





本文字数:15692;估计阅读时间:40 分钟
作者:Tom Schreiber

Meetup活动
ClickHouse 北京第三届 Meetup 火热报名中,详见文末海报!
TL;DR
我们从零开始重新构思了 ClickHouse 列式存储中的类 SQL UPDATE 实现方式。本文将详细介绍我们如何完成这一过程,从最初的重量级 mutation,到借助可扩展 patch part 实现的轻量级更新。性能基准测试将在第 3 部分发布。

列式存储并不以快速更新著称。
长期以来,面向分析场景设计的系统通常会牺牲更新性能,以换取更快的读取速度。行级别的变更被认为与高吞吐、优化扫描的架构天然不兼容。
ClickHouse 也曾是如此,直到我们通过 *重新定义“更新”的本质*,打破了这一限制。
在 第 1 部分 中,我们介绍了 ClickHouse 采用的一种全新模型:将更新转换为插入。通过像 ReplacingMergeTree 和 CollapsingMergeTree 这样的专用引擎,系统可以异步地在后台通过合并操作完成更新,同时保持极高的写入性能。
不过,并不是所有用户都希望以“合并语义”的方式思考更新操作。许多用户只想简单地写出这样的 SQL 语句:
UPDATE ordersSET discount = 0.2WHERE quantity >= 40;
因此,我们希望在不牺牲 ClickHouse 性能优势的前提下,支持这种使用方式。
本文将介绍我们是如何实现这一目标的。
我们将带你了解 ClickHouse 中类 SQL 更新机制的演进过程:
经典的 mutation,虽然简单但代价较高; 向前迈进的一步:即时更新,无需等待 mutation 完成; 最终通过 patch part 实现快速声明式 SQL 更新,这是一种专为高频率工作负载设计、具备良好可扩展性的原生列式更新机制。
想了解性能表现?敬请关注第 3 部分。本文将聚焦于快速更新背后的架构设计。
我们先来回顾一下 ClickHouse 多年来所支持的基于 mutation 的传统 UPDATE 实现方式。
自 2018 年起,ClickHouse 就已经支持使用 ALTER TABLE... UPDATE(https://clickhouse.com/docs/sql-reference/statements/alter/update) 语句进行类 SQL 的更新操作。
我们将继续沿用 第 1 部分 中的 orders 表示例,来说明 UPDATE 在底层是如何通过 mutation 实现的:
CREATE TABLE orders (order_id Int32,item_id String,quantity UInt32,price Decimal(10,2),discount Decimal(5,2))ENGINE = MergeTreeORDER BY (order_id, item_id);
下面我们将从一次初始插入操作开始,逐步剖析一个简单的 UPDATE 如何在底层触发 mutation 过程。
初始插入
我们从一个包含同一订单中两个商品的 part 开始:
INSERT INTO orders VALUES(1001, 'kbd', 10, 45.00, 0.00),(1001, 'mouse', 6, 25.00, 0.00);
这将生成一个名为 all_1_1_0 的数据 part(命名规则详见此处(https://clickhouse.com/blog/updates-in-clickhouse-1-purpose-built-engines#how-to-read-a-part-name)):

UPDATE 会触发变更
接下来,我们对其中鼠标商品的数量和折扣进行了更新:
ALTER TABLE ordersUPDATE quantity = 60, discount = 0.20WHERE order_id = 1001 AND item_id = 'mouse';
ALTER TABLE ... UPDATE 的语法特意与 标准 SQL UPDATE(https://www.w3schools.com/sql/sql_update.asp) 不同,以反映底层的实际机制:ClickHouse 并不会就地修改行数据,而是通过重写数据 part(即执行 mutation)来完成更新。
由于执行了 UPDATE,ClickHouse 在后台触发了一次 mutation(https://clickhouse.com/docs/sql-reference/statements/alter#mutations) 操作。这个过程包括三个内部步骤:
系统会为此次更新 分配一个新的块号(如 2),用于标记哪些 part 需要被重写(可参考part 的块结构(https://clickhouse.com/blog/updates-in-clickhouse-1-purpose-built-engines#how-blocks-make-up-a-part))。
2. 然后在磁盘上创建一个新的 更新后 part,命名为 all_1_1_0_2,其中的数字 `2` 表示此次 mutation 的版本号。
3. mutation 仅适用于块号小于 2 的 part,例如最初的 all_1_1_0。
