




导读
在大型数据库系统中,日常运行可能包含成千上万条 SQL,但真正决定系统整体性能的,往往是其中少数几条“高消耗 SQL”。这些 Top SQL 常常伴随着 CPU 飙升、IO 瓶颈、响应延迟 等问题,成为性能优化的关键突破口。如何精准识别并定位这些 SQL,不仅能快速缓解系统压力,还能为后续的优化提供明确方向。
本次我们邀请到云和恩墨技术顾问李宁,带来《从采集到提速,如何精准定位 Oracle Top SQL,轻松降低 CPU 和系统负载》精彩分享,他结合实际案例深入剖析运维交付中常见的风险场景,并总结出一系列可落地的安全实践建议。
本文整理自直播分享,部分语句在不改变原意的基础上做了更改。
演讲资料:https://www.modb.pro/doc/146688
视频回放:https://www.modb.pro/video/10648

李宁
云和恩墨技术顾问
主要负责Oracle、OceanBase方向的技术支持,包括日常运维、故障处理、性能优化等。获得MySOL8.0OCP、MySQL8.0 DBD OCP、OBCA、YCA、YCP、KCA、KCP、软件设计师等证书。
在日常数据库运维中,我们经常会遇到系统负载高、CPU 飙升的问题,而问题的根源往往集中在少数高消耗的 SQL 上。为了帮助大家快速发现性能瓶颈,我今天将围绕为何要关注 Top SQL、如何采集与分析、以及常见的优化思路 展开探讨。
为什么要关注 Top SQL
在日常运维中,数据库会执行成千上万条 SQL,但真正消耗大量资源的往往只有少数几条。实践表明:
• 20% 的 SQL 消耗了 80% 的资源;
• 在很多系统中,几条 SQL 就能导致 CPU 使用率飙升、操作系统负载过重。
因此,定位并优化 Top SQL 是数据库性能优化中最有效的突破口。
