





当下大模型应用涉及的非结构化数据处理和管理,实际大多是跟着MaaS平台和应用走的,传统大数据平台一方面并没有做好技术上的准备,另一方面也跟架构规划上的模糊有关系。
比如,公司的向量库到底应该由MaaS建,应用建,还是大数据平台建,当前没有定论,因此往往各显神通。
但随着大模型应用的规模化,非结构化数据的统一处理和管理,一定要逐步提上日程,这就跟大数据平台息息相关了。
本文提供了一张融合非结构化处理的大数据平台架构蓝图,并且尝试明确与MaaS平台的分工,最后给出了一个处理案例,希望给你以启示。
一、架构全貌
开头一张图镇楼,大家自己品味。
图中蓝色部分为结构化处理模块,绿色部分为新增的非结构化处理模块,红色部分为协作的MaaS模块,青色部分为湖仓一体模块。
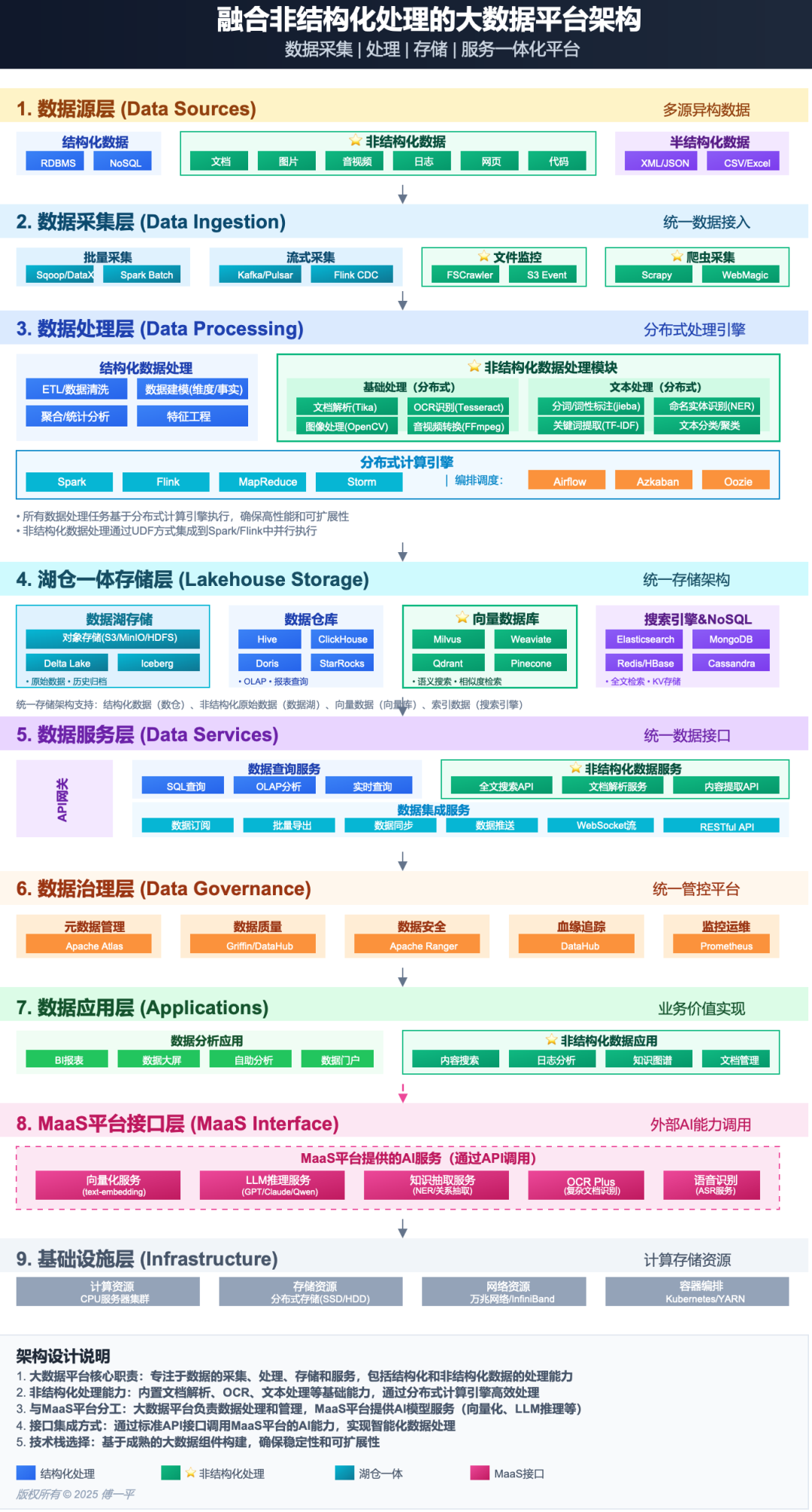
1.1 九层结构
想象一栋九层大楼,每层各司其职:

数据从底层向上流动:原始数据→采集→处理→存储→服务→应用,每一层都为上层提供支撑。
1.2 与传统平台的本质区别

核心升级:从"存储数据"进化到"理解数据",从"统计分析"进化到"智能应用"。
二、分层解读
第1层:数据源层 - 所有数据都是原料
传统能力:
- 结构化:MySQL、Oracle等数据库
- 半结构化:JSON、XML、CSV文件
🌟 非结构化扩展:
- 文档类:Word、PDF、PPT(企业知识的主要载体)
- 媒体类:图片、音频、视频(会议录音、产品图片)
- 文本类:网页、日志、代码(系统日志、技术文档)
💡 价值点:让企业90%被忽视的数据资产"活"起来
第2层:数据采集层 - 智能化的数据搬运工
传统采集:
- Sqoop/DataX:定时批量导入,像货车定点运输
- Kafka/Flink CDC:实时数据流,像传送带不停运转
🌟 非结构化采集:
- FSCrawler:文件夹监控器,新文件自动发现并采集
- Scrapy爬虫:网页采集器,自动抓取网站内容
- S3 Event:云存储事件触发,文件上传即采集
💡 通俗理解:就像配备了自动扫描仪、网络爬虫和智能监控的数据收集系统
第3层:数据处理层 - 数据的智能加工厂
这是整个平台的核心引擎,分为两条生产线:
传统生产线:
- ETL清洗、数据建模、聚合统计
🌟 非结构化生产线:
基础处理车间(分布式执行):
- Tika文档解析:把PDF/Word变成文本,像把纸质书数字化
- Tesseract OCR:识别图片文字,扫描件秒变可编辑文本
- OpenCV图像处理:图片裁剪、格式转换、特征提取
