




先更正一下上一篇文章:kafka系列(四),不是createDStream,而是createStream。
下面介绍createDirectStream,因为在kafkaUtil.createDirectStream进行了创建。所以我们来研究一下这里做了什么事情。
createDirectStream:
作用:
创建一个input stream用来直接从kafka broker中pull消息,在这个过程中,没有用到任何receiver。这个input stream可以被保证从kafka中来的数据只将转换操作进行一次。
要点分析:
no receivers:这种类型的stream不需要任何receiver,它直接从kafka中查询offsets进行消费,不需要使用zookeeper进行offsets的存储,offsets由kafka自身存储。
Failure Recovery(故障恢复):从driver中恢复故障,必须使用checkpoint机制。一些消费的offsets的信息可以从checkpoint的内容中进行恢复。
End-to-end semantics(端到端语义):每一个消息都被有效的接受和转换一次[exactly once],但不能保障转换后的数据是否准确的只输出一次
DirectKafkaInputDStream:
kafkaUtil.createDirectStream(ssc,kafkaParams,topic)中,会去调用DirectKafkaInputDStream.该类会和Kafka集群打交道。

每个DirectKafkaInputDStream对应着一个Topic。在该类中,会获取每个Topic的每个Partition的offset。
在这个类中,主要的是compute方法,到计算周期时,也就是调用了compute后,会做以下事情:
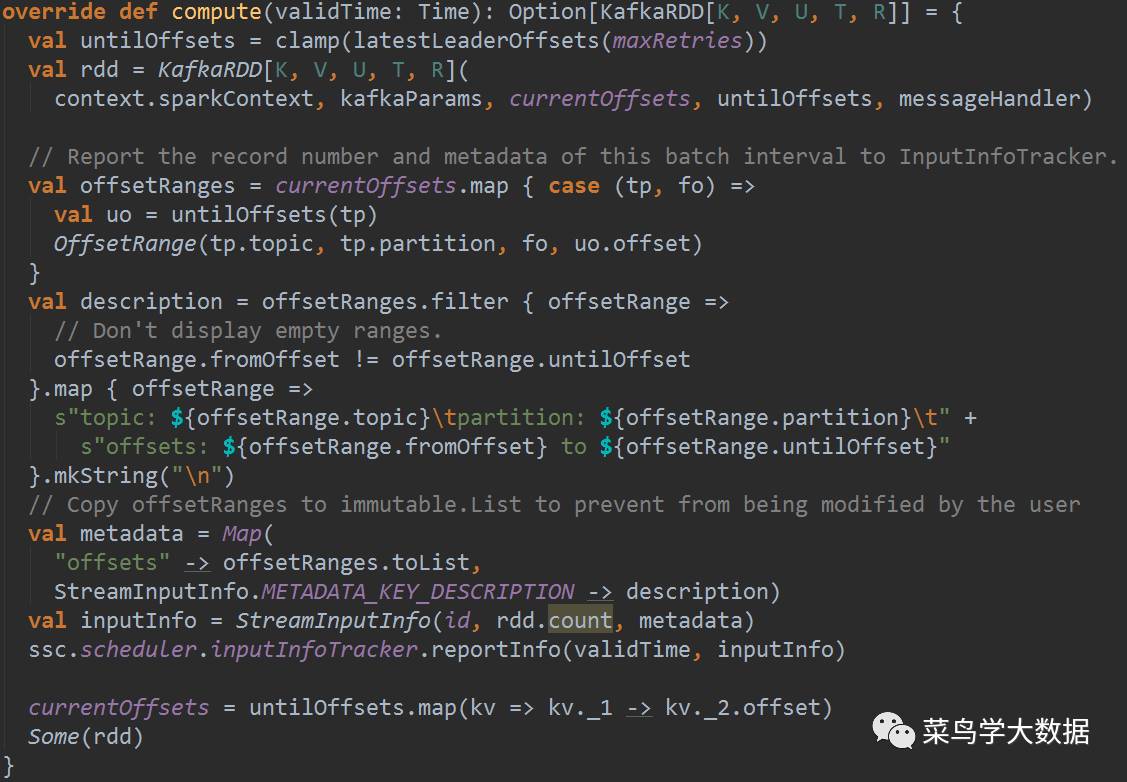
主要有以下四个方面:
计算untiloffset[kafka partition]
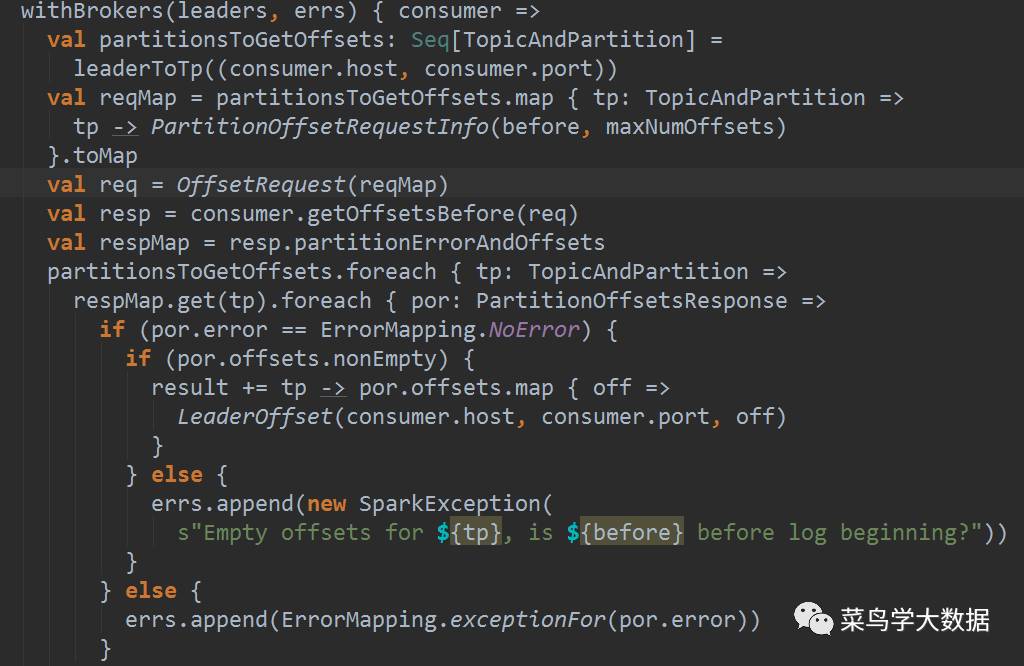
实例化一个kafkaRDD[sc,kafkaparams,currentoffset,untiloffset,,messageHandler]