下图展示了更新发生的情况:被修改的列(quantity 和 discount)会被完全重写;未修改的列(如 order_id、item_id、price)则通过硬链接(https://en.wikipedia.org/wiki/Hard_link) 的方式进行复用。这些列的数据文件不会被复制,新的 part 直接复用磁盘上的原始文件:
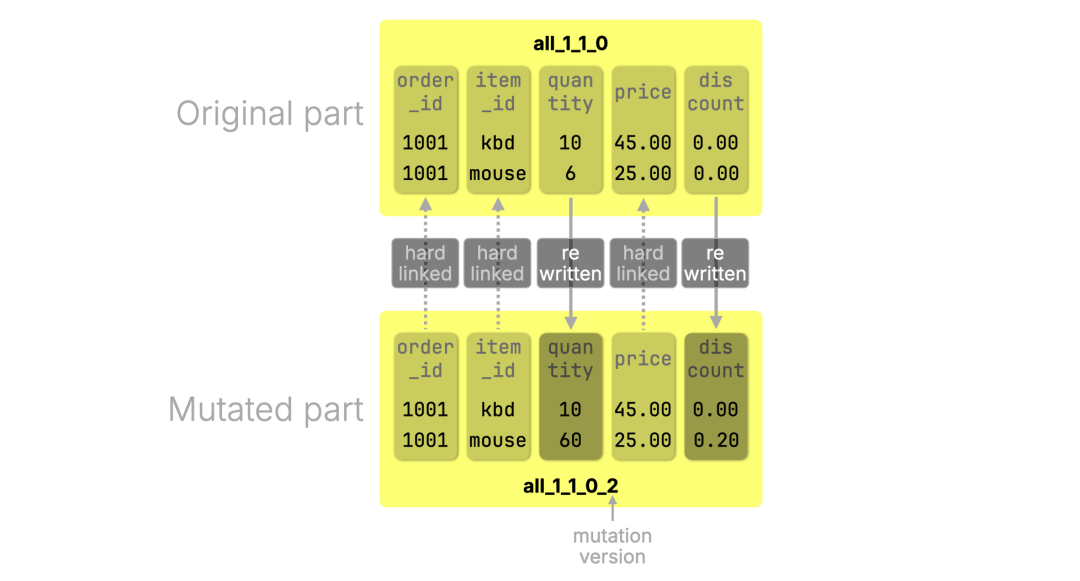
当 mutation 完成后,新的 part all_1_1_0_2 会替换原始的 all_1_1_0,后者随即被移除。尽管原始的 目录(https://clickhouse.com/blog/updates-in-clickhouse-1-purpose-built-engines#whats-inside-a-part) 及其文件项会被删除,但只要新的 part all_1_1_0_2 仍然通过硬链接引用原有的列文件,这些数据仍会安全地保留在磁盘中。硬链接机制可以确保文件只有在没有任何引用存在时才会真正被删除。
总结与权衡
这种经典的 mutation 模型具有较强的可靠性,但也伴随着一些代价:
更新成本较高:每次 UPDATE 都需要重写被修改的列,面对大规模数据时代价不菲;
可见性延迟:更新结果在后台 mutation 完成之前不会反映到查询中;
依赖合并操作:mutation 必须等前面的合并或 mutation 操作完成之后才能执行。(这部分内容在本文中未详细展开,但它确实存在,并且在某些情况下可能带来意想不到的限制。)
默认(https://clickhouse.com/docs/operations/settings/settings#mutations_sync)情况下,ALTER TABLE … UPDATE 语句是异步执行的,这样 ClickHouse 就可以将多个更新请求合并成一次 mutation,从而有效摊薄数据重写的开销。
在介绍即时 mutation(on-the-fly mutation)之前,我们先来看基于这一模型的另一个优化方案:轻量级删除(lightweight deletes)。
在推出即时 mutation 之前,ClickHouse 曾引入一种更简单的方式,以提升经典 mutation 模型下 DELETE 操作的性能。
DELETE 并不会立即删除数据行,而是被转换为 ALTER TABLE... UPDATE 操作,设置一个特殊的掩码列 _row_exists = 0。这会触发一次轻量级 mutation,系统只需写入或重写 _row_exists 一列,其余列通过硬链接方式复用已有数据,从而避免了不必要的磁盘读写操作。
如果这是该 part 上的首次删除 mutation,则在新的 part 中会创建 _row_exists 列;如果是后续的删除(且该 part 尚未被合并),则该列将被重新写入。
下图展示了轻量级 DELETE 执行前后的变化。我们将在图下逐步说明处理流程:
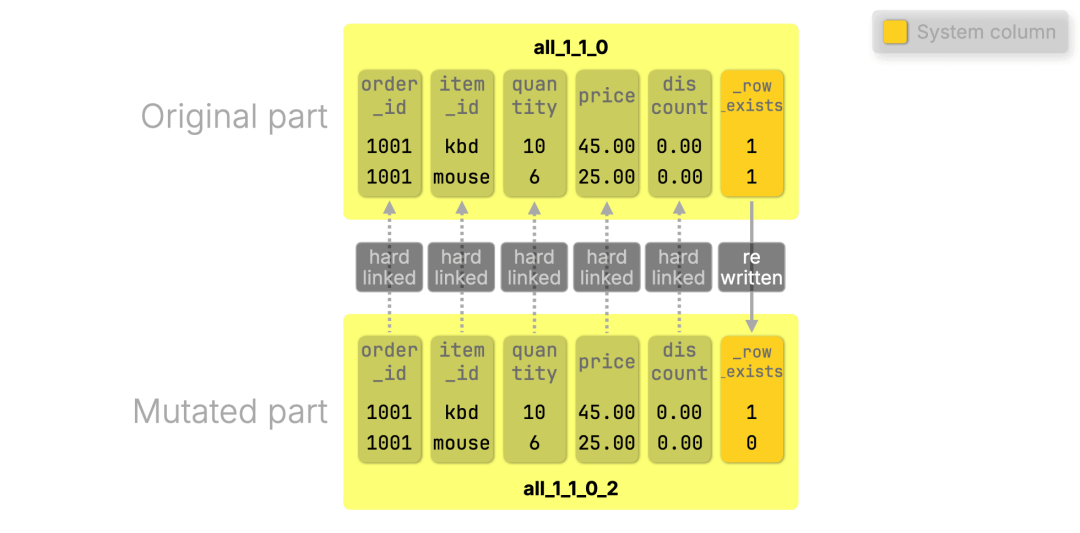
(为便于说明,我们在原始 part 中展示了 _row_exists 列。但如前所述,该列最初并不存在,而是由首次删除 mutation 动态添加。)
1. 初始插入:继续沿用第一阶段的小订单示例,插入两条记录,生成原始数据 part all_1_1_0:
INSERT INTO orders VALUES(1001, 'kbd', 10, 45.00, 0.00),(1001, 'mouse', 6, 25.00, 0.00);
2. 执行 DELETE 操作:例如删除其中的鼠标商品:
DELETE FROM orders WHERE order_id = 1001 AND item_id = 'mouse';
ClickHouse 内部会将该行的 _row_exists 标记为 0:
ALTER TABLE ordersUPDATE _row_exists = 0WHERE order_id = 1001 AND item_id = 'mouse';
3. 生成 mutation:创建新 part all_1_1_0_2,仅重写 _row_exists;
4. 查询行为变化:查询结果中,所有 _row_exists = 0 的记录将被自动排除;
5. 后续清理:该行数据会在下次后台合并任务中被彻底清除。
总结与权衡
这种方式在不改变原有 mutation 机制的前提下,使 DELETE 操作大幅提速。不过它仍然需要依赖后台重写才能彻底生效。
下一阶段的优化虽然也保留了后台重写机制,但实现了“更新即刻生效”的体验,无需等待 mutation 执行完成即可查询到更新结果。
传统 mutation 的代价不小——它需要重写完整的数据列,在处理大规模数据集时尤为耗时。为降低 UPDATE 与结果可见之间的延迟,ClickHouse 引入了 即时 mutation(https://clickhouse.com/docs/guides/developer/on-the-fly-mutations),这是一项使更新结果立即可见的优化,即使对应的数据部分尚未重写。
这是迈向 patch part 的关键第一步。虽然重写过程仍然存在,但用户能立即看到更新效果,大幅改善了交互体验。
下图展示了其执行机制:UPDATE 语句会被保存在内存中,并在查询读取时即时生效,而实际的数据 mutation 则在后台异步执行:
