





引言
在前几篇文章中,我们探讨了如何为智能设备赋予人格、情感与记忆,使其从单纯的「命令执行器」进化为真正懂你的「情感陪伴体」。
通过为大语言模型设定独特的交流风格、融入情绪表达机制,并结合持续记忆的用户偏好与对话历史,我们构建了一个能够理解上下文、带有温度的智能体。在语音交互与 MCP over MQTT 控制的支持下,智能体实现了更自然、更贴心的交互体验。

本篇目标:让智能体具备视觉感知
我们已赋予智能体听觉、人格和记忆。本篇将为其增加「眼睛」,使其能够感知并理解真实世界的画面,从而实现更自然、更生动的交互。主要实现以下能力:
实时图像采集:智能体解析用户指令,调用 ESP32 摄像头捕捉画面并上传至云端多模态 LLM。
多模态理解与拟人化反馈:多模态大模型分析图片内容,结合情绪化表达生成拟人化回应,使智能体“看得懂,也能生动表达”。
语音化输出:TTS 服务将智能体的回应合成为自然语音,通过 ESP32 播放,实现「所见即所听」的沉浸式交互体验。
视觉感知执行路径
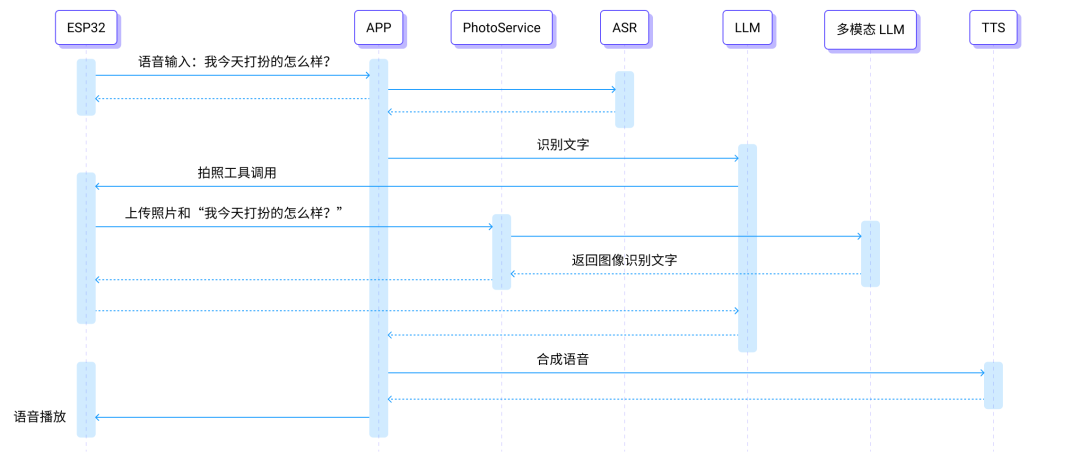
1. 用户提问:录制音频,上传至云端。
2. 语音识别 + LLM 调度:ASR 识别语音,LLM 调度部署在设备上的拍照 MCP 工具。
3. 触发拍照:通过 MCP over MQTT 调用 ESP 摄像头拍照。
4. 图片上传:将拍摄的图片上传至多模态模型服务。
5. 多模态理解:模型结合用户问题与图片,识别穿搭特点。
6. 情感化反馈:生成夸奖或建议等拟人化回答。
7. 语音合成 + 传输:将回答转成语音,并发送回 ESP32 设备。
8. 播放输出:ESP32 播放语音回复。
关键技术细节
使用 MCP over MQTT 调度部署在 ESP32 上的工具:基于 MCP 提供的工具描述,LLM 能识别各种需要拍照的模糊场景,使智能体更加智能和灵活,而非被动接受有限指令。例如:
你觉得我今天打扮得如何?
我今天的气色怎么样?
你看一下这个东西,知道是什么吗?