将offset和streaminputinfo组成metadata信息报告给inputinfoTracker
返回rdd。为了防止空数据错误,用了Some(rdd)
KafkaRDD详解:
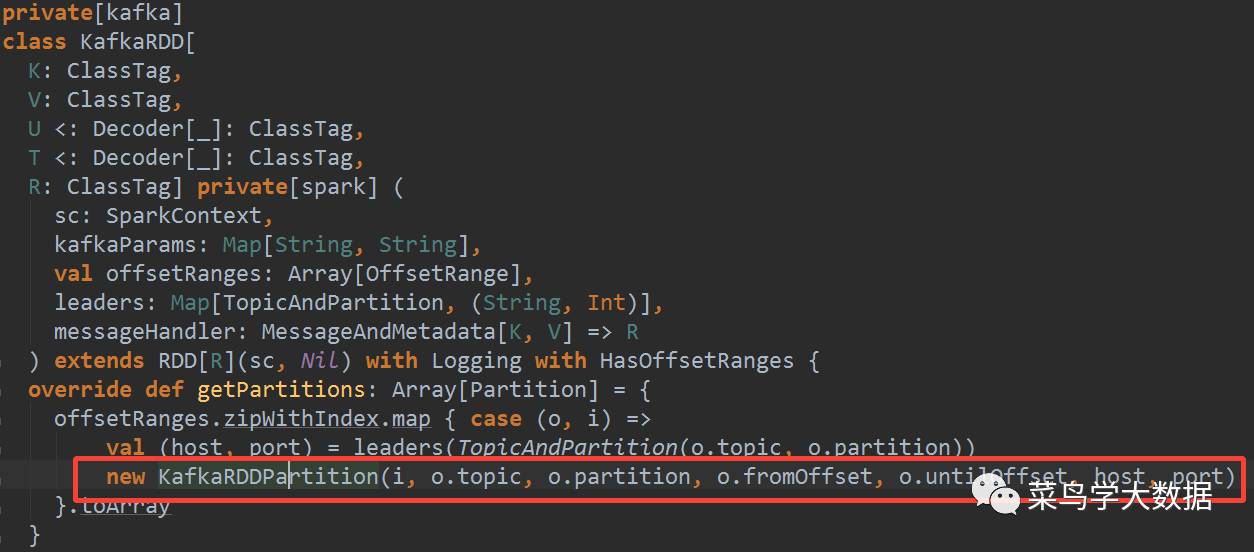
KafkaRDD 包含 N(N=Kafka的partition数目)个 KafkaRDDPartition。
在这里,去获取KafkaRDD的partition,因为kafkaRDD的partition和topic的Partition是一一对应的
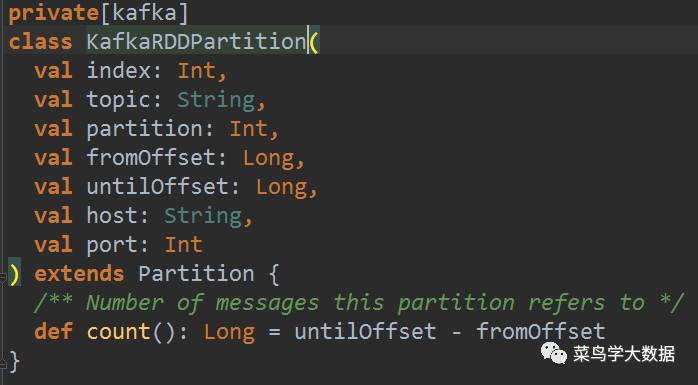
这里通过KafkaRDDPartition获取partition中message的个数。如下,通过untiloffset-fromoffset计算得到message个数。
重点是这里的compute函数,创建了KafkaRDDIterator实例。用该实例来真正pull数据。代码如下:
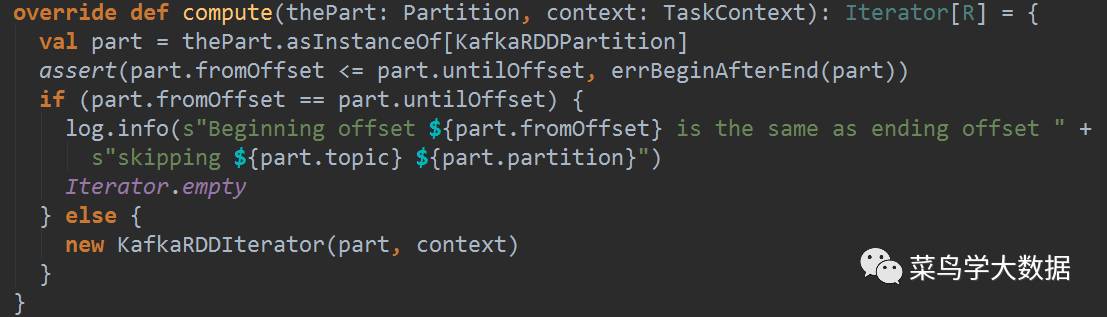
在KafkaRDDIterator中主要的部分是:fetchBatch,用于取数据。