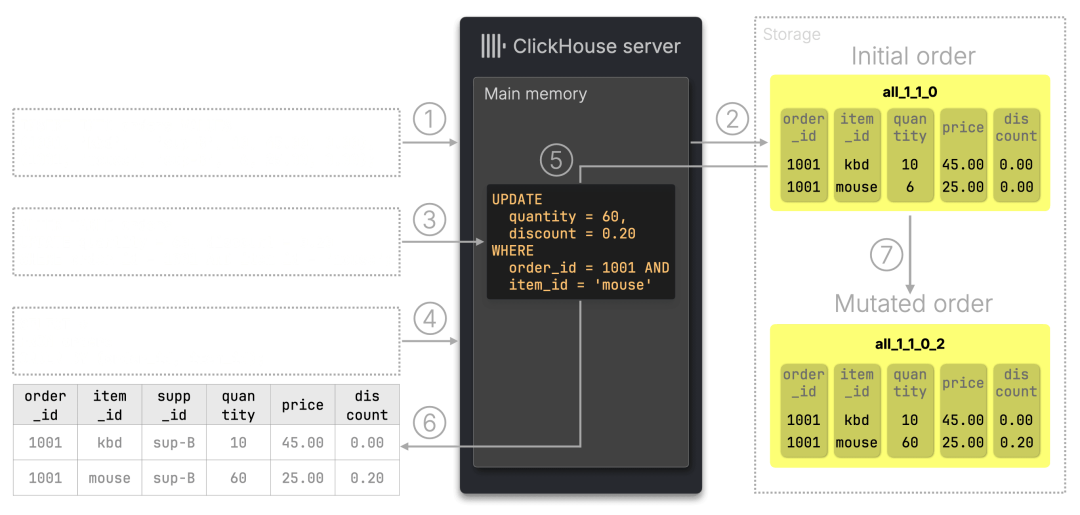
- 插入操作:如前所述,① 插入两条订单记录,② 生成初始 part all_1_1_0;
2. 发起 UPDATE:对鼠标商品的记录进行 ③ 更新,ClickHouse 将更新表达式暂存于内存;
3. 执行查询:当用户发出 ④ SELECT 查询时,系统读取原始数据并在内存中 ⑤ 实时应用更新逻辑;
4. 结果展示:⑥ 查询结果中立即可见更新后的记录;
5. 后台 mutation 启动:随后 ClickHouse 在后台完成 mutation,将数据重写为新 part all_1_1_0_2,并删除旧 part。
总结与权衡
即时 mutation 提升了用户查询的响应速度,但并未彻底移除后台重写的过程。在更新频率较高的场景下,它可能会对查询性能产生影响,此外对 子查询及非确定性函数的支持也较为有限(https://clickhouse.com/docs/guides/developer/on-the-fly-mutations#support-for-subqueries-and-non-deterministic-functions)。
因此,即时 mutation 更像是一种务实的过渡性优化,为我们开发更强大的机制预留了空间。而真正的飞跃则是后续的设计:patch part —— 一种为大规模频繁更新而生的全新机制。
之前的更新方案仍存在明显瓶颈,因此我们从头构建了一个更优的解决方案。
为什么经典变更不够用
即使有即时更新,原有模型依然面临以下挑战:
即便只更新了几行数据,也需要重写整列,导致资源浪费;
依赖前置的合并或 mutation,易带来查询延迟或行为不可预测。
正因如此,我们从零开发了 patch part。顾名思义,它在合并过程中对原始 part 进行“修补”,只应用发生变更的数据内容。
一个基于成熟经验的模型
patch part 的设计融合了我们在 专用引擎(https://clickhouse.com/blog/updates-in-clickhouse-1-purpose-built-engines)中已经验证的两个核心机制:高速写入 与 后台合并,并加以泛化,实现了支持灵活 SQL 风格更新的通用方案:
- 高速插入能力:ClickHouse 的写入性能极高(在一些生产环境中,每秒处理超 10 亿行数据(https://clickhouse.com/blog/how-tesla-built-quadrillion-scale-observability-platform-on-clickhouse#proving-the-system-at-scale)),我们将此能力用于构建轻量级的更新和删除流程;
2. 后台合并能力:MergeTree 本身就负责后台数据扫描与重写,因此在合并过程中附加执行更新或删除几乎不会带来额外开销,额外成本近乎为零(https://clickhouse.com/blog/updates-in-clickhouse-1-purpose-built-engines#merges-are-fast-thanks-to-sorted-parts)。
接下来,我们将通过一个简单示例来演示 patch part 的具体执行过程。(我们将从简入手,逐步展开其内部工作机制。)
我们仍以先前使用的小型 orders 表为例,来演示一次简单更新操作,并深入理解 patch part 的运行方式及其高效之处。
CREATE TABLE orders (order_id Int32,item_id String,quantity UInt32,price Decimal(10,2),discount Decimal(5,2))ENGINE = MergeTreeORDER BY (order_id, item_id);
基于 patch part 的 UPDATE 在 ClickHouse 25.7 中仍处于实验阶段
若希望在 ClickHouse 25.7 中体验该功能,需要手动启用以下设置:
SET allow_experimental_lightweight_update = 1;
ALTER TABLE orders MODIFY SETTING enable_block_number_column = 1, enable_block_offset_column = 1;
(该功能预计将在 25.8 版本进入 Beta 阶段)
我们继续沿用前文的订单示例,其中包含两个商品(键盘和鼠标)。这些记录被写入名为 all_1_1_0 的数据 part(见下图)。
INSERT INTO orders VALUES(1001, 'kbd', 10, 45.00, 0.00),(1001, 'mouse', 6, 25.00, 0.00);
假设鼠标的订单数量增加至 60 件,并因此享受 20% 的批量折扣,我们对对应的记录进行更新:
UPDATE ordersSET quantity = 60, discount = 0.20WHERE order_id = 1001 AND item_id = 'mouse';
此次 UPDATE 触发了一次基于 patch part 的 轻量级更新(lightweight update)。