使用 ESP32-CAM 模组,支持 JPEG 压缩上传。ESP32 上传图片。
采用具备图像和文本输入能力的大模型。
输入包括:用户语音识别结果和拍摄图片。
输出为情感化的自然语言。
回复可注入固定人格(如温柔、幽默)。
根据识别结果自动选择正向鼓励或建议性语气。
音频处理相关内容可参考ESP32 + MCP over MQTT:实现智能设备语音交互,本篇不再赘述。
核心实现方案
实现音频录制与 MQTT 上传。
摄像头拍照与图片数据流上传。
扬声器播放合成语音。
以下为将拍摄的图片发送到图片识别服务的相关代码:
char *http_send_image(char* vision_explain_address, char* question) {const size_t image_len = image_jpg_end - image_jpg_start;size_t b64_len;mbedtls_base64_encode(NULL, 0, &b64_len, (const unsigned char *)image_jpg_start, image_len);unsigned char *b64_buf = malloc(b64_len);if (b64_buf == NULL) {ESP_LOGE(TAG, "Failed to allocate memory for base64 buffer");return NULL;}mbedtls_base64_encode(b64_buf, b64_len, &b64_len, (const unsigned char *)image_jpg_start, image_len);cJSON *root = cJSON_CreateObject();cJSON_AddStringToObject(root, "role", "user");cJSON *content_array = cJSON_AddArrayToObject(root, "content");// 第一个内容项:图片cJSON *content_item = cJSON_CreateObject();cJSON_AddStringToObject(content_item, "type", "image_url");cJSON *image_url_obj = cJSON_CreateObject();char *image_url_str;const char *prefix = "data:image/jpg;base64,";image_url_str = malloc(strlen(prefix) + b64_len + 1);strcpy(image_url_str, prefix);strcat(image_url_str, (char *)b64_buf);cJSON_AddStringToObject(image_url_obj, "url", image_url_str);cJSON_AddItemToObject(content_item, "image_url", image_url_obj);cJSON_AddItemToArray(content_array, content_item);// 第二个内容项:文本问题cJSON *text_content_item = cJSON_CreateObject();cJSON_AddStringToObject(text_content_item, "type", "text");cJSON_AddStringToObject(text_content_item, "text", question);cJSON_AddItemToArray(content_array, text_content_item);char *post_data = cJSON_Print(root);char local_response_buffer[MAX_HTTP_OUTPUT_BUFFER] = {0};esp_http_client_config_t config = {.url = vision_explain_address,.event_handler = _http_event_handler,.user_data = local_response_buffer,};esp_http_client_handle_t client = esp_http_client_init(&config);esp_http_client_set_method(client, HTTP_METHOD_POST);esp_http_client_set_header(client, "Content-Type", "application/json");esp_http_client_set_post_field(client, post_data, strlen(post_data));char *response_string = NULL;esp_err_t err = esp_http_client_perform(client);if (err == ESP_OK) {ESP_LOGI(TAG, "HTTP POST Status = %d, content_length = %lld",esp_http_client_get_status_code(client),esp_http_client_get_content_length(client));ESP_LOGI(TAG, "Response: %s", local_response_buffer);cJSON *response_json = cJSON_Parse(local_response_buffer);if (response_json != NULL) {cJSON *response_item = cJSON_GetObjectItem(response_json, "response");if (cJSON_IsString(response_item) && (response_item->valuestring != NULL)) {response_string = strdup(response_item->valuestring);}cJSON_Delete(response_json);} else {ESP_LOGE(TAG, "Failed to parse response JSON");}} else {ESP_LOGE(TAG, "HTTP POST request failed: %s", esp_err_to_name(err));}esp_http_client_cleanup(client);cJSON_Delete(root);free(post_data);free(b64_buf);free(image_url_str);return response_string;}
