与信息来源
准备材料阶段就是数据获取与清洗,整合多源数据,对脏数据进行数据清洗,获得准确可靠的数据。具体步骤包含:多源数据获取、数据清洗。
1.多源数据获取
(1)结构化数据:企业工商数据库(如企查查API)、上市公司财报(CSV/Excel)、股票交易数据(时间序列)。
(2)半结构化数据:招股说明书、监管公示网页。
(3)非结构化数据:裁判文书。
2.数据清洗关键
金额与日期统一(如“2023/01/01” → “2023-01-01”)。
缺失值处理(如空股东名单需标记为“待核查”)。
使用工具:知识图谱平台-数据管理
图4-数据连接
阶段三:知识抽取
挖掘关键要素
知识抽取阶段就是基于清洗后的数据拆解出有用的零件阶段,需要从文本/表格中识别实体、关系及属性。具体步骤包含:实体识别、关系抽取、属性抽取。
1. 实体识别
从文本中提取实体(如企业实体,自然人(股东/高管))。
2. 关系抽取
识别实体间关系(如股权关系(“A持股B 30%”)、担保关系(“A为B提供连带责任担保”)。
3. 属性抽取
补充实体特征(如企业属性:注册资本、行业分类,个人属性:任职履历、关联企业数量。)
使用工具:知识图谱平台-知识抽取
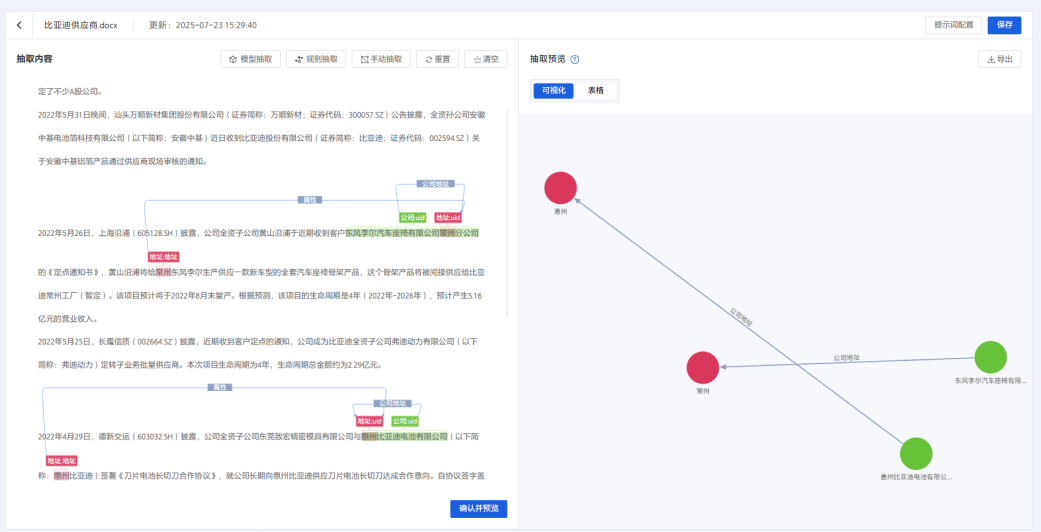
图5-数据抽取
阶段四:知识融合
消除冲突与冗余
知识融合就是组装调试阶段,把重复的零件合并(实体对齐),检查零件之间是否匹配(语义消歧)。具体步骤包含:实体对齐、语义消歧。
1.实体对齐
实体对齐:合并相同实体,如同一企业不同表述(如“蜀天梦图” vs “蜀天梦图数据科技有限公司”)。
2.语义消歧
解决矛盾数据(如不同来源的“注册资本”数值)。
使用工具:知识图谱平台-知识融合
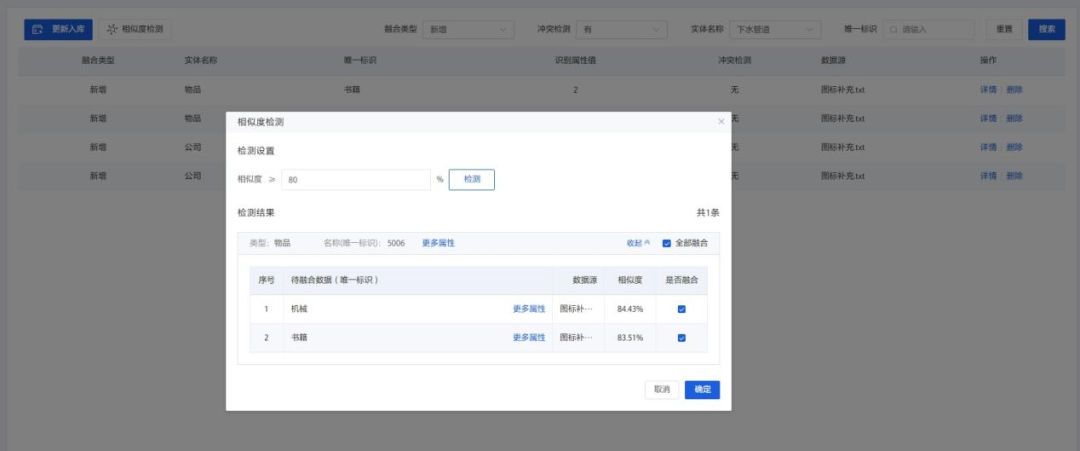
图6-知识融合
阶段五:知识存储
选择合适容器-图数据库
知识存储就是入库保存阶段,把整理好的数据存放到专门的"数据库",采用分布式原生图数据库GDMBASE,方便以后快速取用。
使用工具:分布式原生图数据库GDMBASE-数据存储
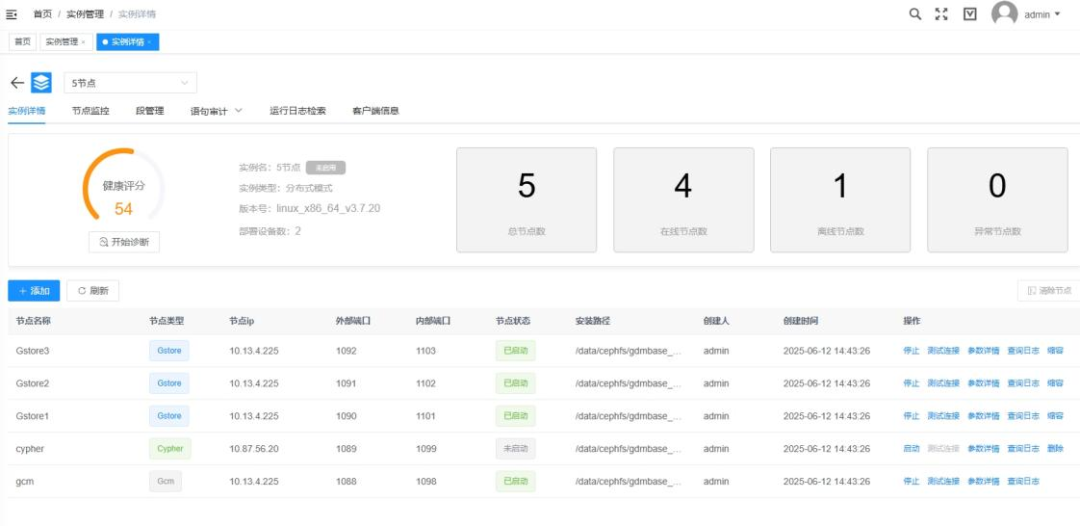