patch part 更新支持标准 SQL UPDATE 语法(https://www.w3schools.com/sql/sql_update.asp)。ClickHouse 将这一新特性称为 lightweight update(https://clickhouse.com/docs/sql-reference/statements/update),不同于经典 mutation,它更贴近行级更新的语义:高频、小幅度的数据变更也能高效处理。
此时,更新内容 已立即在查询结果中可见,无需等待后台 mutation 执行完成。具体原理我们将稍后说明。
补丁部分是增量数据,而不是完整替换
与传统 mutation 模型不同,ClickHouse 不再重写整个列或 part,而是生成一个新的、小型的 patch part,其中仅包含:
本次更新的列值(例如 quantity = 60,discount = 0.20);
用于精确定位原始记录的元数据信息。
可以将 patch part 理解为“差异更新”:它只记录哪些行的哪些列发生了变化。因此我们称它为 轻量级更新:既紧凑又高效。
可视化示例:补丁部分如何更新行
下面是该 UPDATE 执行过程的可视化图示:
(为突出核心概念,图中略去了底层实现的部分细节,完整机制将在后文介绍。)
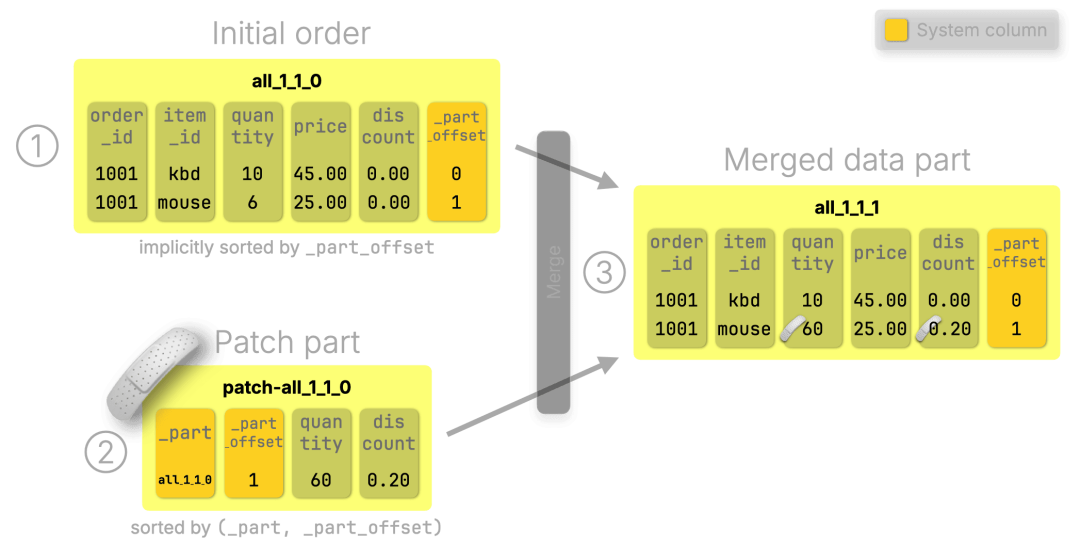
① 原始数据 part:
包含键盘和鼠标订单记录,并根据表定义的排序键 (order_id, item_id) 进行排序。每条记录还附带一个 虚拟列(https://clickhouse.com/docs/engines/table-engines/mergetree-family/mergetree#virtual-columns) _part_offset,用于标识其在 part 中的位置,因此整个 part 同时也按 _part_offset 排序。
② Patch part:
由本次 UPDATE 生成,仅包含原始 part all_1_1_0 中第 2 行的变更字段(quantity 和 discount),以及定位信息:_part = all_1_1_0,_part_offset = 1。
③ 合并结果:
在后续的后台合并过程中,ClickHouse 会将原始 part 与 patch part 合并,并用更新后的值替换对应的记录。
结构紧凑
Patch part 的核心设计目标之一,就是尽可能减少写入数据的体积:
仅写入那些 发生变更的字段值;
所有 未修改的列(如 order_id、item_id、price)完全省略,在 patch part 中不会出现。 (相比之下,像 ReplacingMergeTree 这类专用引擎需要重新插入整行,包括未变更的数据。)
执行高效
Patch part 充分利用 ClickHouse 已在后台持续运行的 合并机制(https://clickhouse.com/blog/updates-in-clickhouse-1-purpose-built-engines#merges-happen-in-the-background),几乎不带来任何额外负担:
数据 part 自然对齐:原始 part 按照表的排序键排序,并隐式按 _part_offset 排序;而 patch part 则按照 (_part, _part_offset) 排序;
这使得后台合并过程中能轻松以 _part_offset 为锚点对齐对应行,无需构建额外索引,也无需重新排序或重写;
更新操作可高效完成:引擎只需对原始 part 和 patch part 进行一次线性扫描,即可将更新内容自然地合并进去,无需临时缓冲区或随机读取。
(这种方式与 ClickHouse 专用引擎的逻辑类似,但 patch part 使用 _part_offset 作为定位依据,而不是依赖排序键。)
为便于说明,我们在上述示例中进行了简化,仅展示了 patch part 在单条更新场景下的基本运行方式。
接下来我们将展示其完整架构,并进一步解释其可扩展性。
为了理解 ClickHouse 如何实现 大规模、高并发、非阻塞的更新机制,我们需要了解 patch part 背后的系统列和元数据结构。
实际应用中的更新操作正是通过这些底层机制,高效实现跨多个 part 的精确行级更新。
让我们深入探索其运行原理
假设现在要为所有订单中数量大于等于 40 的商品应用 20% 的折扣:
UPDATE ordersSET discount = 0.2WHERE quantity >= 40;
这样的 SQL 语句可能会影响 多个数据 part 中的众多行。不过用户无需关心这些底层细节,只需表达更新意图即可。
声明式更新的价值
与 专用引擎(https://clickhouse.com/blog/updates-in-clickhouse-1-purpose-built-engines)(如 ReplacingMergeTree)不同,不再需要为每条更新显式插入新行。声明式 SQL 更新由系统自动处理所有执行逻辑,用户只需描述“要更新什么”。
为了演示 patch part 如何在 多个数据 part 中高效定位目标行,下图扩展了前面的示例,包含更多插入操作和一条批量更新语句。
说明:为了突出重点,我们将图中本示例未涉及的系统列和结构*进行灰显处理。
• 使用 橙色 标注实际使用到的系统列;
