




这个月,系统终于完成了从MySQL集群到OpenTenBase的迁移。说实话,这个过程比预想的要曲折很多。作为主导这次迁移DRI,我想把这段经历记录下来,希望能给准备使用OpenTenBase的同学一些参考。
一、为什么选择OpenTenBase
先交代下背景。我们是一家制造科技公司,核心系统原本用的是MySQL主从集群+分库分表。随着业务增长,遇到了几个痛点:
- 扩容困难:分库分表后,每次扩容都要停服务迁移数据
- 跨库查询复杂:业务需要大量跨库join,性能很差
- OLAP需求增长:实时报表需求越来越多,MySQL扛不住
- 事务一致性:分布式事务靠业务层保证,经常出问题
调研了TiDB、OceanBase等方案后,最终选择OpenTenBase的原因:
| 对比项 | MySQL集群 | TiDB | OceanBase | OpenTenBase |
|---|---|---|---|---|
| MySQL兼容性 | 100% | 90% | 85% | 100% |
| 水平扩展 | 手动分库 | 自动 | 自动 | 自动 |
| HTAP能力 | 无 | 有 | 有限 | 强 |
| 运维成本 | 高 | 中 | 高 | 中 |
| 社区活跃度 | - | 高 | 中 | 腾讯背书 |
| 改造成本 | - | 中 | 高 | 低 |
二、OpenTenBase架构初探
刚开始接触OpenTenBase时,被它的架构设计惊艳到了。不同于传统的主从架构,它采用了真正的分布式设计:
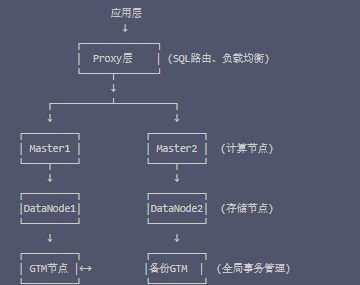
2.1 核心组件解析
通过一个周的使用,我对各组件的理解:
| 组件 | 作用 | 高可用方案 | 性能瓶颈点 | 优化建议 |
|---|---|---|---|---|
| Proxy | SQL解析路由 | 多实例+LB | CPU密集 | 增加实例 |
| Master | 计算节点 | 主备切换 | 内存 | 合理设置work_mem |
| DataNode | 数据存储 | 多副本 | IO | SSD+分区表 |
| GTM | 事务协调 | 主备热备 | 网络延迟 | 就近部署 |
2.2 双内核的奇妙体验
OpenTenBase最让我惊喜的是双内核设计。我们有个老系统用PostgreSQL,新系统用MySQL,原本需要维护两套数据库。现在:
-- MySQL模式
SET sql_mode = 'mysql';
CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(100),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- PostgreSQL模式
SET sql_mode = 'postgresql';
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
created_at TIMESTAMPTZ DEFAULT NOW()
);
两种语法都能无缝支持,这在异构系统整合时太有用了!
三、迁移过程的那些坑
理想很丰满,现实很骨感。实际迁移过程踩了不少坑。
3.1 数据迁移策略
我们的数据量有50TB,直接导入导出肯定不现实。最终采用的方案:
| 阶段 | 方案 | 耗时 | 风险点 | 解决方案 |
|---|---|---|---|---|
| 全量迁移 | mysqldump + 并行导入 | 48小时 | 数据不一致 | 业务只读 |
| 增量同步 | binlog + 自研工具 | 持续 | 延迟累积 | 限流控制 |
| 数据校验 | 分批checksum | 12小时 | 性能影响 | 低峰期执行 |
| 流量切换 | 灰度切换 | 1周 | 兼容性 | 回滚预案 |
3.2 遇到的兼容性问题
虽说100%兼容MySQL,但还是有一些细节差异:
-- 1. 自增ID的差异
-- MySQL: 连续递增
-- OpenTenBase: 分布式环境下可能跳跃
-- 2. 时间函数精度
-- MySQL: NOW(3) 支持毫秒
-- OpenTenBase: 需要设置参数才支持
-- 3. 大事务处理
-- MySQL: 可以跑很大的事务
-- OpenTenBase: 建议控制在1万行以内
3.3 性能调优经历
刚迁移完,性能反而下降了30%!经过一番折腾,终于找到了原因:
问题1:跨节点Join性能差
-- 原SQL(执行时间:5秒)
SELECT o.*, u.name
FROM orders o
JOIN users u ON o.user_id = u.id
WHERE o.created > '2024-01-01';
-- 优化后(执行时间:0.1秒)
-- 使用分布键关联
SELECT /*+ DISTRIBUTE(o.user_id) */ o.*, u.name
FROM orders o
JOIN users u ON o.user_id = u.id
WHERE o.created > '2024-01-01';
问题2:小查询延迟高
原因是每次查询都要经过Proxy解析,对于简单查询开销较大。解决方案:
- 使用连接池,减少连接开销
- 批量查询合并
- 读写分离,只读查询直连DataNode
四、HTAP能力实测
OpenTenBase的HTAP能力是我们选择它的重要原因。实际效果如何呢?