然而,从发现系统异常到真正定位问题 SQL,中间往往存在不小的差距。我们不仅要识别出最消耗资源的 SQL,还需要结合执行特征与等待事件,判断瓶颈究竟出在 CPU 还是 I/O,是 高频执行 还是 大数据量处理。在日常运维里,DBA 在分析问题时经常会遇到几个典型难点:
- 没有完善的监控体系或产品,监控的的数据库指标有限我们能看到 CPU 高、IO 打满,各种等待事件,但很难快速精准地定位到是哪条 SQL 造成的。
- 手工分析效率低靠人工收集 GV$SQL 、ASH或 AWR,既耗时又容易遗漏,根本不适合生产紧急场景。
- 缺少长期跟踪手段没有将信息做一个时间上的归档,导致很多 SQL 是等出问题后才发现,没有纵向对比信息

图1:日常运维的典型问题及SQL优化
近期在一个优化专题中,一套 Oracle 系统在向 OceanBase(OB)做迁移评估时发现,其原有数据库可能承受不住业务压力。优化目标是将 Oracle 数据库的 CPU 使用率从 40%-60% 降低到约 30%。
在实际优化过程中,一般我们可以从围点打圆式优化 SQL以及按 AWR 的 Top SQL 进行优化两个方向入手,实现资源的有效利用。
Oracle GETS Top SQL 自动化采集脚本
手工查询 V$ 视图或 AWR 效率低,且难以长期跟踪。通过自动化脚本,我们可以持续采集 Top SQL,建立历史数据,形成完整的优化闭环。
1、脚本设计思路
- 数据来源:AWR 的
dba_hist_sqlstat与dba_hist_sqltext - 存储方式:写入自建表
top_sql_history - 统计方式:按 SQL_ID 分组,计算逻辑读总量、执行次数、CPU 时间,识别前 N 热点 SQL
- 调度方式:通过
DBMS_SCHEDULER定时执行,每小时或每天采集一次
2、自动化采集的价值