• 使用 蓝色 标注实际使用的索引;
• 浅灰色 表示未参与本次示例的数据结构。
这样的方式既便于聚焦核心内容,又能帮助读者全面了解底层机制。
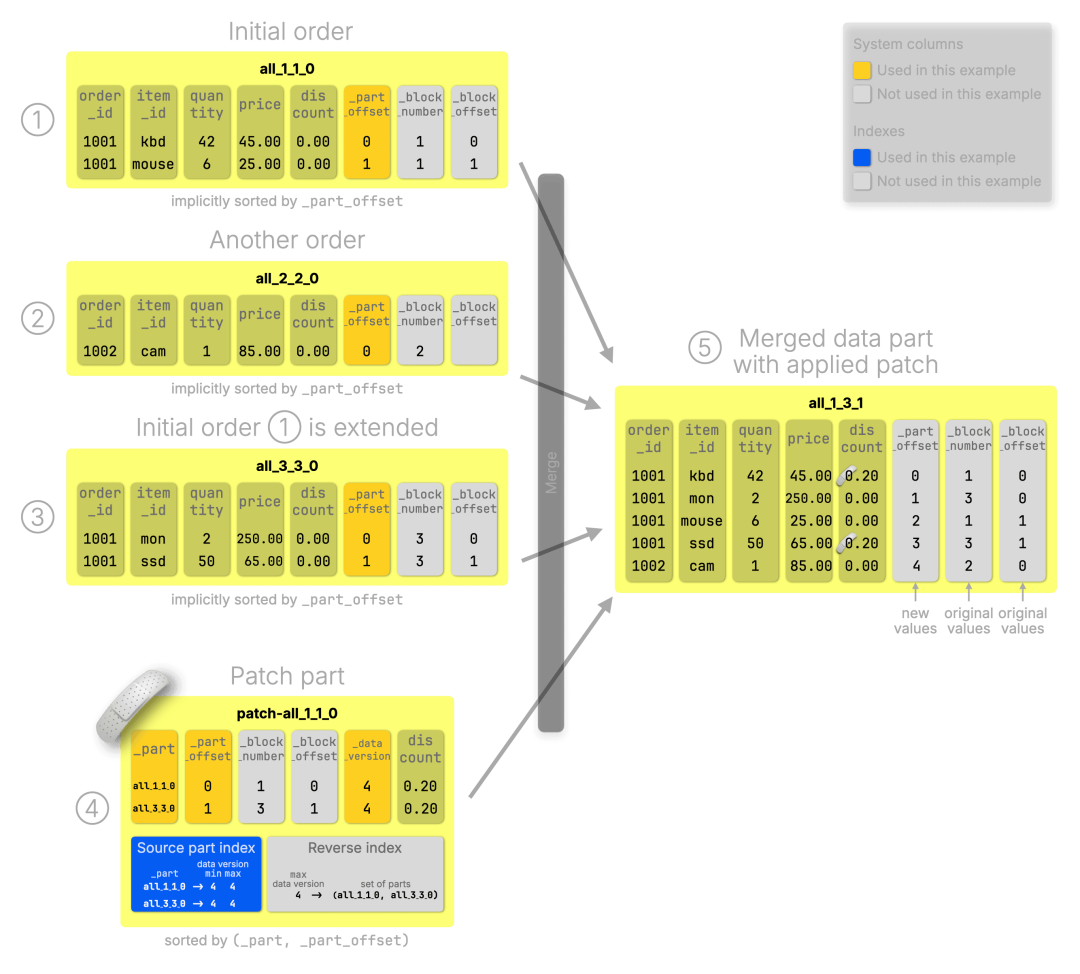
① 初始订单记录:包含两个商品的订单,用作基础示例。
② 新订单:插入一个新的 order_id,构成独立的一条记录。
③ 扩展订单:为初始订单添加两个额外商品。
上述三条为普通插入操作,最终生成 三个数据 part。
④ Patch part:由 UPDATE 操作生成,仅包含变更字段(两行记录的 discount 更新为 0.2)及定位所需的元数据。
⑤ 合并后的数据 part:将旧数据与 patch 值合并生成的最终 part。
数据清理流程:合并完成后,原始的 part(① 至 ③)以及 patch part(④)会被系统清理,仅保留合并产物 ⑤。
接下来我们来看图示中涉及的系统列与底层结构。
原始行中的系统列
为支持 patch part 机制,每条原始数据记录需携带以下 三个系统列:
系统列 | 描述 |
_part_offset | 行在所在 part 中的序号位置,用于合并时对齐数据并高效匹配 patch 行; |
_block_number, _block_offset | 行在插入时所属 block 的编号及其在该 block 中的偏移量,在 _part_offset 失效的情况下用于后续行定位;(本示例未使用) |
(这些列默认属于 虚拟列(https://clickhouse.com/docs/engines/table-engines/mergetree-family/mergetree#virtual-columns),图示中为便于理解以物理形式展示,实际仅在合并后落盘。)
补丁部分中的精确定位元数据
每条 patch part 中的记录只包含用于定位其目标行所必需的最小元数据:
系统列 | 用途 |
_part, _part_offset | 用于定位目标记录所在的原始 part 和对应行位置; |
_block_number, _block_offset | 支持在复杂场景下通过 block 维度进行数据追踪(本例未启用); |
_data_version | 记录更新版本号,用于跳过已处理的 patch,并支持多个 patch part 的合并(将在后文详解) |
patch part 中的其余字段包括:
<updated columns> |
补丁部分索引
当 patch part 创建完成后,ClickHouse 需要判断其应用时机与目标位置。为此,系统会为每个 patch part 构建两类轻量级索引:
索引名称 | 功能说明 |
源 part 索引(Source part index) | 将每个受影响的源数据 part 映射到其变更的最小与最大 _data_version,用于判断是否应将该 patch 应用于当前 part; |
反向索引(Reverse index) | 将某个 patch 的 _data_version 映射到所有需要被更新的 part 和 block,即使它们已经被合并,也能精确找到更新目标; |
这些索引机制确保了在后台持续合并的环境中,仍能 高效地定位并应用更新。
通过索引实现快速源部分匹配
以本示例为例,ClickHouse 借助 patch part 的 source part index 快速判断本次更新适用于哪些源 part。结果表明,仅 all_1_1_0 和 all_3_3_0 需要应用该 patch,而 all_2_2_0 不受影响。
借助系统列排序实现高效补丁合并
正如前文提到的,patch part 的设计充分依赖 ClickHouse 的后台合并机制(https://clickhouse.com/blog/updates-in-clickhouse-2-sql-style-updates#theyre-efficient)。由于所有 part 都按 _part_offset 排序(无论是显式还是隐式),ClickHouse 可在一次合并遍历中直接应用 patch,效率极高。
合并过程中保持行标识
在最终合并生成的 part(⑤)中,系统会重新生成 _part_offset 以反映新行位置;而 _block_number 与 _block_offset 则从原始数据中直接复用,保持不变。
这个细节对于支持更新操作在目标 part 被合并的同时 并发运行 是至关重要的。
接下来我们将深入解析其背后的运行机制。
ClickHouse 实现的更新机制是 非阻塞式 的:UPDATE 操作不需要等待正在进行的合并完成,而是基于一个 快照(https://clickhouse.com/blog/clickhouse-release-25-06#single-snapshot-for-select) 执行,该快照记录了操作开始时可见的所有 part。
相比之下,传统 mutation 机制要求等待之前所有合并与 mutation 操作完成之后才能开始执行。
大多数情况下,该快照在 patch part 后续被应用时依然有效。但如果此期间目标 part 已被 后台合并清除,ClickHouse 会自动回退至备用的匹配逻辑来确保更新依然正确执行。
我们将在下节通过图示演示这一回退过程。
如果在补丁应用前,源部分已被合并,会发生什么?