图7-数据存储
阶段六:知识加工
知识加工这一步就像是给知识库做全面检查:自动补充没说清楚的关系,还要检查是否有矛盾点,做"查漏补缺"和"质量检查"。具体步骤包含:知识推理、质量评估。
1.知识推理
补全缺失的隐含关系(如“A是B上司→B是A下属”)。
2.质量评估
校验准确性、一致性,确保推理后的知识符合领域逻辑且无矛盾。
使用工具:知识图谱平台-图分析
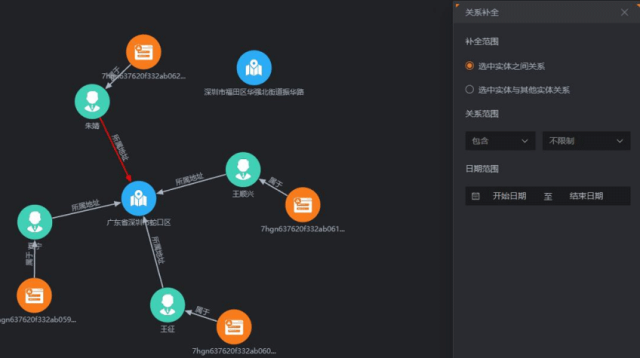
图8-关系补全
阶段七:知识图谱应用
知识图谱应用就是投入使用阶段,基于建好的知识图谱实现查询、推理、可视化等下游任务,具体应用包含:领域知识库、知识推理、可视化分析、LLM增强。
1.数据整合
把分散的数据串成一张网-领域知识库。
无论是数据库里的结构化数据,还是文档、网页里的文字信息,知识图谱都能统一“建模”,构建出清晰的领域知识库。
图9-知识库
2.多跳查询&路径推理
找出隐藏的关系链。
不是简单查“某个点”,而是能一步步“顺藤摸瓜”查出人和人之间、事和事之间的因果链、影响链、上下游依赖。