- 趋势分析:可观察 7 天或 30 天的热点 SQL 变化
- 优化闭环:优化前后对比逻辑读和 CPU 使用情况
- 效果量化:通过历史数据量化优化成果,便于向管理层汇报
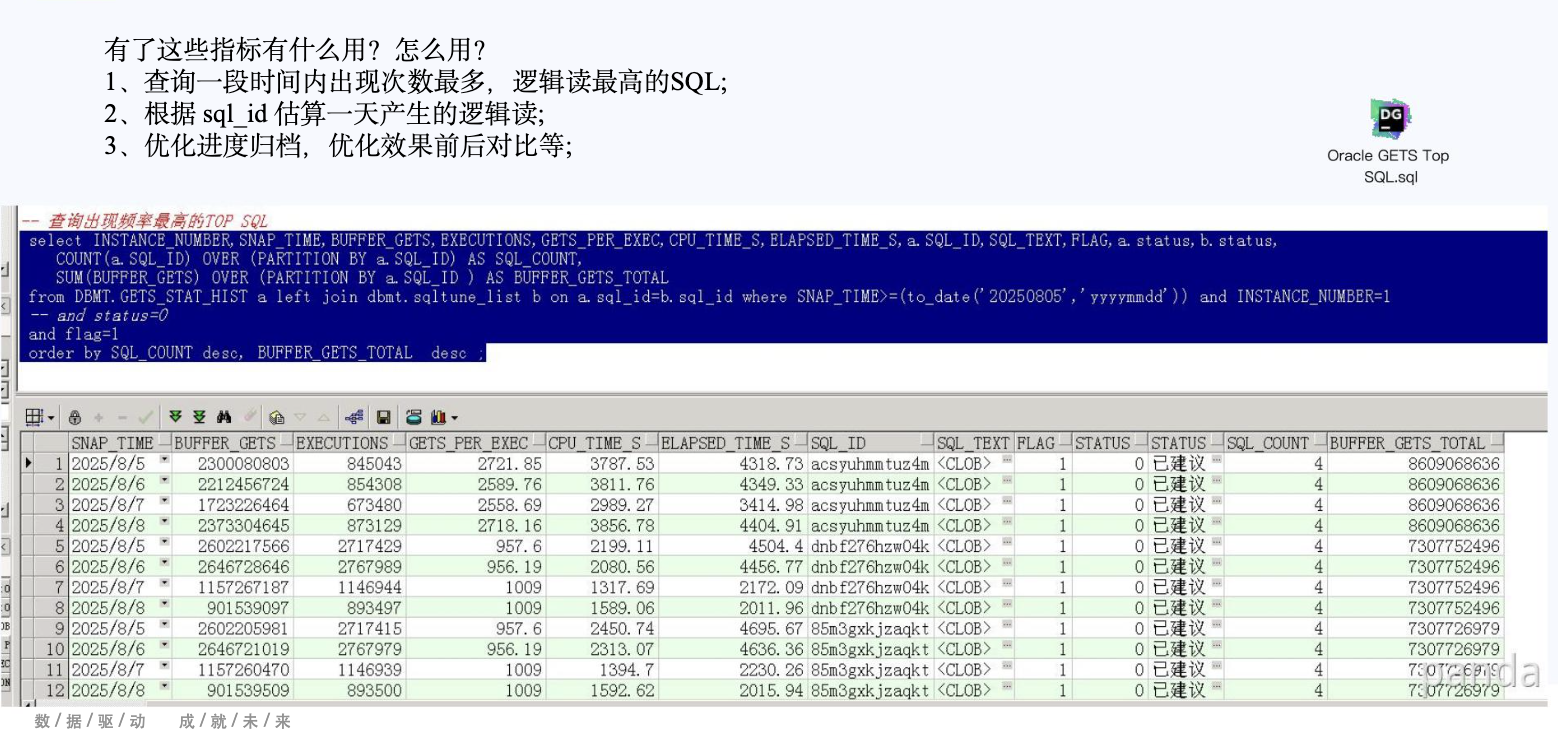
图2:Oracle GETS Top SQL 自动化采集脚本的指标及作用
SQL 优化案例分享
在实际的数据库运维中,我们发现少数 SQL 往往消耗了绝大部分资源。下面,我结合真实案例,分享几个典型的 Top SQL 优化经验,展示如何有效降低逻辑读和 CPU 占用。
案例 1:统计信息缺失
在一次 OLTP 系统排查中,我们发现某条 SQL 选择了低选择性索引,CPU 使用率瞬间飙升至 95%。分析执行计划后发现,统计信息过期导致优化器选择了不合适的索引。
- 优化策略:重新收集最新统计信息,确保优化器能选择最优执行计划;
- 优化效果:CPU 使用率从 95% 降至 30%,系统负载明显下降。
案例 2:索引跳跃扫描
某查询频繁触发 Index Skip Scan,逻辑读达到 3 万,执行时间 18ms,明显成为性能瓶颈。
- 优化策略:通过改写谓词或新增合适索引,使查询能够走更高效的访问路径;
- 优化效果:逻辑读降至 5 千,执行时间降至 3ms。
案例 3:索引碎片问题
小表频繁插入删除导致索引碎片严重,查询逻辑读超标,影响整体性能。
- 优化策略:执行 shrink space 或重建索引,恢复索引结构连续性;
- 优化效果:逻辑读降至个位数,查询稳定性大幅提升。
案例 4:复杂 OR 条件
某业务报表查询包含多个 OR 条件,导致执行计划低效,逻辑读过高。
- 优化策略:将 OR 条件拆分为多个 UNION 查询,使优化器可以分别选择最优路径;
- 优化效果:逻辑读从 1017 降至 609,执行效率显著提升。
案例 5:分区裁剪缺失