下图继续基于前文扩展示例,展示当目标 part 在 patch 应用之前已被合并移除 时,ClickHouse 如何处理该情况。
在前一张图中,我们将 _block_number 和 _block_offset 淡化处理。本图中,则将 _part、_part_offset 以及 patch 的 source part index 以灰色显示,因为它们在该场景下未被使用。
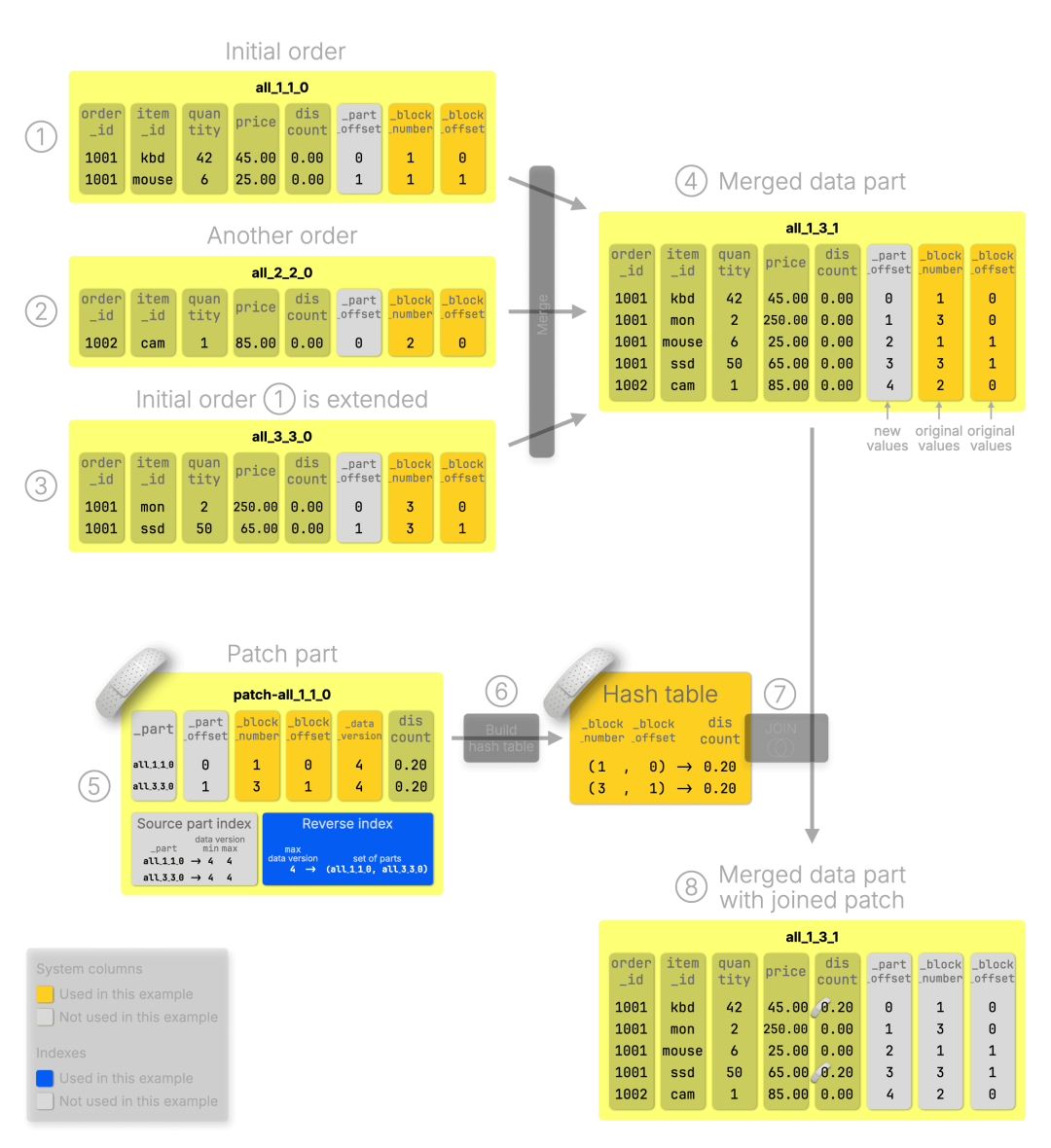
这个场景与之前有何不同?