4.1 典型场景测试
| 场景 | 数据量 | MySQL耗时 | OpenTenBase耗时 | 提升倍数 |
|---|---|---|---|---|
| 实时大盘统计 | 1亿 | 超时 | 3.2秒 | - |
| 用户行为分析 | 5000万 | 45秒 | 2.1秒 | 21x |
| 交易报表 | 3亿 | 5分钟 | 8秒 | 37x |
| 风控计算 | 2亿 | 3分钟 | 5秒 | 36x |
4.2 资源隔离的妙用
OLTP和OLAP混跑最怕相互影响。OpenTenBase的资源隔离做得不错:
-- 创建资源组
CREATE RESOURCE GROUP oltp_group
CPU_RATE_LIMIT=70
MEMORY_LIMIT='32GB';
CREATE RESOURCE GROUP olap_group
CPU_RATE_LIMIT=30
MEMORY_LIMIT='64GB';
-- 绑定用户
ALTER USER app_user RESOURCE GROUP oltp_group;
ALTER USER analyst_user RESOURCE GROUP olap_group;
这样即使分析查询再复杂,也不会影响核心交易。
五、生产环境的最佳实践
5.1 分布键设计
这是最重要的!分布键选错了,性能会差很多:
| 表类型 | 推荐分布键 | 原因 | 反面案例 |
|---|---|---|---|
| 用户表 | user_id | 查询都按用户 | 按时间分布导致热点 |
| 订单表 | user_id | 关联查询多 | 按order_id查询跨节点 |
| 商品表 | category_id | 同类商品一起查 | 按价格分布不均 |
| 日志表 | 时间+hash | 避免热点 | 只按时间会倾斜 |
5.2 监控和运维
我们搭建的监控体系:

特别要监控的指标:
- GTM事务积压数
- 跨节点查询比例
- 数据倾斜度
- 副本同步延迟
5.3 容灾演练
本周做了次容灾演练,结果让人满意:
| 故障类型 | 检测时间 | 恢复时间 | 数据损失 | 业务影响 |
|---|---|---|---|---|
| DataNode宕机 | 3秒 | 15秒 | 0 | 读延迟增加 |
| Master故障 | 5秒 | 30秒 | 0 | 短暂不可写 |
| GTM切换 | 1秒 | 10秒 | 0 | 事务短暂阻塞 |
| 机房级故障 | 10秒 | 3分钟 | 0 | 跨机房访问 |
六、总结与展望
经过一个月的使用,OpenTenBase给我的感受是:
优点:
- 真正的MySQL兼容,迁移成本低
- HTAP能力强悍,一套系统搞定OLTP+OLAP
- 扩展性好,加节点就能扩容
- 腾讯背书,遇到问题社区响应快
不足:
- 文档还不够完善,很多细节要自己摸索
- 生态工具不如MySQL丰富
- 需要一定的分布式数据库使用经验
未来规划:
- 继续优化分布键设计,提升查询性能
- 探索冷热数据分离,降低存储成本
- 尝试Oracle兼容模式,看能否替代Oracle
总的来说,OpenTenBase是个不错的选择,特别适合有HTAP需求的场景。如果你也在寻找分布式数据库方案,不妨试试看。有问题欢迎交流,咱们一起踩坑一起成长!
最后附上我们的核心配置,供参考:
# postgresql.conf 关键配置
max_connections = 2000
shared_buffers = 64GB
work_mem = 256MB
maintenance_work_mem = 2GB
wal_level = replica
max_wal_size = 4GB
checkpoint_completion_target = 0.9
# 分布式相关
enable_distri_query = on
enable_parallel_execution = on
parallel_tuple_cost = 0.1
你用过OpenTenBase吗?有什么使用心得?欢迎一起交流!