更新分区表时未使用分区键,导致逻辑读高达 120 万,严重影响系统吞吐。
- 优化策略:增加分区键条件,触发动态分区裁剪;
- 优化效果:逻辑读降至 61,执行时间从 5 秒降至 0.2ms,性能提升几乎是量级级别。
案例 6:高频任务 SQL
任务表中的少数 SQL 长期占用大量 CPU,成为系统瓶颈。
- 优化策略:增加索引、改写 SQL,并对部分计算结果进行缓存;
总结与扩展
通过前面的案例可以清楚地看到,少数 Top SQL 往往决定系统整体性能。在实践中,我们发现仅凭经验或临时排查,很难长期维持系统的高效运行。因此,针对 Top SQL 的优化需要形成系统化的方法。基于这些实践经验,我们总结出几个关键方向:
1. 关注 Top SQL
精准定位少量高消耗 SQL,是性能优化的首要突破口。
2. 自动化采集
通过 GETS 脚本持续采集 Top SQL,建立历史数据,实现趋势分析和长期跟踪。
3. 形成优化闭环
从采集 → 定位 → 优化 → 对比 → 长期跟踪,形成持续改进机制。
4. 优化方向
- 索引优化:增加缺失索引、消除碎片、避免跳跃扫描;
- SQL 改写:拆分 OR 条件、优化复杂查询;
- 统计信息:及时收集,保证优化器选择最优计划;
- 分区裁剪:合理利用分区键,减少无效扫描。
5. 扩展应用
- 方法可迁移至 OceanBase、MySQL 等其他数据库;
- 可结合监控平台生成可视化报表,为管理层提供数据支持;
- 支撑数据库迁移、容量规划及系统性能评估。
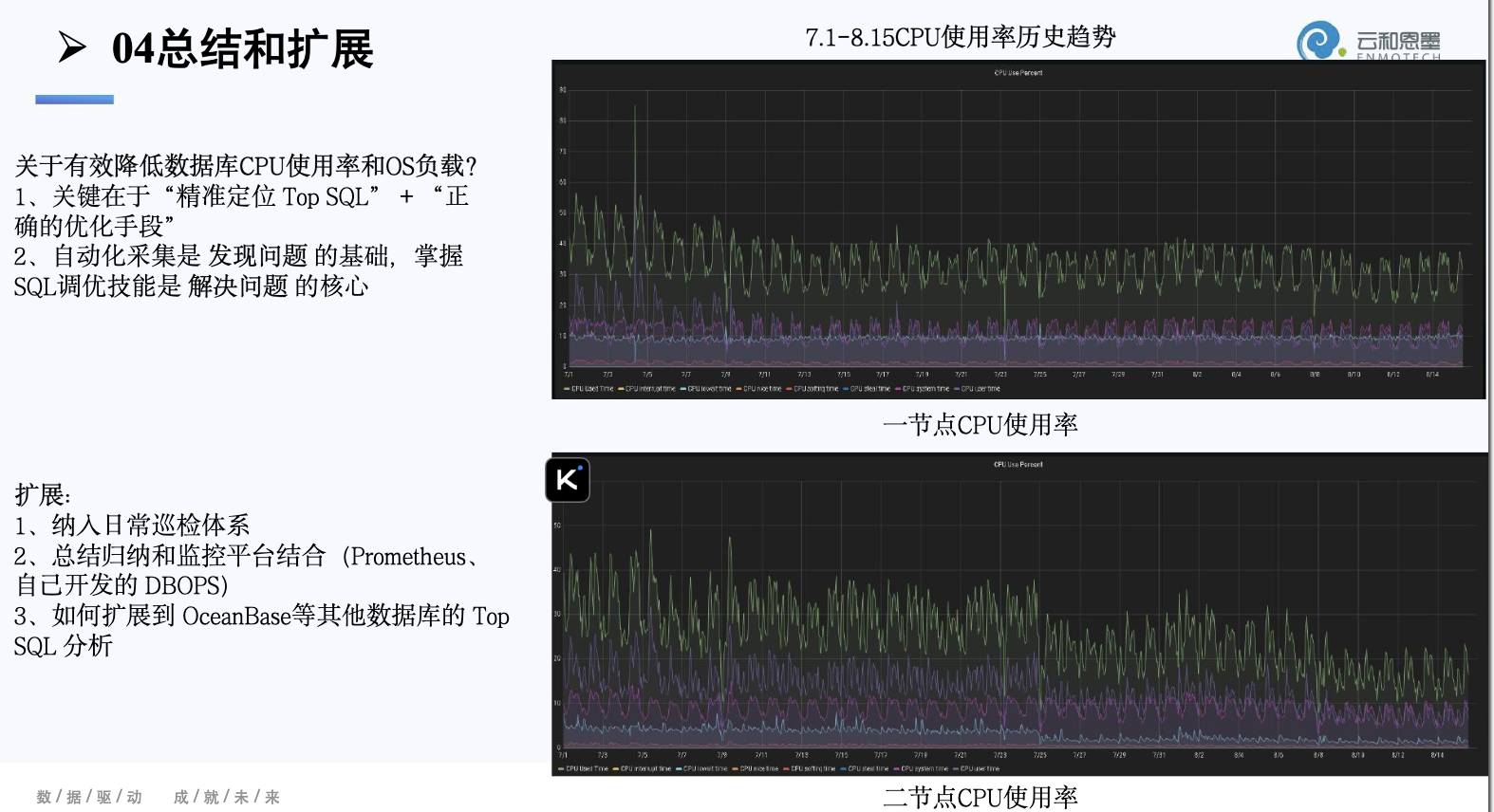
图3:总结和扩展
通过精准定位 Top SQL、建立自动化采集机制并进行优化,我们不仅能显著降低 CPU 和逻辑读,也能形成数据驱动的长期优化机制,为数据库稳定运行提供保障。
以上就是我今天的所有分享,谢谢大家!