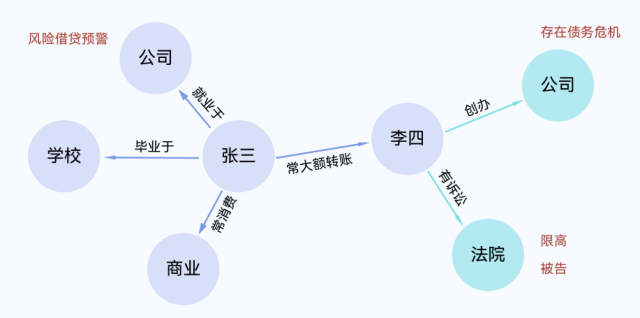
图10-路径推理
3.可视化分析
让复杂关系一目了然
整合多源数据,构建关系网络,辅助企业洞察(如金融风控、供应链优化)。
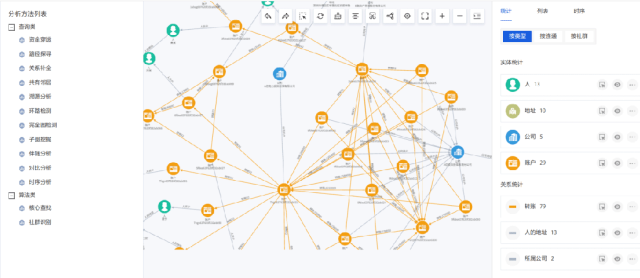
图11-可视化分析
4.知识推理
不光查得到,还能自动“想得到”
通过图结构和内置规则,图谱可以“补全”遗漏的信息、识别潜在模式,支持智能判断和预警提示。
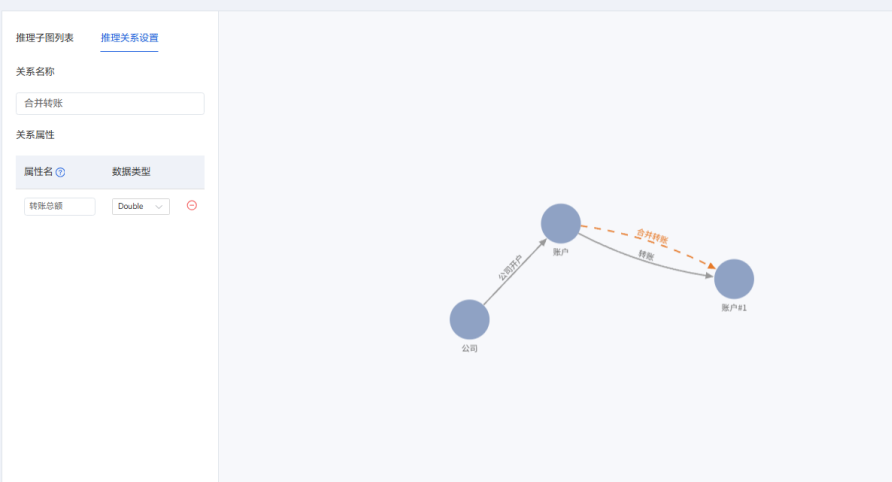
图12-知识推理
5.LLM增强
让大模型有“脑有记性”
图谱可以作为大模型的知识支撑,结合GraphRAG技术,通过逻辑推理生成答案,让问答不再“胡说八道”。
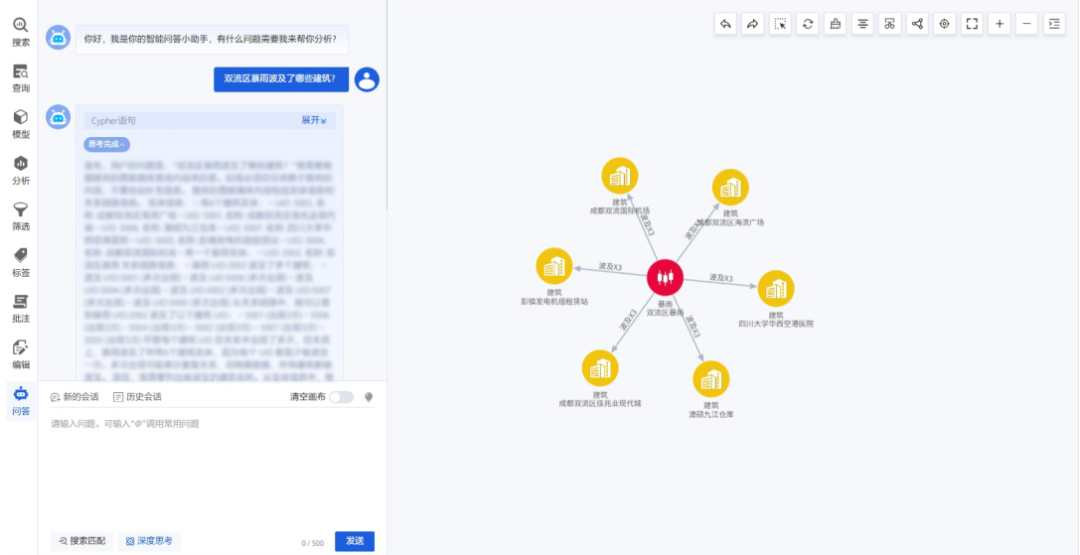
图13-LLM增强
四、实践工具推荐
GDMBASE图数据库引擎-数据存储