①–③:执行的仍是之前的 相同插入操作 与后续的 ⑤ UPDATE,流程未发生变化。
④:不同的是,此次 patch 尚未应用,原始数据 part(①–③)就已被后台合并成一个新 part,并按常规被系统清除。
⑤:由于 patch 引用的 _part 和 _part_offset 对应的 part 已被删除,原有引用失效,ClickHouse 回退使用在合并过程中保留下来的 _block_number 与 _block_offset 来匹配目标行。
⑥–⑧:此时,ClickHouse 使用基于哈希连接的方式将 patch 应用于合并后的数据 part,生成包含更新内容的最终数据结果。
下面我们来具体看看这种“回退路径”是如何工作的。
利用反向索引进行源部分匹配
patch 的反向索引显示,它适用于 data version 4,目标是 all_1_1_0 与 all_3_3_0。根据其 命名规则(https://clickhouse.com/blog/updates-in-clickhouse-1-purpose-built-engines#how-to-read-a-part-name),这两个 part 分别包含 block 编号 1 与 3。
新的合并 part all_1_3_1(从名称可看出)覆盖了 block 编号 1 至 3,因此匹配范围有效。此外,该 part 的 data version 为 1(来源于最小的 block 编号),小于 patch 的版本 4,满足 patch 应用条件。
通过这种反向映射机制,ClickHouse 即使在原始 part 被合并并删除后,也能准确定位目标记录并应用 patch。
基于块的系统列 JOIN 来应用补丁
由于原始 part 已经不存在,原先依赖的 _part 和 _part_offset 无法继续使用,ClickHouse 改为采用一种基于 哈希连接 的匹配方式:将 patch part 加载进内存,按 (_block_number, _block_offset) 作为键构建哈希表,并与合并 part 中的数据按相同键进行匹配与更新。
这种回退路径相较前述的快速路径开销更大,需要 patch 内容全部驻留内存。未来 ClickHouse 可能会引入不依赖内存的 全量合并连接(full merge join),但目前该功能尚未实现。
值得庆幸的是,这种回退场景在实际中并不常见,大多数源数据 part 在生命周期内都足够完成快速 patch 操作。
既然我们已经深入了解了 ClickHouse 如何在合并过程中高效地执行 UPDATE 操作,接下来让我们看看 DELETE 又是如何实现类似的效率提升。
在 第 1.5 阶段(https://clickhouse.com/blog/updates-in-clickhouse-2-sql-style-updates#stage-15-lightweight-deletes-still-mutations-but-faster),ClickHouse 已通过 轻量级 DELETE 优化了删除操作的效率:仅通过 ALTER UPDATE 更新 _row_exists 掩码字段,避免重写整行数据。
但这还不是终点,我们还能进一步优化。
当 lightweight_delete_mode(https://clickhouse.com/docs/operations/settings/settings#lightweight_delete_mode) 被设置为 lightweight_update 时,DELETE 将不再依赖 ALTER 操作。ClickHouse 会直接生成一个 patch part,将被删除记录的 _row_exists 字段设置为 0。此类记录将在后续的后台合并任务中被彻底移除。
下图复用了阶段 1.5 的示例:我们删除原始订单中的鼠标商品记录。(为简化展示,图中省略了未使用的系统列,如 _block_number、_block_offset 等。)
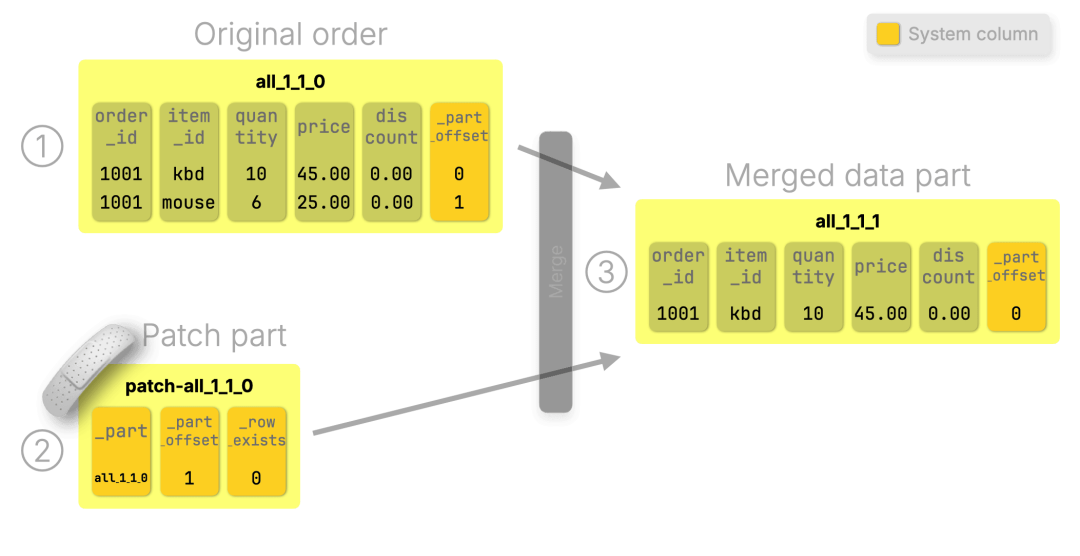
步骤 ①:初始数据 part 含两行数据。
步骤 ②:patch part 将其中一行(鼠标)标记为 _row_exists = 0。
步骤 ③:在下一轮后台合并中,该行会被物理删除。
ClickHouse 会立即将 patch 应用于查询执行过程中。在合并发生之前,系统会自动忽略所有 _row_exists = 0 的行。这正是 读取时应用 patch(patch-on-read) 查询模型的核心机制。
ClickHouse 不会等待 patch part 被物化或合并完成再提供查询结果,而是:
patch part 会在查询期间自动加载至内存并即时生效,类似隐式的 FINAL 操作(https://clickhouse.com/blog/updates-in-clickhouse-1-purpose-built-engines#getting-up-to-date-results-with-final)。
这一 patch-on-read 模型设计旨在最大程度降低查询性能开销。
一般来说,在 索引分析(https://clickhouse.com/docs/primary-indexes) 之后,查询所涉及的数据分布在多个数据范围(连续数据块)中,这些范围可能横跨多个数据 part。ClickHouse 查询引擎会将这些范围动态分发至 ① 各个并行的数据流阶段(data stream stage),并通过 ② 并行处理通道(https://clickhouse.com/docs/optimize/query-parallelism#distributing-work-across-processing-lanes) 执行过滤、聚合、排序及限制等操作,最终输出查询结果:
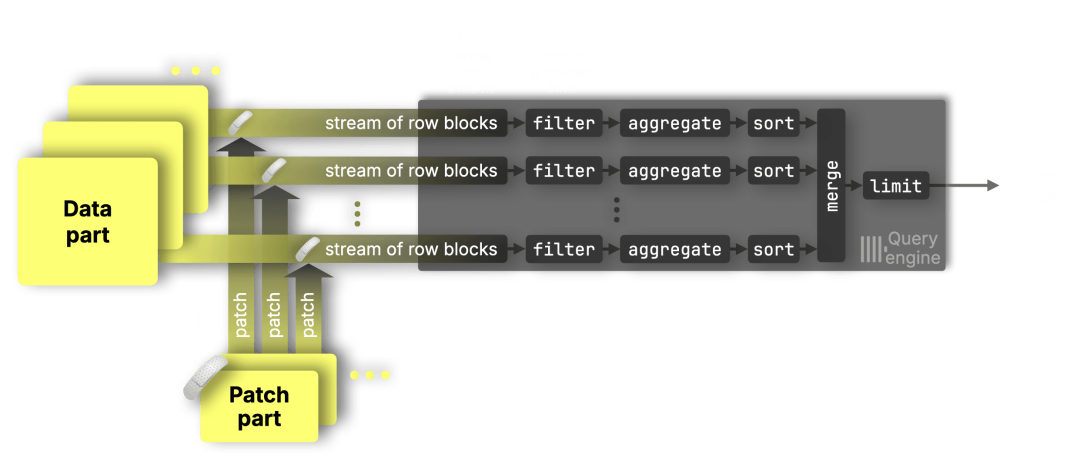
尚未合并的 patch part 会在 ③ 每个数据流的各个数据范围内 独立识别并应用补丁,确保更新准确无误,同时不影响查询的并行执行效率。