- FFmpeg音视频处理:提取音轨、视频转码、截取片段
文本处理车间(分布式执行):
- jieba分词:把句子切成词语,"大数据平台"→"大数据/平台"
- NER实体识别:找出人名、地名、产品名、金额等关键信息
- TF-IDF关键词提取:自动找出文档的核心主题词
- 文本分类聚类:自动给文档贴标签、归类
计算引擎:
- Spark/Flink:分布式处理框架,把任务分给100台机器同时干
- Airflow调度:任务编排器,确保处理流程有序进行
💡 技术突破:通过UDF(用户自定义函数)将AI能力嵌入大数据引擎,实现规模化智能处理
第4层:湖仓一体存储层 - 四大智能仓库
数据湖(原始库):
- MinIO/S3:对象存储,啥都能装的大仓库
- Delta Lake/Iceberg:数据湖表格式,支持版本管理和事务
数据仓库(整理库):
- Hive/ClickHouse:OLAP分析引擎,专门做报表统计
🌟 向量数据库(语义库):
- Milvus/Weaviate/Qdrant:存储文本/图片的数学表示
- 核心能力:AI时代的关键新增组件,语义搜索,输入"产品质量问题"能找到所有相关内容
- 应用场景:相似文档查找、智能推荐、知识检索
搜索引擎(索引库):
- Elasticsearch:全文检索引擎,毫秒级搜索TB级数据
- MongoDB/Redis:NoSQL存储,灵活的文档数据库
💡 创新点:向量数据库是连接传统数据和AI的桥梁,让计算机真正"理解"内容含义
第5层:数据服务层 - 统一的数据超市
API网关:所有服务的统一入口
传统服务:
- SQL查询、OLAP分析、数据订阅
🌟 非结构化服务:
- 全文搜索API:关键词搜索所有文档
- 向量检索API:基于语义找相似内容
- 内容提取API:自动提取摘要、关键信息
💡 服务化思维:把复杂的数据能力包装成简单的API调用
第6层:数据治理层 - 数据的守护者
- Apache Atlas元数据管理:数据字典,记录每个数据的身份信息
- DataHub数据质量:数据体检中心,确保准确性
- Apache Ranger安全管控:权限管理,谁能看什么数据
- 血缘追踪:数据族谱,追踪数据来龙去脉
第7层:数据应用层 - 价值变现的舞台
传统应用:
- BI报表、数据大屏、自助分析
🌟 非结构化应用:
- 智能搜索:企业知识库的Google
- 日志分析:从海量日志中发现异常
- 知识图谱:构建企业知识网络
- 文档管理:智能分类、自动标签
第8层:MaaS平台接口层 - AI能力的加油站