GDMBASE是四川蜀天梦图数据科技有限公司完全自主研发的一款支持属性图模型的数据库,它使用原生图存储的方法对图数据进行存储、查询和运算,并提供了丰富的客户端编程接口。
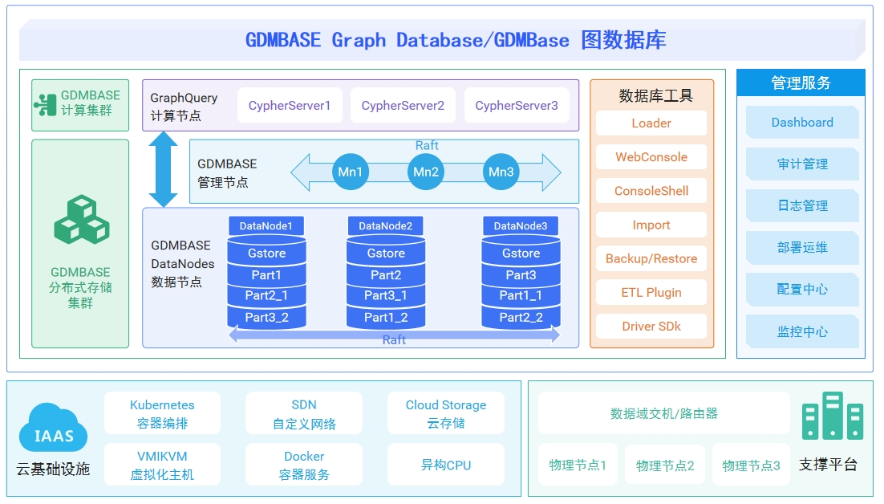
图14-GDMBASE图数据库架构
知识图谱平台-数据图谱交互分析
知识图谱平台提供数据管理、本体建模、数据存储、图谱分析等从构建分析到管理全生命周期的数据分析能力,结合多维的图可视化能力,为用户提供丰富多样的图分析体验,从而更高效地挖掘数据价值。
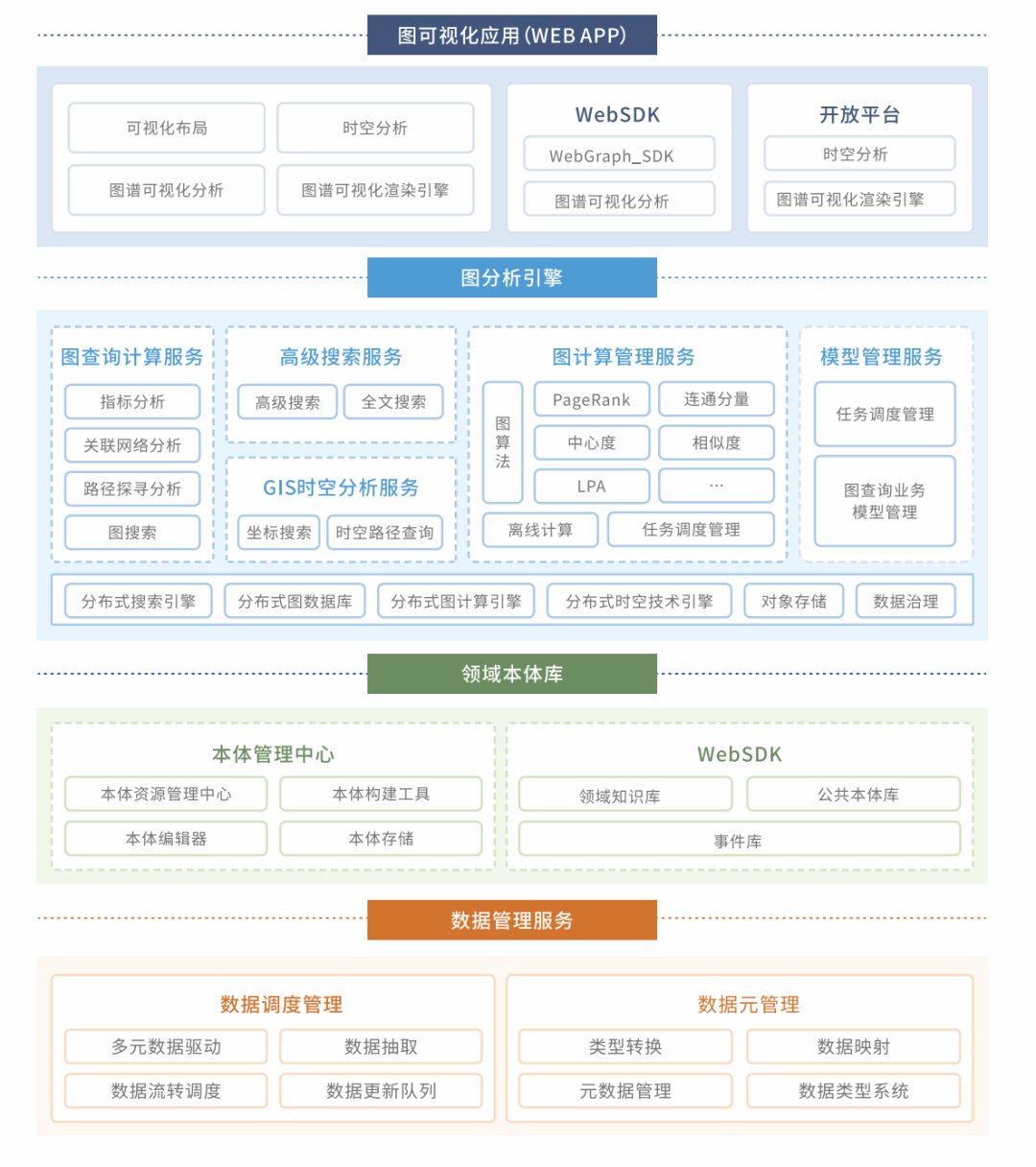
图15-知识图谱平台架构
在知识图谱建设进入“工程化阶段”的今天,仅靠通用数据库或离线处理工具已无法胜任。而通过GDMBASE强大的图存储与图查询能力,配合知识图谱平台的建模与分析,可以构建真正可用、可管、可推理的知识图谱系统。未来,随着多模态融合与大模型集成的深入,知识图谱将成为智能系统的基础“神经网络”。
*注:图1-13中的数据均为虚拟数据,仅供参考
撰文 | 阿芙拉
校对 | 莉佳