(如有需要,可以通过执行 ALTER TABLE … APPLY PATCHES 命令,将所有尚未合并的变更数据显式物化。但该操作并非必须。)
要全面理解 patch part,还需要了解它的完整生命周期,即 ClickHouse 如何在后台执行合并、去重和清理操作。
虽然 patch part 在功能上具有特殊意义,但在底层实现中,它们与普通数据 part 没有本质区别。这也意味着:
patch part 会通过 ReplacingMergeTree(https://clickhouse.com/blog/updates-in-clickhouse-1-purpose-built-engines#replacingmergetree-replace-rows-by-inserting-new-ones) 算法进行合并,系统使用 _data_version 作为 版本控制列(https://clickhouse.com/docs/engines/table-engines/mergetree-family/replacingmergetree#replacingmergetree-parameters),以确保每一行更新记录仅保留最新版本;
一旦补丁被完全合并进所有相关数据 part,或与其他 patch part 合并完成,该补丁数据会被 自动清理,清理任务由后台线程安全执行;
所有 patch part 也会 计入每个分区的 TOO_MANY_PARTS 限制(详见 文档说明(https://clickhouse.com/docs/operations/settings/merge-tree-settings#parts_to_throw_insert))。为降低此限制带来的影响,ClickHouse 会根据每次更新所涉及的列集合将 patch part 存储在不同的分区中。例如,执行 SET x = …、SET y = … 和 SET x = …, y = … 会分别生成三个 patch 分区,每个分区独立统计 part 数量。
这样的机制使得 patch part 具备了高效、可扩展、深度集成 MergeTree 架构的特性。
前文我们一直关注 patch part 的单次行为表现。那么,在多个更新同时发生的情况下,ClickHouse 又是如何保证正确性的呢?
ClickHouse 默认支持并发执行更新操作。 当两个 UPDATE 涉及同一列时,系统会自动识别依赖关系并按正确顺序执行,确保数据一致性。整个过程无需用户手动干预。
你可以通过以下配置参数来控制并发行为:
update_parallel_mode(https://clickhouse.com/docs/operations/settings/settings#update_parallel_mode):
auto(默认):会对存在依赖的更新操作进行序列化处理(例如 UPDATE a=3 WHERE b=2 与 UPDATE b=2 WHERE a=1),无依赖更新则并行执行;
sync:强制所有 UPDATE 顺序执行;
async:所有 UPDATE 无协调地并发运行;
update_sequential_consistency(https://clickhouse.com/docs/operations/settings/settings#update_sequential_consistency)(默认关闭):开启后可保证每次更新都基于最新可见状态执行,适用于需要严格一致性的场景,但会略微影响性能。
对于绝大多数使用场景,默认配置已经能够提供良好的性能与正确性保障。
这些并发协调机制完全由 ClickHouse 内部处理。对开发者而言,执行 UPDATE 操作就像普通 SQL 一样直观可靠 —— 它不需要你了解其背后的复杂机制。
在文章的最后,让我们从更宏观的角度来看待这项变革。
patch part 并不是试图绕开列式存储的特性来实现 UPDATE,而是充分发挥了列式架构的优势,最终为 ClickHouse 带来了真正高效、声明式、可扩展的类 SQL 更新能力。
我们充分利用了 ClickHouse 的核心优势:
写入速度极快,后台合并持续进行,数据 part 保持不可变且有序。
正因为 插入如此高效,我们将更新操作抽象为插入行为。
ClickHouse 在后台生成紧凑的 patch part,并在合并过程中高效应用这些更新。
我们没有额外增加系统负担,而是让已有的合并机制承担更多职责。
既然引擎本就持续在后台合并数据 part,我们只是顺势将更新操作也纳入该流程,以极低的额外开销完成补丁应用。
patch part 可即时生效,对查询性能几乎无影响。
更新结果几乎立即可见,尚未合并的补丁会以并行友好的方式应用,不会干扰查询执行。
这正是如今支撑 ClickHouse 中 轻量级更新(lightweight update) 的核心机制。
它延续了 ReplacingMergeTree 等专用引擎的核心理念,但将其抽象为一套通用能力,封装在灵活、标准的 SQL 语法之下:
UPDATE ordersSET discount = 0.2WHERE quantity >= 40;
最终实现效果是:更新即刻可见,查询持续高效,执行过程无阻塞。这就是 ClickHouse 所实现的现代化 UPDATE 模型 —— 完全基于标准 SQL,具备行业领先的性能表现。
我们将在第 3 部分对该机制进行性能基准测试。
敬请关注。

好消息:ClickHouse Beijing User Group第 3 届 Meetup 火热报名中,将于2025年09月20日在北京海淀永泰福朋喜来登酒店(北京市海淀区远大路25号1座)举行,扫码免费报名

/END/
试用阿里云 ClickHouse企业版
轻松节省30%云资源成本?阿里云数据库ClickHouse 云原生架构全新升级,首次购买ClickHouse企业版计算和存储资源组合,首月消费不超过99.58元(包含最大16CCU+450G OSS用量)了解详情:https://t.aliyun.com/Kz5Z0q9G


征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