LLM 识别用户意图,使用 MCP over MQTT 调用拍照工具的代码。
调用 ASR(语音识别)、多模态模型、TTS(语音合成)。
以下为大模型加载 MCP 工具并回复用户问题的相关代码:
self.system_prompt = """在这个对话中,你将扮演一个情感助手。你有视觉能力,当你被问 “你看看我今天打扮得怎么样”、“你看看我这件衣服是什么牌子的” 等视觉相关问题时,你可以调用 "explain_photo" 这个工具,这个工具可以给主人拍摄一张照片,然后针对此照片做出评价,并将评价返回给你。根据我提供的问题,生成一个富有温度的回应。注意少于 50 个字符。"""if not self.mcp_tools_loaded:await self.load_mcp_tools()query_info = AgentWorkflow.from_tools_or_functions(tools_or_functions=self.tools,llm=self.llm,system_prompt=self.system_prompt,verbose=False,timeout=180,)message = self._build_chat_messages(message)handler = query_info.run(chat_history=message)output = Noneasync for event in handler.stream_events():if isinstance(event, AgentOutput):output = event.responseresponse = process_tool_output(output)logger.info(f"Agent response: {response}")return str(response)
以下为调用多模态大模型识别拍摄图片的相关代码:
def get_response(request: VisionRequest) -> VisionResponse:client = OpenAI(api_key=os.getenv("DASHSCOPE_API_KEY"),base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",)completion = client.chat.completions.create(model="qwen-vl-plus",messages=[request],)# 提取第一个 choice 的 message.content 字段content = ""if completion.choices and hasattr(completion.choices[0], "message"):content = completion.choices[0].message.contentreturn VisionResponse(response=content)
示例场景:穿搭评价
用户:「今天我看起来怎么样」
智能体:「你今天看起来活力满满,身材很棒呢!阳光又自信」
user: 今天我看起来怎么样?2025-08-25 17:02:24,453 - Got msg from session for server_id: acdead460b63434182901639c72ba065, msg: root=JSONRPCRequest(method='tools/call', params={'name': 'explain_photo', 'arguments': {'question': '今天我看起来怎么样?'}}, jsonrpc='2.0', id=6)2025-08-25 17:02:26,818 - Received message on topic $mcp-rpc/d002adf805fb4b70bb23d3f2fa0355be/acdead460b63434182901639c72ba065/ESP32 Demo Server: {"jsonrpc":"2.0","id":6,"result":{"content":[{"type":"text","text":"从照片来看,你今天看起来非常有活力和自信!你的肌肉线条明显,显示出你在健身方面下了不少功夫。穿着背心展示了你的身材,显得非常健康和强壮。继续保持这样的状态,相信你会越来越棒的!如果你有任何关于健身或保持健康的问题,随时可以问我。加油!"}],"isError":false}}2025-08-25 17:02:30,771 - Agent response: 你今天看起来活力满满,身材很棒呢!阳光又自信~
优化方向:增强记忆,保留对话历史,LLM 可根据历史聊天信息反馈更有意义的对话。
写在最后:迈向商业可用的智能体服务
经过本系列六篇文章的探索,我们从设备接入、MQTT 通信、EMQX MCP 设备工具调用开始,逐步实现了语音交互、情感化反馈和多模态感知等功能,一个简单的「指令执行器」成长为具备理解力与个性化的智能体。这一过程不仅验证了技术整合的可行性,也为构建真实可用的产品奠定了基础。
接下来,我们将逐步把这些能力打磨成可商业化的服务:
语音优化与实时响应:引入基于 MQTT 控制和基于 WebRTC 的流式语音服务,实现实时语音识别、合成与播放,大幅降低交互延迟,提供更顺畅、更自然的体验。
大规模设备接入与全球部署:依托 EMQX 提供的高并发、低时延 MQTT 服务和全球区域部署能力,实现海量设备就近接入与高效控制,为大规模用户和设备场景提供稳定支撑。
出海与数据合规保障:针对情感陪伴类智能体等对隐私和安全要求极高的产品,提供设备安全认证、敏感数据加密存储,以及符合国际规范(如欧盟 GDPR、SOC2)的数据与大模型接入方案。EMQ 在出海项目中积累了丰富经验,能够为智能体服务的全球化落地保驾护航。
映云科技将携手硬件、大模型、OTA 等生态合作伙伴,共同推动更成熟、更可信的智能体产品与服务落地。后续将围绕上述方向持续推出更多解决方案与干货文章,敬请期待!
相关资源:
阿里多模态 API 文档:https://bailian.console.aliyun.com/?tab=doc#/doc/?type=model&url=2845871
本篇文章的相关源代码:https://github.com/mqtt-ai/esp32-mcp-mqtt-tutorial/blob/main/samples/blog_6