关键说明:本架构的关键设计之一,用于实现与外部AI能力的解耦。 大数据平台通过API调用外部MaaS平台提供的服务,获取更高级的AI能力,而无需自己部署和维护复杂的模型。
核心服务:
- 向量化服务:把文本变成AI能理解的数字(embedding)
- LLM推理:调用GPT/Claude等大模型
- 知识抽取:从文本中提取结构化信息
- OCR Plus:识别复杂版式文档
- ASR语音识别:语音转文字
💡 架构智慧:大数据平台管数据,MaaS平台管AI,分工明确,各司其职
第9层:基础设施层 - 算力底座
- 计算资源:CPU服务器集群
- 存储资源:分布式存储阵列
- 容器编排:Kubernetes资源调度
- 网络:万兆网络、InfiniBand高速互联
三、实战演练:智能合同管理系统
📋 场景设定
某大型企业有10万份历史合同(PDF格式)、每天新增100份合同、大量合同谈判录音,需要构建智能合同管理系统。
🔄 端到端处理流程
Step 1:数据采集
- FSCrawler监控合同文件夹,新合同自动采集
- 历史合同批量导入
- 谈判录音实时上传
Step 2:智能处理
PDF合同 → Tika解析 → 提取文本
扫描件 → OCR识别 → 转为文本
录音文件 → 调用MaaS的ASR → 转为文字
Step 3:信息提取(左右滑动看全部)
合同文本 → NER识别 → 提取:
甲方乙方名称
合同金额
签署日期
关键条款
文本分块 → 每1000字一块 → 调用MaaS向量化服务 → 生成向量
Step 4:多维存储
原始PDF → 数据湖(备份)
结构化信息 → 数据仓库(统计分析)
合同全文 → Elasticsearch(全文检索)
文本向量 → Milvus(语义搜索)
Step 5:智能应用
场景1:风险条款排查
- 用户输入:"查找所有包含无限责任条款的合同"
- 系统:向量化查询 → Milvus语义搜索 → 返回相关合同
- 调用MaaS的LLM → 生成风险分析报告
场景2:相似合同查找
- 上传新合同 → 系统自动找出最相似的5份历史合同
- 对比条款差异 → 提示风险点
场景3:合同问答助手
- 问:"我们和XX公司的合作期限是多久?"
- 系统:语义检索 → 找到相关合同 → 调用LLM生成答案
- 答:"根据2023年签署的服务合同,合作期限为3年,至2026年12月31日止。"
🎯 协同效果
- 大数据平台:负责合同的存储、检索、统计分析
- MaaS平台:提供OCR、语音识别、向量化、智能问答能力
- 业务价值:合同审核时间从3天缩短到3小时,风险识别准确率提升80%



🧐分享、点赞、在看,给个3连击呗!👇
